-
-
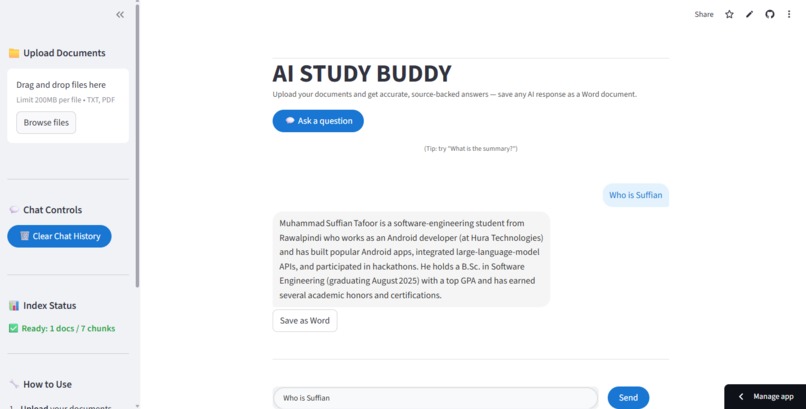
Main Screen
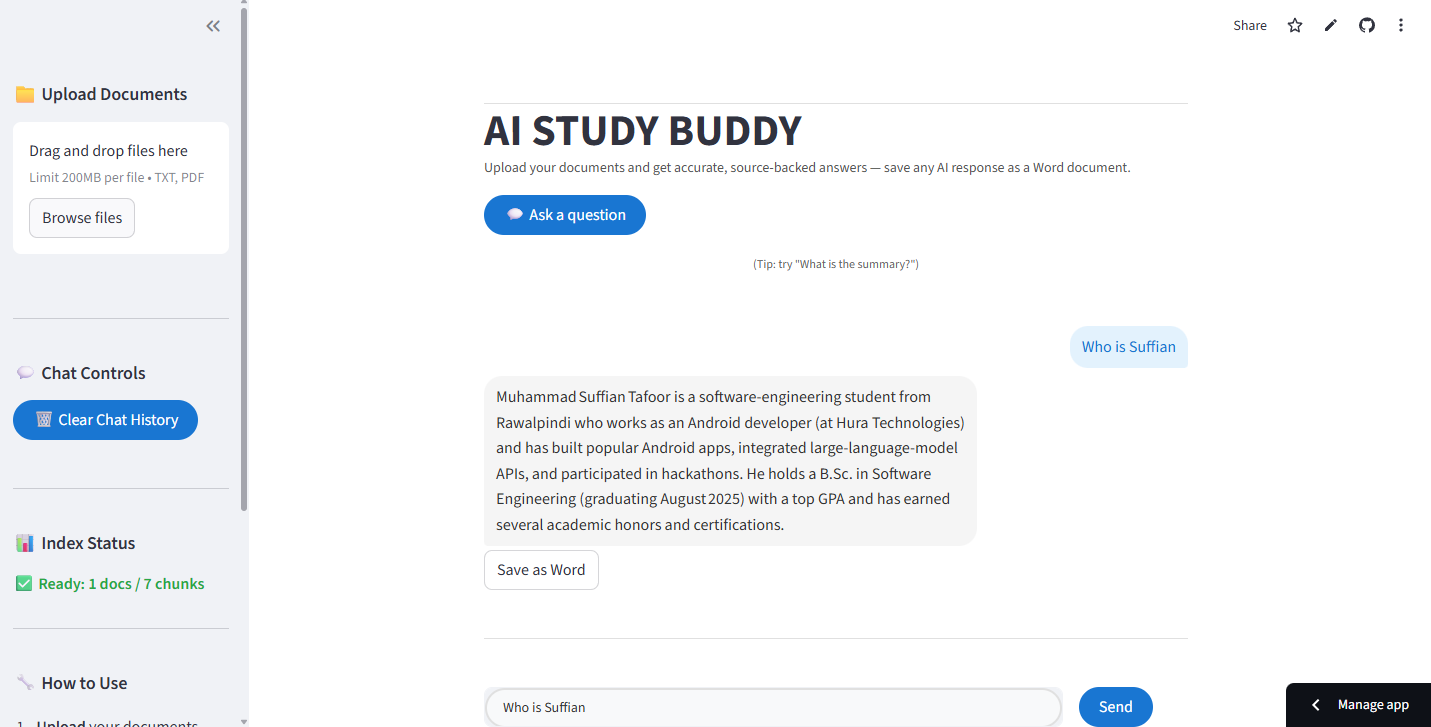
About the Project
AI Study Buddy is a lightweight Retrieval-Augmented Generation (RAG) assistant built with Streamlit.
It allows users to upload TXT or PDF files, index them using embeddings and FAISS, and ask questions about the content.
The app retrieves the most relevant chunks and generates accurate, context-grounded answers using a Groq LLM.
Each AI reply can be exported as a Word document (.docx) for sharing or note-taking.
Its a Track 1: AI Visibility & Prompt Discovery project
What Inspired the Project
I wanted a fast, private, and grounded study companion — like asking a knowledgeable colleague about your own documents.
Generic LLM demos often suffer from:
- Hallucinations without context
- Inconvenient copy/paste workflows
- Always-online, centralized data handling
So, I built a simple, local RAG app focused on:
- Answers from your uploaded files only
- One-click .docx exports
- A clean, approachable Streamlit UI
Key Learnings
- Retrieval reduces hallucinations and improves factual accuracy.
- Sentence-transformers (all-MiniLM-L6-v2) are efficient for short-text semantic search.
- Learned how FAISS enables fast similarity search.
- Gained experience with Streamlit session state, UI toggles, and file handling.
- Discovered PyPDF2’s limitations for scanned PDFs (future OCR integration needed).
- Implemented automated Word file export with python-docx.
How It Works (High-Level)
Architecture
- Frontend: Streamlit app (chat UI, upload, export)
- Ingestion: PyPDF2 for PDFs, text reader for TXT
- Chunking: RecursiveCharacterTextSplitter (size=500, overlap=50)
- Embeddings: sentence-transformers (HuggingFaceEmbeddings)
- Vector store: FAISS (in-memory)
- Retrieval: top-k (k=3) chunks → context-constrained Groq LLM query
- Export: .docx generation via python-docx + st.download_button
Prompt Design
Prompts explicitly instruct:
“Provide only the final answer. Do not include chain-of-thought or hidden reasoning.”
Post-processing ensures clean, readable responses.
Challenges and Solutions
HTML/JS vs Streamlit components
- Problem: Custom HTML buttons couldn’t trigger file pickers reliably.
- Solution: Used native Streamlit buttons + session state toggles.
PDF Extraction Quality
- Problem: PyPDF2 fails on image-based PDFs.
- Solution: Added warning and noted OCR as a future enhancement.
Memory and Persistence
- Problem: FAISS index stored only in memory (lost on reload).
- Solution: Kept in session for prototype; disk persistence planned.
Reducing Hallucinations
- Problem: LLMs can still fabricate info.
- Solution: Tight prompt control and retrieval-only context.
Export Fidelity
- Problem: Wanted metadata and citations in Word exports.
- Solution: Basic export works; structured metadata planned next.
Conclusion
AI Study Buddy proves how a small RAG-based app can deliver accurate, document-aware answers with privacy and ease of use.
It emphasizes practical learning, user control, and a lightweight approach to applied AI.
Built With
- ai
- deployment-local
- huggingface-embeddings-(all-minilm-l6-v2)-apis/llm-groq-(for-fast-llm-processing)-file-handling-pypdf2
- langchain-(orchestration)-ai/nlp-sentence-transformers-(hugging-face)
- language-python-frameworks-streamlit-(ui)
- prompt
- python-docx
- reimagineweb
- streamlit
- torch-vector/search-faiss-(in-memory-vector-store)
- track1




Log in or sign up for Devpost to join the conversation.