-
-
Interface
-
pdf Uploading
-
PDF Uploaded Successfully
-
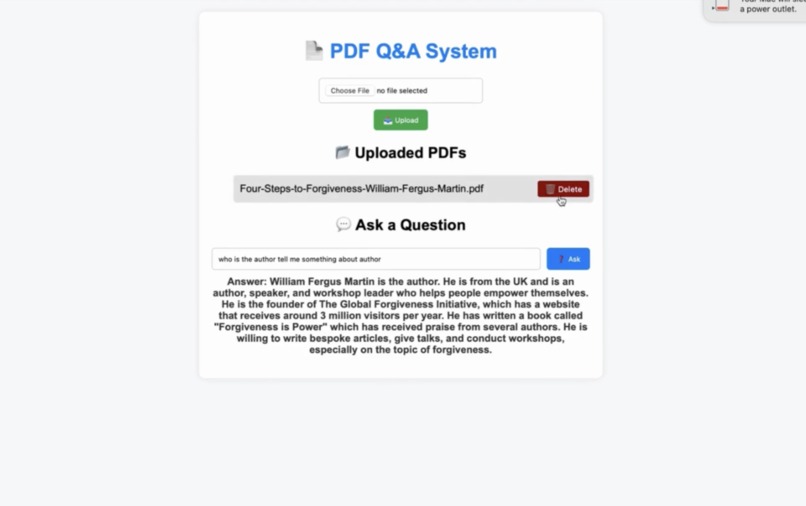
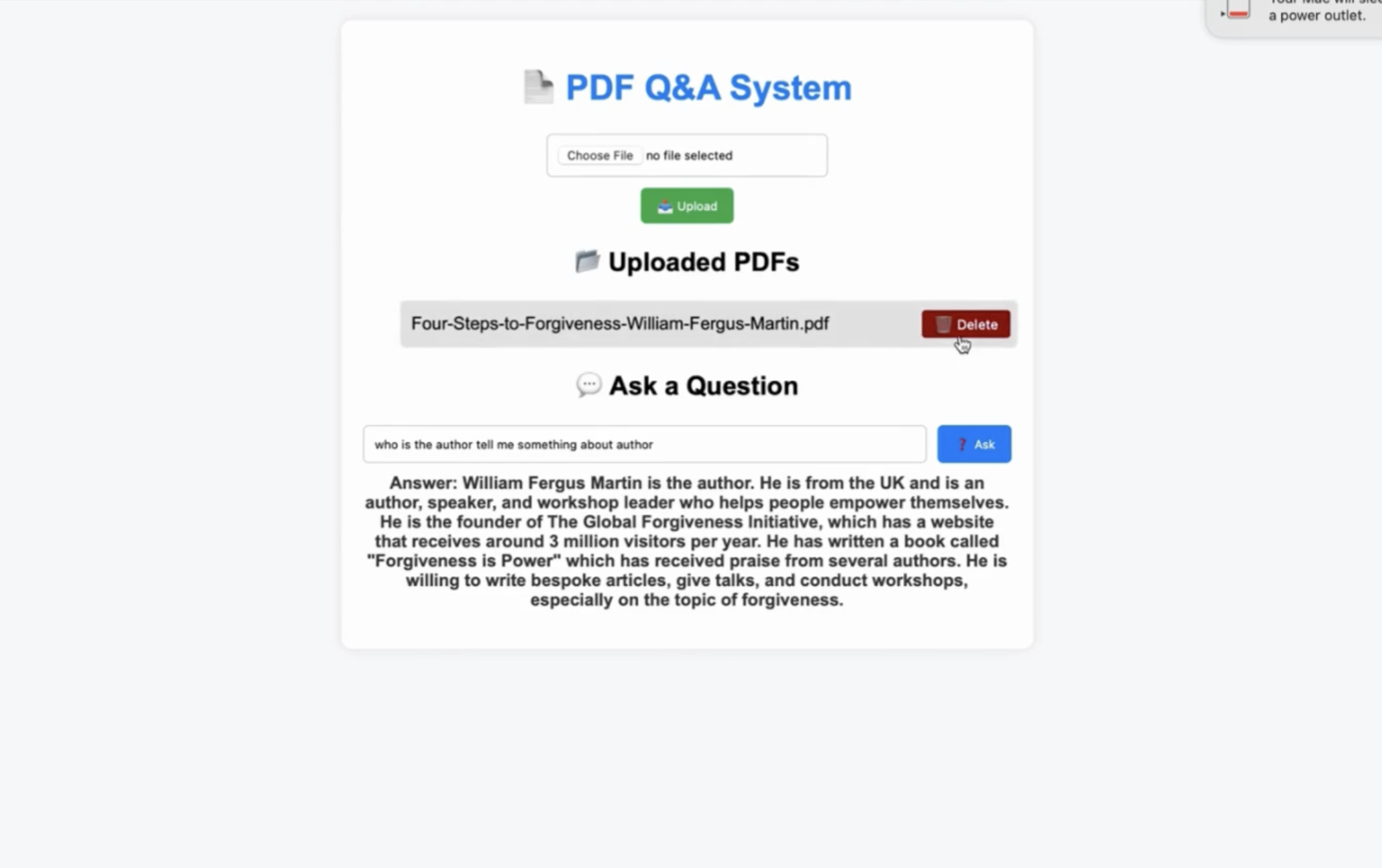
Answered the question related to the PDF
Inspiration
In today’s AI-driven world, simply relying on large language models (LLMs) for question answering is not enough — they can hallucinate or provide outdated information. To solve this, we aimed to build a Retrieval-Augmented Generation (RAG) system that combines the intelligence of LLMs with accuracy of custom datasets or documents. This way, users get responses that are both smart and grounded in facts.
What it does
The AI-Powered RAG System allows users to: Upload a PDF or document. Ask natural language questions about the content. Get answers generated by an LLM, but strictly based on the uploaded data (retrieved and chunked intelligently). In short, it’s like ChatGPT but it knows what’s in your documents.
How we built it
We used: Python for backend processing. LangChain for document chunking and retrieval pipeline. FAISS as the vector store for semantic search. Hugging Face Transformers / OpenAI for LLM responses. Flask as the web framework. HTML/CSS/JS (or Streamlit if used) for the frontend. Workflow: PDF is uploaded. It's split into chunks with metadata. FAISS indexes the chunks. User's question is converted into a vector and matched with top-k chunks. These chunks + question are passed to the LLM for the final answer.
Challenges we ran into
File size and GitHub limits: Encountered issues pushing large files (e.g., ONNX, Torch libs) to GitHub. Solved this by cleaning the repo and adding .gitignore. Vector DB tuning: FAISS required careful tuning to ensure accurate retrieval. Context window limits: Balancing how much chunked data can be sent to the LLM without exceeding token limits. Multi-language support (if applicable) required additional preprocessing.
Accomplishments that we're proud of
Successfully built a working end-to-end RAG system. Enabled domain-specific question answering with custom data. Learned and integrated multiple AI tools: LangChain, FAISS, Hugging Face. Overcame Git and deployment barriers to keep the repo clean and usable.
What we learned
The power and flexibility of LangChain for building advanced retrieval pipelines. How to embed and retrieve documents semantically using FAISS. Real-world issues with file size management in repos, and how to resolve them. How RAG improves accuracy and reduces hallucination compared to standard LLM outputs.
What's next for AI-Powered RAG System
Web deployment using Streamlit Cloud or Hugging Face Spaces. Multi-file or folder upload with indexing across documents. Voice input and output using SpeechRecognition + gTTS. Add user authentication for private document handling. Enable chat history and conversation memory. Support for multiple languages and file types (e.g., Word, CSV).


Log in or sign up for Devpost to join the conversation.