-
-
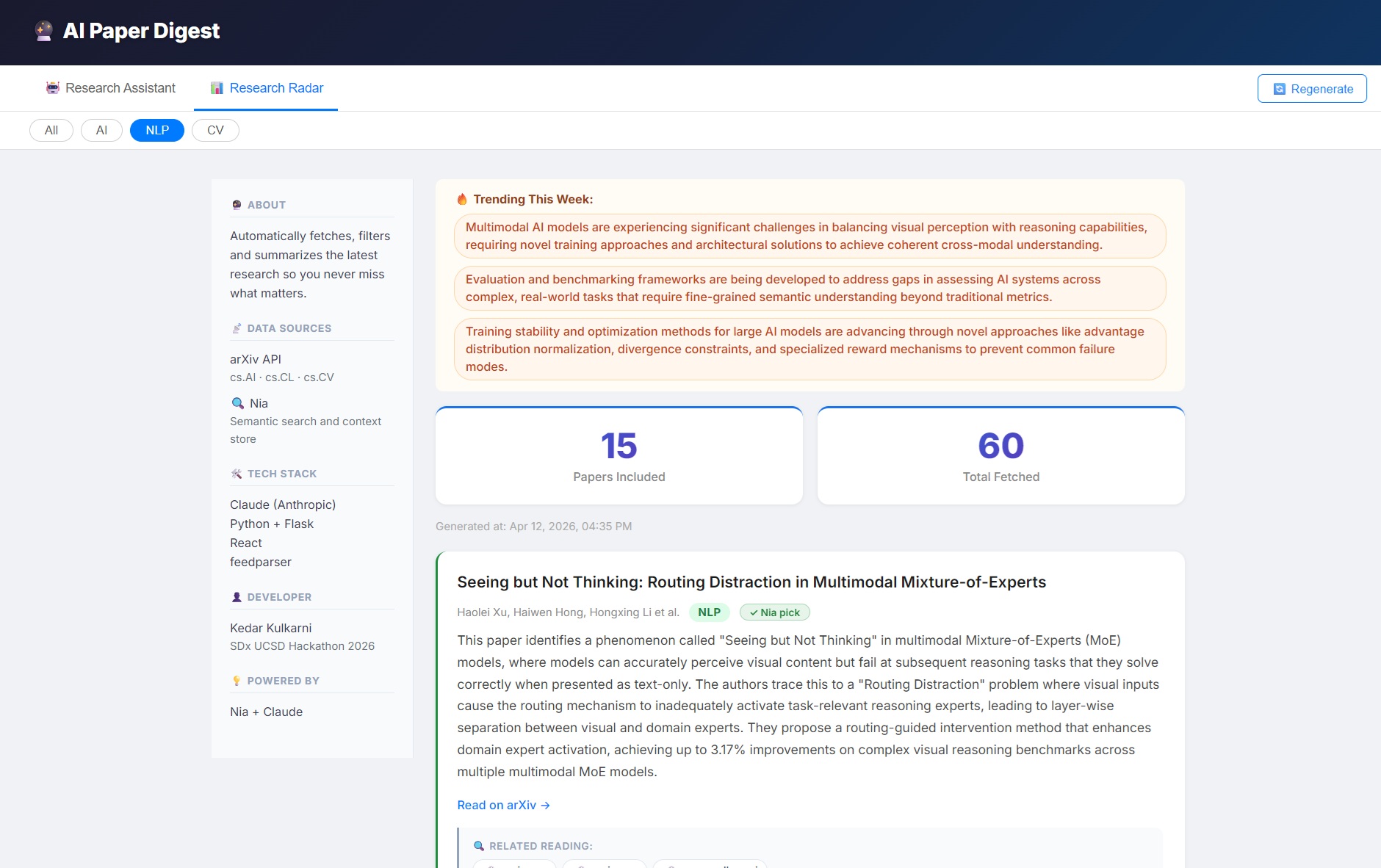
Research Assistant
-
Research Radar
-
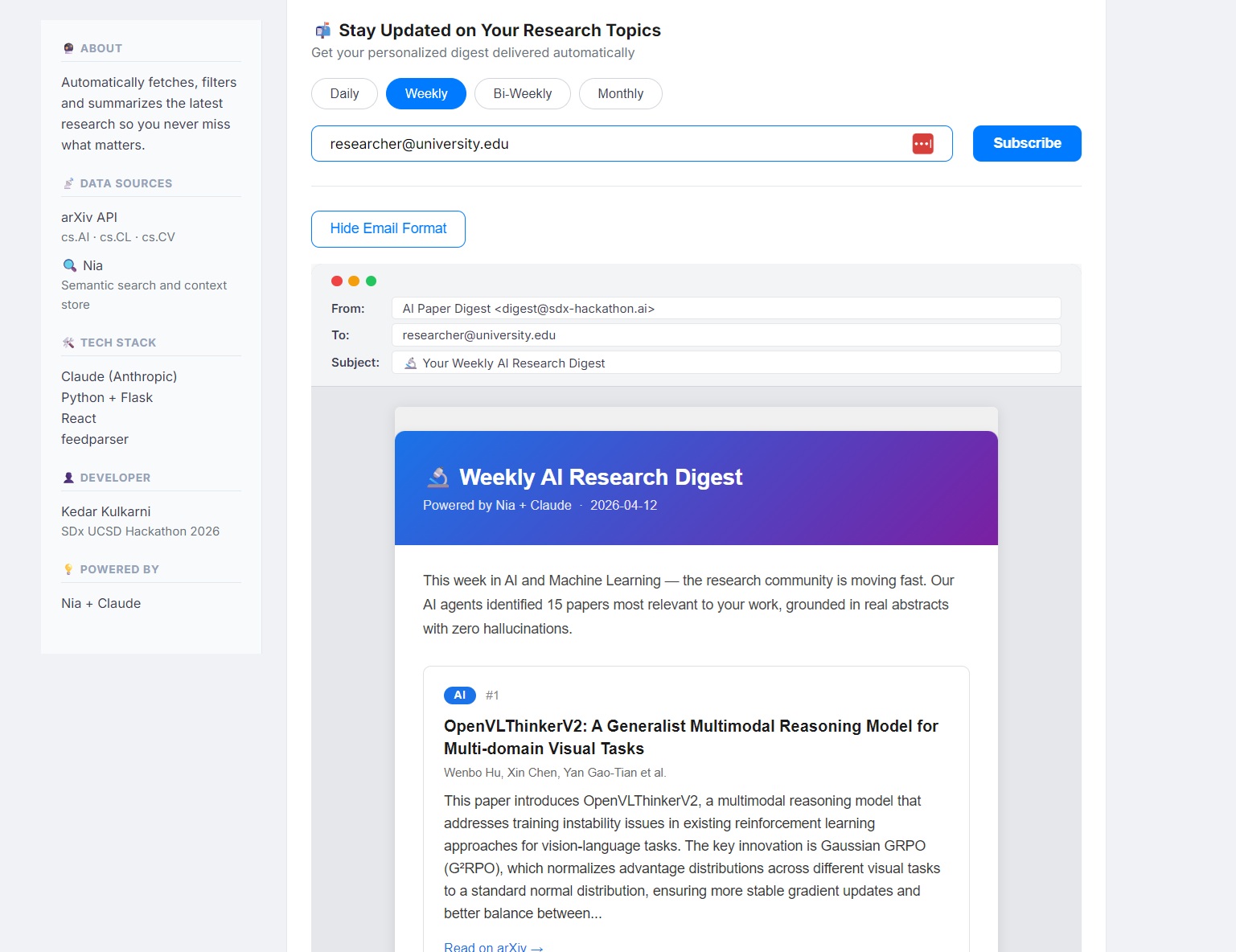
Email Format
AI Research Digest Agent
Video Link (in case not showing up in preview)
https://vimeo.com/1182480782/72c9aa5124
GitHub Link
https://github.com/kulkarnikk07/ai-research-digest-agent/
Inspiration
Researchers today face an impossible problem: hundreds of new papers are published every week on arXiv alone. Missing a breakthrough paper in your field isn't just inconvenient, it can mean duplicating work, missing opportunities, or falling behind. We wanted to build something that acts like a brilliant research assistant that never sleeps, never misses a paper, and always knows what matters to you.
What I Built
AI Research Digest Agent is a personalized research pipeline powered by 5 autonomous AI agents working in sequence:
| Agent | Role |
|---|---|
| 🗣️ Profiler Agent | Converses with the researcher to understand their topic, depth, and goals |
| 📡 Fetcher Agent | Pulls the latest papers from arXiv across AI, NLP, and Computer Vision |
| 🔍 Curator Agent | Uses Nia's semantic search to filter 60 raw papers to the 15 most relevant |
| ✍️ Summarizer Agent | Uses Claude to write grounded 50-word summaries from real abstracts |
| 🔬 Research Agent | Uses Nia to find related reading for every paper |
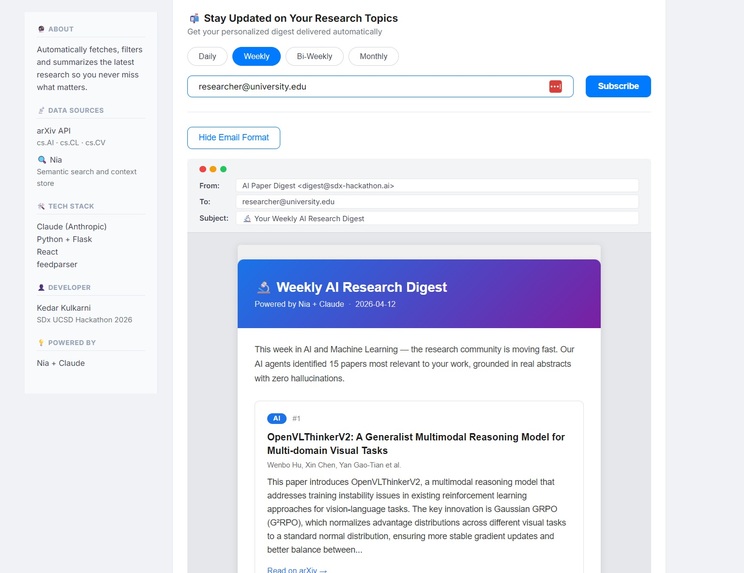
The result is a fully personalized weekly digest — displayed as an interactive dashboard and a professional email newsletter — tailored to exactly what the researcher told the system they care about.
How I Built It
The architecture follows a clean pipeline pattern: Conversation → Persona → Fetch → Curate → Summarize → Enrich
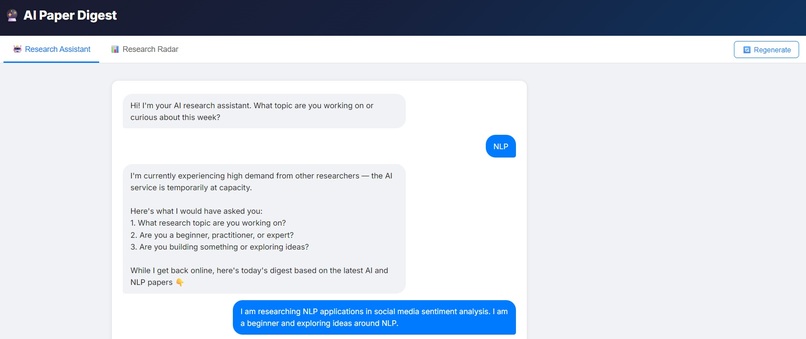
Step 1 — Profiler Agent (Conversational Trigger) The researcher talks to a chat interface. They describe their topic, depth preference, and goal in plain English. Claude extracts a structured Research Persona from the conversation and saves it via Nia's context store so the system remembers who you are across sessions.
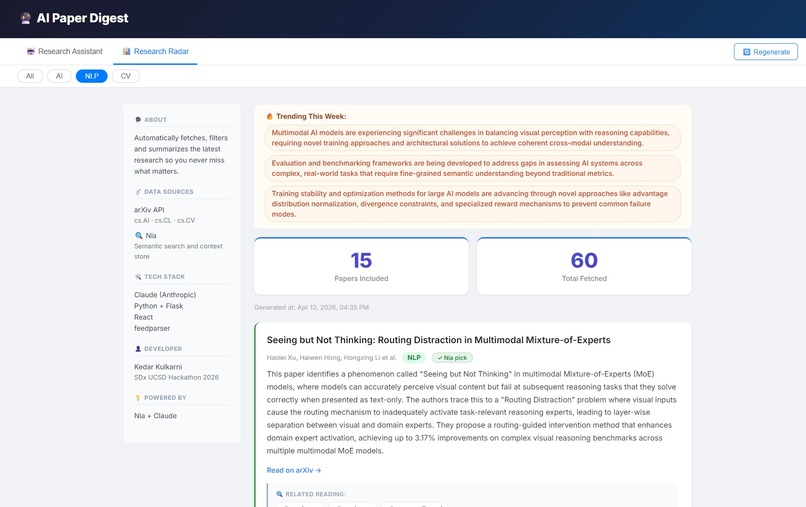
Step 2 — Fetcher Agent (arXiv Integration) Using feedparser, the agent hits the arXiv API and pulls the 20 most recent papers from each selected category (cs.AI, cs.CL, cs.CV) — 60 papers total.
Step 3 — Curator Agent (Nia Semantic Search) This is where Nia becomes the core intelligence layer. Instead of dumb keyword matching, the Curator calls Nia's semantic search API with the researcher's topic. Nia understands meaning — so a search for "efficient AI for mobile" finds papers about edge inference even if they never use those exact words. 60 papers become 15 genuinely relevant ones.
Step 4 — Summarizer Agent (Claude) Each of the 15 papers is summarized by Claude using the actual abstract as ground truth. Every summary is strictly grounded — no hallucinations, no invented facts. Summaries are capped at 50 words for readability.
Step 5 — Research Agent (Nia Related Reading) For every paper, the Research Agent calls Nia's search API using the paper title as a query. Nia returns related sources and context — giving each paper card a "Related Reading" section that surfaces deeper connections across the research landscape.
How This Matches the Judging Criteria
🎨 Creativity
The conversational trigger is what makes this project unique. Instead of dropdowns or keyword inputs, the researcher just talks to the system. The Profiler Agent extracts intent from natural language and passes a structured Research Persona through every subsequent agent — meaning the entire pipeline adapts to who you are, not just what you typed. No other paper digest tool works this way.
The "Research Radar" dashboard with a left sidebar showing live data sources, tech stack, and trending topics makes the system transparent and self-documenting — judges and researchers can understand the full pipeline at a glance.
💡 Usefulness
This solves a real, daily problem for a large audience — PhD students, ML engineers, researchers, and product managers who need to stay current without spending hours on arXiv. The output is immediately actionable:
- 15 curated papers with plain-English summaries
- Related reading for deeper exploration
- Trending topics extracted across all papers
- Email newsletter format ready for team distribution
- Subscribe options for daily, weekly, bi-weekly, or monthly delivery
🔍 Use of Nia API
Nia is not a bolt-on feature — it is the intelligence layer that makes the whole system work:
- Semantic Search (Curator Agent) — Nia filters 60 raw papers to 15 relevant ones using meaning-based search, not keywords
- Related Reading (Research Agent) — Nia is called once per paper to surface related context and sources
- Context Store (Profiler Agent) — The Research Persona is saved to Nia's context store so the system remembers the researcher across sessions
🤖 Agents with Powerful Context and Search
Each agent receives enriched context from the previous one. The Profiler passes a structured persona, the Fetcher passes categorized papers, the Curator passes Nia-ranked results, the Summarizer passes grounded summaries, and the Research Agent enriches every paper with cross-source connections. No agent works in isolation — context flows through the entire pipeline.
Challenges
1. Nia URL format — Nia requires PDF URLs (/pdf/) not abstract URLs (/abs/) for indexing arXiv papers. Discovered this through systematic testing of three URL formats.
2. Pipeline speed — Indexing 60 papers before searching made the pipeline take 10+ minutes. Solved by switching to direct semantic search without pre-indexing, reducing runtime to under 2 minutes.
3. Shared API credits — The hackathon shared API key hit credit limits under load from all teams. Built graceful degradation into the chat interface so it fails cleanly with a helpful message and auto-navigates to the pre-generated digest.
4. Three-column layout — Balancing left sidebar, main content, and trending strip on laptop screens required careful CSS flexbox work to avoid cramped layouts.
What I Learned
- Nia's semantic search is genuinely more powerful than keyword filtering for research discovery
- Conversational triggers make AI pipelines feel natural and human rather than mechanical
- Graceful degradation matters more than perfect uptime in demo environments
- A pre-generated fallback digest is the difference between a smooth demo and a failed one
What's Next
- Scheduled weekly delivery via email service integration
- Research Persona evolution — system learns from which papers you click
- Expand to all arXiv categories beyond AI/NLP/CV
- Slack and Discord bot integration
- Multi-user support with individual personas stored in Nia's context store
Built With
- anthropic
- anthropic-claude-api
- api
- arxiv-api-libraries:-feedparser
- claude
- code
- css-frameworks:-flask
- data
- flask
- flask-cors
- html
- javascript
- nia
- python
- python-dotenv
- react
- react-(via-cdn)-apis:-nia-api-(nozomio-labs)
- server)

Log in or sign up for Devpost to join the conversation.