-
-
Architecture Diagram
-
-

-

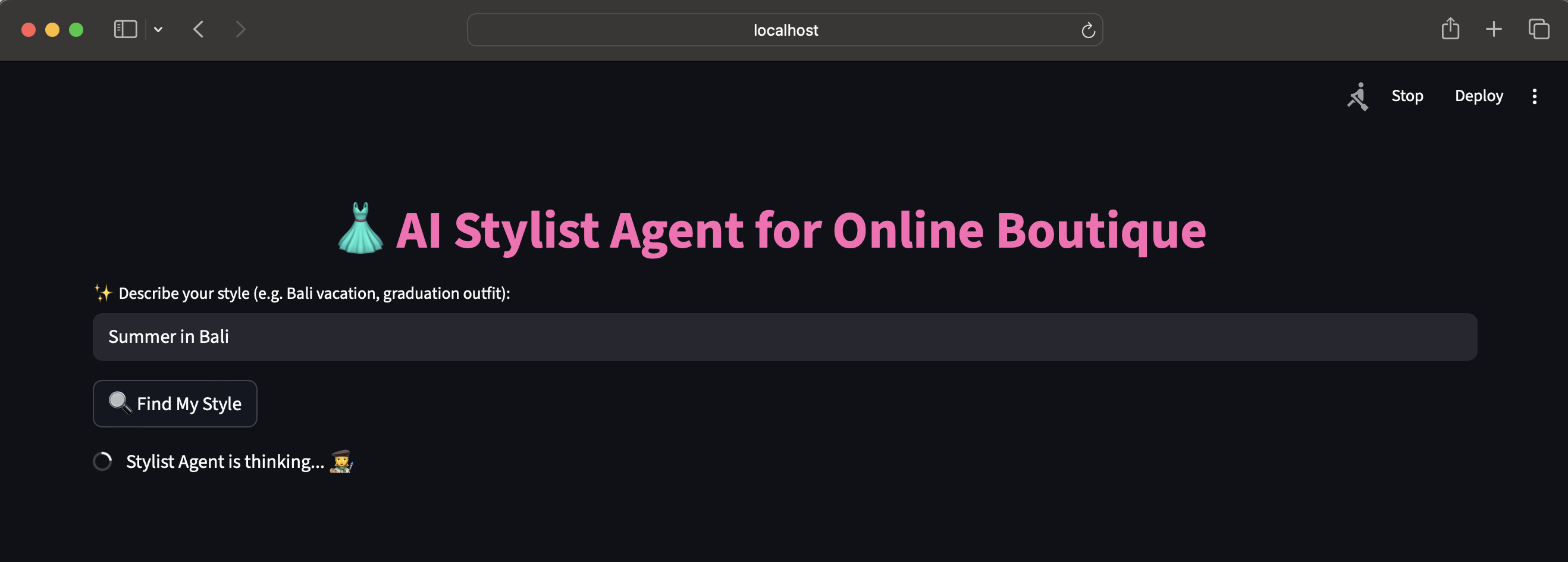
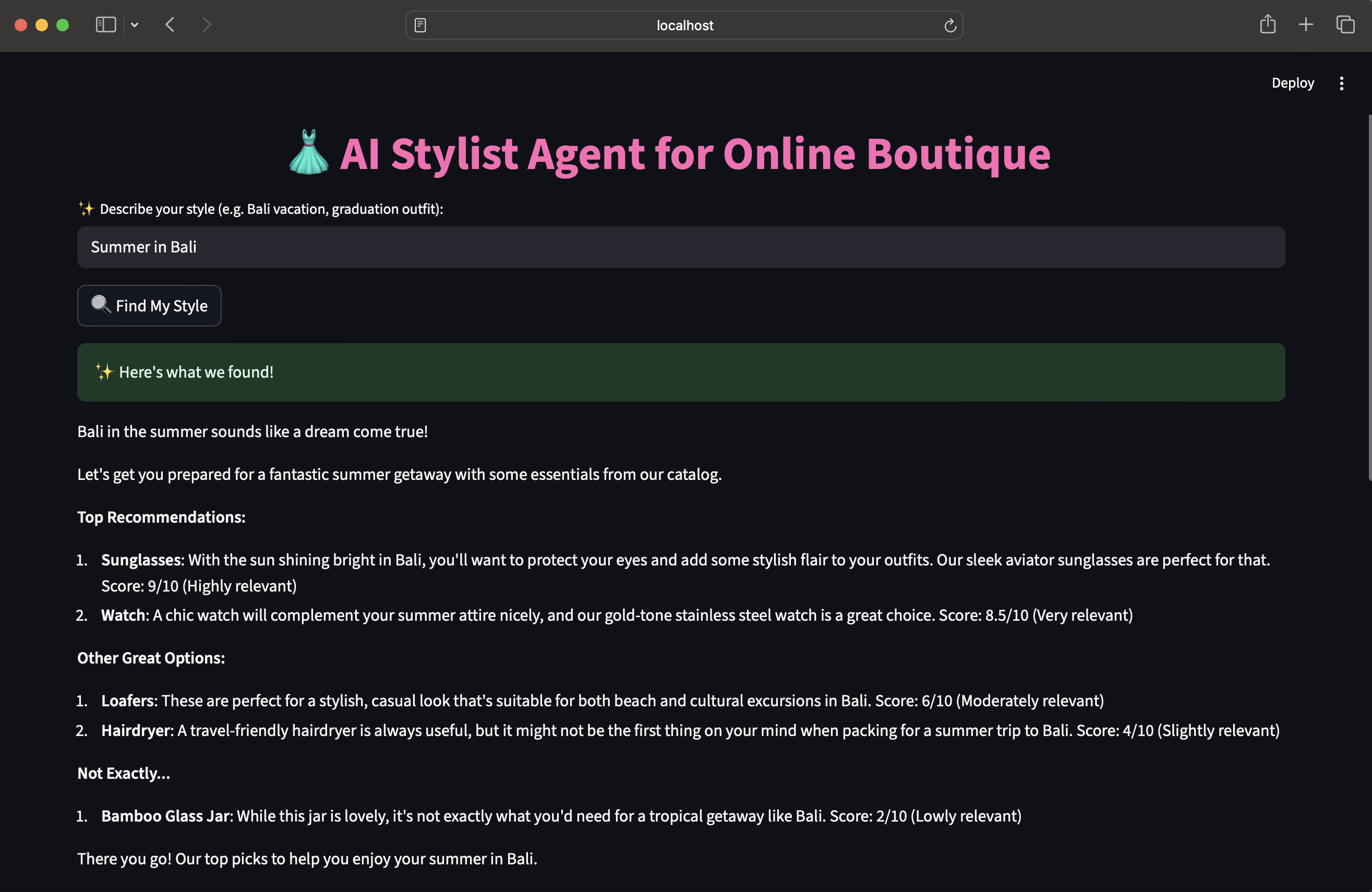
AI-Stylish Fashion Agent
1. Summary of Features and Functionality
The AI-Stylish Fashion Agent is an intelligent recommendation system designed to enhance the Google Online Boutique microservices application. Instead of relying on simple keyword searches, our agent functions as an AI-powered stylist, allowing users to describe a mood, event, or "vibe" to receive personalized and context-aware fashion recommendations.
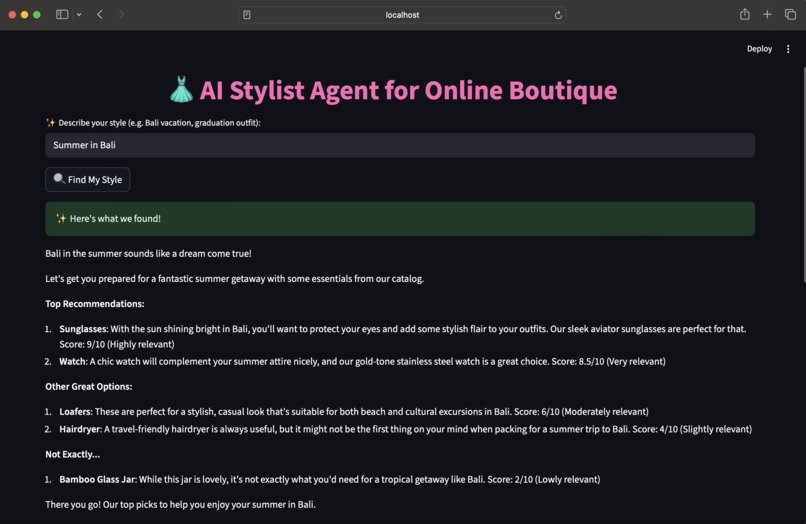
The core functionality is powered by a Retrieval-Augmented Generation (RAG) architecture. A user's natural language query (e.g., "Summer in Bali") is first converted into a mathematical embedding. This embedding is used to perform a semantic search against a specialized Pinecone vector database containing the boutique's entire product catalog. The most relevant products are "retrieved" and, along with the original query, are passed as context to a powerful Large Language Model (LLM). The LLM "generates" a final, conversational recommendation, explaining why each item is a good fit and creating a curated look for the user.
Key Features
- Intelligent Vibe-Based Recommendations: Provides outfit suggestions based on descriptive, abstract queries rather than just product names or categories.
- Cloud-Native AI Integration: The system is built entirely on Google's
GeminiAPI, leveraging its powerful models for both embedding and generation tasks. - Efficient Vector Search: Leverages
Pineconefor a high-speed vector database for real-time semantic search, ensuring quick and relevant product retrieval. - Seamless Microservice Integration: The agent integrates cleanly with the existing
Google Online Boutiqueplatform by fetching product data directly from itsgRPCendpoint.
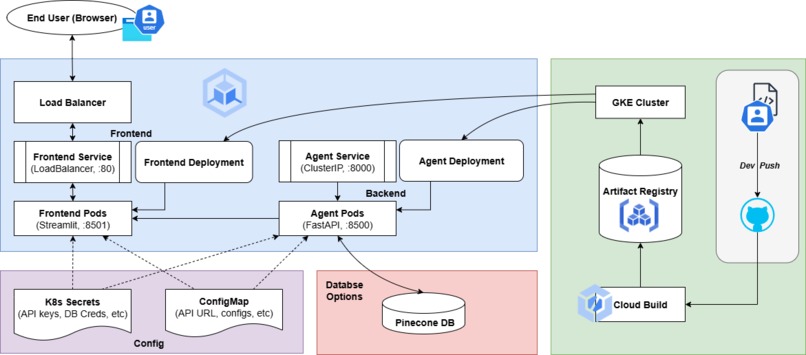
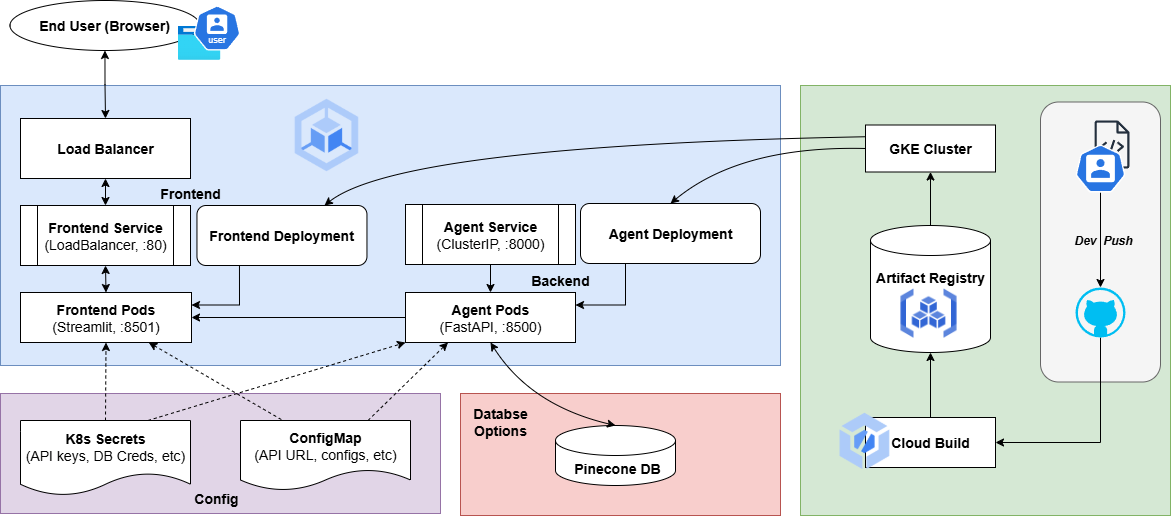
2. Architecture Overview
The system follows a modern microservice architecture designed for scalability and separation of concerns.
The user interacts with a Streamlit web frontend, where they enter their style query. The frontend sends an API request to the FastAPI backend microservice (the "ragagent"). The agent service receives the query, generates an embedding, and queries the Pinecone vector index to find the most relevant products. The retrieved product data and the user's query are formatted into a detailed prompt for the Gemini 2.5 Flash generative model. The LLM generates a user-friendly, conversational recommendation which is returned to the frontend and displayed to the user.
This entire process is supported by an initial data ingestion script (db.py) that populates the Pinecone database by connecting to the existing Online Boutique's gRPC Product API.

2.1 Deployment on GKE
After building and containerizing the AI Fashion Agent, the next big step was deploying it to Google Kubernetes Engine (GKE). This allowed the entire system (frontend, backend, and AI inference service) to run seamlessly in the cloud with load balancing and autoscaling.
Each service in the project: the FastAPI backend, the Streamlit frontend, and the AI model service; were packaged as a Docker image, and after testing locally with Docker Compose, the images were tagged and pushed to Google Artifact Registry.
The frontend and backend each ran in their own set of pods. The frontend pods served the Streamlit interface to users, while the backend pods handled AI inference requests, connecting to Pinecone for semantic search and Gemini for generative recommendations. A Load Balancer managed external access, routing user traffic efficiently to healthy frontend pods, while backend requests flowed internally through Kubernetes services.
The deployment was built with scalability in mind. The backend and frontend service could automatically scale up when multiple users started generating fashion recommendations at once and scale down during low traffic.
From a DevOps perspective, everything flowed smoothly through Cloud Build and Artifact Registry, forming a mini CI/CD loop. Any code changes could be pushed to the repository, automatically built into new images, and rolled out to the cluster through continuous deployment.
3. Technologies Used
- Backend: The core AI agent is a microservice built with
FastAPI. - Frontend: A user-friendly and interactive web interface was rapidly developed using
Streamlit. - AI / Machine Learning:
- Generative Model:
Google Gemini 2.5 Flashis used for the final recommendation generation step. - Embedding Model: Google's
embedding-001is used to create embeddings for all product and query text. - Vector Database:
Pineconeis used to store, index, and search through the product embeddings.
- Generative Model:
- Data Integration:
gRPCis used to communicate with theProductCatalogServiceof the Online Boutique to fetch product data. - Deployment & Infrastructure:
Docker&kubectlare used to fully containerize and orchestrate both frontend and backend services.
4. Data Sources
The AI-Stylish Fashion Agent is designed to work exclusively with the data from the pre-existing Google Online Boutique microservices application. No external data was used.
The data ingestion process is handled by a dedicated Python script (db.py). This script connects to the ProductCatalogService via its gRPC API to extract the entire list of products, including their names and descriptions. Each product's textual data is then converted into a vector embedding and upserted into the Pinecone index along with essential metadata (ID, name, description, price). This ensures our AI agent's knowledge base is a direct and accurate reflection of the boutique's current inventory.
5. Findings and Learnings
- The Power of RAG for E-Commerce: The RAG pattern is exceptionally effective for e-commerce, grounding the LLM in the available product catalog, preventing hallucinations, and providing actionable recommendations.
- Microservices for AI Augmentation: Building the AI agent as a separate, containerized microservice allowed adding a transformative feature without disrupting existing core services.
- Power of a Unified AI Ecosystem: Building the entire AI workflow on Google's models (
embedding-001andGemini 2.0 Flash) created a streamlined and highly efficient system. It simplified development and ensured seamless compatibility between the embedding and generation stages. - Rapid Prototyping with Modern Tools:
StreamlitandFastAPIallowed for fast development of a polished prototype within the hackathon time constraints. - The "Last Mile" is Conversational: The LLM’s ability to weave search results into a natural narrative turned the system into a true AI stylist rather than just a search engine.





Log in or sign up for Devpost to join the conversation.