-
-

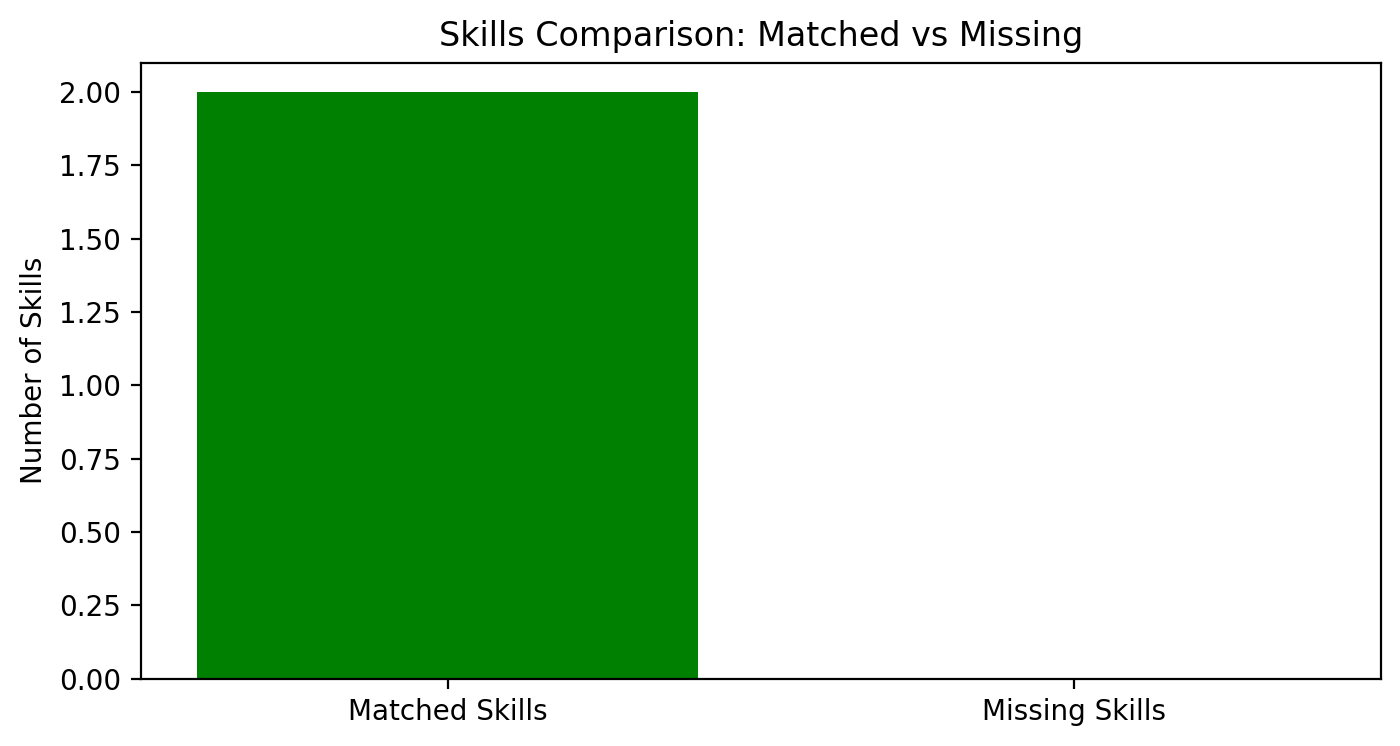
Skill analysis
-
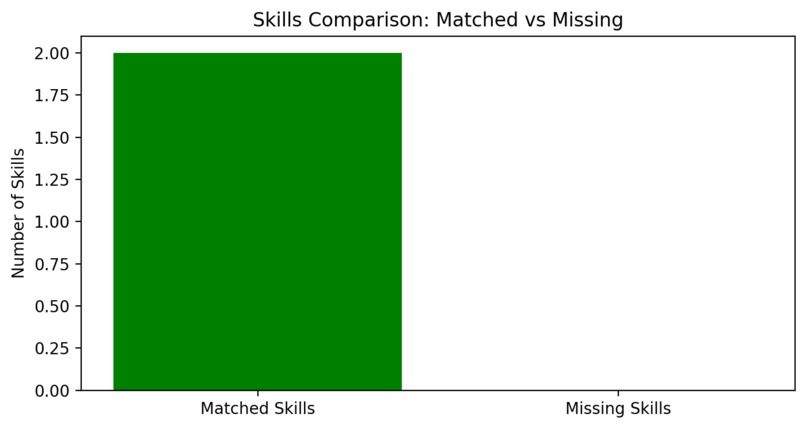
Matched vs missing skills graph
-
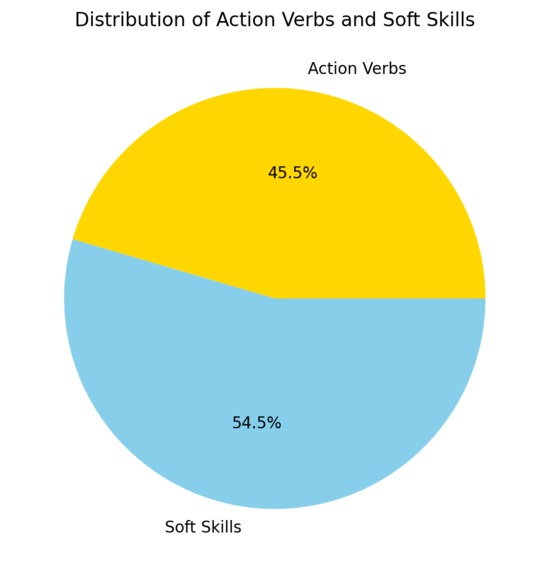
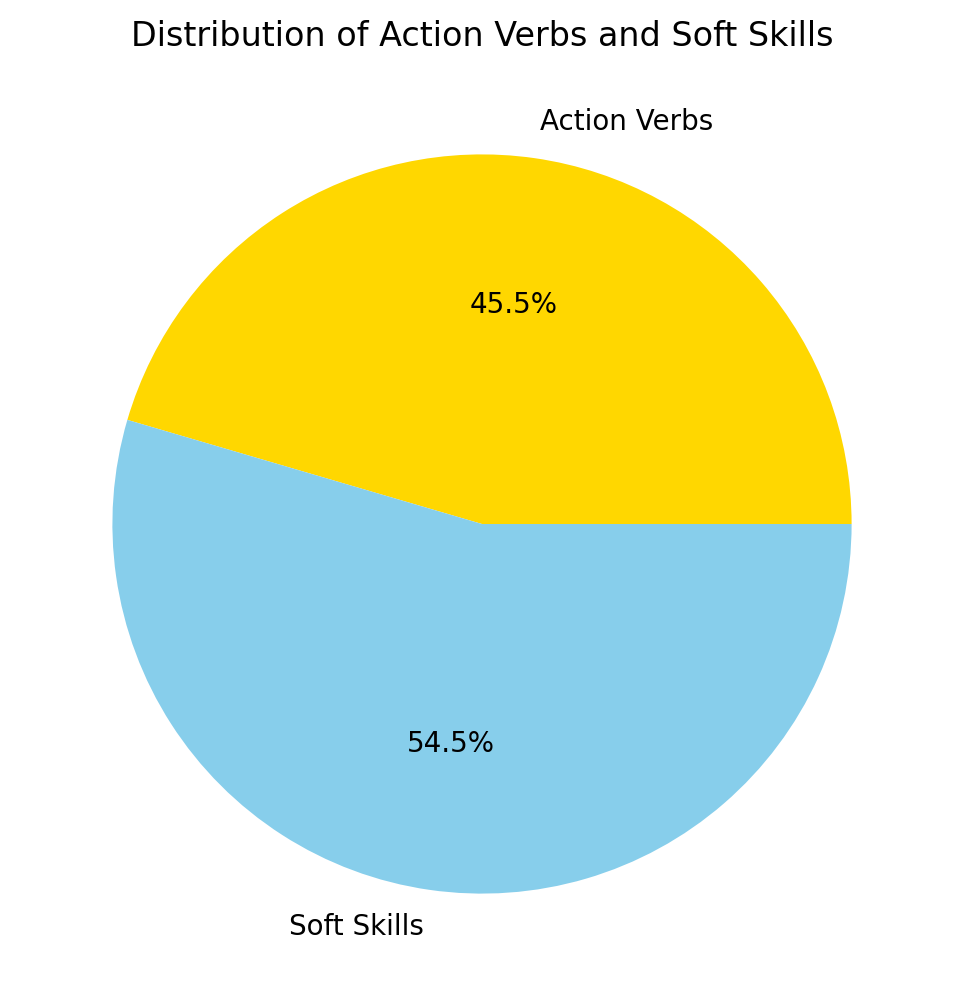
Distribution of both
-

Action Verbs and soft skills analysis
-
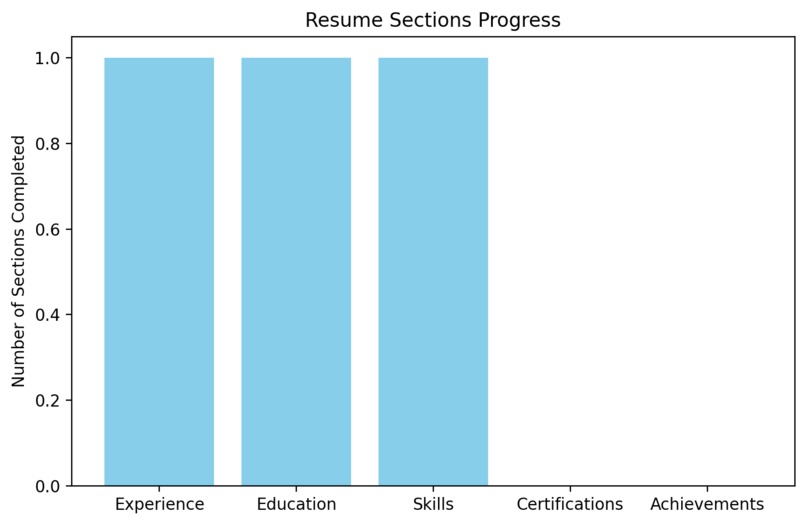
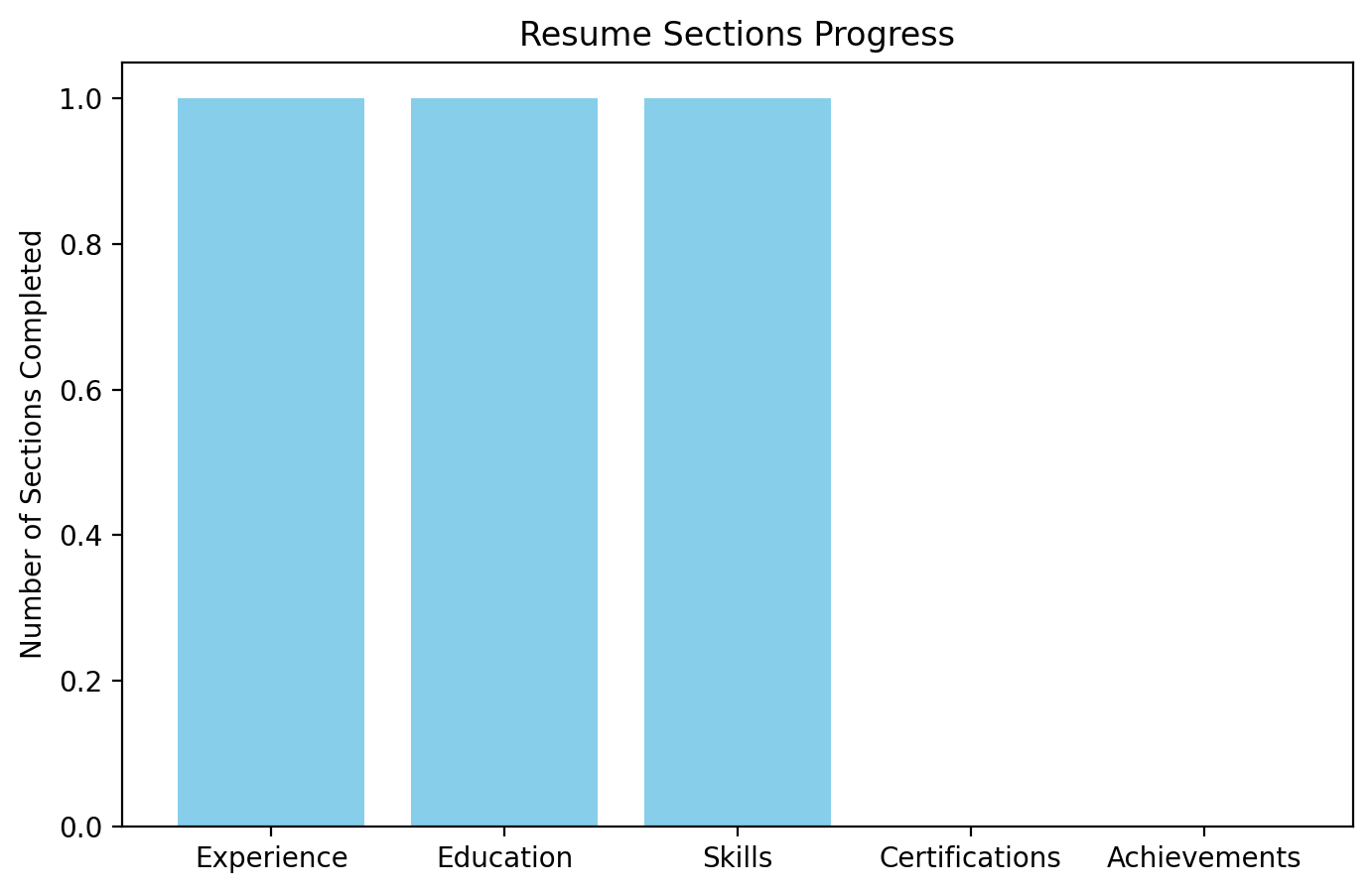
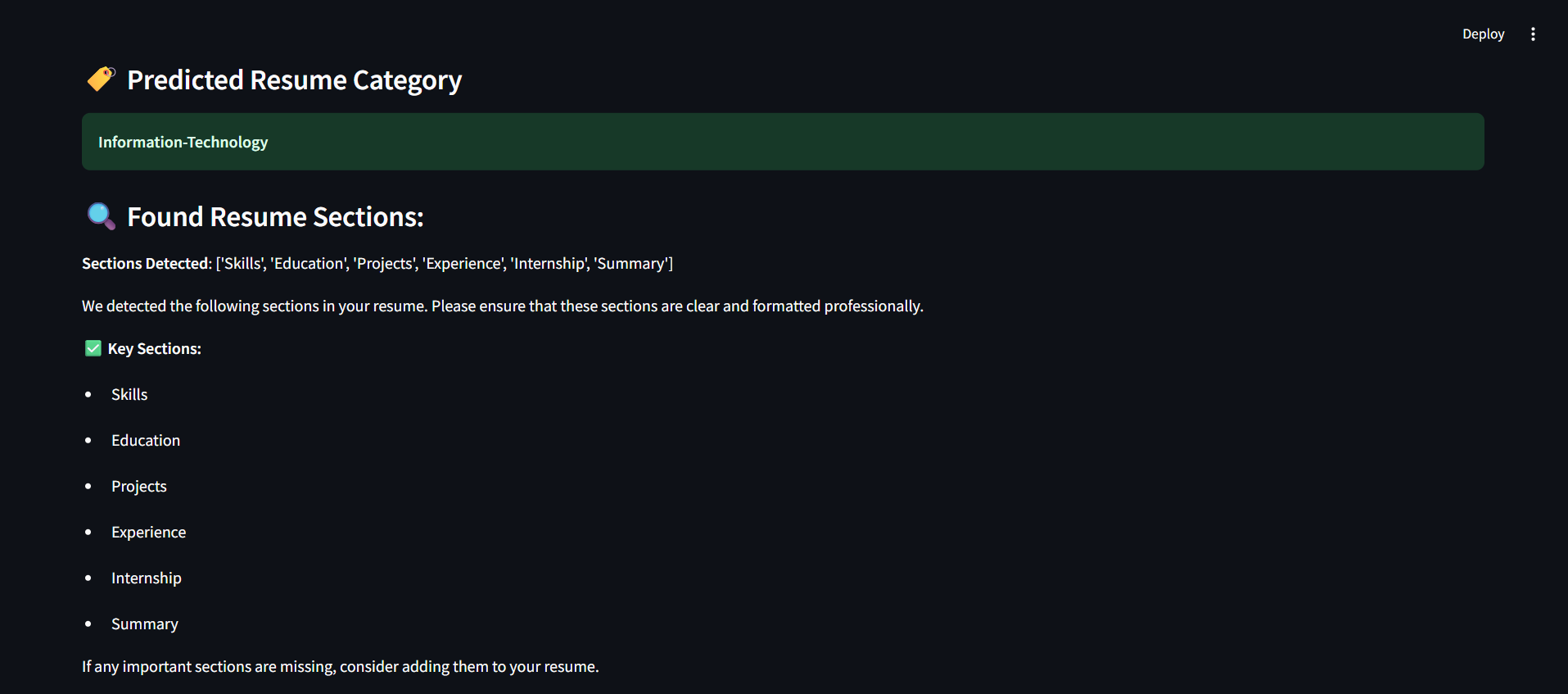
Found Sections and missing
-
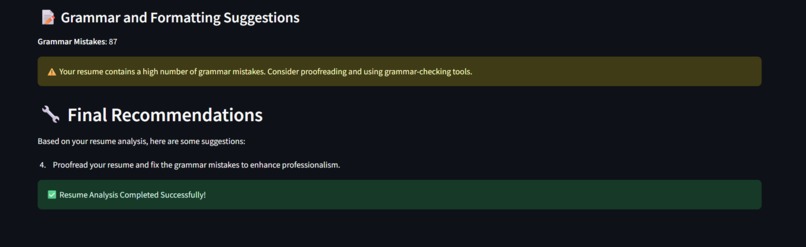
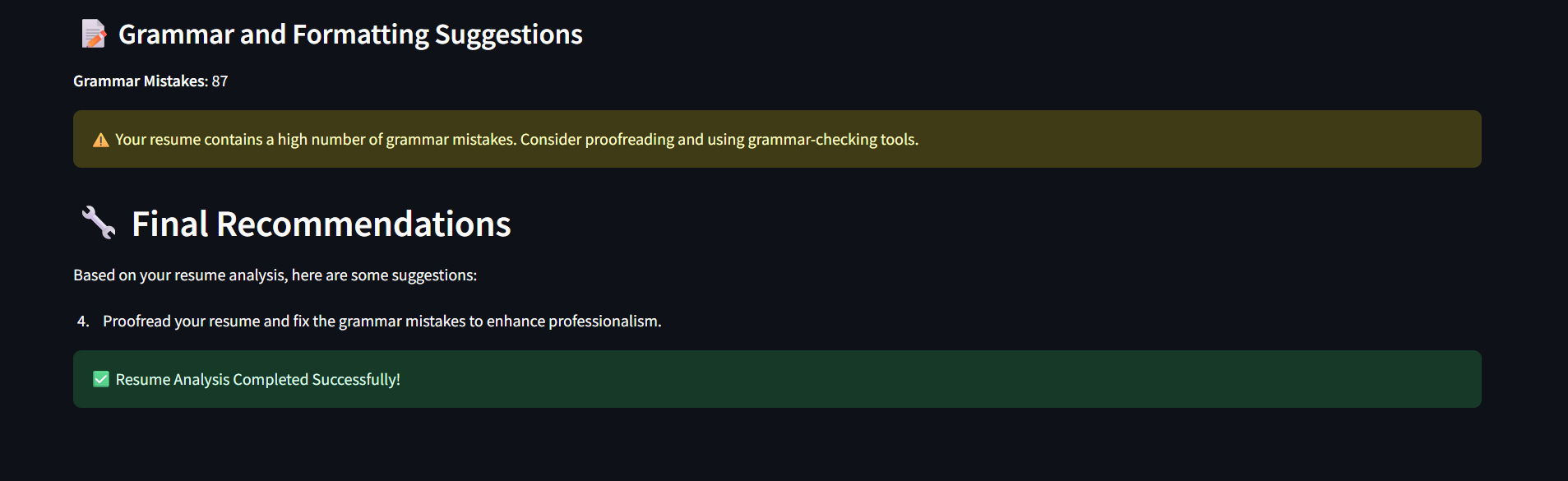
Grammar Suggestions and Final Remarks
-
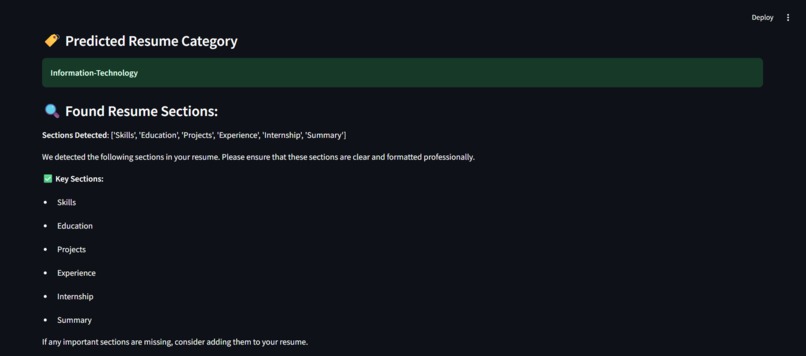
Predicted category and Found Resume Sections
-
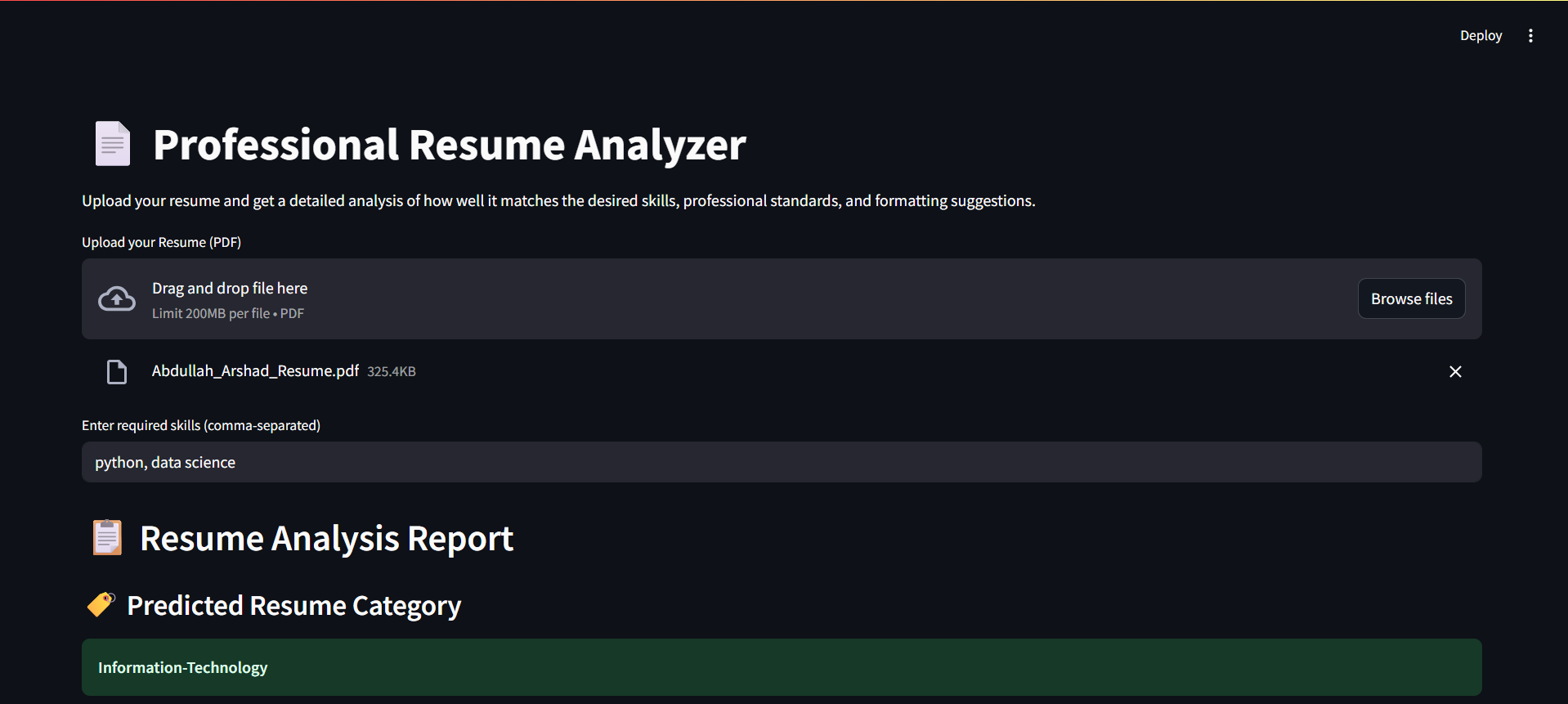
interface, here we can upload our resume to analyze


AI Resume Analyzer
Inspiration
The job application process can be overwhelming, especially for fresh graduates or junior professionals who aren’t sure whether their resume is strong enough. Recruiters often spend less than 10 seconds skimming a resume — making it essential to tailor your resume for each role.
I was inspired to build the AI Resume Analyzer after noticing how often job seekers struggle with resume formatting, keyword optimization, and grammar — all of which can lead to lost opportunities.
What we Learned
This project gave us hands-on experience with:
- Natural Language Processing (NLP)
- PDF parsing and text extraction
- Machine learning classification (Logistic Regression, Random Forest)
- Data visualization using Matplotlib and Seaborn
- Building and deploying web apps with Streamlit
We also deepened my understanding of:
- How resumes are structured
- The importance of keyword matching in applicant tracking systems (ATS)
- Using grammar-check APIs (like
language_tool_python)
How we Built It
The project was built in Python using the following key libraries:
PyPDF2andPyMuPDFfor PDF text extractionnltkfor tokenization and text processinglanguage_tool_pythonfor grammar checkingscikit-learnfor resume classificationmatplotlibandseabornfor visual feedbackstreamlitfor the web interface
Workflow Overview
- Resume Upload: The user uploads a
.pdfresume via Streamlit. - Text Extraction: We extract clean text from the resume using
PyMuPDF. - Skill Matching: The app compares user-inputted required skills against the resume content.
- Grammar Analysis: We use LanguageTool to identify common grammar issues.
- Structure & Keywords: We check for the presence of key resume sections like
Education,Experience,Projects, and common action verbs. - Machine Learning Classification:
- Used
RandomForestClassifier(after testing with Logistic Regression). - Labeled resumes into categories like
Software Developer,Data Scientist,Business Analyst, etc. - Vectorized resume content using
TfidfVectorizer.
- Used
Sample ML Classification Equation
Let:
- ( x ) be the vectorized resume text
- ( y \in {0, 1, 2} ) represent resume classes
Then:
[ \hat{y} = \text{argmax}_c \; P(y = c \mid x) \quad \text{using Random Forest} ]
Challenges Faced
1. Inconsistent Resume Formatting
Parsing resume content was tricky due to varying structures. Some resumes used tables, others used unusual fonts, which complicated text extraction.
2. PDF Extraction Accuracy
Initially used PyPDF2 but found it unreliable for some multi-column resumes. Switched to PyMuPDF (fitz) which worked more consistently.
3. Model Performance
Training the resume classifier was challenging due to limited labeled data. I manually collected and labeled over 150+ resumes for three categories.
4. Grammar Detection Speed
Grammar checks were slow on large resumes. I had to optimize by reducing token windows and summarizing checks to key sentences.
5. Deployment Hurdles
Hosting on Streamlit Cloud required Python 3.10 compatibility. Some packages (e.g., matplotlib, language_tool_python) had version conflicts, which I resolved by manually tweaking requirements.txt.
Final Outcome
The AI Resume Analyzer provides:
- Skill match percentage
- Grammar suggestions
- Action verb usage analysis
- Resume structure feedback
- Predicted job category (via ML)
- Suggestions for improvements
This tool is helpful for students, professionals, and even career coaches who want quick feedback on resumes.
Built With
- matplotlib
- nltk
- numpy
- pandas
- pymupdf
- pypdf
- python
- randomforest
- scikit-learn
- seaborn
- streamlit
- vscode

Log in or sign up for Devpost to join the conversation.