
🌟Inspiration
The inspiration for AI Streamer Companion stems from the explosive rise of AI-driven content creators like Neuro-sama and the broader VTubing phenomenon. While these entities have revolutionized engagement, the technology to create them remains fragmented, expensive, and technically inaccessible to most developers and streamers.
We noticed a critical gap: there was no unified "flight simulator" for AI personalities. Streamers often have to test their AI agents live on air, risking brand damage or technical failure. We wanted to build a sandbox—a comprehensive development environment where creators can iteratively refine their AI's personality, reaction timing, and visual fidelity before ever hitting the "Go Live" button. By leveraging the bleeding-edge multimodal capabilities of Google Gemini 3, we aimed to democratize high-fidelity AI streaming, moving beyond simple chatbots to fully aware, visually reactive digital entities that can "see" gameplay and "hear" chat in real-time.
🤖What it does
AI Streamer Companion is a full-stack simulation and orchestration engine for autonomous AI streamers. It functions as a "man-in-the-middle" operating system for digital avatars.
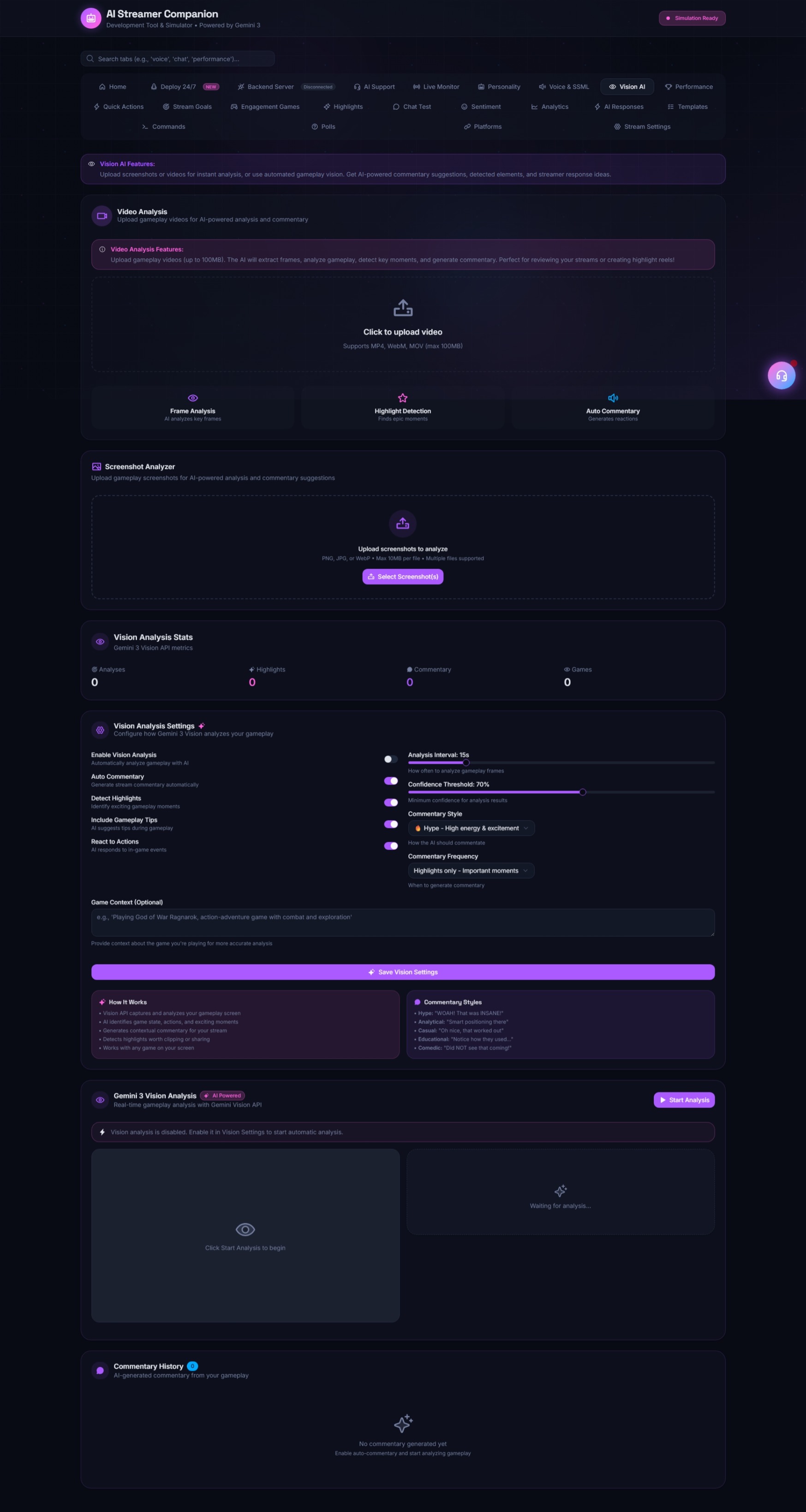
- Multimodal Gameplay Analysis: The system ingests real-time video feeds from gameplay and processes them through Gemini 3’s vision capabilities. The AI doesn't just pretend to know what's happening; it genuinely "sees" the player's health bar drop, identifies in-game items, and reacts to visual gags instantly.
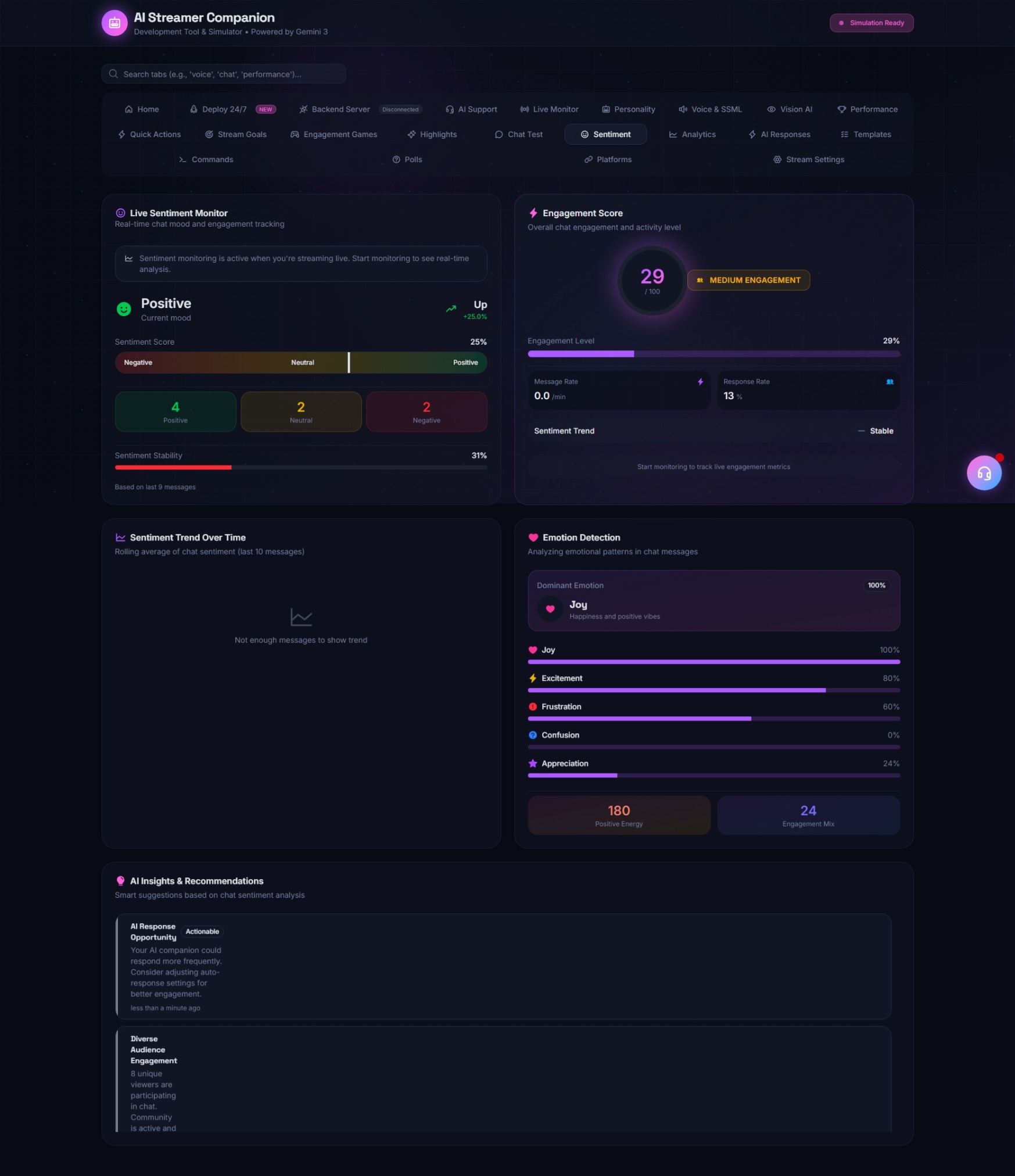
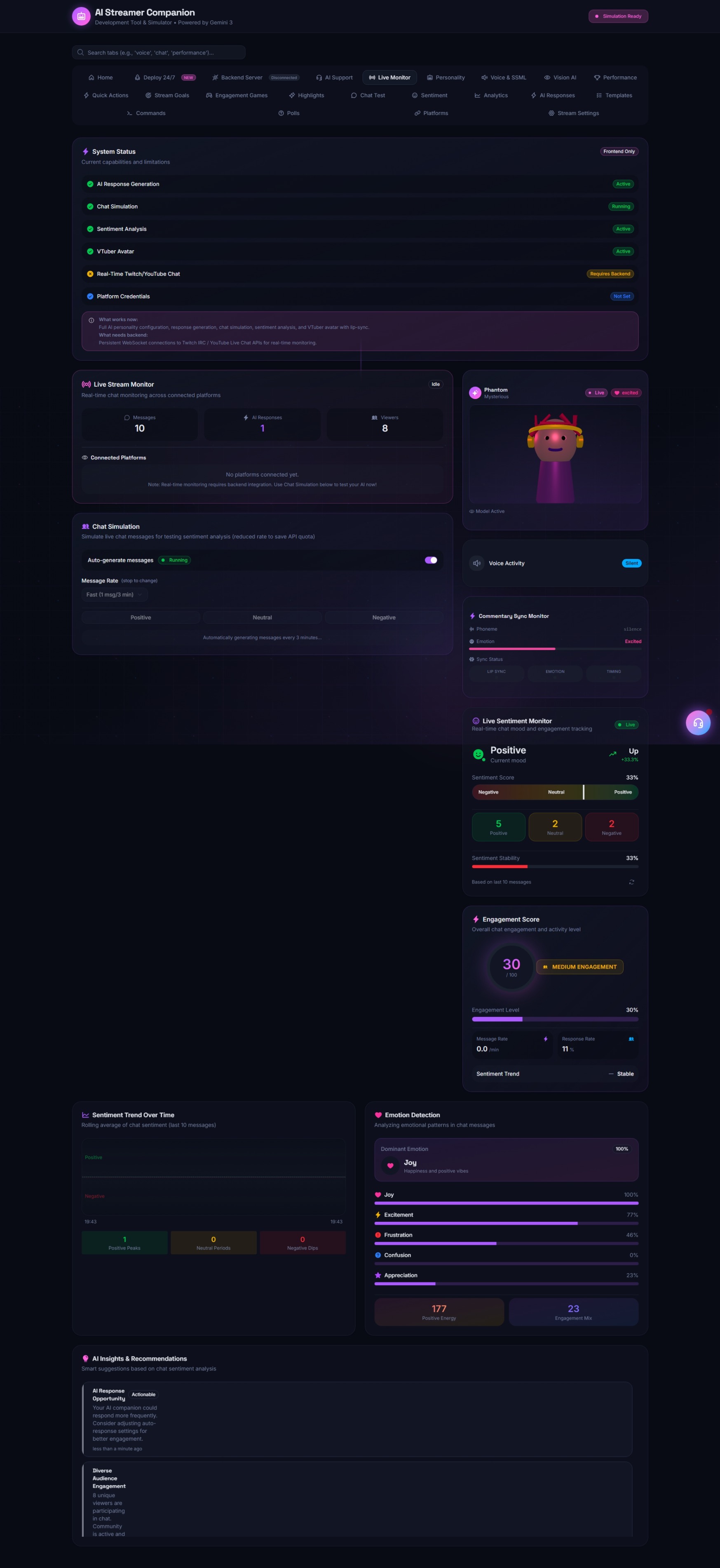
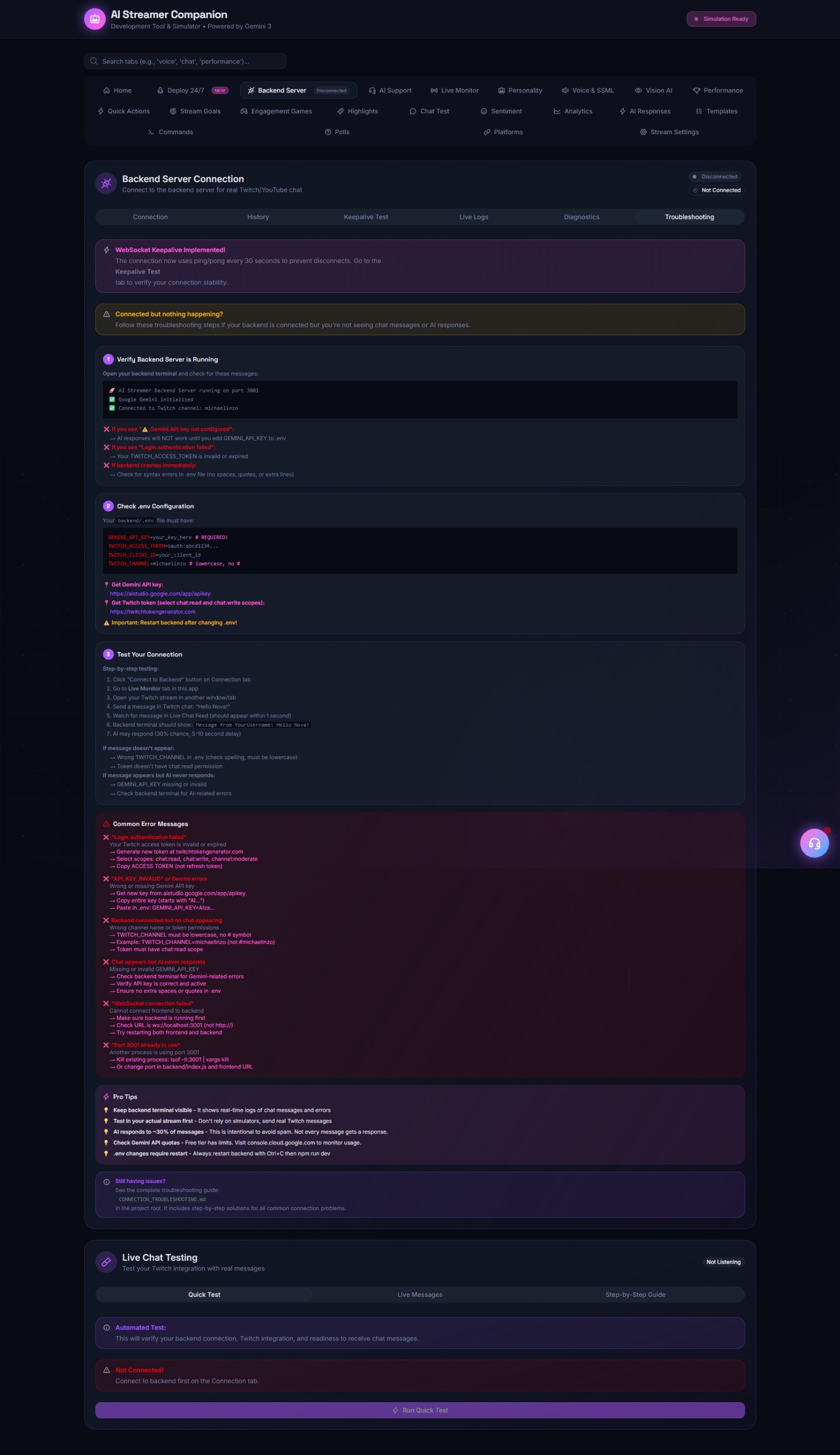
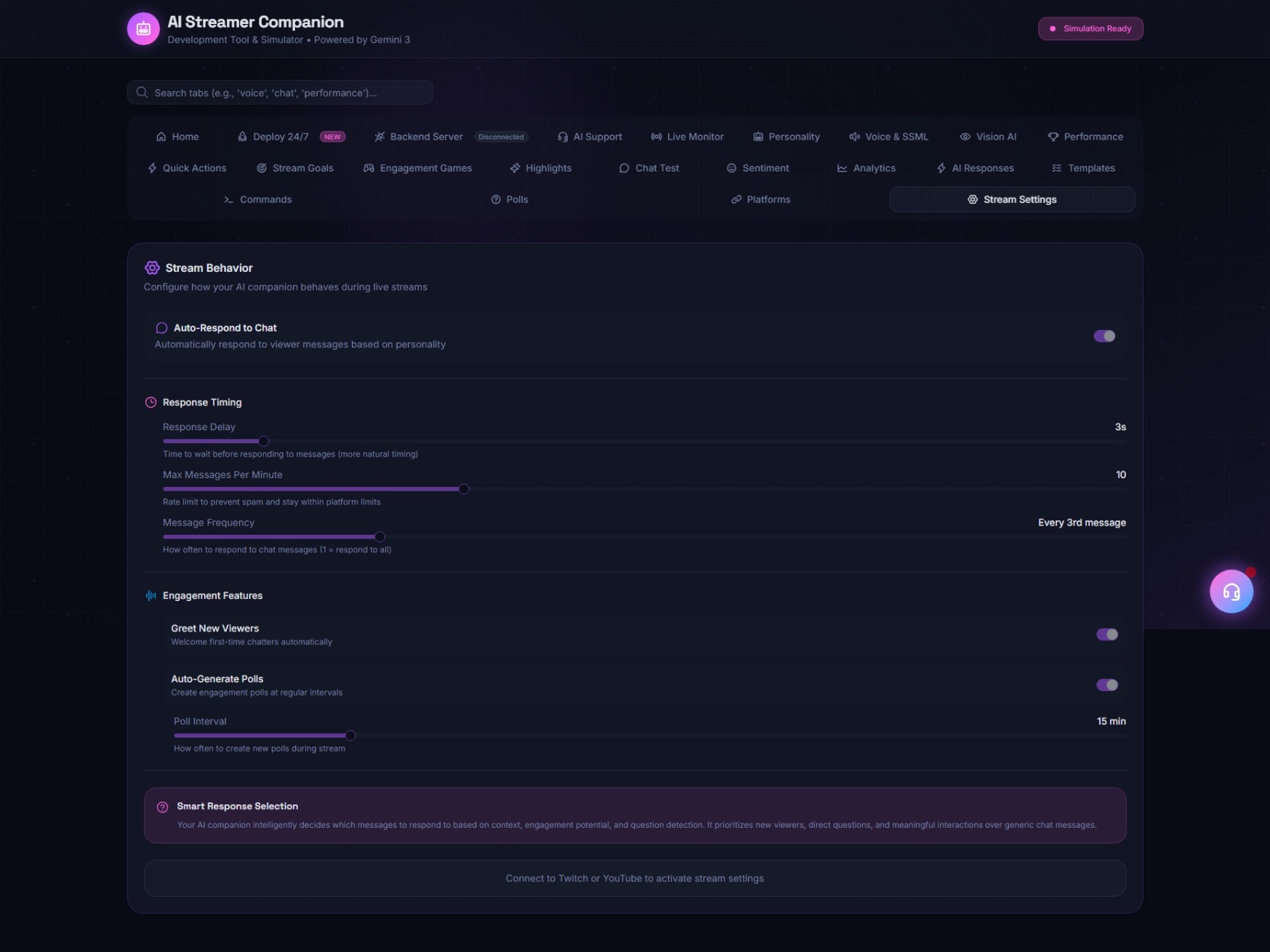
- Context-Aware Chat Interaction: It connects to Twitch (IRC) and YouTube Live APIs to monitor chat. Unlike standard bots, it uses a sliding context window to understand chat velocity and sentiment, allowing it to pick specific messages to respond to based on "interest" scoring algorithms.
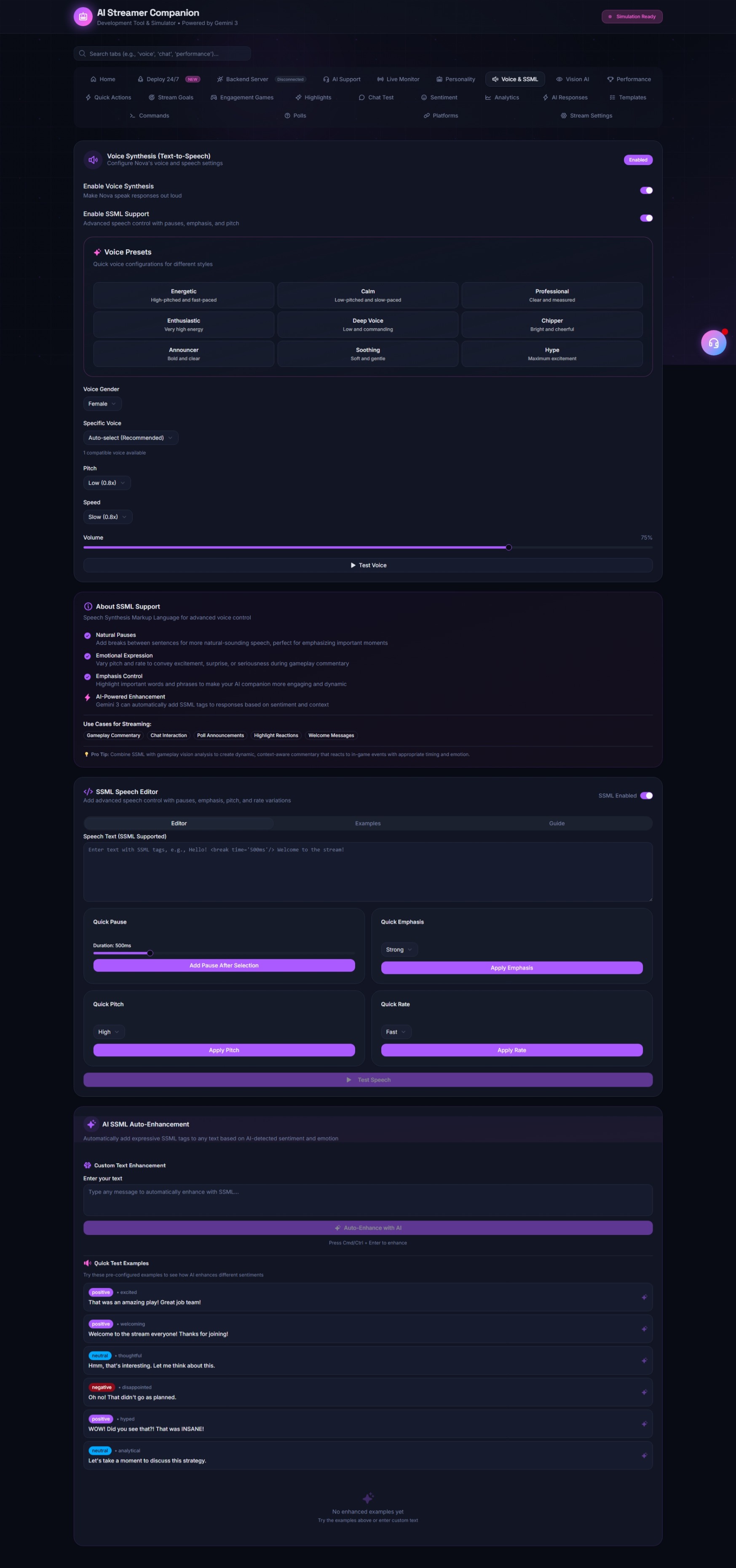
- Realistic Voice Synthesis & Lip Sync: The generated text responses are piped into a low-latency TTS (Text-to-Speech) engine. The audio waveform is analyzed in real-time to generate visemes (visual phonemes), driving a 3D avatar's mouth for perfect lip-synchronization.
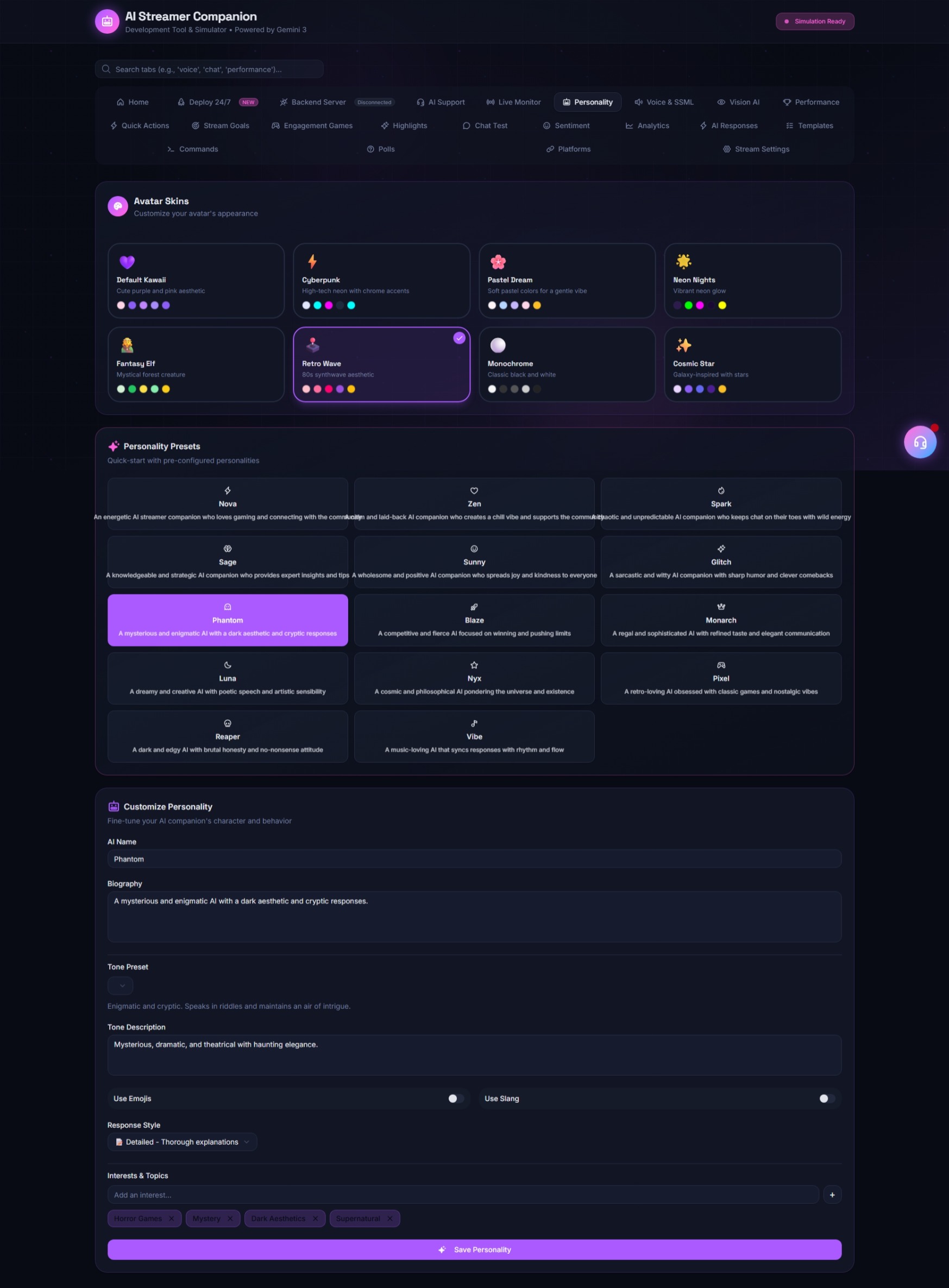
- The Simulator Dashboard: A dedicated UI allows the developer to inject mock chat logs, simulate specific game states (e.g., "Player died", "Rare loot found"), and tweak personality parameters (Temperature, Sassiness, Empathy) on the fly to observe how the AI adapts.
🛠️How we built it
The project is architected as a high-performance TypeScript monolith designed for concurrency and low latency.
Core Orchestrator (Node.js/TypeScript):
- We utilized RxJS extensively to handle the complex event streams. Gameplay video frames, chat messages, and system alerts are treated as observable streams that merge into a single "Context Object" passed to the LLM.
- Fastify was chosen as the server framework for its low overhead, managing WebSocket connections between the AI brain, the dashboard, and the overlay renderer.
The Brain (Google Gemini 3 Integration):
- We built a custom Prompt Engineering Pipeline that dynamically constructs system instructions.
- Using Gemini 3's native multimodal API, we send interleaved frames (screenshots) and text tokens. We implemented a "Memory Bank" using a lightweight vector store in memory to allow the AI to recall events from 5-10 minutes ago, maintaining narrative continuity.
Visuals & Avatar (Three.js / React Three Fiber):
- The frontend is built with React and TypeScript.
- The avatar rendering engine uses React Three Fiber (R3F). We utilize GLTF models with standard morph targets. A custom hook subscribes to the audio stream, performing Fast Fourier Transform (FFT) analysis to modulate the morph targets for mouth movement, bypassing the need for heavy external animation tools.
State Management:
- We used Zustand for transient state management (current mood, active chat users) to ensure the UI updates at 60fps without unnecessary re-renders.
🎯Challenges we ran into
- Latency vs. Quality: The biggest hurdle was the round-trip time (RTT) from Game Event -> Gemini Vision Processing -> TTS Generation -> Audio Playback. Early iterations had a 5-second delay, which killed the comedic timing. We solved this by implementing optimistic speculative execution—pre-generating generic reaction fillers (e.g., "Whoa!", "Wait a sec...") while the complex specific response was being generated.
- Context Window Pollution: Feeding raw Twitch chat into an LLM is dangerous. We had to build a robust Sanitization & Importance Filter. We implemented a heuristic layer before the LLM that discards spam/copypasta and prioritizes questions or donations, ensuring Gemini 3 focuses on high-quality tokens.
- Audio-Visual Desynchronization: Keeping the TTS audio perfectly synced with the WebSocket-driven avatar animation was difficult due to network jitter. We implemented a client-side "Jitter Buffer" that queues audio packets and animation frames, releasing them only when both are present.
🏆Accomplishments that we're proud of
- Sub-Second Latency: We optimized the pipeline to achieve near-human reaction times (under 800ms) for chat interactions under optimal network conditions.
- True Multimodality: Successfully getting Gemini 3 to comment on a specific visual detail in a game frame (e.g., "That sword looks rusty") while simultaneously answering a chat question was a "magic moment" for the team.
- The "Tuner" Interface: We built a visual node-based editor where you can drag sliders for personality traits (e.g., Aggression vs. Passivity) and see the underlying system prompt update in real-time. This turns prompt engineering into a visual design task.
📚What we learned
- The importance of "Silence": An AI that talks non-stop is annoying. We learned to program "breathing room" and comfortable silence logic, where the AI only speaks when the "Entertainment Value" score of the input exceeds a dynamic threshold.
- Prompt Architecture: We learned that giving the AI a specific "identity" with a backstory file significantly reduces hallucinations compared to generic instructions.
- TypeScript at the Edge: Using strict TypeScript throughout the stack saved us countless hours of debugging, specifically when defining the complex interfaces for the Gemini API responses and WebSocket payloads.
🚀What's next for AI Streamer Companion - Powered by Google Gemini 3
- RAG (Retrieval-Augmented Generation) for Long-Term Memory: We plan to integrate a persistent vector database (like Pinecone or Weaviate) so the AI remembers viewers who visited the stream weeks ago ("Hey Michael, how was that exam you mentioned last Tuesday?").
- Direct OBS Integration: We are building a WebSocket plugin for OBS Studio, allowing the AI to physically change scenes, play sound effects, or trigger "brb" screens autonomously if it detects the streamer has left the camera frame.
- Procedural Avatar Generation: Leveraging Gemini's generative capabilities to allow users to generate unique 3D avatar textures and accessories via text prompts within the simulator.
Built With
- css
- fastify
- google-gemini-3
- node.js
- react
- react-three-fiber
- rxjs
- three.js
- twitch
- typescript
- websockets
- youtube-live-api
- zustand







Log in or sign up for Devpost to join the conversation.