-
-
Smart Reader

Inspiration
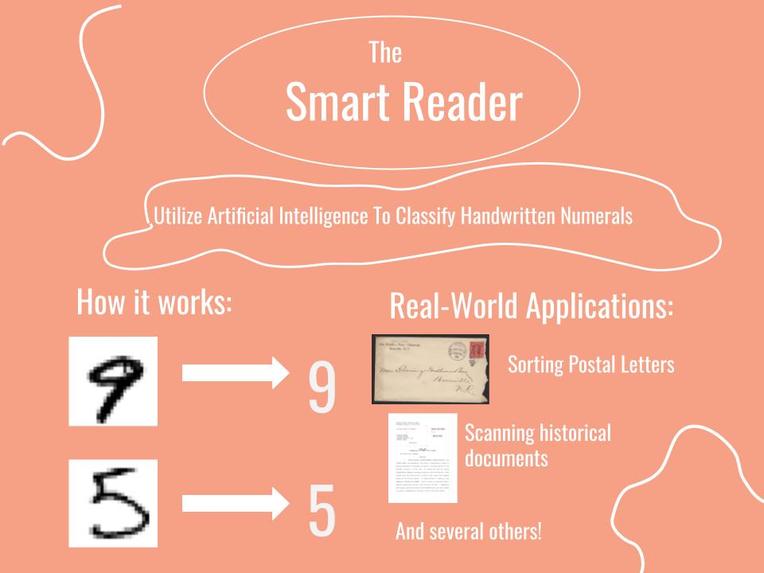
I got inspired to solve this problem because in the current age of digitization, if computers can do the job of recognizing handwritten materials, a lot of old documents in libraries etc can be digitized. Other applications can be recognizing vehicle license-plates, sorting of postal letters, and scanning of historical documents. Processing of digital files is cheaper and faster than processing traditional paper files.
What it does
It takes an image of a handwritten digit as input and predicts the digit.
How we built it
I have used Image classification with Tensorflow and the MNIST dataset to train and test my model. MNIST is a modified subset of two datasets collected by the U.S. National Institute of Standards and Technology. It contains 70,000 labeled images of handwritten digits. I have used 60,000 images to train my model and 10,000 images to test my model. First, I converted the labels to one hot encoded labels. Next, I reshaped each of the samples from 28 by 28 size images to 784 pixel array Then I did normalization of the samples Then I created a neural network using Sequential class and a dense model which means all the nodes of a layer are connected to all the nodes of the previous layer. My model consists of 2 hidden layers with 128 nodes in each. Then I compiled the model and trained the model on training images. After that, I used the 10,000 images in the test set to evaluate the model and make predictions. Finally, I compared the predicted values to the actual test labels and plotted the results.
Challenges we ran into
It was hard to set up the basic framework. It took several iterations to train the model to give a high accuracy.
Accomplishments that we're proud of
I was able to achieve a high accuracy. The accuracy of my model is 96.2%
What we learned
I learned about Tensorflow, Keras and matplotlib libraries.
What's next for SmartReader
To be able to read images with multiple digits
Built With
- keras
- matplotlib
- mnist
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.