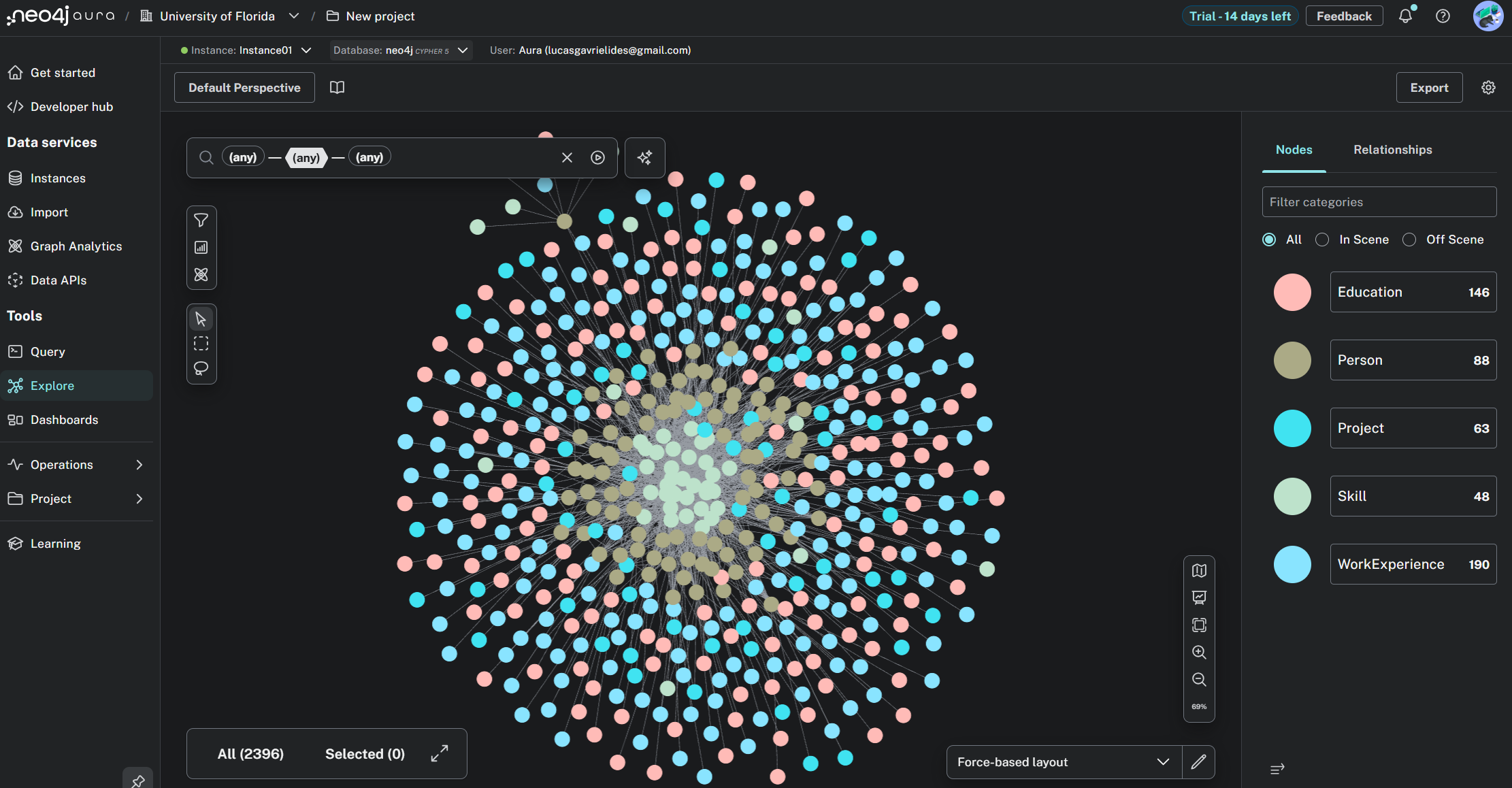
As work changes, teamwork is the norm. Managers need people who have demonstrated the right skills, and have worked on the right projects. In big companies, that proof hides in resumes, enterprise project document, and other miscellaneous company unstructured data, which can make finding the perfect talent match extremely difficult.
SkillPool pulls those sources into a living map of people, skills, and projects. Using GraphRAG on a Neo4j graph, you ask in plain language and get named candidates with cited evidence. It goes beyond keywords by connecting context across documents and time. Under the hood, we pair vector search with graph walks and multi-hop reasoning. We built ingestion, matched identities across systems using an embedding LLM, created a Neo4J graph database, and used queries to traverse through our complex database. The hard parts were a clear graph schema, understanding elements of GraphRAG such as unstructured data ingestion, chunking, entity relation mapping, node insertion, and stable LLM querying. We solved them with ALOT of reiteration and help from LLM's. The result is faster staffing, better matches, and an evidence based LLM generation that can allow managers to make more informed decisions for their talent acquisition.

Log in or sign up for Devpost to join the conversation.