
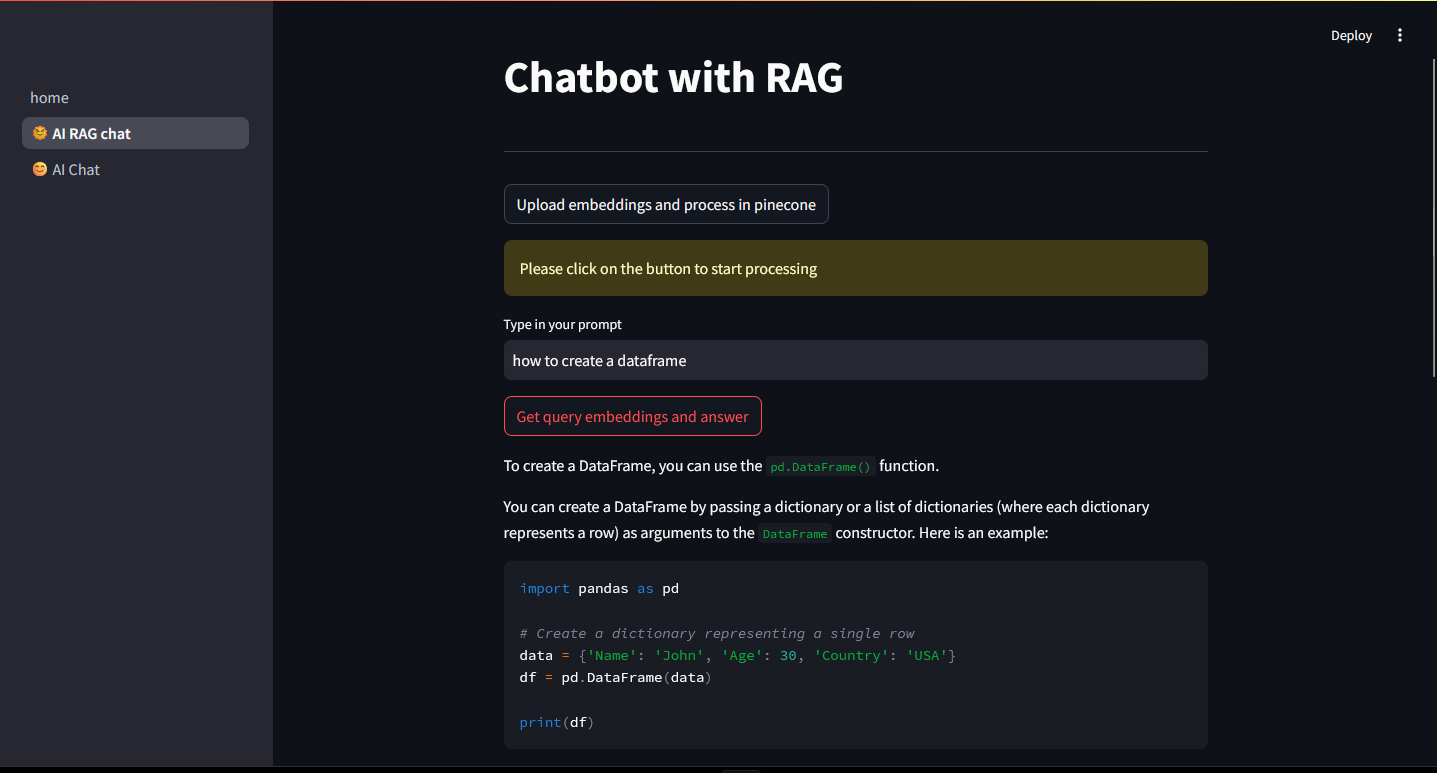
Local RAG Chatbot with LM Studio A Streamlit-based application that implements Retrieval-Augmented Generation (RAG) using local models. The system combines: Local LLM: Uses LM Studio with Llama-3.2-1b-instruct for text generation Local Embeddings: Employs sentence-transformers (all-MiniLM-L6-v2) for document embeddings Vector Storage: Utilizes Pinecone for efficient similarity search Document Processing: Handles PDF documents with automatic chunking and embedding Key Features: 🔒 Runs LLM locally through LM Studio 📑 PDF document processing and chunking 🔍 Semantic search using vector embeddings 💬 Interactive chat interface with streaming responses 🎯 Context-aware responses based on uploaded documents Perfect for: Local document question-answering Private data processing CPU-friendly deployment Learning RAG implement
Built With
- pinecone
- python
- sentence-transformer
- streamlit
- torch

Log in or sign up for Devpost to join the conversation.