-
-
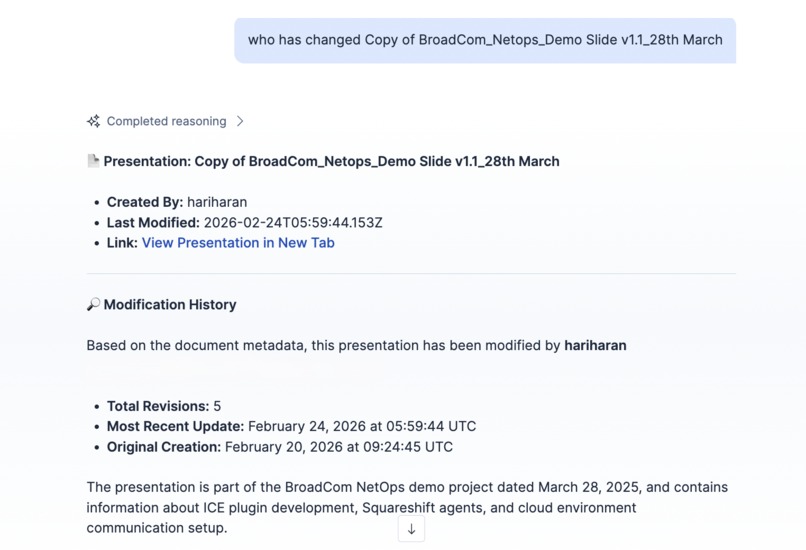
Track the version history and the modifications done by users on the files
-
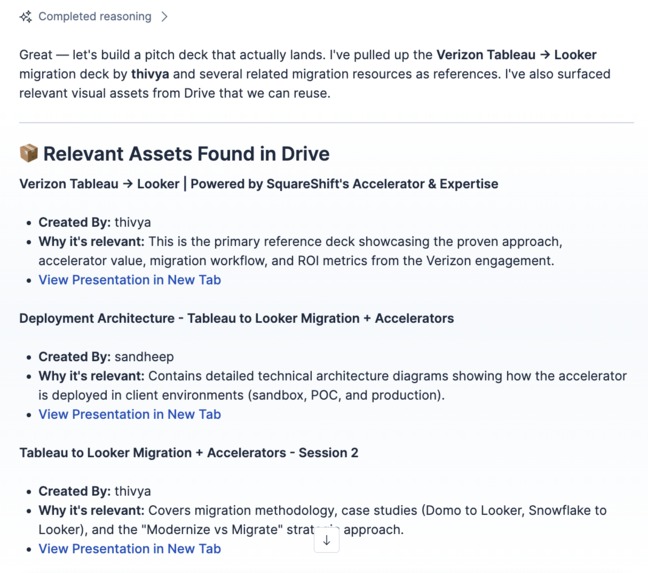
Semantic based retrieval from the drive files
-
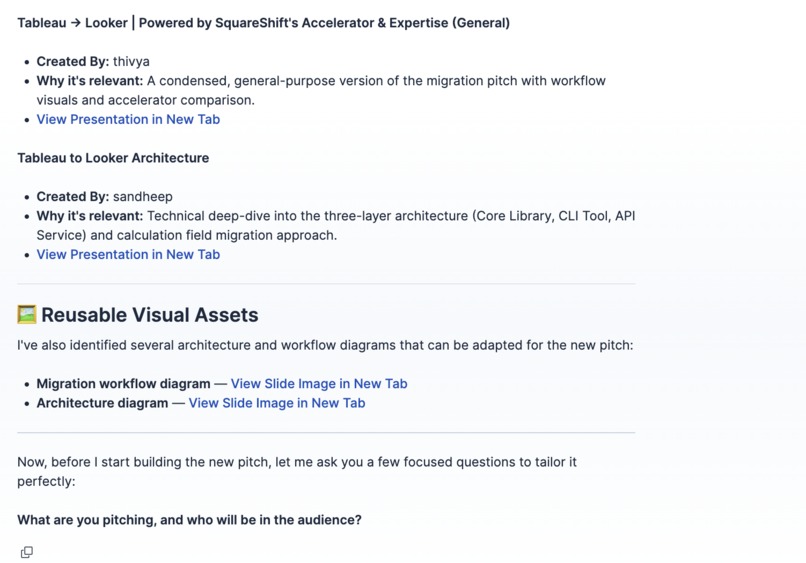
Image-vector based retrieval from existing slides
-
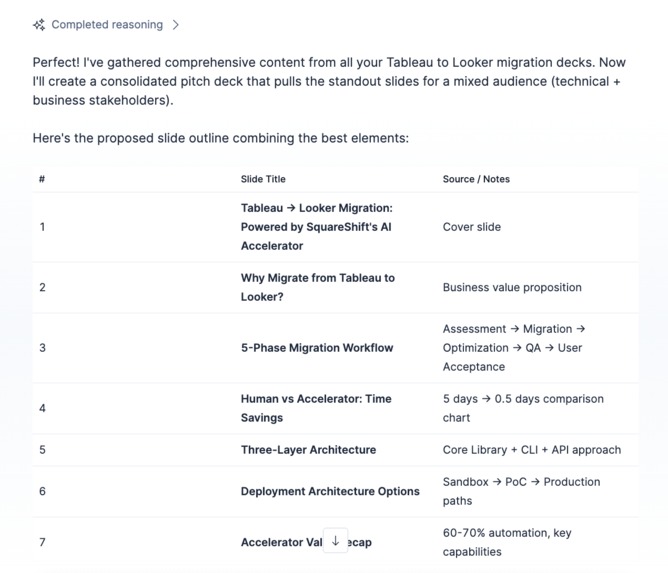
MCP based slide content curation from existing slides
-
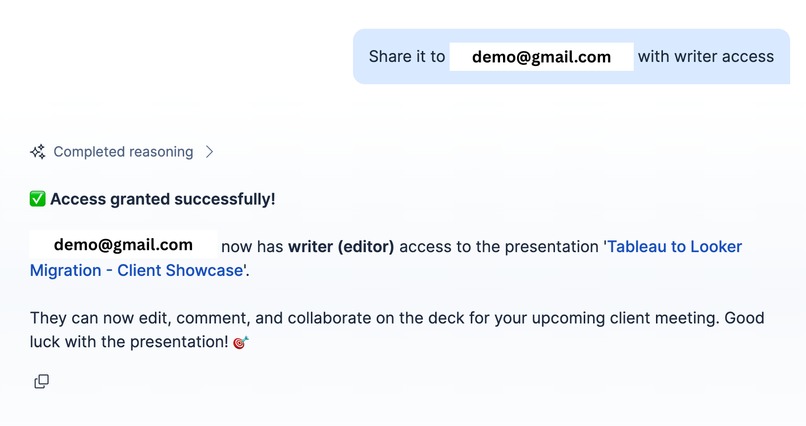
Provide or revoke or update the access for a file in drive for users
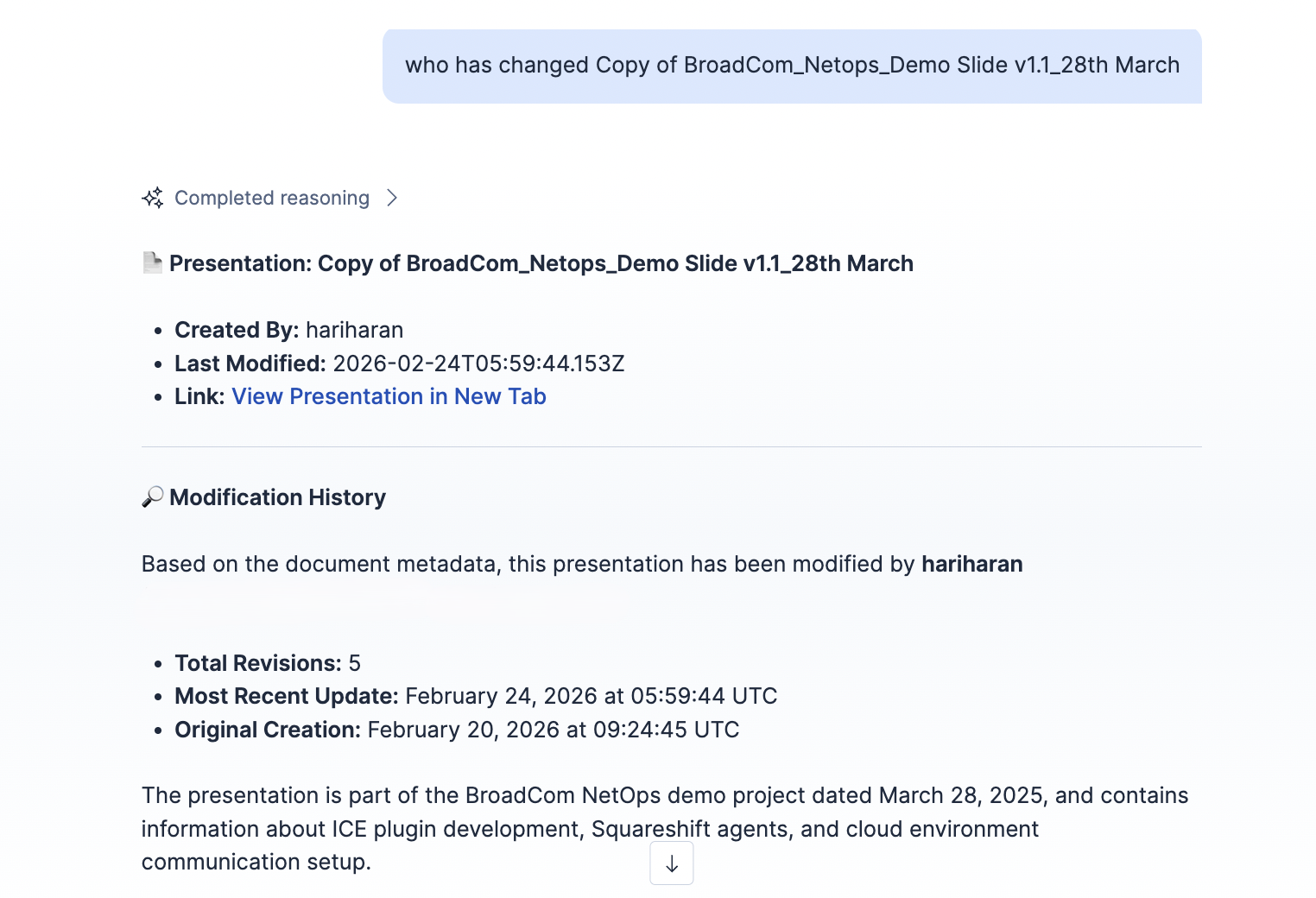
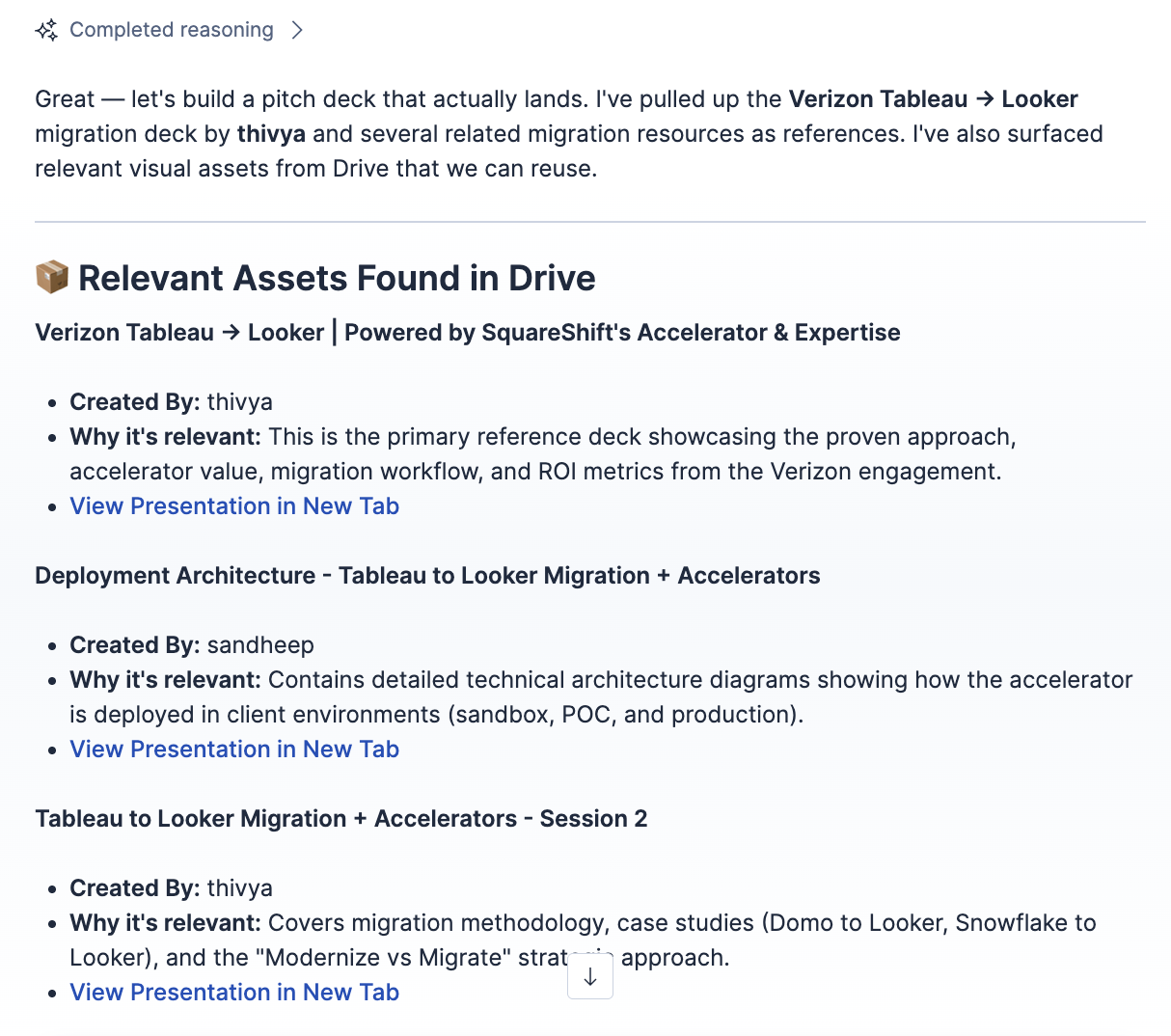
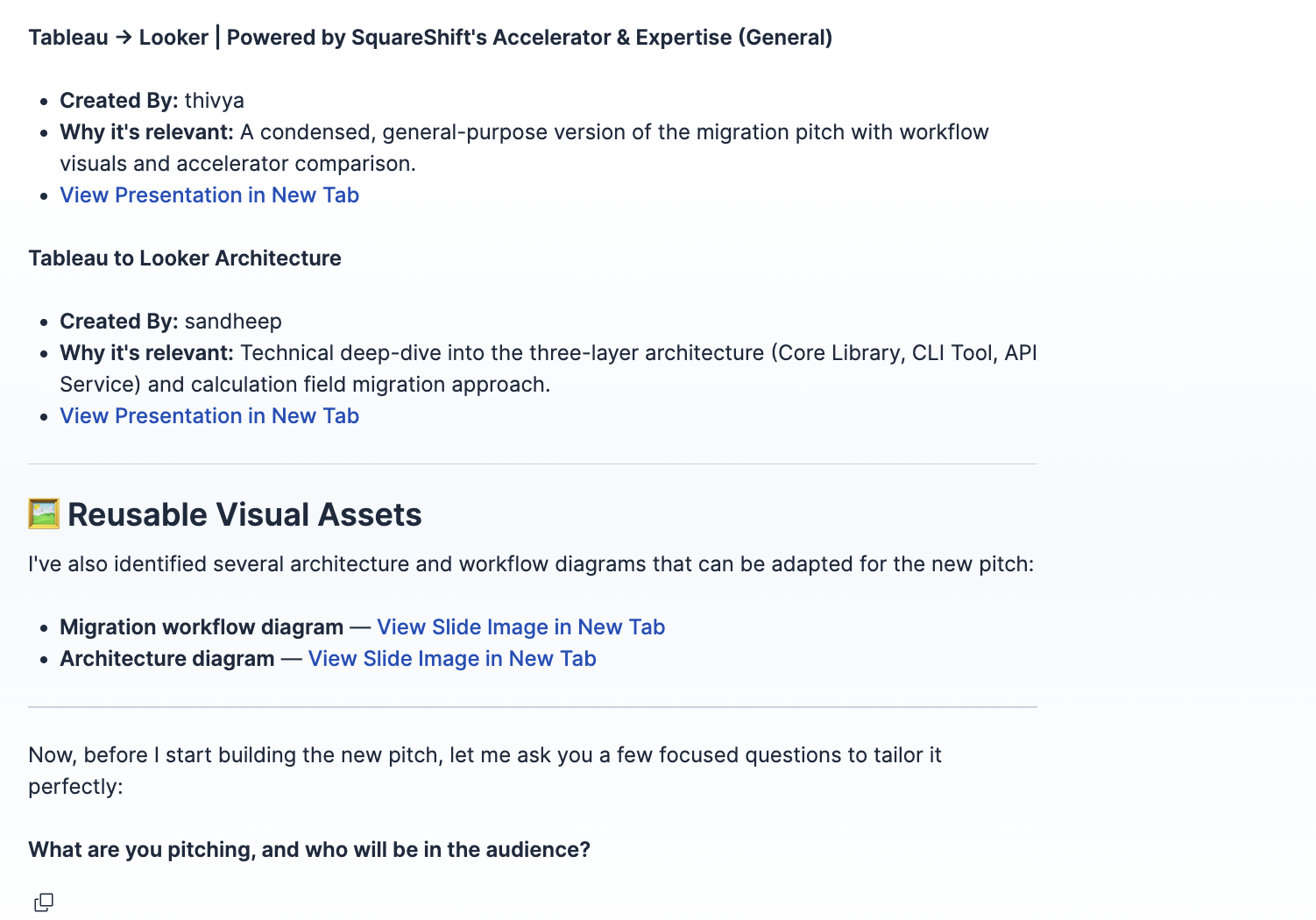
Inspiration
Every enterprise team we’ve worked with faces the same painful reality: hundreds of Google Drive presentations sitting silently in folders, impossible to search meaningfully, impossible to reuse quickly. People rebuild slides that already exist. Proposals get delayed because no one can find the right deck. New joiners have no way to discover what the company has already built.
We were inspired by a simple question — what if your entire presentation library could think? What if instead of remembering where a file lives, you could just describe what you need and have it found, assembled, or built for you in seconds?
That question became FrankenSlide.
What it does
FrankenSlide is a dual-agent platform built on Elastic that transforms how enterprise teams search, reuse, and create presentations.
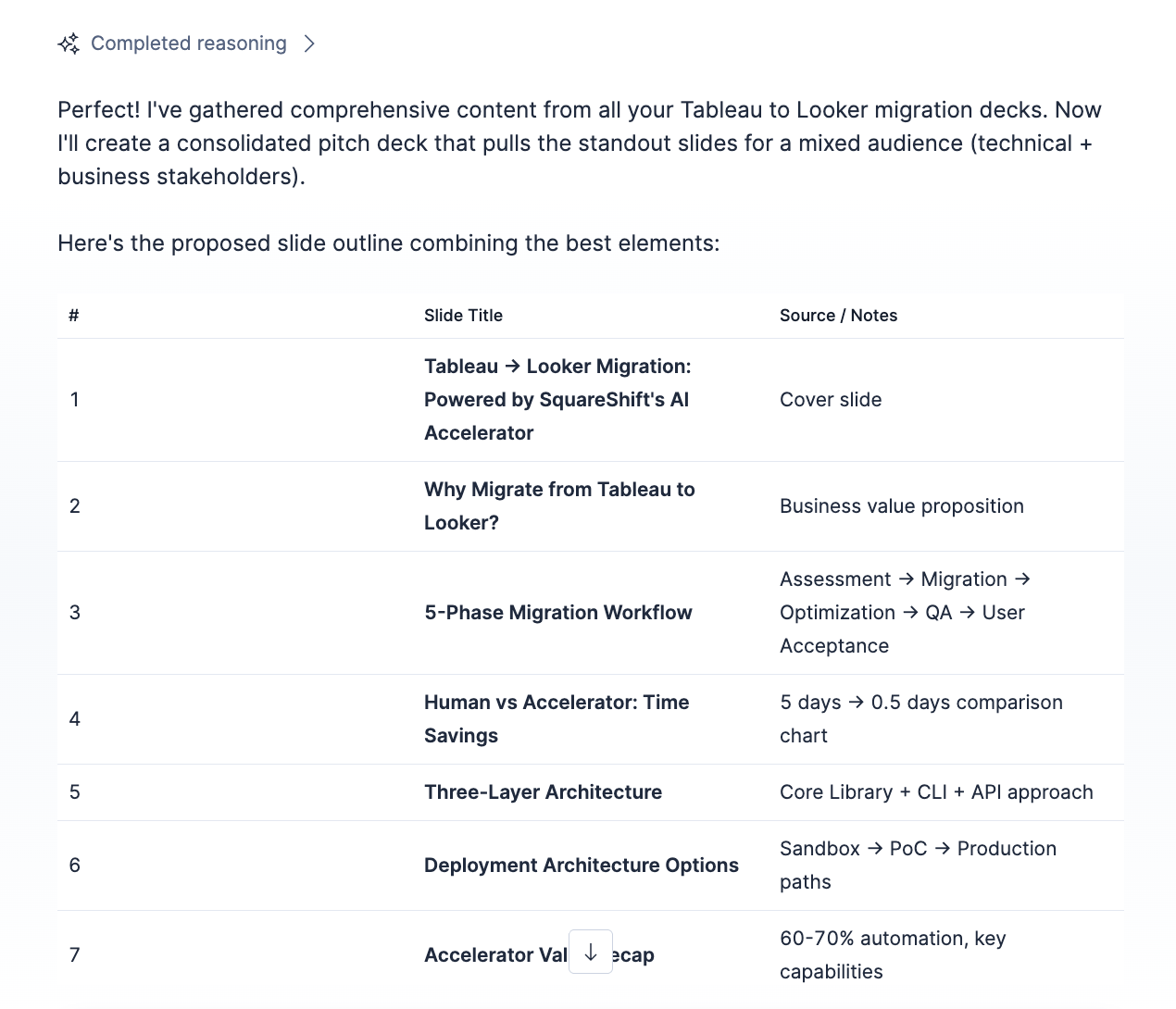
Agent 1 — Deck Hunter lets users semantically search across every Google Drive presentation in their organisation, surface the exact slides by meaning not just keywords, retrieve relevant visual diagrams, and generate fully authored new pitch decks through a guided AI conversation. It creates brand new content, manages access permissions, and delivers a ready-to-edit Google Slides link — all from a single chat interface.
Agent 2 — Slide Assembler takes a fundamentally different approach: zero content generation. It semantically finds the most relevant existing slides, scores, and ranks them by similarity, then triggers an automated workflow that uses Google AppScript to physically copy and assemble those slides into a new presentation — preserving every logo, font, and format exactly as originally approved. Built for teams where compliance, brand consistency, and auditability are non-negotiable.
Together, they cover every presentation scenario an enterprise team faces.
How we built it
- Elasticsearch as the core search and intelligence layer, using the native Google Drive Connector for ingestion and document-level security to enforce Drive permissions at query time
- Python enrichment pipeline that processes indexed presentations and
adds semantic embedding fields (
semantic_body,semantic_name) to enable hybrid BM25 + kNN vector search - Two custom ES|QL tools —
hackathon.list_slidesfor lightweight metadata discovery andhackathon.content_shrinkerfor scored, truncated semantic content retrieval — paired with animage_vector_searchtool for visual asset discovery - Elastic Agent Builder to orchestrate both agents with multi-step reasoning, tool chaining, mode detection, and PitchCraft conversation flows
- Custom MCP server (
node-deck-creator) built in Node.js exposing Google Slides API capabilities as agent tools — includingcreate_presentation_from_contentfor one-call full deck generation andbatch_update_presentationfor incremental slide editing - Google AppScript + Workflow Engine (Agent 2) to handle zero-generation
assembly — receiving slide IDs from the agent, copying slides via the
Slides API
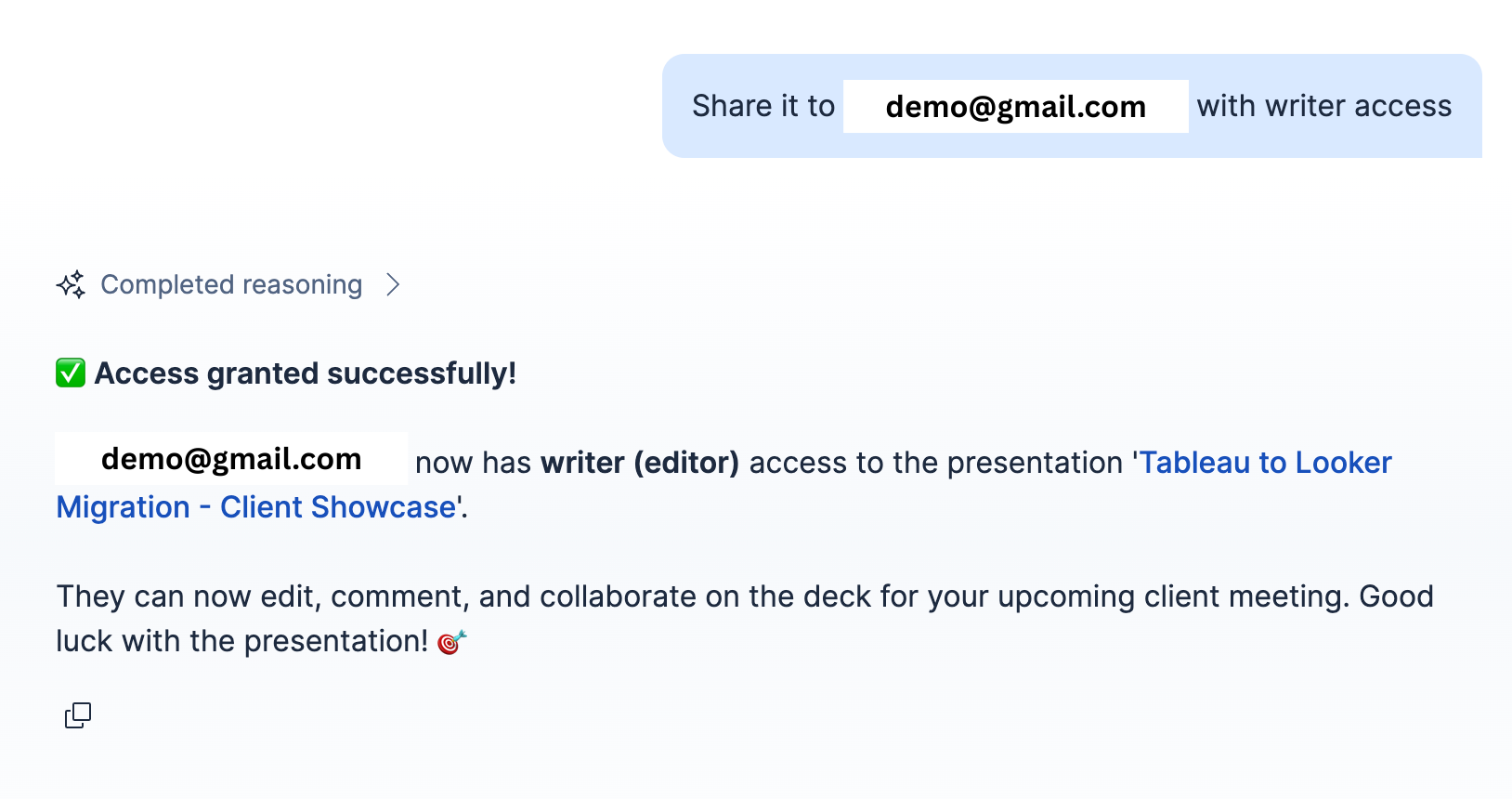
copyTo()method, and reordering them to match the user’s requested sequence automated_manage_drive_accesstool wired to the Drive Permissions API so users can grant, update, or revoke collaborator access directly from the agent chat UI
Challenges we ran into
- Metadata reliability from the Drive Connector — fields like
created_bywas inconsistently populated in the Elasticsearch index. We solved this by splitting retrieval into two dedicated tools: one purely for metadata and one purely for content, each optimised for its own purpose. - ES|QL limitations for summarisation — ES|QL is a retrieval and transformation language, not an inference engine. We had to architect a clean boundary where ES|QL handles fetching and pre-filtering, and the LLM handles understanding and synthesis.
- Preserving slide formatting in Agent 2 — getting AppScript to
faithfully copy slides, including embedded images, custom fonts, and
master layouts across different source presentations required careful
handling of the Slides API
copyTo()response and layout inheritance. - Agent mode detection — distinguishing between a retrieval intent, a PitchCraft creation intent, and a hybrid intent purely from natural language required iterative prompt engineering and explicit decision logic in the agent instruction set.
- Keeping the two agents architecturally separate while sharing the same Elasticsearch foundation without cross-contaminating their tool sets, response formats, and workflows.
Accomplishments that we’re proud of
- Built two fully functional, production-grade AI agents on Elastic in a single hackathon sprint — each with its own architecture, workflow, and a distinct value proposition
- Achieved semantic slide-level search across entire Drive repositories, not just filename matching — a meaningful leap beyond what Drive search natively offers
- Delivered a zero-generation assembly pipeline via AppScript that preserves 100% of the original slide formatting, making it genuinely compliance-ready
- Built a live access management capability so users never need to leave the agent chat to share a deck with a collaborator
- Designed the entire system around document-level security, meaning users can only retrieve and reuse slides for which they already have permission to access in Drive — enterprise-grade from day one
- Created a Slide-Structure Extractor inside the agent that converts natural language pitch content into structured JSON and creates a full Google Slides deck in a single API call
What we learned
- Elasticsearch is far more than a search engine — with the right enrichment pipeline and hybrid retrieval strategy, it becomes a genuine AI knowledge layer for enterprise content
- Splitting tools by single responsibility (one for metadata, one for content) dramatically improved retrieval reliability and made the agent’s decision-making is cleaner and more predictable
- AppScript is an underrated automation layer for Google Workspace — combining it with an AI agent’s semantic understanding creates a powerful assembly pipeline that no off-the-shelf tool offers today
- The hardest part of building AI agents isn’t the model — it’s the tool design, retrieval architecture, and instruction engineering that determines whether the agent actually behaves reliably in production
- Two narrow, well-scoped agents outperform one bloated general agent — separating creation from assembly gave each agent a clear identity, cleaner failure modes, and a much sharper user experience
What’s next for FrankenSlide
- Speech-to-text search — letting users describe what they need verbally and triggering semantic retrieval from voice input
- Slide-level revision intelligence — surfacing which specific slides changed between versions, who changed them, and why
- Cross-repository ingestion — extending beyond Google Drive to SharePoint, Notion, and Confluence, so the platform covers the full enterprise content landscape
- Auto slide redesign — using generative AI to reformat assembled slides to a consistent template after Agent 2 copies them, bridging the gap between the two agents
- Analytics dashboard — showing which slides are most reused, which decks are most searched, and where content gaps exist in the library
- Multi-language semantic search — enabling global teams to search in their native language and retrieve slides regardless of the language they were originally authored in
Built With
- apps-script
- cloudrun
- elastic
- elastic-agent-builder
- esql
- gcp
- google-drive-api
- google-drive-connector
- google-slides-api
- image-embedding
- mcp
- natural-language-processing
- node.js
- python
- semantic-search
- workflow




Log in or sign up for Devpost to join the conversation.