-
-
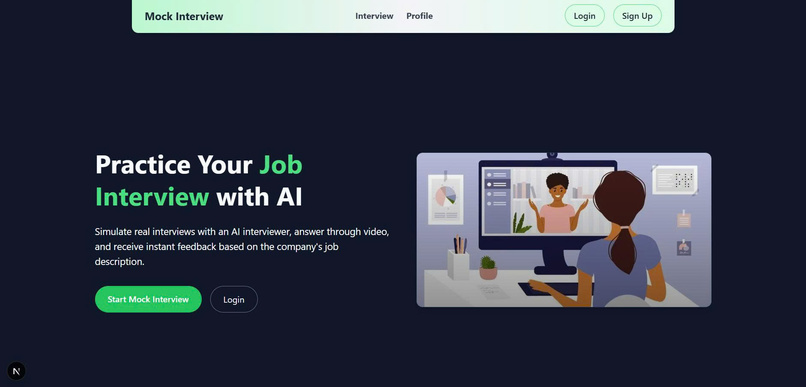
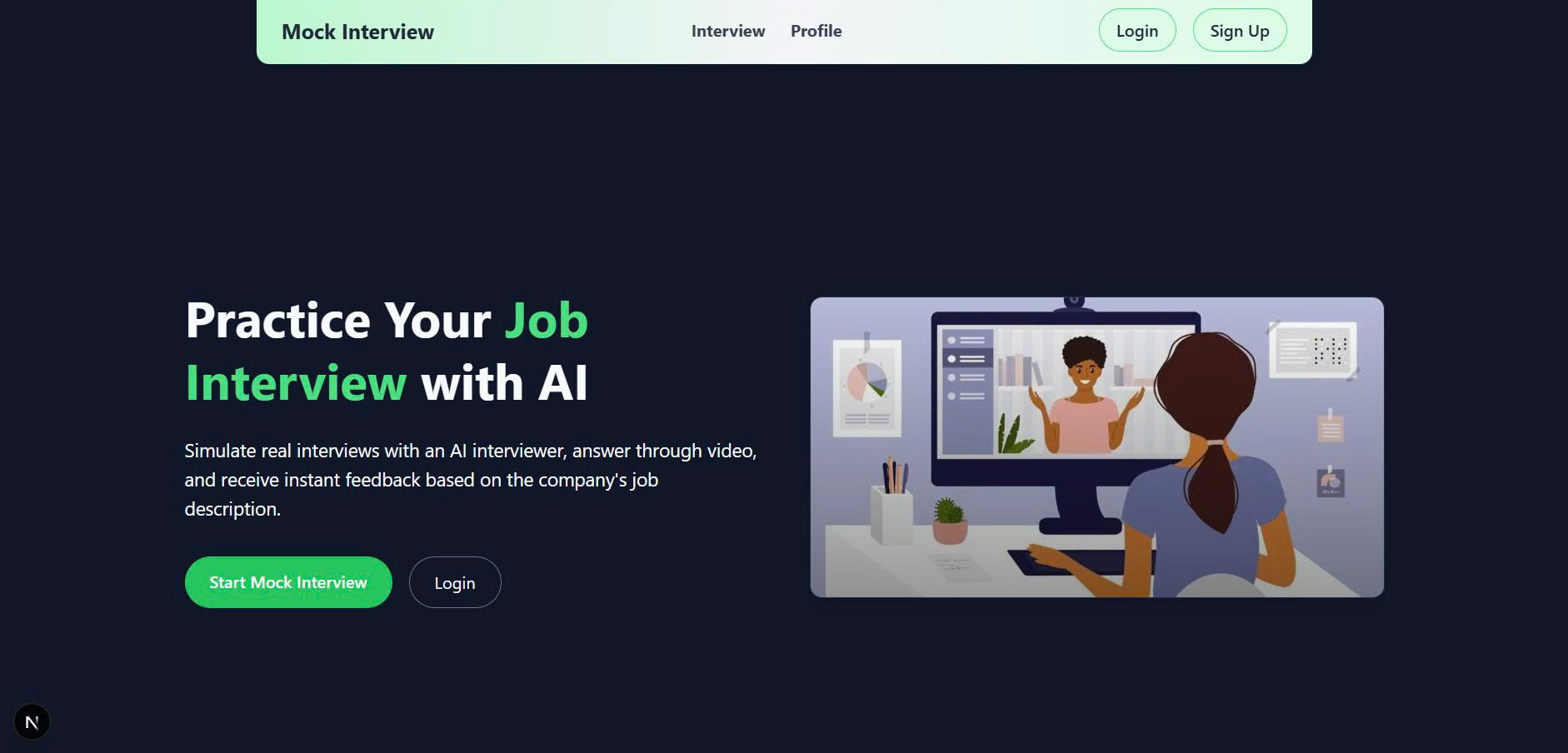
Landing page
-
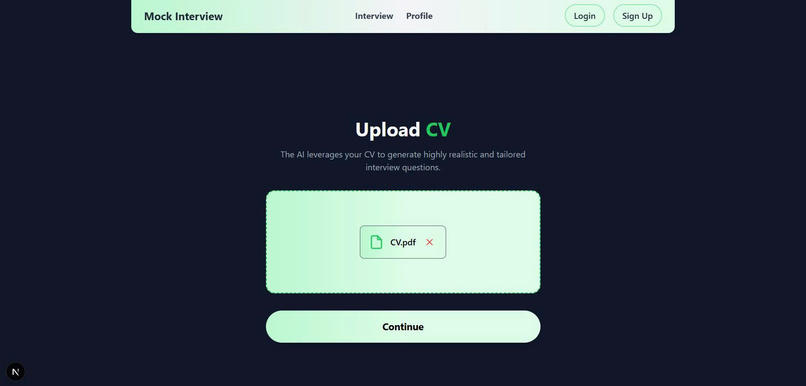
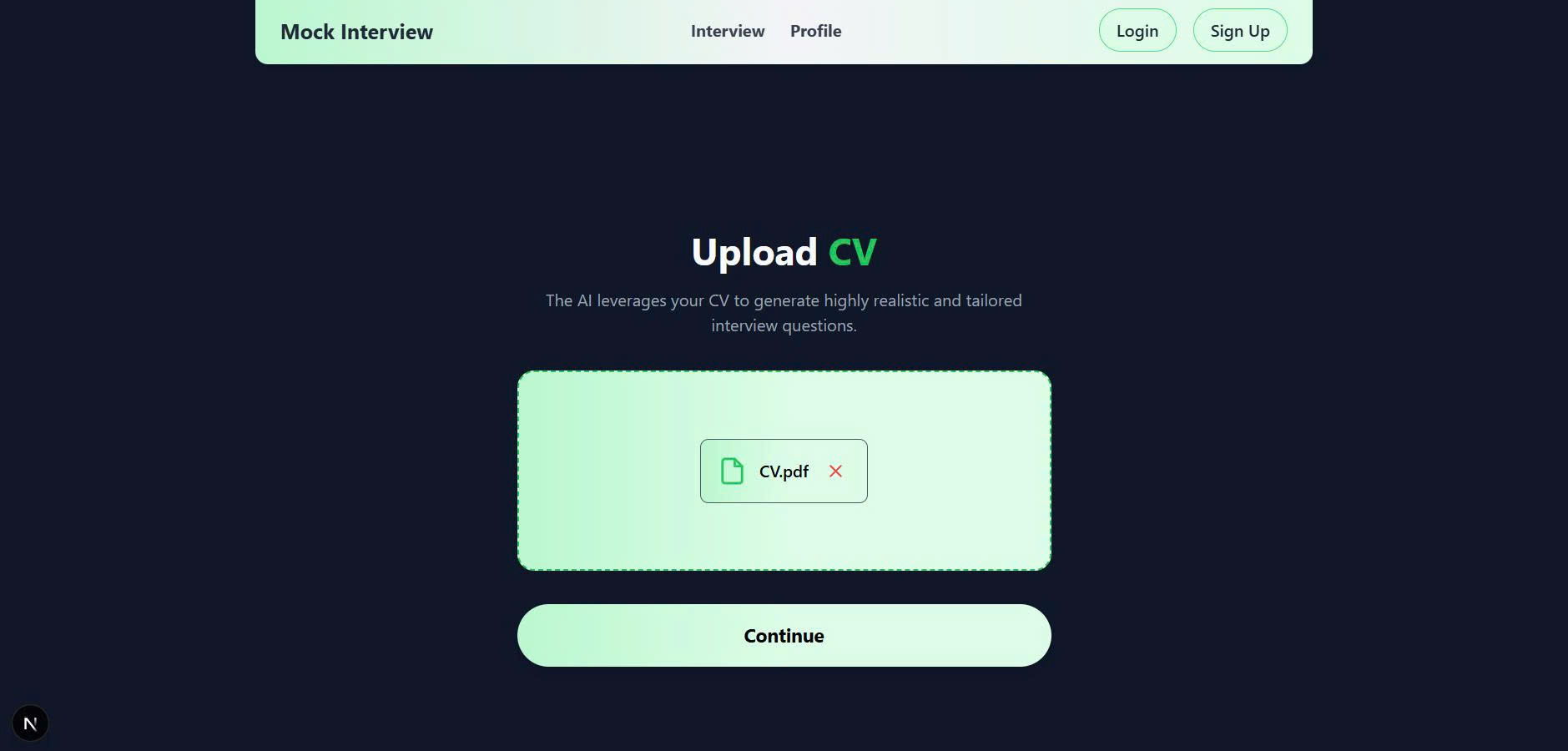
Upload CV
-
Login
-
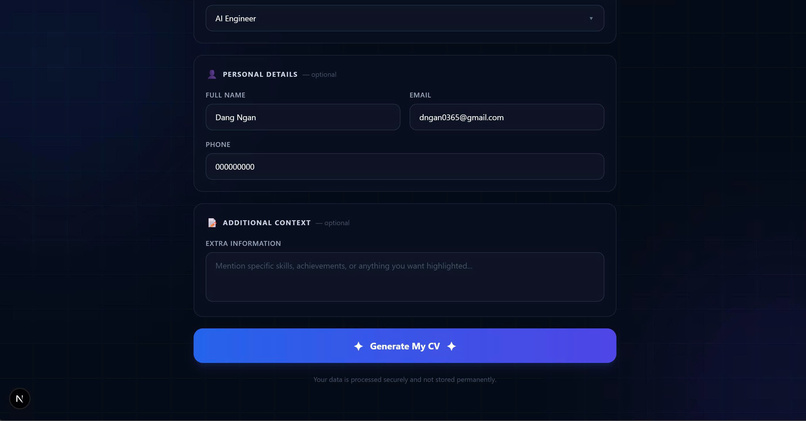
User Information
-
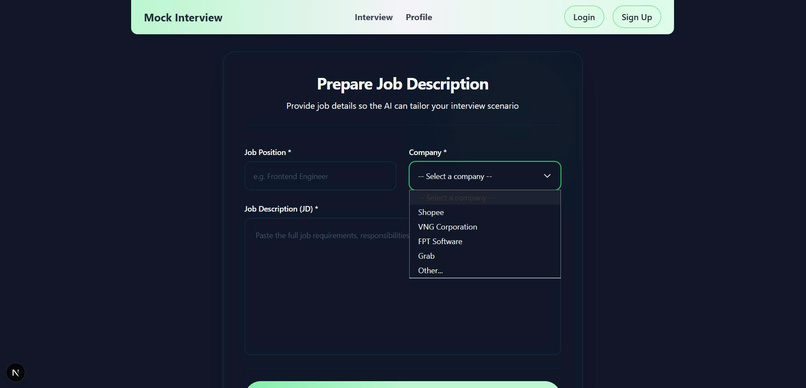
Upload JD
-
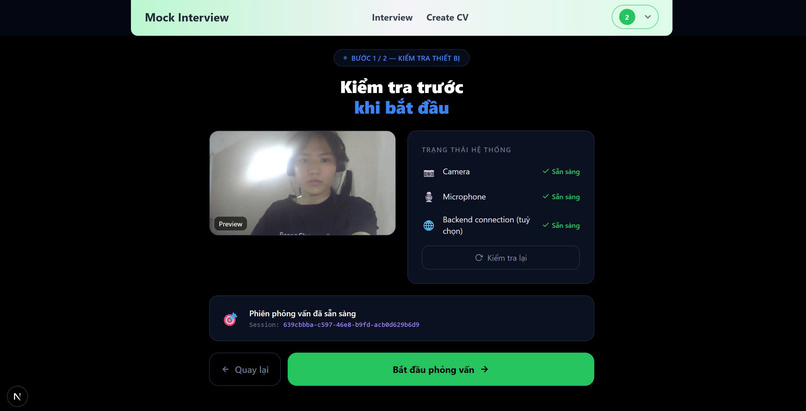
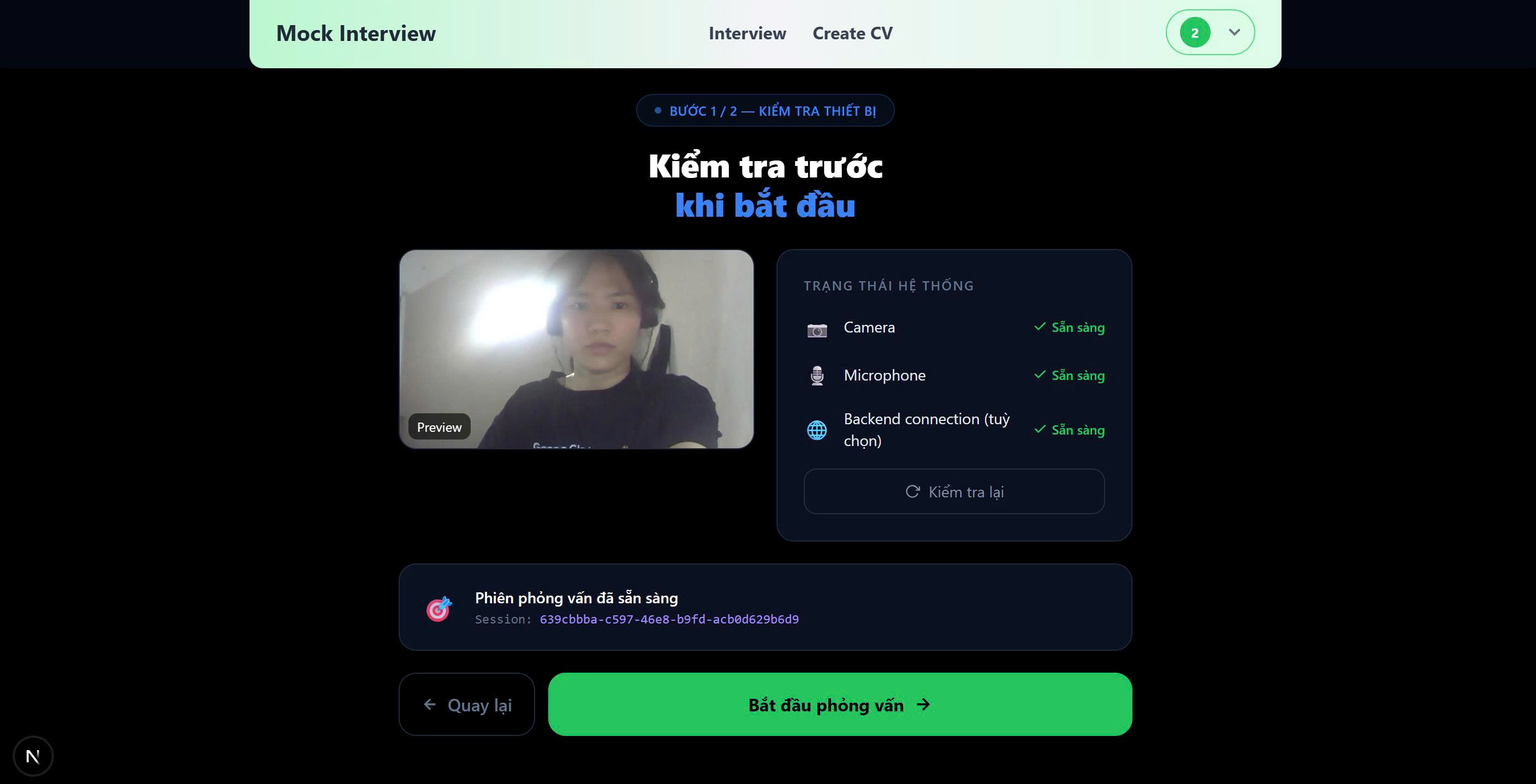
Setup
-
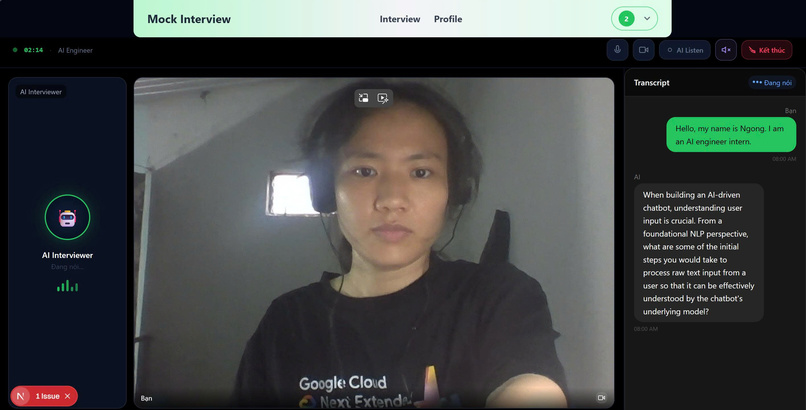
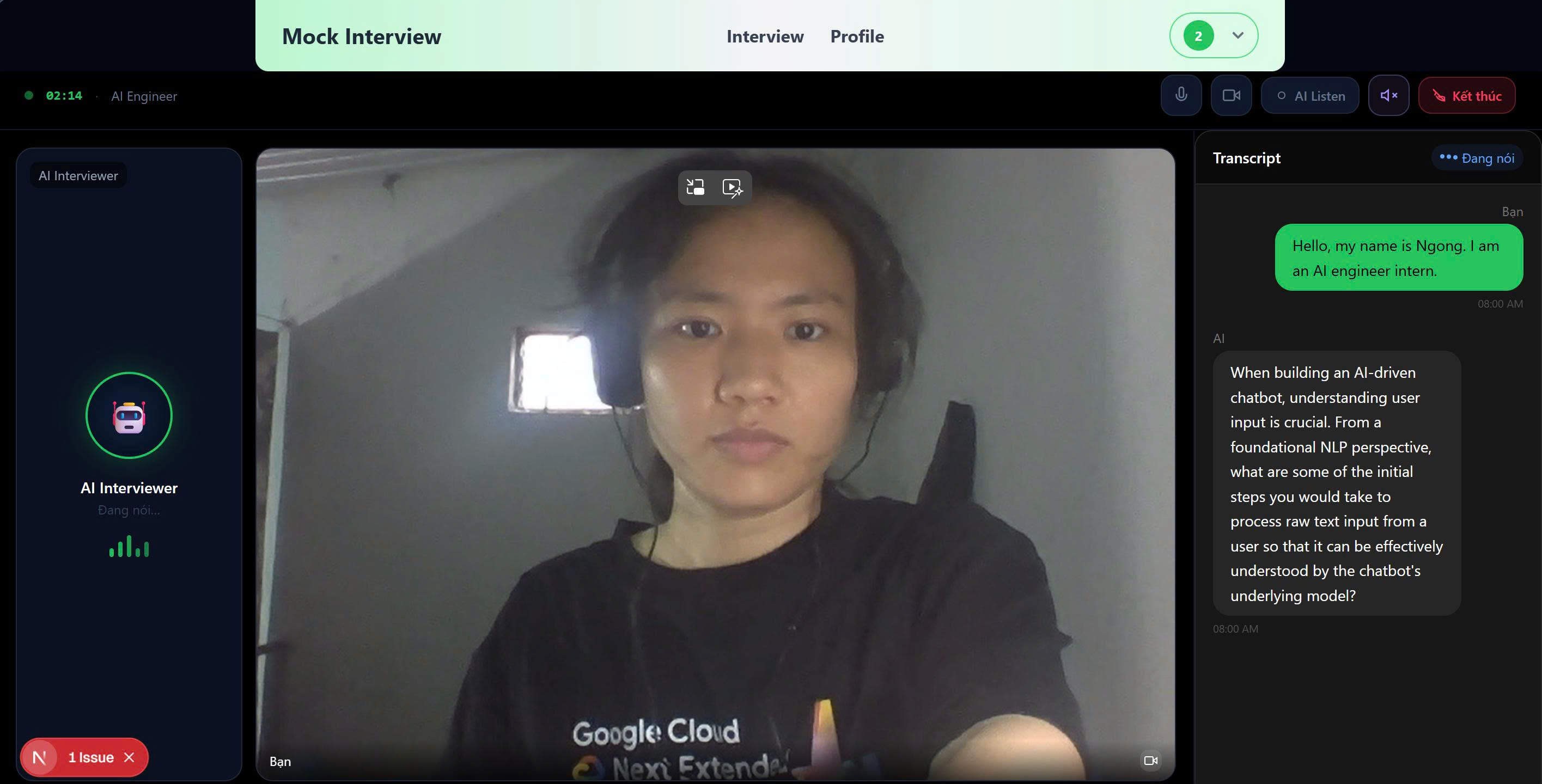
Interview with AI
-
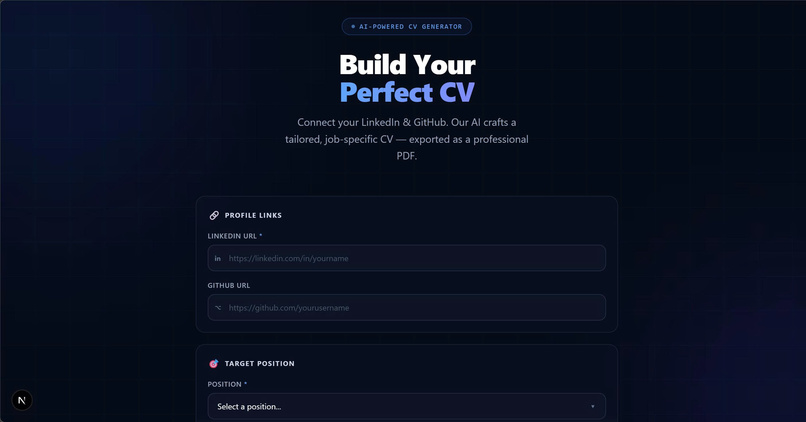
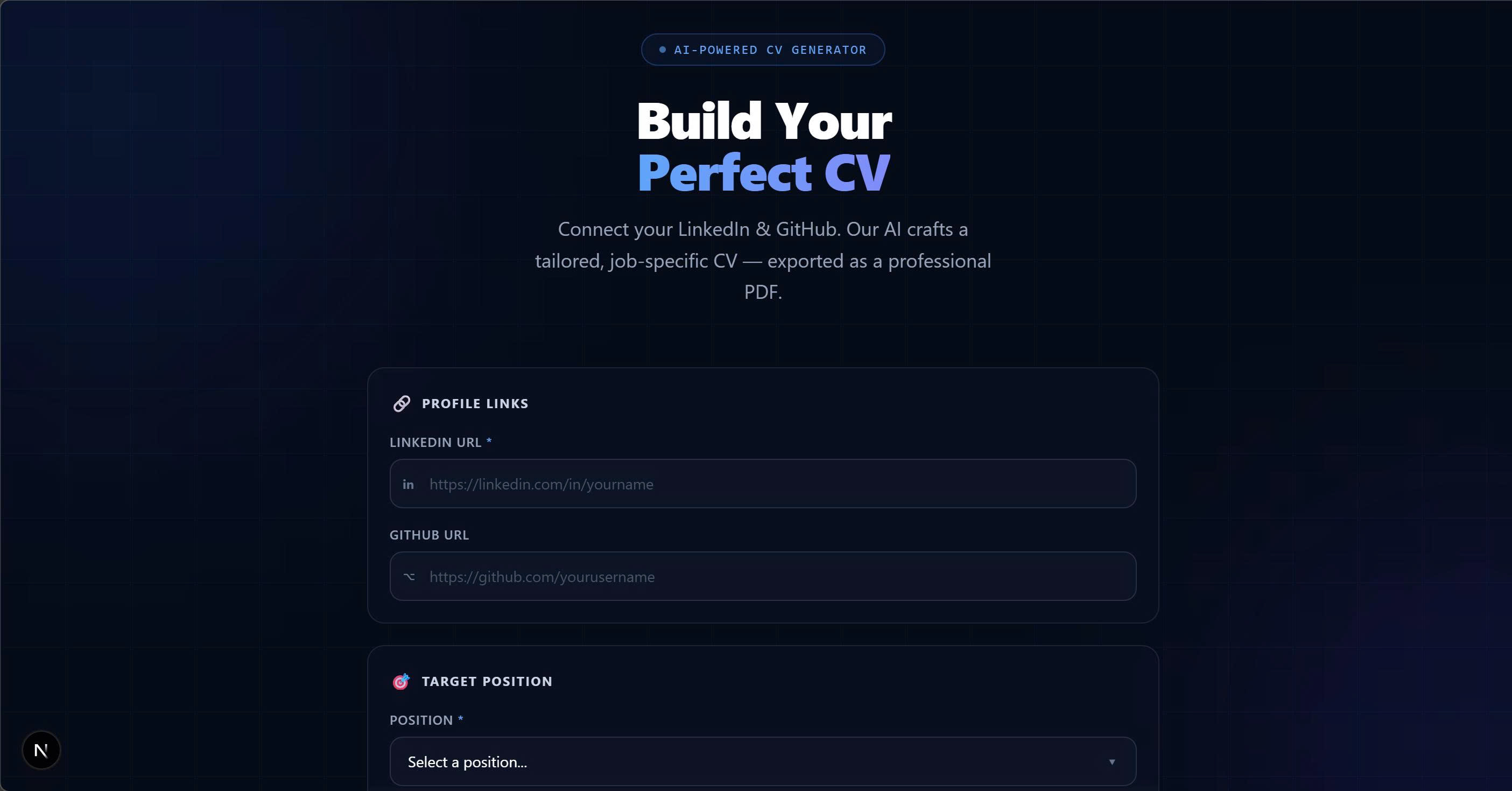
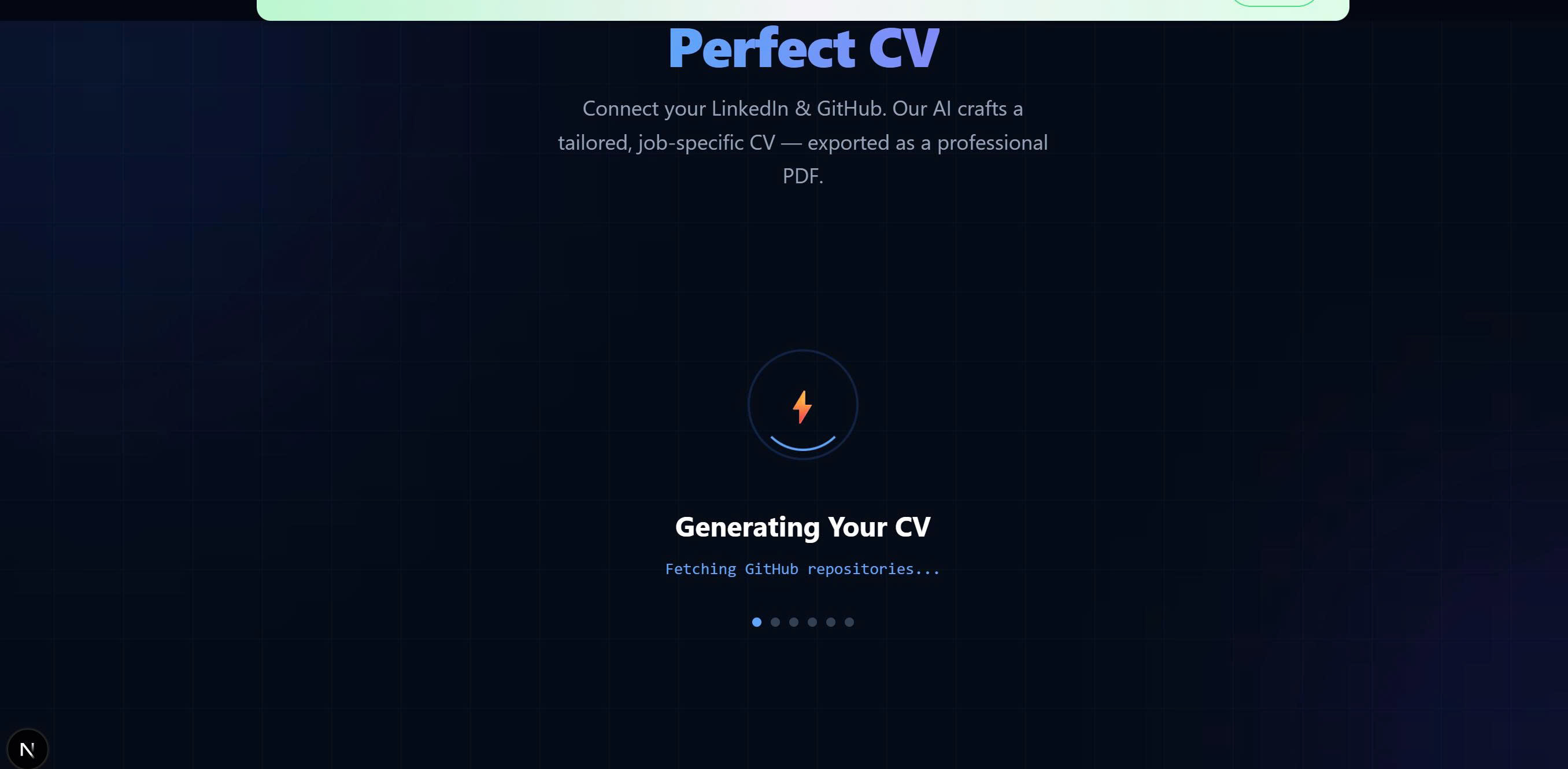
Build CV
-
-
Inspiration
Preparing for technical interviews is challenging, especially for software engineering roles. Many candidates struggle not because they lack technical skills, but because they lack realistic practice and personalized feedback.
Most existing platforms provide generic questions and static evaluations, which do not reflect real interview scenarios or specific job requirements.
We were inspired to build a system that can simulate real, personalized interviews based on a candidate’s profile and target job, and help them continuously improve with actionable insights.
What it does
This project is an AI-powered mock interview and smart CV builder platform.
Mock Interview Simulation
Simulates real interview sessions using:
- CV
- Job role
- Job description
- Company information
Generates:
- Technical and behavioral questions
- Follow-up questions based on user responses
Intelligent Evaluation
Provides structured feedback across:
- Technical skills
- Project explanation
- Communication
- Behavioral performance
Each category is scored on a scale: [ Score \in [1, 10] ]
With detailed explanations and improvement suggestions.
Smart CV Builder
Builds job-specific CVs using:
- GitHub (projects & code analysis)
- LinkedIn (experience)
- Interview history
How we built it
Tech Stack
Frontend
- Next.js (App Router) – interactive UI and smooth interview experience
- React + TypeScript – state management and type safety
- Tailwind CSS – responsive UI with dark/light theme support
- Zustand – lightweight global state management
Backend
- FastAPI (Python) – high-performance API for interview sessions
- PostgreSQL (via Supabase) – persistent storage
- Supabase Auth & Storage – authentication and file handling
- Redis – session memory and caching
AI System
LLM (Gemini / GPT-based):
- Question generation
- Answer evaluation
- CV generation
- Question generation
RAG (Retrieval-Augmented Generation): Combines:
- Job description
- Company data
- User CV
- Job description
Embeddings (sBERT – Vietnamese):
- Semantic search
- Context retrieval
- Semantic search
Vector Database (Weaviate / Qdrant):
- Store embeddings
- Enable semantic retrieval
- Store embeddings
Infrastructure
- AWS S3 / Supabase Storage – file storage
- GitHub API – project analysis
- Environment Configuration (.env):
- NEXT_PUBLIC_API_URL
- SUPABASE_URL
- GEMINI_API_KEY
- REDIS_URL
- MAX_INTERVIEW_QUESTIONS
- QUESTIONS_PER_SECTION
- NEXT_PUBLIC_API_URL
Core Features
AI Mock Interview Engine
- Personalized interview generation
- Multi-step interview flow
- Context-aware follow-up questions
Intelligent Feedback System
- Multi-dimensional evaluation:
- Technical
- Communication
- Behavioral
- Technical
- Structured scoring and explanations
Smart CV Generator
- Job-specific CV creation
- Avoids generic templates
- Uses real user data
RAG-based Personalization
- Context retrieval from multiple sources
- Improves accuracy and relevance
- Reduces hallucination
Conversational Interview Flow
- Chat-based interaction
- Maintains context using Redis
- Dynamic question generation
Real-time Interview Experience
- Camera and microphone integration
- Simulates real interview conditions
Performance Tracking
- Score tracking across sessions
- Continuous improvement insights
Challenges we ran into
Personalized Interview Generation
Ensuring questions match:
- Job role
- Company
- Candidate profile
This required combining multiple data sources effectively.
Consistent AI Evaluation
LLM outputs can be:
- Inconsistent
- Too generic
We addressed this with:
- Prompt engineering
- Structured output formats
High-quality CV Generation
Avoiding:
- Generic CVs
- Irrelevant content
We focused on:
- Context-aware generation
- Job-specific tailoring
Data Integration
Combining:
- GitHub
- LinkedIn
- CV
Into a unified pipeline was non-trivial and required careful system design.
Accomplishments that we're proud of
- Built a full end-to-end AI system, not just a chatbot
- Successfully implemented personalized interview generation
- Designed a multi-dimensional evaluation system
- Created a job-specific CV generator
- Integrated multiple data sources into a unified pipeline
What we learned
- How to design and implement RAG-based AI systems
- The importance of prompt engineering for structured outputs
- Techniques to make AI outputs more consistent and reliable
Real-world system design challenges:
- Scalability
- Data flow
- Scalability
The trade-off between: [ Flexibility \leftrightarrow Control ]
What's next
- Voice-based interviews for realism
- Real-time coding interviews
- Fine-tuned models for better evaluation
- Company-specific interview datasets
- Advanced CV analysis with deeper project insights
Built With
- amazon-web-services
- cache:
- cloud:
- db:
- languages:-python
- qdrant
- redis
- sbert
- typescript-frontend:-next.js-backend:-fastapi-ai/ml:-llm-(gpt)
- vector
- weaviate


Log in or sign up for Devpost to join the conversation.