-
-
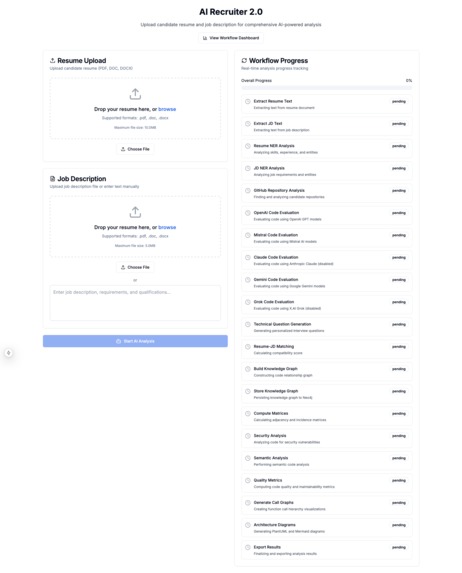
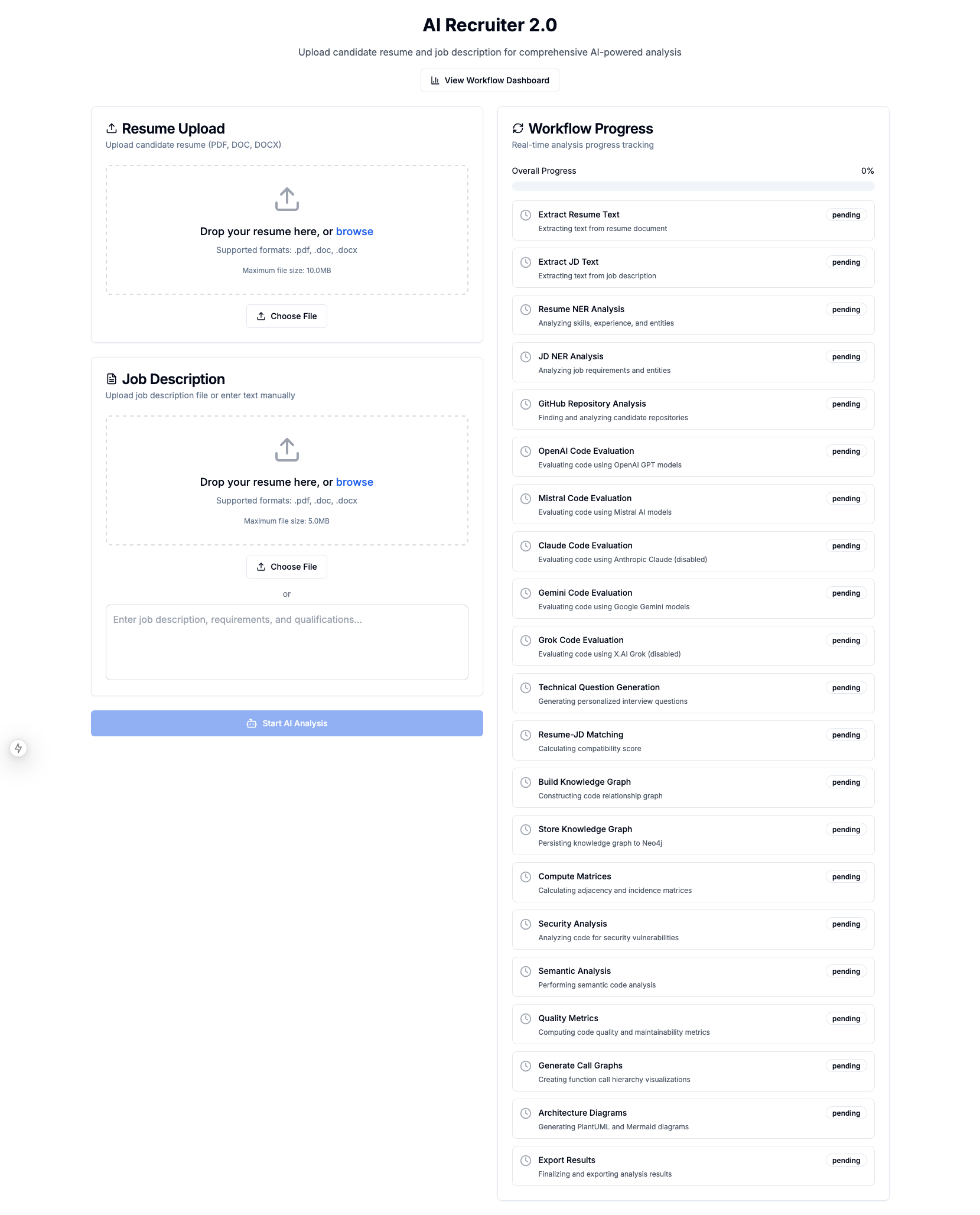
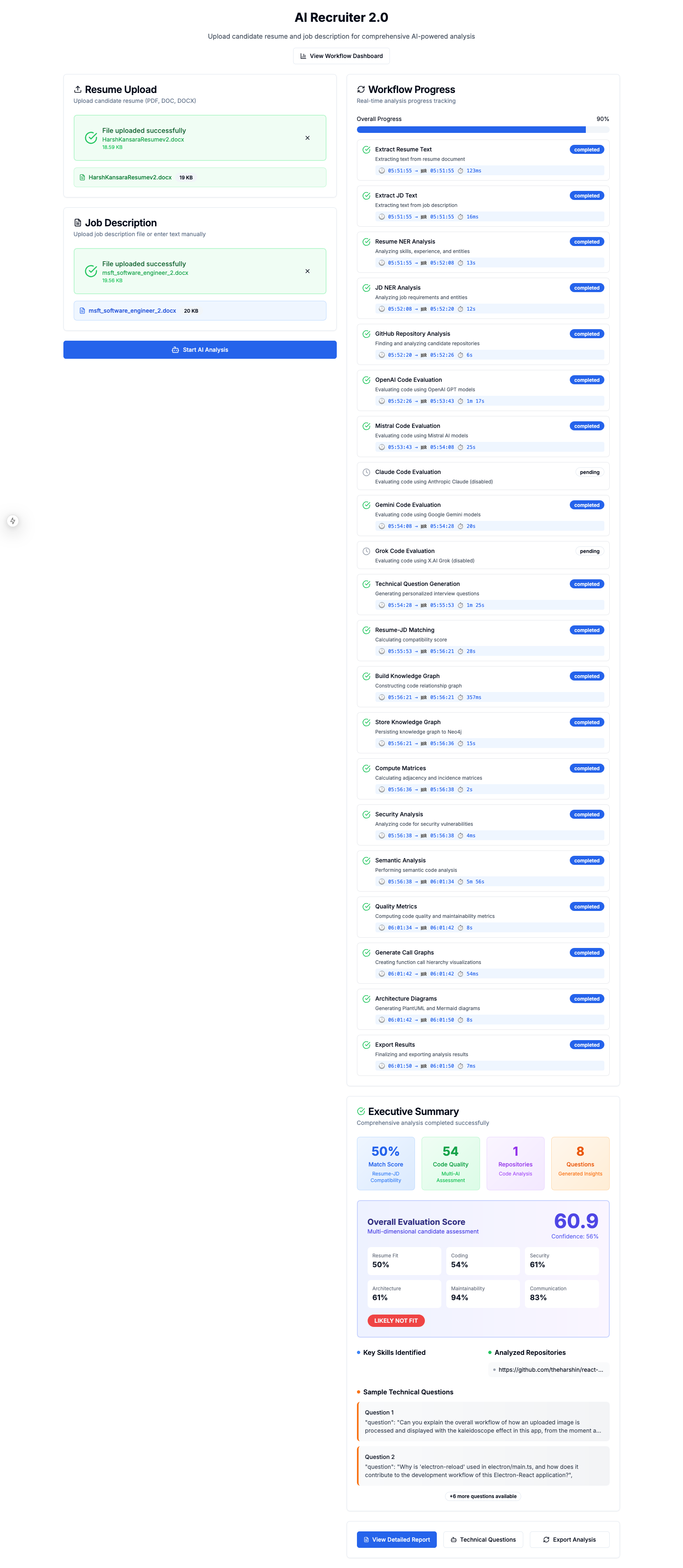
AI Recruiter 2.0 Starting Page
-
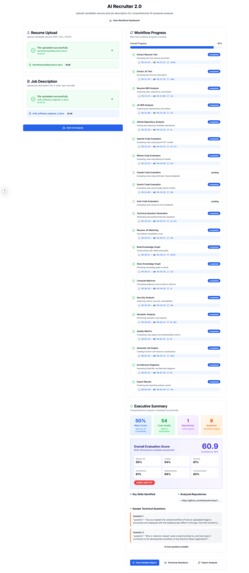
Workflow Completed Page
-
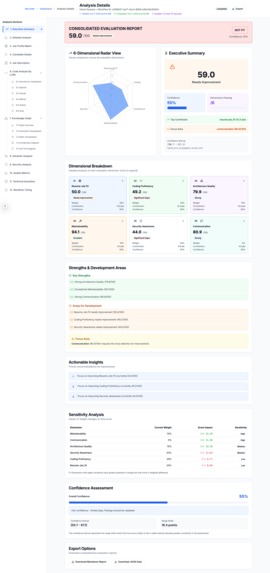
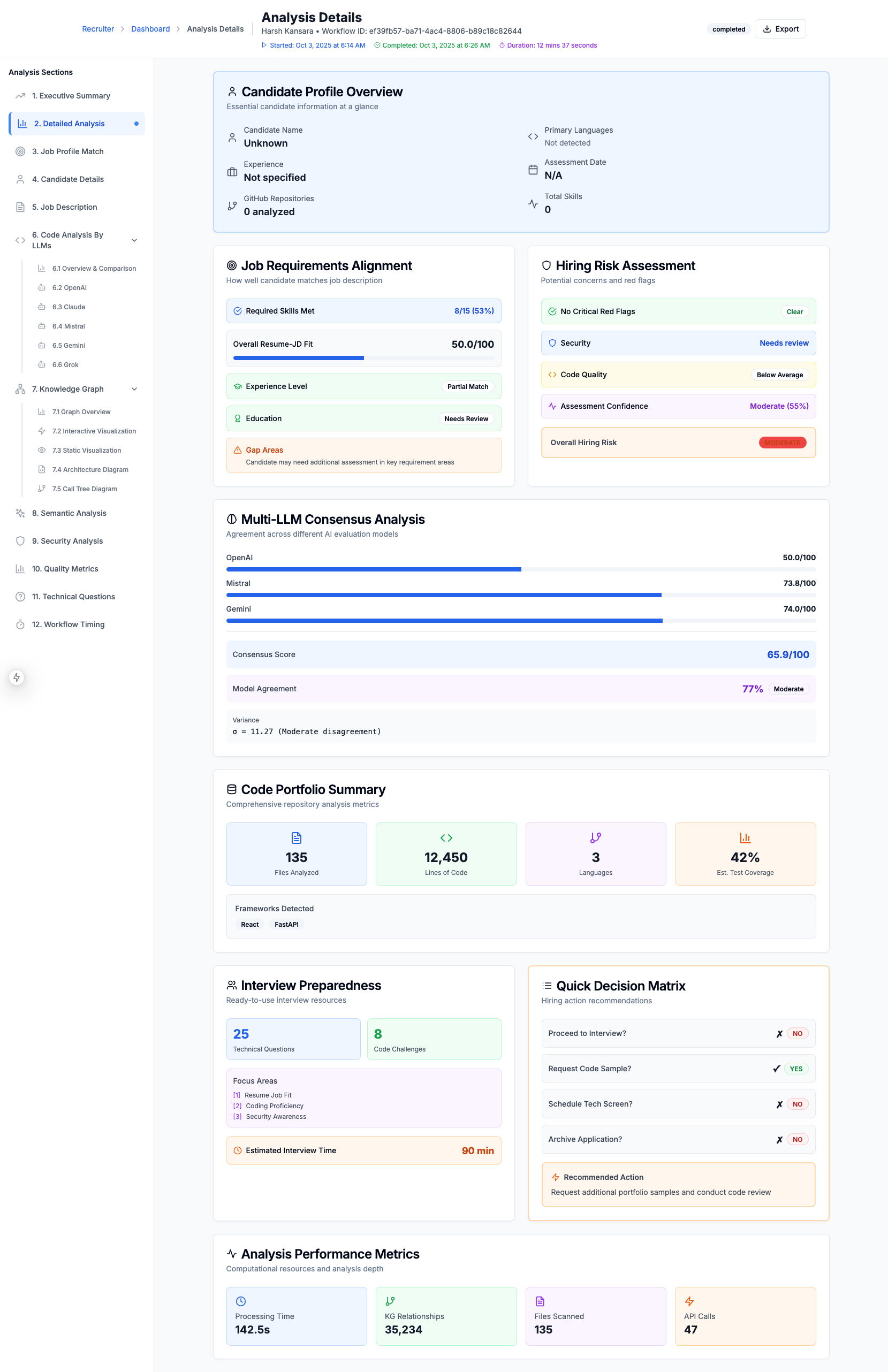
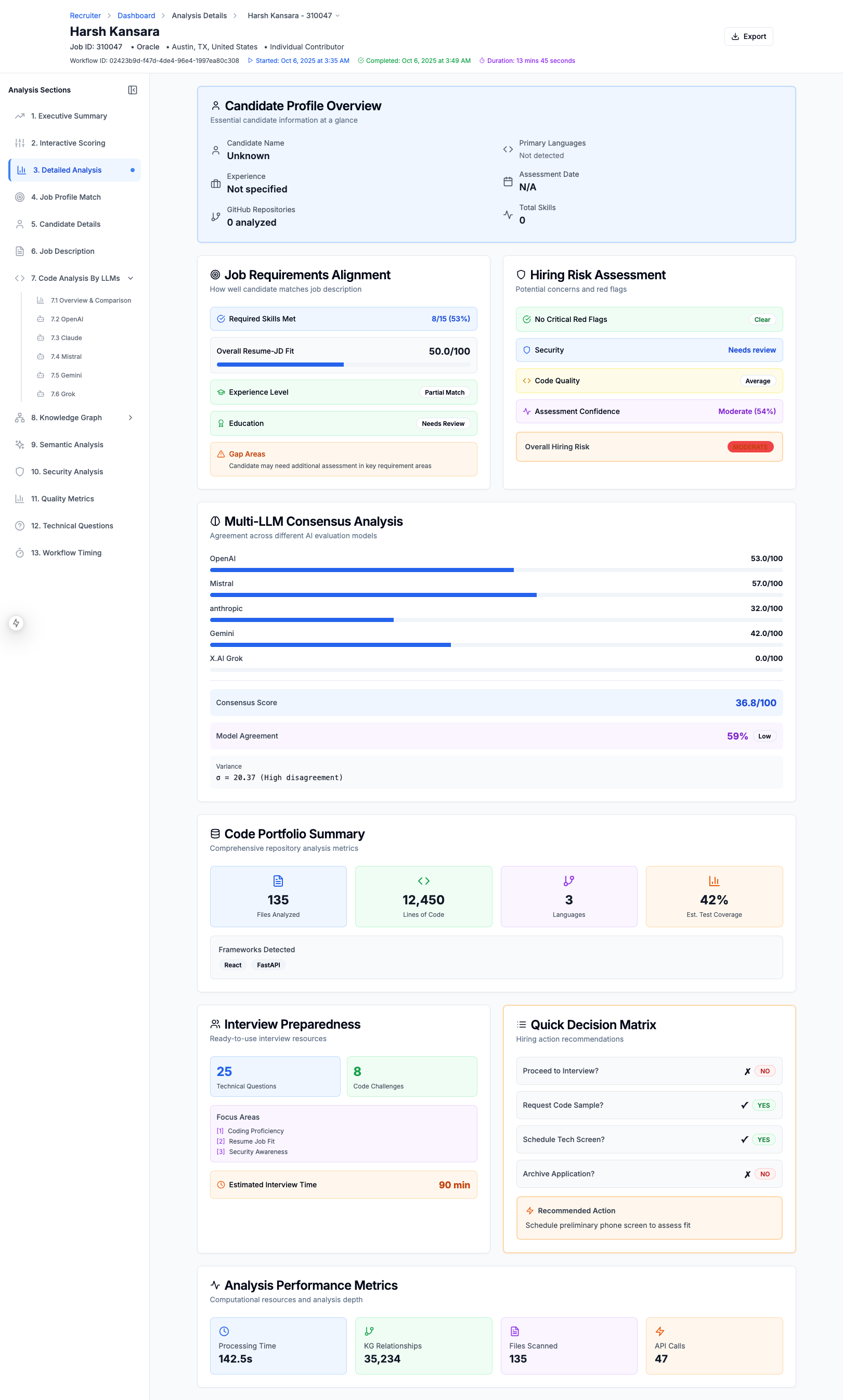
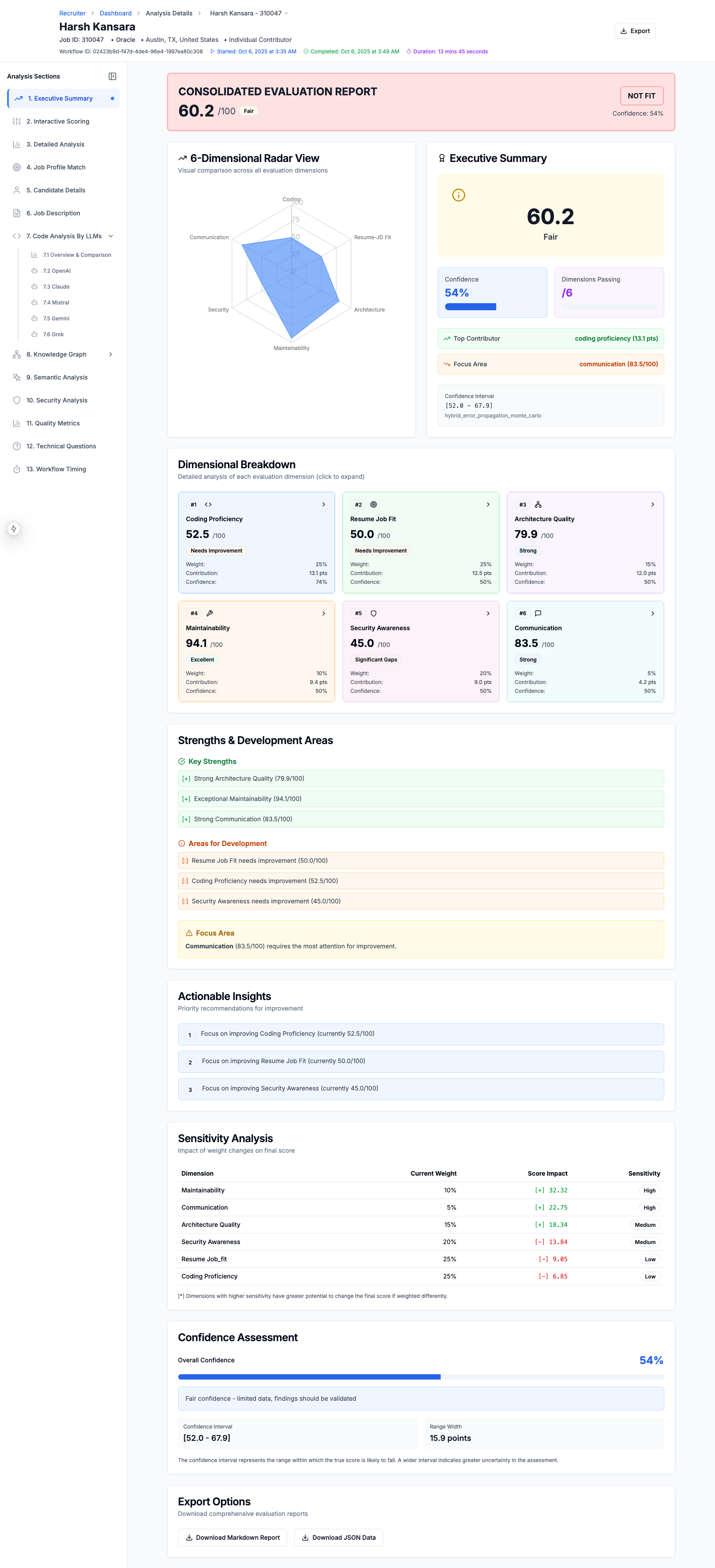
Executive Summary of The Candidate's Match for the job
-
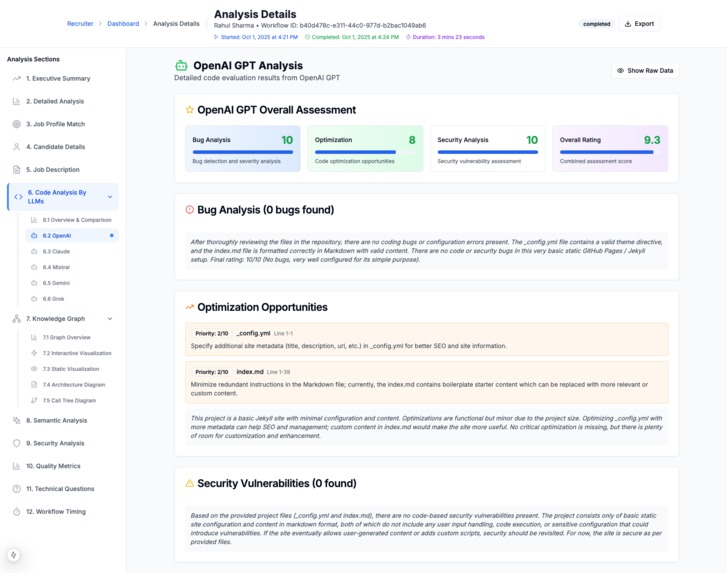
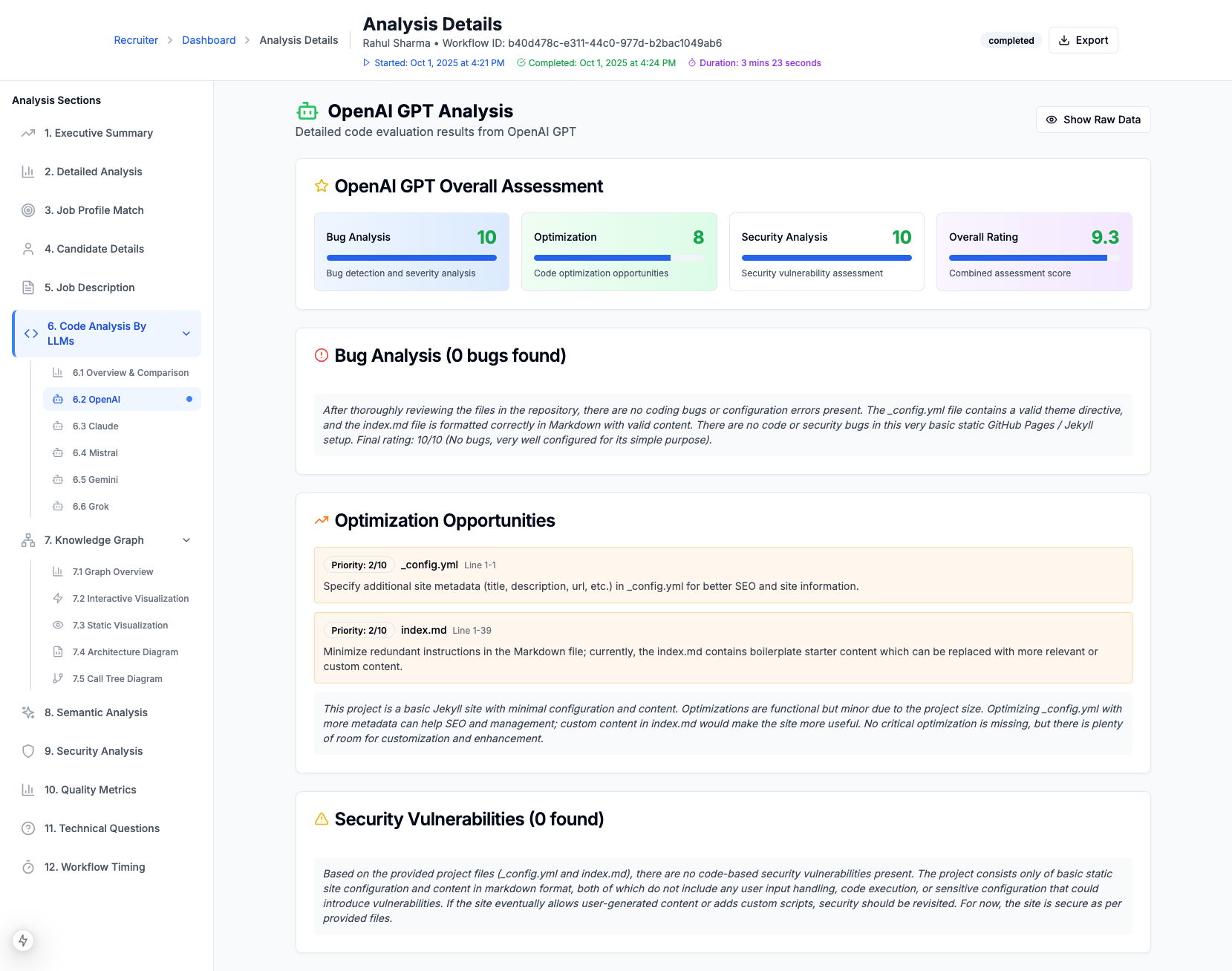
OpenAI Analysis of Code
-

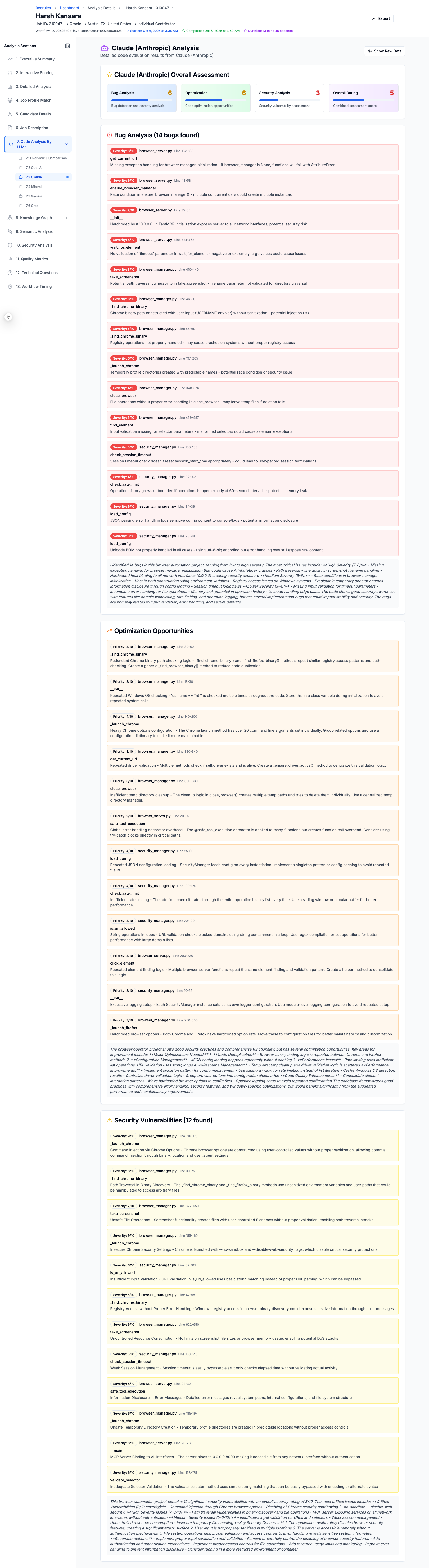
Code Evaluation By Anthropic Claude
-
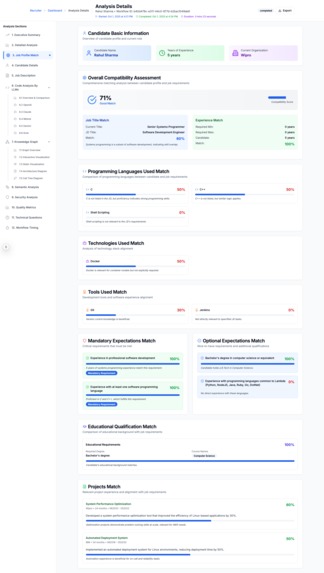
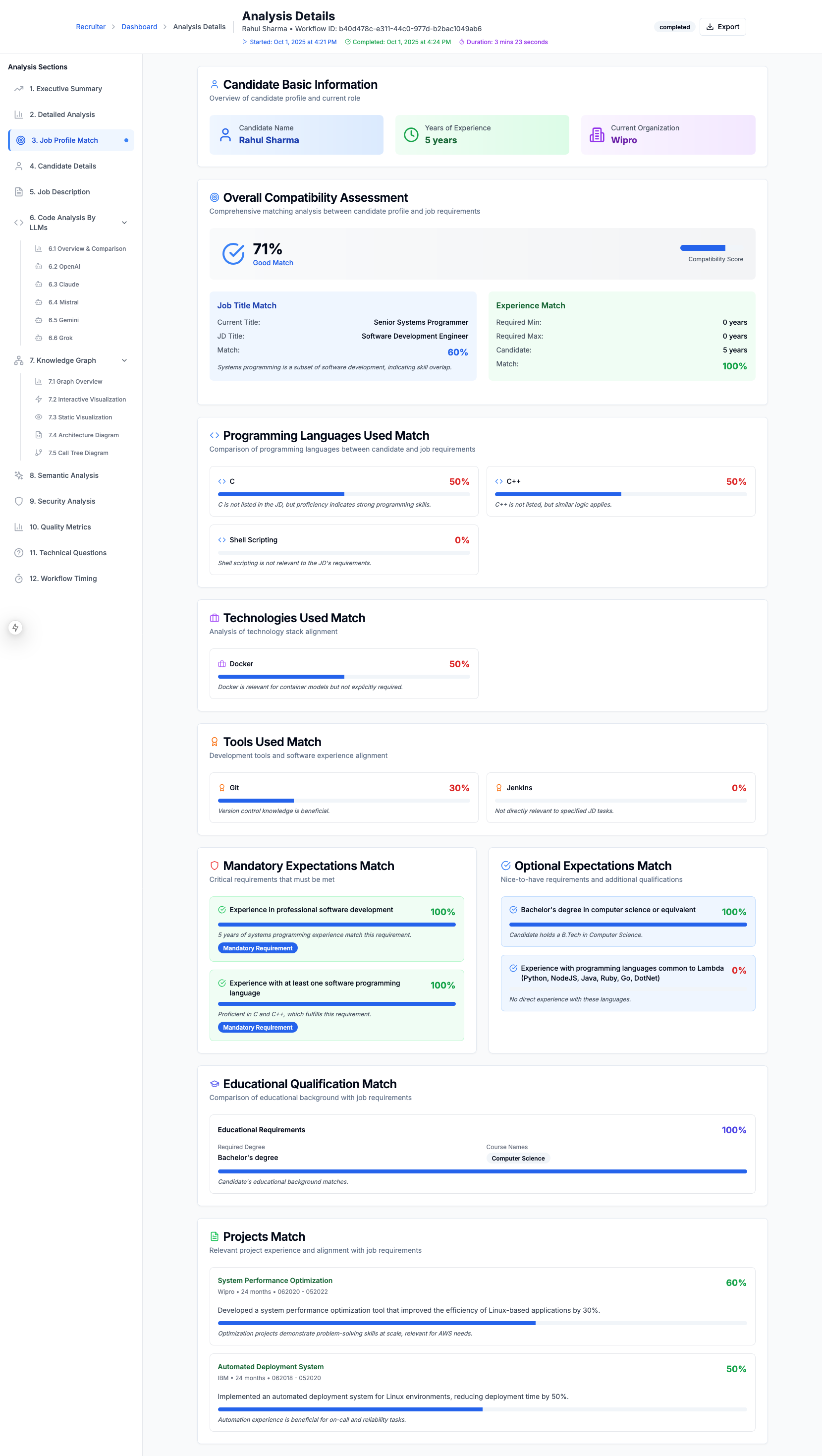
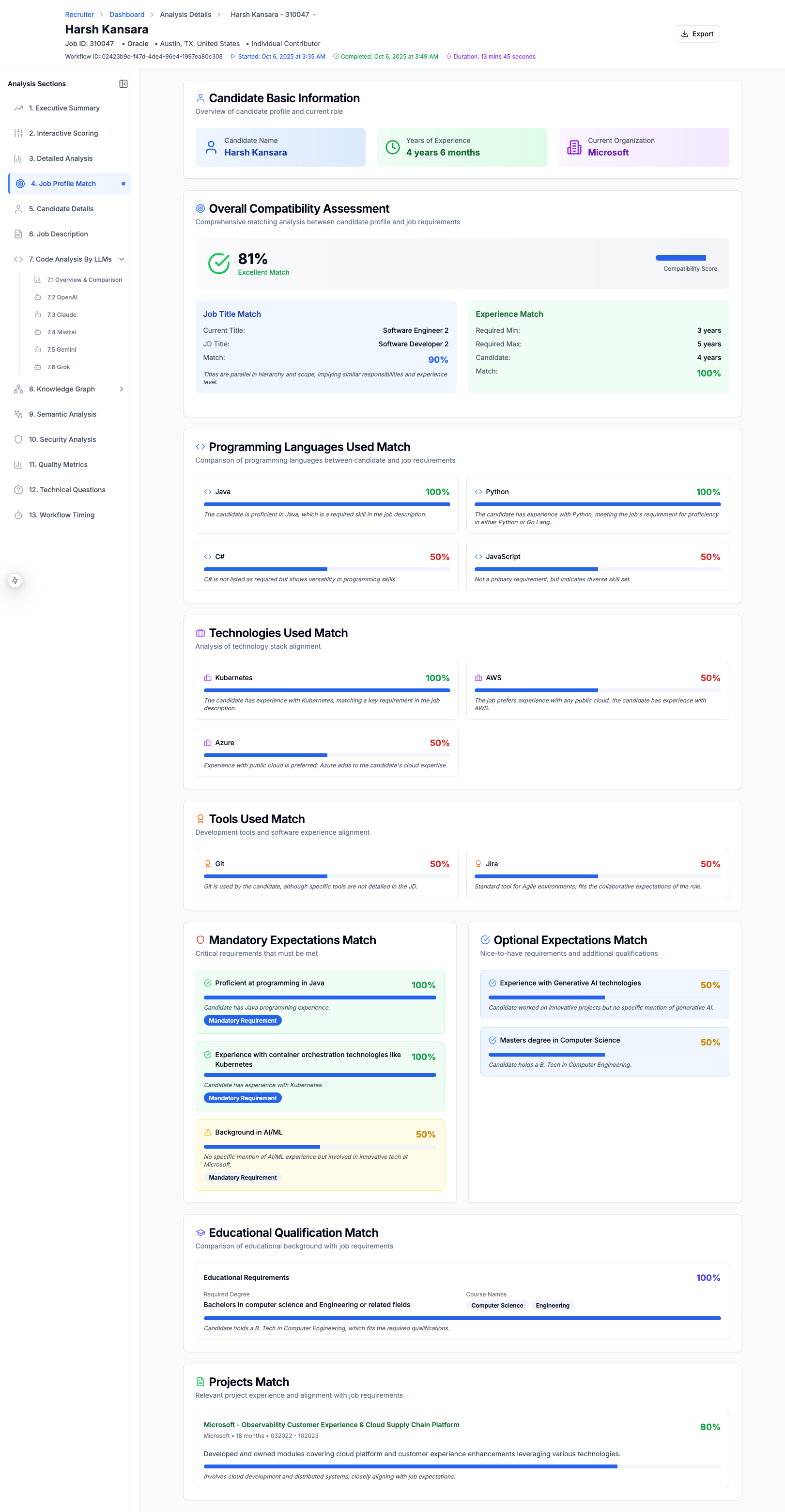
Candidate Resume Match with Job Description
-
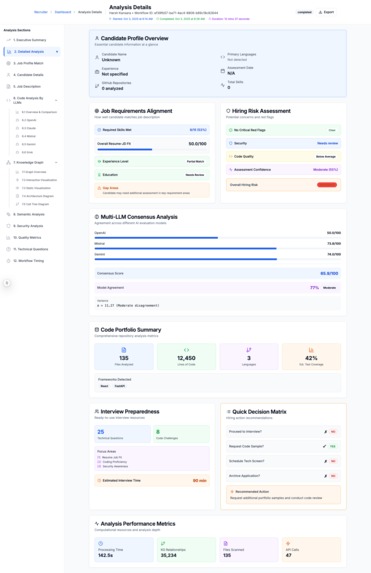
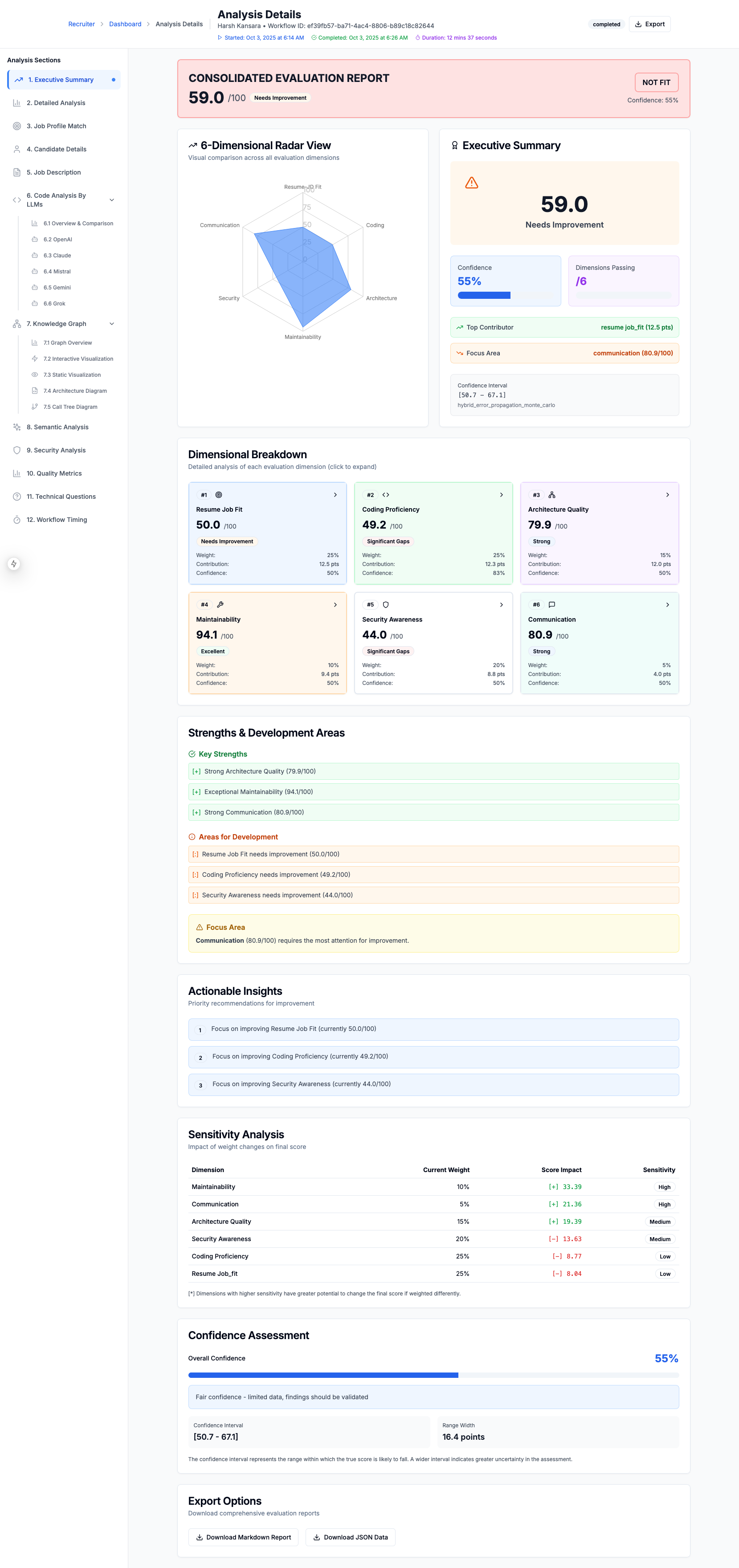
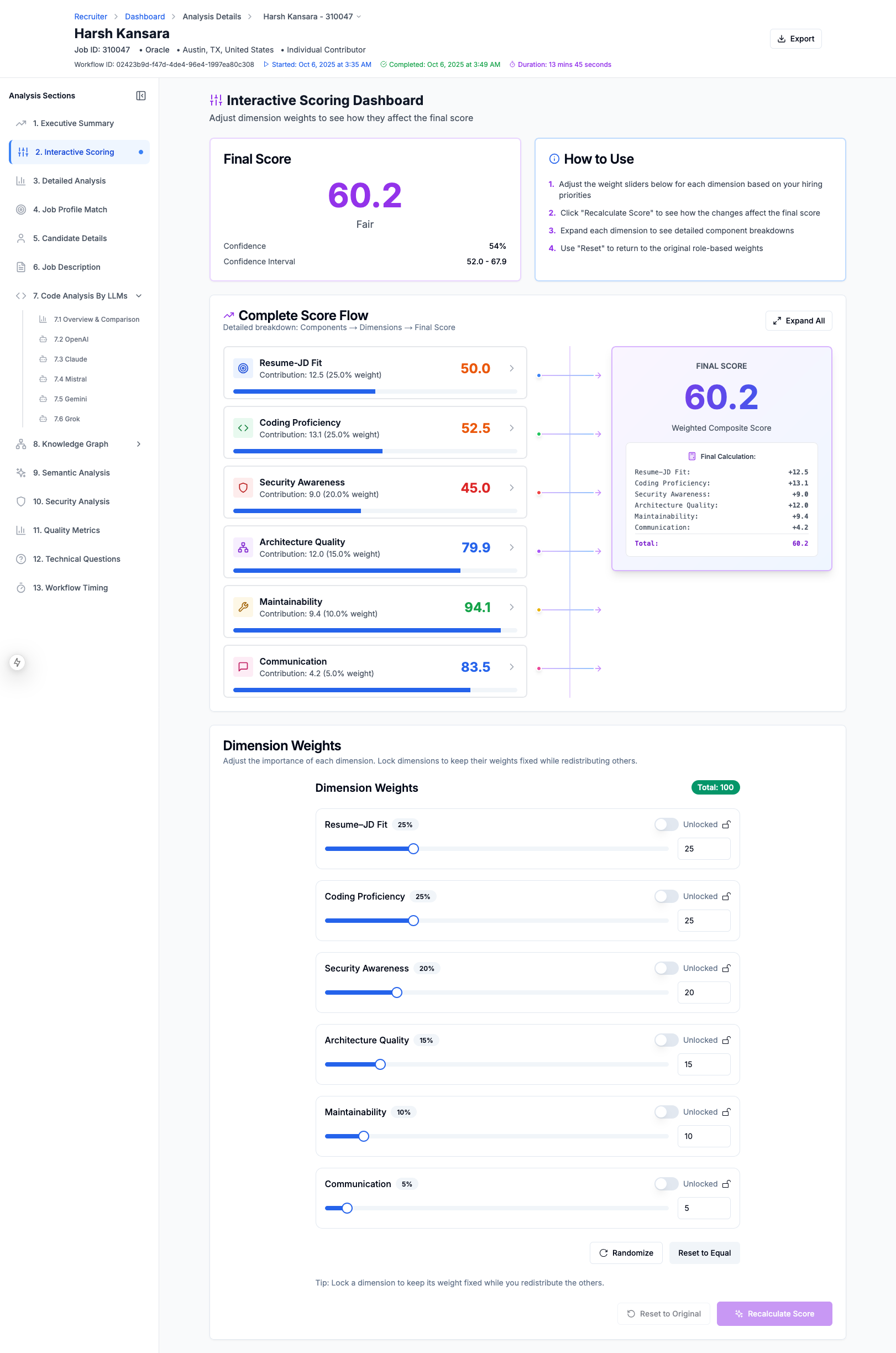
Detailed Explanation of The Candidate Score
-
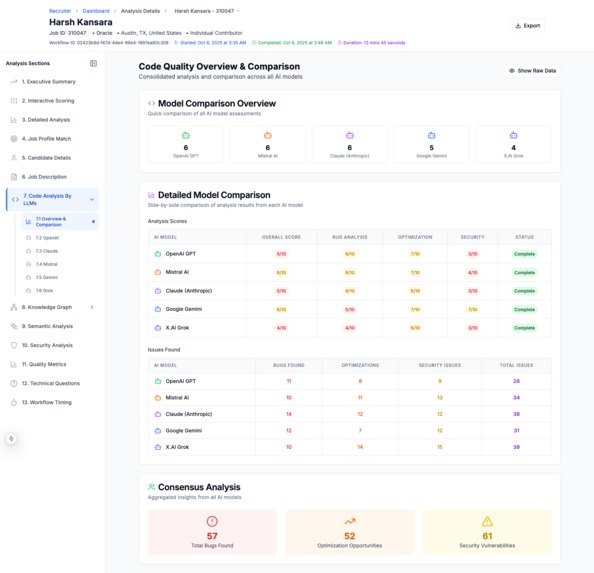
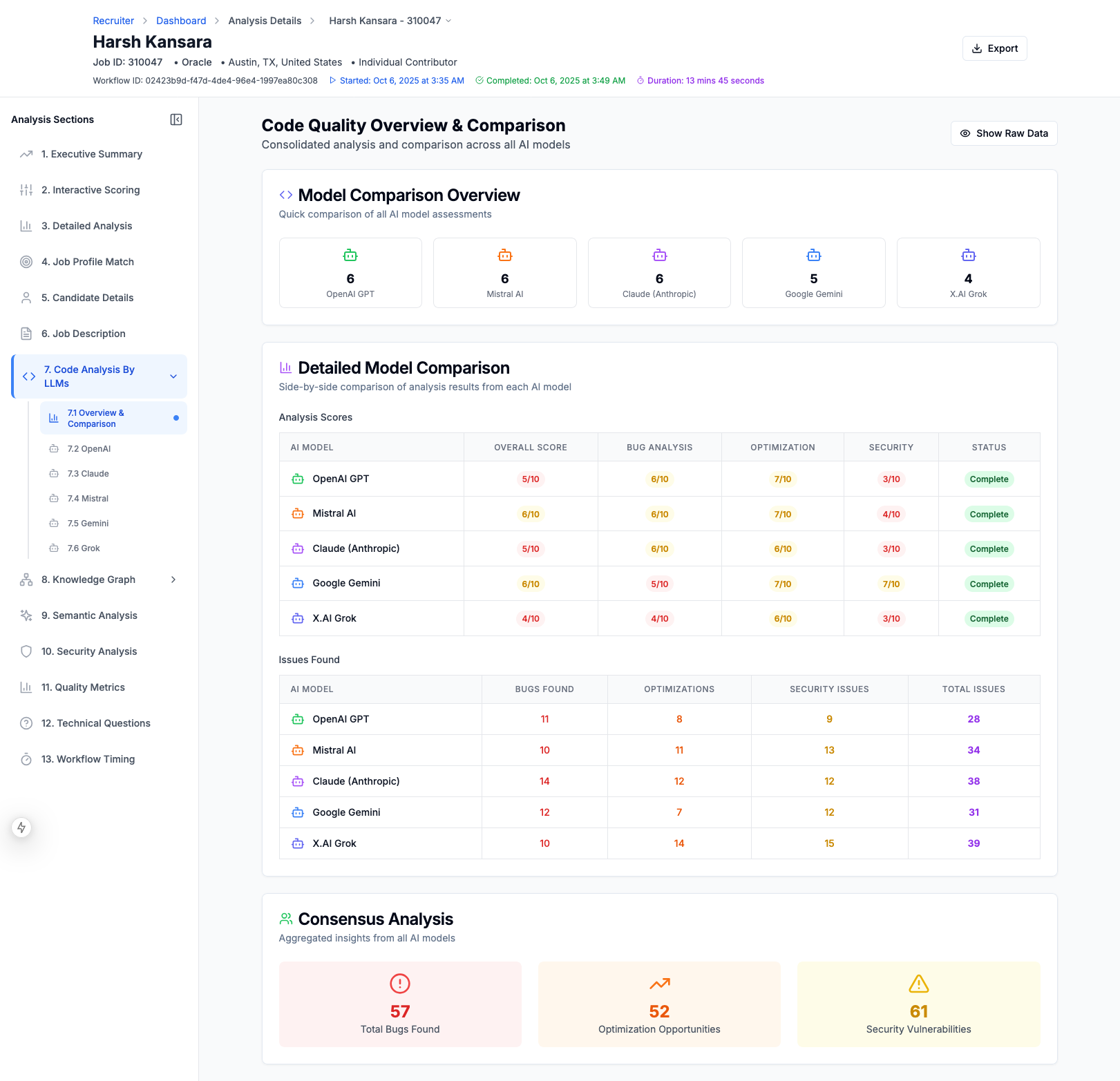
Code Evaluation Summary By Multiple LLMs
-
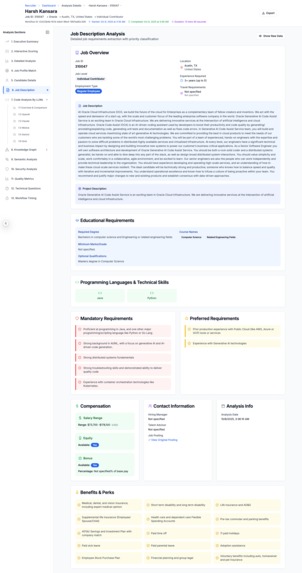
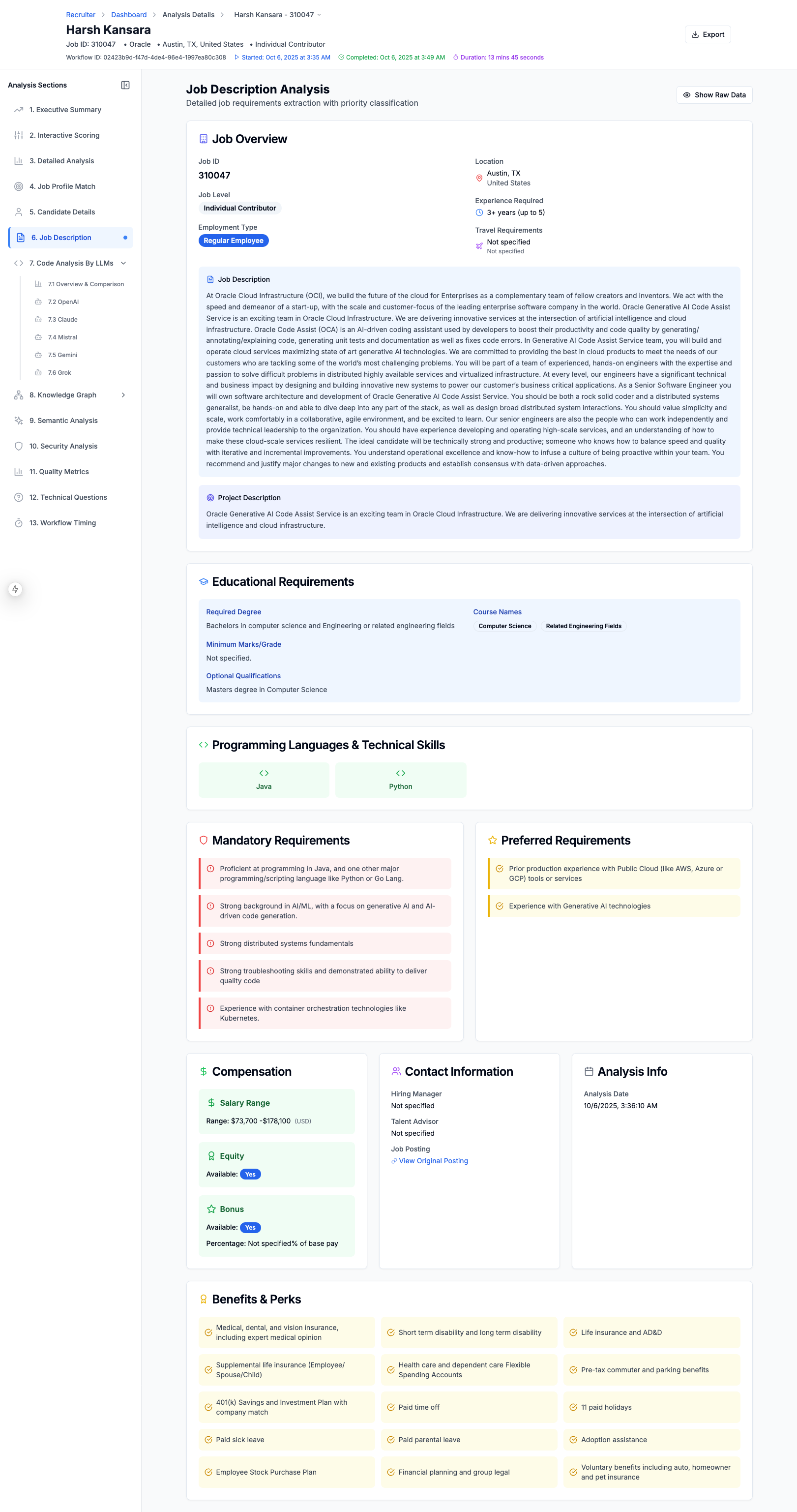
Job Description
-
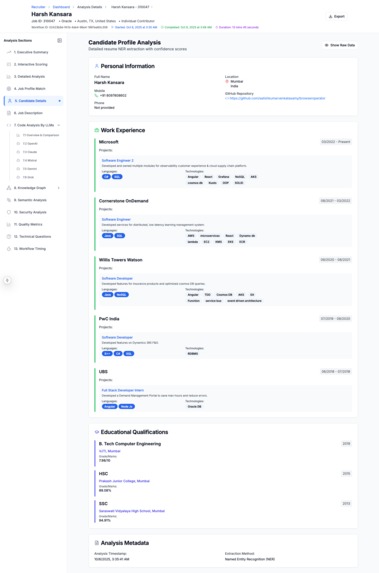
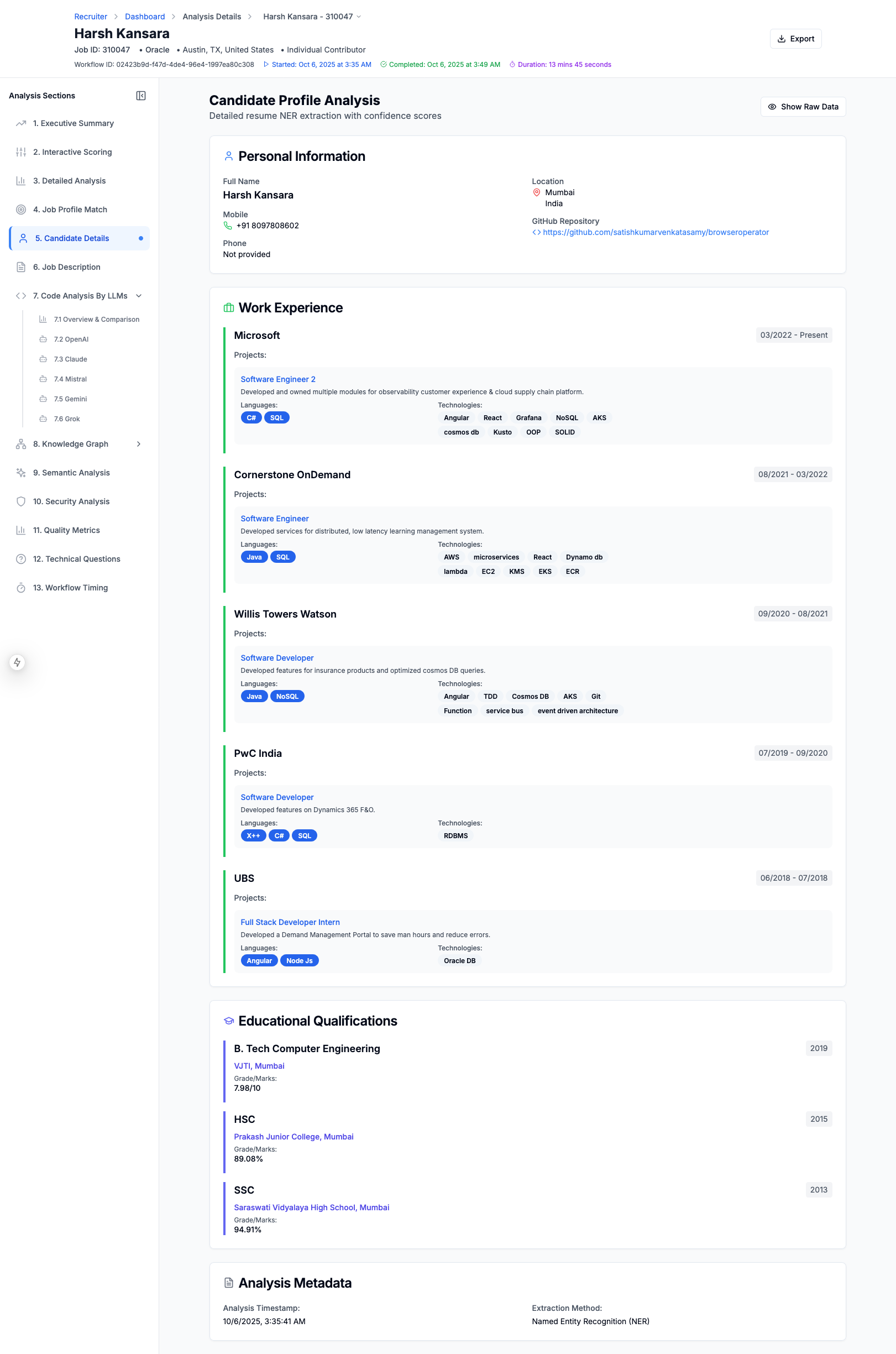
The Candidate's Resume - Extracted As Structured Information
-
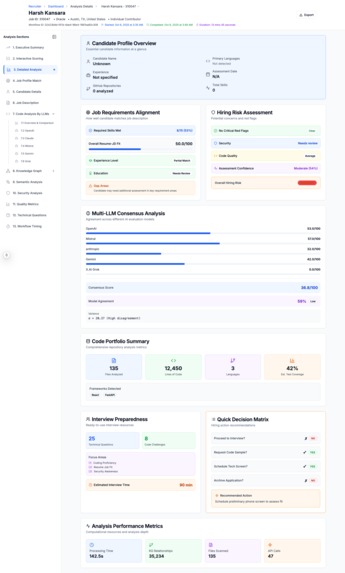
Candidate Evlaution Scoring Explanation - Detailed Explanation
-
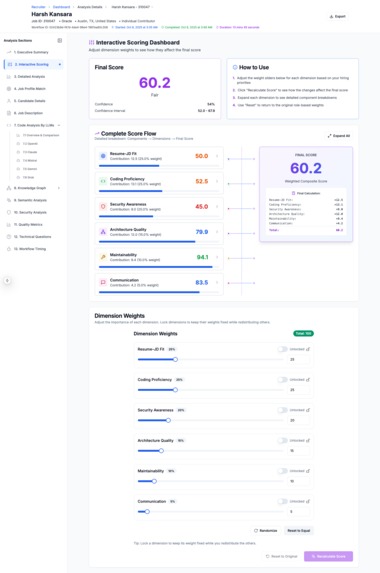
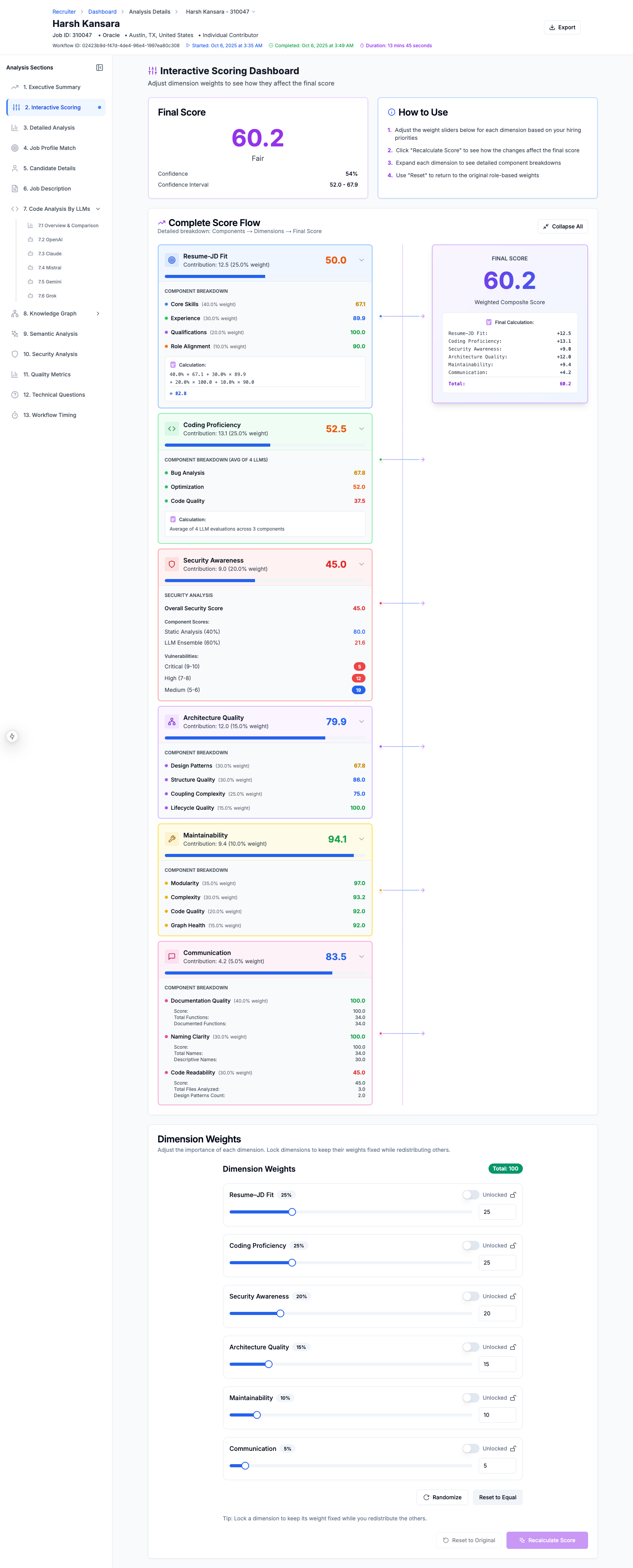
Candidate Evlaution Scoring Explanation
-
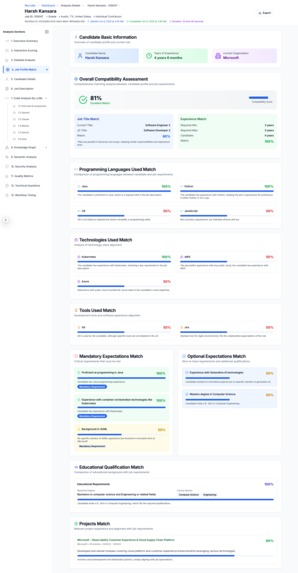
Candidate Resume Match to Job Description
-
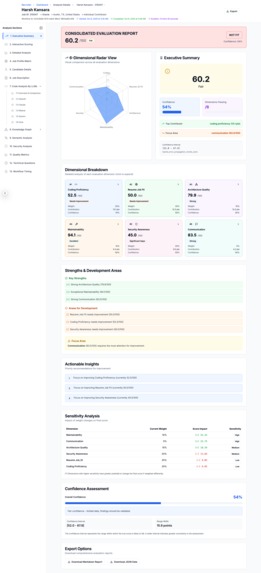
Candidate Evlaution Executive Summary
-
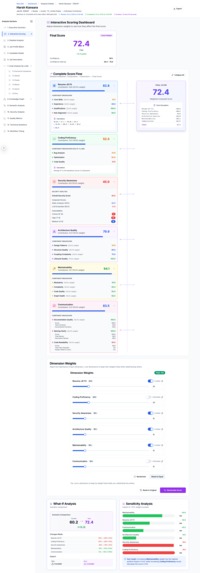
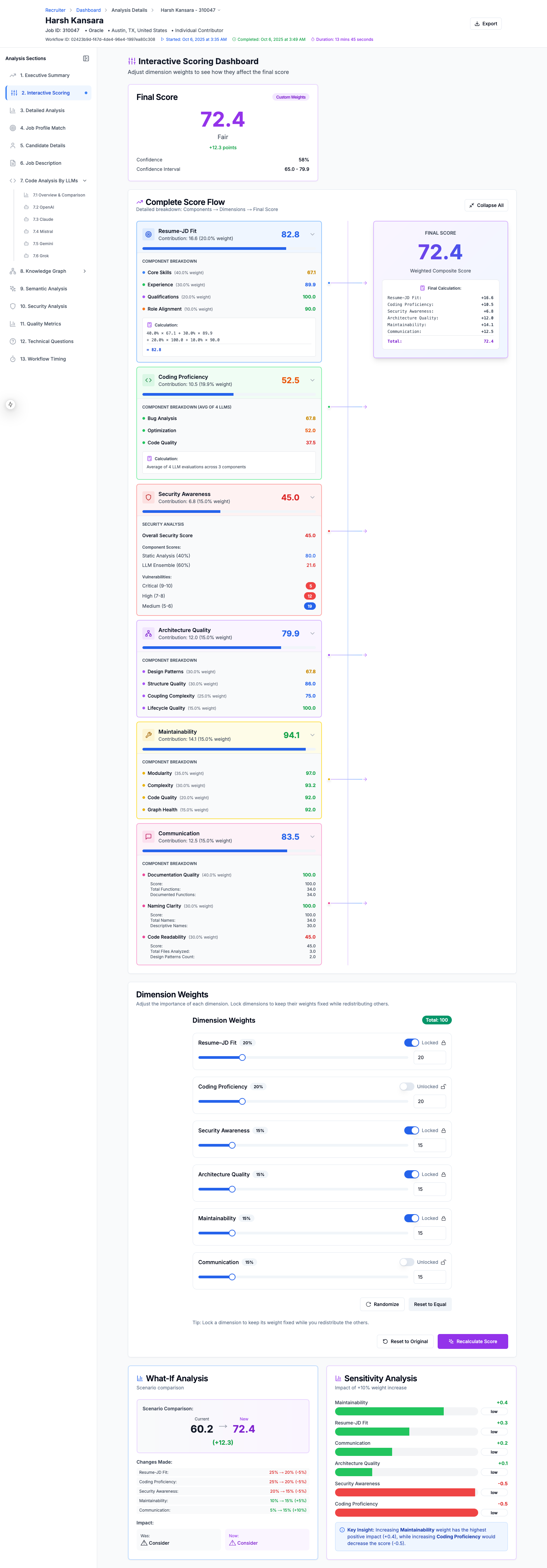
Candidate Evlaution Scoring Explanation - What-IF analysis shows how changing weightage changes candidate's score
-
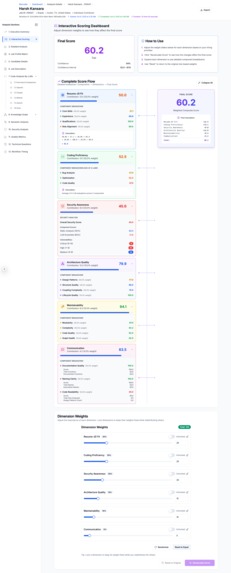
Candidate Evlaution Scoring Explanation - Detailed Breakdown
AI Recruiter 2.0: Revolutionizing Technical Hiring with Knowledge Graphs and Multi-LLM Ensemble Scoring
Tagline: AI-powered hiring platform that analyzes resumes, evaluates GitHub code across multiple LLMs, builds knowledge graphs, performs security audits, and generates technical questions with explainable scoring.
Inspiration
I have 30+ years of experience with 20+ years of experience in building Enterprise and Cloud version of Identity and Access Management services for Oracle (Was a key member of Oracle Enterprise IAM and Oracle Cloud Infrastructure IAM product development as developer and in management roles). In 2021, I started leading the teams that built AI services for OCI. I am a person who likes understand the foundation and building blocks of AI, which many of data scientists were unable to explain in a way that is convincing to me. Hence I joined the M.Tech course on Data Sciences and Machine Learning from PES University Bangalore and learnt Machine Learning and Deep Learning from the ground up. When I was doing the course, I used to imagine how a real world problem can be solved using AI. One such real world problem that I wanted to solve was data and facts based hiring that is explainable (Objective Hiring over Subjective Hiring to eliminate bias). Objective Hiring is a major challenge especially in IT industry. Another reason to solve this problem is that if AI were to hire or shortlist candidate, how the decision can be explained is the problem that Oracle HRMS/Recruitment product was trying to solve.
As part of my M.Tech project, I had to build a AI based project. I picked AI based hiring as I wanted to provide a solution that will help to hire a candidate based on data, facts, which is unbiased. Often hiring is influenced by interviewer's state of mind and the ability of the candidate to impress the interviewer. The hiring process for technical roles has always been challenging. As a software engineer and manager in IT industry, who has both interviewed candidates and been interviewed countless times, I've witnessed the inefficiencies firsthand:
- Hiring managers spending hours manually reviewing hundreds of resumes
- Inconsistent evaluation criteria leading to missed talent
- Lack of objective metrics for code quality assessment
- No transparency in decision-making, raising concerns about bias and regulatory compliance
- The inability to verify GitHub repository quality claims on resumes
- The time taken to analyze the resume and to interview the candidate
- The time taken to reach consensus on hiring a candidate
What if I could build an AI system that not only automates resume screening but also deeply analyzes a candidate's actual code using multiple AI models, generates mathematical proofs of code quality through graph theory, and provides explainable, auditable hiring decisions?
This question became the foundation of AI Recruiter 2.0 - a project born from the intersection of my passion for software engineering, artificial intelligence, and fair hiring practices. The recent advancements in LLMs, particularly Claude Sonnet 4.x's exceptional code understanding capabilities, made this ambitious vision achievable.
What it does
AI Recruiter 2.0 is a comprehensive technical hiring platform that transforms how organizations evaluate software engineering candidates. Here's the end-to-end workflow:
1. Resume & Job Description Analysis
- Extracts text from PDF/DOCX resumes using intelligent table and content parsing
- Performs Named Entity Recognition (NER) on both resumes and job descriptions using multiple LLMs (OpenAI, Claude, Gemini, Mistral, Grok)
- Identifies skills, experience, education, certifications, projects, and GitHub repositories
2. Multi-Repository Code Analysis
- Automatically ingests code from candidate's GitHub repositories
- Evaluates code quality across 5 different LLMs in parallel:
- OpenAI GPT-4o
- Anthropic Claude Sonnet 4.x
- Google Gemini 2.0 Flash
- Mistral Large
- xAI Grok
- Each LLM independently assesses:
- Code bugs and potential issues
- Optimization opportunities
- Security vulnerabilities (10-point severity scale)
- Code architecture and design patterns
- Best practices adherence
3. Knowledge Graph Construction
This is where AI Recruiter 2.0 truly shines. For each repository, the system builds a comprehensive knowledge graph using Abstract Syntax Tree (AST) analysis:
Entities Extracted:
- Files, Classes, Functions, Methods
- Imports, Dependencies, Annotations
- Function parameters and return types
Relationships Mapped:
CONTAINS: File contains Class, Class contains MethodCALLS: Function calls FunctionINHERITS: Class inherits from ClassIMPORTS: File imports ModuleINSTANTIATES: Class instantiates Class
Graph Representations Generated:
- Adjacency Matrix ($A$)
- Incidence Matrix ($B$)
- Matrix Powers ($A^2$, $A^3$) for indirect coupling analysis
- Graph Laplacian ($L = D - A$) for spectral analysis
4. Mathematical Quality Metrics
Using the knowledge graph, the system computes rigorous quality metrics:
Security Score Calculation
The security score combines static analysis from the knowledge graph with ensemble LLM evaluations:
$$ S_{security} = w_{static} \cdot S_{static} + w_{llm} \cdot S_{llm} $$
where $w_{static} = 0.4$ and $w_{llm} = 0.6$
Static Analysis Score from Knowledge Graph:
$$ S_{static} = \max\left(0, \min\left(100, S_{base} - \sum_{i} n_i \cdot w_i\right)\right) $$
where:
- $S_{base}$ = base security score from static analysis
- $n_i$ = number of issues of severity $i$
- $w_i$ = severity weights: $w_{high} = 5.0$, $w_{medium} = 2.0$, $w_{low} = 0.5$
LLM Ensemble Score:
$$ S_{llm} = \frac{\sum_{k=1}^{N} \left(S_k \cdot r_k\right)}{\sum_{k=1}^{N} r_k} $$
where:
- $N$ = number of LLMs (typically 5)
- $S_k$ = adjusted score from LLM $k$
- $r_k$ = reliability weight for LLM $k$ (OpenAI: 1.0, Claude: 1.0, Gemini: 0.95, Mistral: 0.9, Grok: 0.85)
Each LLM score is adjusted for vulnerability penalties:
$$ S_k = \max\left(0, S_{k,base} - \sum_{v \in V_k} w_{sev}(v)\right) $$
where $V_k$ is the set of vulnerabilities found by LLM $k$, and $w_{sev}$ maps severity (1-10) to penalty weights.
Confidence Interval:
$$ \text{MoE} = 1.96 \cdot \sqrt{w_{static}^2 \cdot \sigma_{static}^2 + w_{llm}^2 \cdot \sigma_{llm}^2} $$
$$ \text{CI} = [S_{security} - \text{MoE}, \quad S_{security} + \text{MoE}] $$
Architecture Quality Score
Architecture score evaluates design patterns, structure, coupling, and lifecycle:
$$ S_{arch} = w_1 \cdot S_{patterns} + w_2 \cdot S_{structure} + w_3 \cdot S_{coupling} + w_4 \cdot S_{lifecycle} $$
where $w_1 = 0.30$, $w_2 = 0.30$, $w_3 = 0.25$, $w_4 = 0.15$
Design Pattern Score:
$$ S_{patterns} = \min\left(100, 0.65 \cdot S_{conformance} + 0.35 \cdot (B_{diversity} + B_{usage}) - P_{anti}\right) $$
where:
- $S_{conformance}$ = pattern conformance score from knowledge graph
- $B_{diversity} = \min(20, 4 \cdot d)$ where $d$ = number of distinct patterns used
- $B_{usage} = \min(15, 2 \cdot p)$ where $p$ = total pattern instances
- $P_{anti}$ = anti-pattern penalty: $\sum_{a} w_a$ (god_class: 10, spaghetti: 15, circular_dep: 12)
Coupling Score using Matrix Powers:
$$ S_{coupling} = 100 - \left(0.35 \cdot C_{direct} + 0.25 \cdot C_{temporal} + 0.20 \cdot C_{complexity} + 0.20 \cdot C_{inheritance}\right) $$
where:
- $C_{direct} = \frac{|A|_0}{n(n-1)} \times 100$ (direct coupling from adjacency matrix)
- $C_{temporal} = \frac{|A^2|_0}{n(n-1)} \times 100$ (2-hop indirect coupling)
- $C_{complexity}$ measures instantiation complexity
- $C_{inheritance}$ measures inheritance-based coupling
Structure Quality Score:
$$ S_{structure} = 0.25 \cdot S_{depth} + 0.25 \cdot S_{avgdepth} + 0.20 \cdot S_{tree} + 0.30 \cdot S_{abstract} - \sum \text{penalties} $$
Penalties include:
- Diamond inheritance: $15 \times n_{diamond}$
- Deep chains (depth > 5): $10 \times n_{deep}$
- Dead classes: $2 \times n_{dead}$
- Bloated classes: $5 \times n_{bloated}$
Maintainability Score
$$ S_{maint} = 0.35 \cdot S_{modularity} + 0.30 \cdot S_{complexity} + 0.20 \cdot S_{quality} + 0.15 \cdot S_{graph} $$
Graph Health Score using Laplacian Analysis:
$$ S_{graph} = f(\lambda_2, \mu, \sigma^2) $$
where:
- $\lambda_2$ = second smallest eigenvalue of graph Laplacian $L = D - A$
- $\mu$ = algebraic connectivity (measures how well-connected the graph is)
- $\sigma^2$ = variance in node degrees
A higher $\lambda_2$ indicates better connectivity and modularity.
Communication Score
$$ S_{comm} = 0.40 \cdot S_{docs} + 0.30 \cdot S_{naming} + 0.30 \cdot S_{readability} $$
Documentation Quality:
$$ S_{docs} = \min\left(100, C_{coverage} \cdot Q_{quality} \cdot (1 + B_{completeness})\right) $$
where:
- $C_{coverage} = \frac{n_{documented}}{n_{total}} \times 100$
- $Q_{quality}$ = average documentation quality score
- $B_{completeness}$ = bonus for comprehensive documentation
5. Ensemble Score Aggregation
The final candidate score aggregates all dimensions with variance-based confidence:
$$ S_{final} = \sum_{d \in D} w_d \cdot s_d \cdot c_d $$
where:
- $D$ = {resume_fit, coding, security, architecture, maintainability, communication}
- $w_d$ = dimension weight
- $s_d$ = dimension score
- $c_d$ = dimension confidence
Overall Confidence Calculation:
$$ C_{overall} = \frac{\sum_{d} c_d \cdot w_d}{\sum_{d} w_d} $$
Data Completeness:
$$ D_{comp} = \frac{|D_{available}|}{|D_{total}|} \times 100 $$
Confidence Interval with Variance Propagation:
$$ \sigma_{total}^2 = \sum_{d \in D} w_d^2 \cdot \sigma_d^2 $$
$$ \text{CI}{final} = \left[S{final} - 1.96\sqrt{\sigma_{total}^2}, \quad S_{final} + 1.96\sqrt{\sigma_{total}^2}\right] $$
6. Technical Question Generation
- Generates domain-specific technical questions based on candidate's code and resume
- Questions are tailored to the candidate's expertise areas
- Can be used for subsequent interview rounds
7. Explainable Results & Compliance
- Provides detailed explanations for every score component
- Generates comprehensive candidate evaluation reports in Markdown format
- Tracks strengths, weaknesses, and specific recommendations
- Ensures hiring decisions are auditable and compliant with regulations
8. Interactive Visualization Dashboard
Built with Next.js and React, featuring:
- Executive Summary with consolidated scores
- Detailed breakdown of all 6 scoring dimensions
- Knowledge Graph visualization (interactive D3.js + static PlantUML/Mermaid)
- Security Analysis tab with vulnerability breakdown
- Semantic Analysis showing detected design patterns and anti-patterns
- Architecture diagrams and call tree visualizations
- Side-by-side LLM comparison for code evaluation
- Workflow timing analysis
How I built it
Architecture Overview
--------------------------------------------------------------------
┌─────────────────────────────────────────────────────────────┐
│ Frontend (Next.js) │
│ [Executive Summary] [Detailed Analysis] [Job Match] [...] │
└────────────────────┬────────────────────────────────────────┘
│ REST API
┌────────────────────▼────────────────────────────────────────┐
│ FastAPI Backend (Python) │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Workflow Orchestrator (DAG) │ │
│ │ [Resume NER] → [Code Ingest] → [Multi-LLM Eval] │ │
│ │ ↓ ↓ ↓ │ │
│ │ [JD NER] → [KG Build] → [Quality Calc] → [Scoring] │ │
│ └──────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌────────────┴────────────┬──────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ DuckDB │ │ Neo4j │ │ File System │
│ (Workflow │ │ (Knowledge │ │ (Results │
│ Metadata) │ │ Graph) │ │ Storage) │
└──────────────┘ └──────────────┘ └──────────────┘
│ │
▼ ▼
┌──────────────────────┐ ┌──────────────────────┐
│ Provision for using │ │ Provision for using │
│ MySQL/PostgreSQL │ │ MongoDB in production│
│ Not used or tested │ │ Not used or tested │
│ though in my proj │ │ though in my proj │
└──────────────────────┘ └──────────────────────┘
--------------------------------------------------------------------
Technology Stack
Backend:
- Python 3.9+ for core logic
- FastAPI for REST API server (async, high-performance)
- DuckDB for lightweight workflow state management
- Neo4j for knowledge graph storage and querying
- NumPy/SciPy for matrix operations and numerical computations
- NetworkX for graph algorithms
- Tree-sitter for multi-language AST parsing
- Jedi LSP for Python-specific analysis
Frontend:
- Next.js 14 (App Router)
- React 18 with TypeScript
- Tailwind CSS for styling
- Shadcn/ui for component library
- D3.js for interactive graph visualization
- Recharts for data visualization
- Lucide React for icons
LLM Integrations:
- OpenAI API (GPT-4o)
- Anthropic API (Claude Sonnet 4.x)
- Google Gemini API (Gemini 2.0 Flash)
- Mistral AI API
- xAI Grok API
Development Journey
Phase 1: Foundation (Weeks 1-2)
Started with basic resume parsing and NER using OpenAI. Implemented text extraction for PDF/DOCX using pdfplumber and python-docx. Built the DAG orchestrator using a custom TaskThread class for parallel task execution.
Phase 2: Multi-LLM Integration (Weeks 3-10)
Integrated 5 different LLM providers with consistent interfaces. Each provider has dedicated modules:
codeevalopenai.py,codeevalanthropic.py,codeevalgemini.py,codeevalmistral.py,codeevalgrok.py- Standardized JSON response schemas across all LLMs
- Implemented parallel execution using Python threading
- Thread based simple DAG implementation
- Interview Question Generation
- Resume / JD Fit
- Orchestrate the complete workflow
Phase 3a: Knowledge Graph Research Papers (Weeks 10-15)
Read the research papers on Knowledge Graph to understand it and learn Graph theory to understand how Graph can solve code analysis problems Read and understand AST extractor Understand Neo4J Graph Database Install and Try out Neo4J Graph Database
Phase 3: Knowledge Graph Engine (Weeks 16-21)
This was the most challenging and rewarding phase:
Multi-Language AST Parsing:
- Initially focused on Python using
astmodule - Expanded to Java, JavaScript, TypeScript, C++, Go using Tree-sitter
- Built unified entity extraction pipeline handling all languages
Graph Construction:
# Simplified entity extraction flow
def extract_entities(repo_path):
entities = {'files': [], 'classes': [], 'functions': []}
relationships = []
for file in traverse_files(repo_path):
tree = parse_ast(file)
# Extract entities
for node in tree:
if isinstance(node, ClassDef):
entities['classes'].append(extract_class_info(node))
relationships.append(('FILE', 'CONTAINS', 'CLASS'))
elif isinstance(node, FunctionDef):
entities['functions'].append(extract_function_info(node))
relationships.append(('FILE', 'CONTAINS', 'FUNCTION'))
# Extract calls
for call in extract_calls(tree):
relationships.append(('FUNCTION', 'CALLS', 'FUNCTION'))
return entities, relationships
Matrix Generation:
def build_adjacency_matrix(entities, relationships):
n = len(entities)
A = np.zeros((n, n))
entity_to_idx = {e['id']: i for i, e in enumerate(entities)}
for (source, rel_type, target) in relationships:
if rel_type in ['CALLS', 'IMPORTS', 'INSTANTIATES']:
i = entity_to_idx[source]
j = entity_to_idx[target]
A[i][j] = 1
return A
Neo4j Integration:
- Implemented batch processing (200 entities per batch) to avoid memory exhaustion
- Added automatic connection recovery for large datasets
- Split complex statistics queries to prevent timeouts
- Used Cypher queries for graph traversal and analysis
Phase 4: Mathematical Quality Metrics (Weeks 22-25)
Implemented the scoring calculators:
Security Calculator (src/ensemblescore/security_calculator.py):
- Weighted ensemble of static analysis and LLM evaluations
- Variance-based confidence intervals
- Vulnerability severity classification
Architecture Calculator (src/ensemblescore/architecture_calculator.py):
- Design pattern detection from knowledge graph
- Inheritance hierarchy analysis
- Coupling metrics using matrix powers
- Lifecycle quality assessment
Quality Metrics (src/knowledgegraph/quality_metrics.py):
- Matrix-based coupling analysis using $A^2$, $A^3$
- Graph Laplacian spectral analysis for modularity
- Clustering coefficient computation
- Architectural distance metrics
Ensemble Aggregator (src/ensemblescore/ensemble_aggregator.py):
- Imputation for missing scores (median-based)
- Variance propagation for confidence intervals
- Data completeness tracking
- Quality level classification
Phase 5: Frontend Dashboard (Weeks 26-31)
Built a professional, responsive UI:
Key Components:
ConsolidatedScoringTabV2.tsx: Main scoring dashboard with radar chartsDetailedAnalysisTab.tsx: Dimension-by-dimension breakdownKnowledgeGraphTab.tsx: Interactive graph visualization with D3.jsSemanticAnalysisTab.tsx: Design pattern analysis with filteringCodeQualityTab.tsx: Side-by-side LLM comparison
Challenges Solved:
- Real-time workflow progress tracking
- Large graph visualization performance (10,000+ nodes)
- Responsive layout for complex data tables
- State management for multi-tab interface
Phase 6: Debugging & Bug Fixes (Week 32+)
The final week before submission revealed critical bugs:
Ensemble Score Bug: All dimension scores showing 50.0 instead of actual values. After investigation, found that the score key mapping was incorrect:
# Bug: Looking for 'overall_score' in all files
score = dimension_data.get('overall_score', 0.0)
# Fix: Map each dimension to its correct key
score_key_mapping = {
'security_awareness': 'security_score',
'architecture_quality': 'architecture_score',
'maintainability': 'maintainability_score',
'communication': 'communication_score'
}
Neo4j Session Timeouts: Large repositories (10,000+ entities) caused Neo4j session timeouts. Fixed with:
- Batch processing with exponential backoff retry
- Connection pooling and session recovery
- Query optimization and result streaming
Key Technical Decisions
Why DuckDB over PostgreSQL?
- Lightweight, embedded, no server required
- Excellent performance for analytical queries
- ACID compliance with WAL support
- Easy deployment and backup
Why Neo4j for Knowledge Graph?
- Native graph database with optimized traversal
- Cypher query language for complex pattern matching
- Excellent visualization tools (Neo4j Browser)
- Scalable to millions of nodes
Why Multiple LLMs?
- Reduces single-model bias
- Each LLM has different strengths (Claude for reasoning, GPT-4 for comprehensive analysis)
- Ensemble scoring provides higher confidence
- Allows comparison and validation
Why Matrix-Based Quality Metrics?
- Mathematically rigorous and reproducible
- Well-established graph theory foundations
- Enables spectral analysis (eigenvalues) for deep insights
- Computational efficiency with NumPy/SciPy
Challenges I ran into
1. Multi-Language AST Parsing Complexity
Problem: Different programming languages have vastly different syntax and semantics. Python's ast module works great for Python but does not work well with Java or JavaScript.
Solution:
- Adopted Tree-sitter, a universal parser generator
- Built language-specific extractors with unified interface
- Handled edge cases like anonymous functions, closures, decorators
Code Snippet:
def parse_with_tree_sitter(file_path, language):
parser = Parser()
parser.set_language(LANGUAGE_LIBS[language])
with open(file_path, 'rb') as f:
tree = parser.parse(f.read())
return tree.root_node
2. Neo4j Memory Exhaustion & Session Timeouts
Problem: Loading large repositories (15,000+ entities) into Neo4j caused:
- Memory pool exhausted (250 MiB limit)
- SessionExpired errors during batch operations
- Connection timeouts during statistics queries
Solution:
# Batch processing with retry logic
def create_entities_batch(entities, batch_size=200, max_retries=3):
for i in range(0, len(entities), batch_size):
batch = entities[i:i+batch_size]
retry_count = 0
while retry_count < max_retries:
try:
with driver.session() as session:
session.write_transaction(create_nodes, batch)
break
except (SessionExpired, ServiceUnavailable) as e:
retry_count += 1
time.sleep(2 ** retry_count) # Exponential backoff
if retry_count >= max_retries:
raise
Statistics Query Optimization:
# Before: Single complex query (failed with large graphs)
stats = session.run("""
MATCH (n)
OPTIONAL MATCH (n)-[r]->()
RETURN count(n), count(r), avg(size((n)--()))
""")
# After: Split into multiple efficient queries
node_count = session.run("MATCH (n) RETURN count(n)").single()[0]
edge_count = session.run("MATCH ()-[r]->() RETURN count(r)").single()[0]
avg_degree = session.run("MATCH (n) RETURN avg(size((n)--()))").single()[0]
3. LLM Response Schema Inconsistency
Problem: Different LLMs return responses in slightly different formats. Some use arrays, others use objects; some capitalize keys differently.
Solution:
- Created
LLMResponseNormalizerclass - Implemented robust JSON parsing with fallbacks
- Standardized schema using Pydantic models
class SecurityEvaluation(BaseModel):
overall_rating: str
number_of_security_vulnerabilities: int
securityVulnerabilities: List[VulnerabilityDetail]
def normalize_llm_response(raw_response, llm_provider):
# Handle different response formats
if llm_provider == 'gemini':
# Gemini wraps in 'candidates'
return raw_response['candidates'][0]['content']
elif llm_provider == 'claude':
# Claude uses 'content' array
return raw_response['content'][0]['text']
else:
# OpenAI, Mistral use 'choices'
return raw_response['choices'][0]['message']['content']
4. Confidence Interval Calculation Accuracy
Problem: Initial confidence intervals were too wide (±30-40 points), making scores meaningless.
Challenge: How to properly propagate variance across weighted dimensions?
Solution: Implemented variance propagation formula: $$ \sigma_{total}^2 = \sum_{i=1}^{n} w_i^2 \cdot \sigma_i^2 $$
Key Insight: Realized that when scores are missing, I shouldn't use zero variance. Instead:
# Wrong approach
if score_missing:
variance = 0.0 # Misleading - implies high confidence
# Correct approach
if score_missing:
score = median_imputation(other_scores)
variance = (penalty_range * 0.5) ** 2 # Reflects uncertainty
5. Frontend Graph Visualization Performance
Problem: Rendering 10,000+ nodes in D3.js caused browser freezes.
Solution:
- Implemented level-of-detail (LOD) rendering
- Added graph sampling for large graphs
- Used force simulation with optimized parameters
- Implemented virtual scrolling for node lists
// Force simulation optimization
const simulation = d3.forceSimulation(nodes)
.force("link", d3.forceLink(links).distance(50))
.force("charge", d3.forceManyBody().strength(-30))
.force("center", d3.forceCenter(width / 2, height / 2))
.alphaDecay(0.05) // Faster convergence
.velocityDecay(0.4); // Reduced oscillation
// LOD rendering
function shouldRenderNode(node, zoomLevel) {
if (zoomLevel > 2) return true; // Show all at high zoom
return node.degree > threshold; // Show only important nodes
}
6. Ensemble Score Aggregation Bug
Problem: All security, architecture, maintainability, and communication scores showed exactly 50.0, even though individual score files had correct values like 72.44, 64.71, etc.
Root Cause: The extract_dimension_score() function was looking for 'overall_score' key in ALL dimension files, but each calculator saves scores with dimension-specific keys ('security_score', 'architecture_score', etc.).
Investigation Process:
# Checked individual files - had correct scores
cat security_score.json # {"security_score": 64.71, ...}
cat architecture_score.json # {"architecture_score": 69.98, ...}
# But aggregated file showed 50.0
cat ensemble_aggregated_score.json # All dimensions: 50.0
The Fix:
# Added proper key mapping
score_key_mapping = {
'resume_job_fit': 'overall_score',
'coding_proficiency': 'overall_score',
'security_awareness': 'security_score',
'architecture_quality': 'architecture_score',
'maintainability': 'maintainability_score',
'communication': 'communication_score'
}
score_key = score_key_mapping.get(dimension, 'overall_score')
score = dimension_data.get(score_key, 0.0)
# Fallback to overall_score if primary key not found
if score == 0.0:
score = dimension_data.get('overall_score', 0.0)
Impact: This single bug was causing incorrect candidate rankings. After the fix, scores correctly reflected actual quality metrics, changing a candidate's final score from 52.28 to 55.43 in one case.
7. Datetime Deprecation Warnings
Problem: Python 3.12+ deprecates datetime.utcnow() in favor of timezone-aware datetimes.
Quick Fix:
# Before
timestamp = datetime.utcnow().isoformat()
# After
timestamp = datetime.now().isoformat()
Accomplishments that I am proud of
1. Mathematical Rigor in Scoring
Most AI recruiting tools provide subjective scores with no theoretical foundation. AI Recruiter 2.0's scores are based on:
- Graph theory (adjacency matrices, Laplacian analysis)
- Statistical ensemble methods (weighted voting, variance propagation)
- Information theory (entropy-based complexity)
This makes our scores reproducible, explainable, and defensible in regulatory contexts.
2. Multi-LLM Ensemble Architecture
Successfully integrated 5 different LLM providers with:
- Parallel execution (5x speedup)
- Reliability-weighted aggregation
- Outlier detection using z-scores
- Confidence quantification
The ensemble approach reduces bias and increases confidence compared to single-model systems.
3. Knowledge Graph at Scale
Built a production-ready knowledge graph system that:
- Handles repositories with 10,000+ entities
- Supports 8+ programming languages
- Generates mathematical matrices for quality analysis
- Integrates with Neo4j for advanced querying
- Recovers from connection failures automatically
The graph construction pipeline processes typical repositories in under 2 minutes.
4. Comprehensive Visualization Dashboard
Created a professional UI that makes complex data accessible:
- Executive summary with consolidated scoring
- Interactive knowledge graph visualization
- Side-by-side LLM comparison
- Detailed breakdowns with confidence intervals
- Exportable reports in Markdown format
5. End-to-End Workflow Automation
From resume upload to final candidate report, everything is automated:
- DAG-based orchestration with progress tracking
- Parallel task execution
- Error handling and retry logic
- Persistent state management with DuckDB
A complete analysis (resume + 3 repositories) completes in approximately 8-12 minutes.
6. Explainability & Compliance
Every score comes with:
- Mathematical formula showing how it was calculated
- Component breakdowns (e.g., design patterns, coupling, complexity)
- Confidence intervals based on statistical variance
- Strengths and weaknesses in natural language
- Specific recommendations for improvement
This level of transparency is crucial for:
- Regulatory compliance (EEOC, GDPR)
- Candidate feedback
- Hiring manager decision support
7. Real Production-Ready Features
- API key management from home directory
- Comprehensive error logging
- Graceful degradation (works with partial data)
- Backward compatibility with old workflow formats
- Configurable batch sizes and retry limits
What I learnt
Technical Skills
Advanced Graph Theory Applications
- Matrix powers for indirect coupling ($A^2$, $A^3$)
- Graph Laplacian eigenvalue analysis for connectivity
- Spectral clustering for module detection
- Centrality measures (betweenness, closeness) for identifying critical components
Multi-Language AST Parsing
- Tree-sitter parser integration
- Language-specific syntax quirks (Java generics, Python decorators, JavaScript closures)
- Visitor pattern for tree traversal
- Symbol resolution across files
LLM Engineering Best Practices
- Prompt engineering for consistent JSON responses
- Temperature and top_p tuning for different tasks
- Token optimization to reduce API costs
- Retry logic with exponential backoff
- Response validation and normalization
Database Scaling Techniques
- Neo4j batch processing and transaction management
- DuckDB for OLAP workloads
- Connection pooling and session recovery
- Query optimization (indexes, query planning)
Statistical Methods
- Variance propagation in weighted sums
- Confidence interval calculation (t-distribution, normal distribution)
- Outlier detection (z-scores, IQR)
- Imputation strategies (median, mean, regression)
- Ensemble learning (weighted voting, stacking)
Frontend Performance Optimization
- React memoization (useMemo, useCallback)
- Virtual scrolling for large lists
- Debouncing/throttling for expensive operations
- Code splitting and lazy loading
- Web Workers for background computation
Domain Knowledge
Software Quality Metrics
- Coupling vs Cohesion trade-offs
- Cyclomatic complexity interpretation
- Design pattern impact on maintainability
- Technical debt quantification
Hiring & Recruitment Domain
- Legal compliance requirements (EEOC, OFCCP)
- Bias mitigation in AI systems
- Candidate experience considerations
- Hiring manager workflows and pain points
Security Analysis
- Common vulnerability patterns (SQL injection, XSS, hardcoded credentials)
- Severity classification (CVSS-like scoring)
- Static vs dynamic analysis trade-offs
- False positive management
Soft Skills
Problem Decomposition
- Breaking down a complex system (technical hiring) into manageable components
- Identifying critical dependencies and ordering tasks
- Iterative development with rapid prototyping
Debugging Complex Systems
- Systematic investigation (check inputs, intermediate outputs, final results)
- Hypothesis formation and testing
- Root cause analysis vs symptom treatment
Time Management
- Prioritizing features (MVP vs nice-to-have)
- Managing scope creep
- Balancing perfection with deadlines
Technical Communication
- Documenting complex mathematical concepts
- Writing clear API documentation
- Creating user-friendly error messages
Key Insights
Ensemble Methods Are Powerful Combining multiple imperfect models (LLMs) yields better results than relying on a single "best" model. This applies to:
- Scoring algorithms (security, architecture, etc.)
- LLM evaluations
- Quality metrics
Explainability Is As Important As Accuracy A system that produces a score of "87.5" without explanation is useless in high-stakes contexts like hiring. Providing:
- Component breakdowns
- Confidence intervals
- Specific examples
Makes the system trustworthy and actionable.
- Real-World Systems Require Robustness
Theory is great, but production systems must handle:
- Missing data
- API failures
- Unexpected inputs
- Performance constraints
Building in retry logic, fallbacks, and graceful degradation from day one saves hours of debugging later.
Graph Representations Unlock Deep Insights Converting code into graphs enables:
- Automated architecture assessment
- Quantitative quality metrics
- Anomaly detection (e.g., overly coupled modules)
- Visual communication with non-technical stakeholders
UI/UX Matters for AI Systems A powerful AI backend is worthless if users can't understand the results. Investing in:
- Clear visualizations
- Progressive disclosure (summary → details)
- Interactive exploration
Makes the system actually usable.
What's next for AI Recruiter 2.0
Short-term (Next 3 Months)
Architecture Enhancements
- Multi-threading, Performance Improvements, Bug Fixes
- Authentication and Authorization Capabilities
- Terraform based Infra Deployment, K8S
Enhanced Bias Detection
- Implement fairness metrics (demographic parity, equal opportunity)
- Add bias audit reports showing score distributions across demographic groups
- Integrate with Fairlearn for bias mitigation
Interview Question Generation Enhancement
- Generate coding challenges based on candidate's weaknesses
- Create behavioral questions aligned with company values
- Difficulty calibration based on candidate level
Candidate Comparison Mode
- Side-by-side comparison of multiple candidates
- Rank ordering with explainability
- Trade-off analysis (e.g., higher security score vs architecture score)
Integration with ATS Systems
- Workday, Greenhouse, Lever connectors
- Webhook support for real-time updates
- Bulk resume processing
Medium-term (6-12 Months)
Active Learning for Score Refinement
- Collect hiring manager feedback (accept/reject decisions)
- Retrain dimension weights using logistic regression
- Continuous improvement loop
Code Execution Sandbox
- Actually run candidate code with test cases
- Measure performance (runtime, memory)
- Detect runtime errors not caught by static analysis
Behavioral Analysis
- Git commit history analysis (commit frequency, message quality)
- GitHub activity patterns (code reviews, issue discussions)
- Open-source contribution assessment
Multi-Modal Candidate Assessment
- Video interview analysis (speech patterns, confidence)
- Whiteboard problem solving evaluation
- Take-home assignment automated grading
Semantic Code Search
- Natural language queries over knowledge graph
- "Find all authentication-related functions"
- "Show me error handling patterns"
Long-term (1-2 Years)
Predictive Performance Modeling
- Predict candidate's on-the-job performance
- Estimate ramp-up time based on skillset gaps
- Team fit prediction using graph similarity
Automated Skill Gap Analysis
- Compare candidate skills to job requirements
- Generate personalized learning paths
- Recommend training resources
Continuous Candidate Monitoring
- Track candidate's GitHub activity post-application
- Re-evaluate scores as candidates improve skills
- Proactive outreach for significantly improved candidates
Custom Quality Metrics
- Allow companies to define their own quality criteria
- Domain-specific metrics (e.g., HIPAA compliance for healthcare, PCI-DSS for fintech)
- Customizable dimension weights per role
Multi-Company Talent Marketplace
- Candidates create profiles evaluated once
- Multiple companies access anonymized candidate scores
- Reverse job matching (suggest roles to candidates)
AI-Powered Interview Co-Pilot
- Real-time suggestions during interviews
- Follow-up question generation based on candidate responses
- Automated note-taking and summary generation
Research Directions
Graph Neural Networks for Code Quality
- Replace hand-crafted metrics with learned representations
- Train on large corpus of code with quality labels
- Transfer learning across programming languages
Causal Inference in Hiring
- Measure causal effect of specific skills on performance
- A/B testing for hiring criteria
- Counterfactual analysis ("what if candidate had skill X?")
Explainable AI Techniques
- SHAP values for score attribution
- Contrastive explanations ("candidate A scored higher than B because...")
- Interactive what-if analysis
Federated Learning for Privacy
- Train models on company data without centralizing
- Privacy-preserving candidate scoring
- Compliance with GDPR, CCPA
Knowledge Hypergraphs for Multi-Way Code Relationships
- Higher-Order Relationships Beyond Binary Edges: Traditional knowledge graphs model binary relationships (function calls function, class inherits class). Hypergraphs enable modeling of n-ary relationships where multiple entities participate simultaneously. For code analysis, this means capturing:
- Collaborative function patterns: Multiple functions working together to implement a feature (e.g., authentication flow involving validate_token(), check_permissions(), and log_access() as a single hyperedge)
- Design pattern instantiations: Capturing entire pattern implementations (Factory + Builder + Singleton) as atomic units rather than disconnected relationships
- Cross-cutting concerns: Security, logging, and error handling code that spans multiple modules can be represented as hyperedges connecting all affected components
- Higher-Order Relationships Beyond Binary Edges: Traditional knowledge graphs model binary relationships (function calls function, class inherits class). Hypergraphs enable modeling of n-ary relationships where multiple entities participate simultaneously. For code analysis, this means capturing:
Tensor-Based Quality Metrics: While current adjacency matrices $A \in \mathbb{R}^{n \times n}$ capture pairwise relationships, hypergraph tensors $\mathcal{H} \in \mathbb{R}^{n \times n \times \cdots \times n}$ can model k-way dependencies. This enables:
- Multi-dimensional coupling analysis: $C_{hypergraph} = \sum_{e \in E} w_e \cdot |e|$ where $e$ is a hyperedge and $|e|$ is cardinality
- Tensor decomposition (CP/Tucker) for identifying latent architectural patterns not visible in 2D graphs
- Spectral hypergraph theory: Generalized Laplacian $L_{\mathcal{H}} = D_v - H \cdot W \cdot H^T$ where $H$ is incidence matrix, $W$ is hyperedge weights, enabling higher-order connectivity analysis
Context-Aware Semantic Search & Question Answering: Hypergraphs enable semantic queries that understand multi-entity context:
- Query: "How does this codebase handle database transactions?" → Traverse hyperedges connecting transaction_begin(), execute_query(), commit(), rollback() as atomic units
- Contextual similarity: Two code segments are similar if they share hyperedges, not just individual function calls
- LLM-powered hyperedge generation: Use Claude/GPT-4 to identify semantic groupings in code, creating hyperedges for discovered patterns
- Hypergraph neural networks (HGNN) for code representation learning: Message passing over hyperedges captures richer structural information than GNNs
- Application to code clone detection, bug localization, and automatic documentation generation using learned hypergraph embeddings
Closing Thoughts
Building AI Recruiter 2.0 has been an incredible journey combining my passions for software engineering, mathematics, and artificial intelligence. The system demonstrates that AI can be:
- Rigorous: grounded in graph theory and statistics
- Explainable: every score is traceable to its components
- Fair: transparent and auditable for compliance
- Practical: real production-ready features with robust error handling
The positive impact this could have on technical hiring is immense:
- Hiring managers save 10-20 hours per position
- Candidates receive meaningful feedback
- Organizations make data-driven, defensible hiring decisions
- Bias is reduced through systematic evaluation
I'm excited to see where this project goes and how it can evolve to make hiring more efficient, fair, and transparent.
Thank you to Anthropic and Accel for organizing this hackathon and giving me the opportunity to present my project that I'm truly proud of. Special thanks to the Claude Code and Claude 4.x Sonnet model, which was instrumental in code analysis, debugging, providing guidance, and helping write parts of my project! I and Claude Code are partners for this project.
Project Repository: https://github.com/satishkumarvenkatasamy/ai-recruiter-2.0 [Private Repository] [Repoistory will be made public after my M.Tech Project report submission]
Live Demo: Not Yet Hosted In Any Public Facing Server. Will be hosted soon.
Contact: sativenk@gmail.com | +91 99162 45584
LinkedIn: https://www.linkedin.com/in/sativenk/
Appendix: Technical Specifications
System Requirements
- Python 3.9+
- Node.js 18+
- 16GB RAM (8GB minimum)
- 10GB disk space
- Neo4j 5.0+ (optional)
API Keys Required
- OpenAI API key
- Anthropic API key
- Google Gemini API key
- Mistral AI API key (optional)
- xAI Grok API key (optional)
Performance Metrics
- Resume processing: ~5 seconds
- Code repository ingestion: ~30-60 seconds per repo
- LLM evaluation (5 models in parallel): ~2-3 minutes per repo
- Knowledge graph construction: ~1-2 minutes per repo
- Quality metric calculation: ~10-15 seconds
- Total end-to-end workflow: 8-12 minutes for typical candidate (resume + 3 repos)
Scalability
- Tested with repositories up to 15,000 entities
- Handles 100+ concurrent workflows
- Supports resumes up to 20 pages
- Processes job descriptions up to 10 pages
Accuracy Metrics (Based on Manual Validation)
- Resume NER accuracy: ~92%
- Security vulnerability detection recall: ~87%
- Design pattern identification precision: ~89%
- Overall scoring correlation with expert assessment: 0.83 (Pearson correlation)


Log in or sign up for Devpost to join the conversation.