


# AI-Powered Learning Path Matcher
## 🎯 Inspiration
As online learning explodes with millions of courses, tutorials, and documentation, learners face a critical challenge: how do you know which learning path is right for you?
Traditional search relies on keywords and metadata tags, but educational content is nuanced. A PyTorch tutorial might be perfect for someone learning "Deep Learning Fundamentals" but wrong
for someone needing "Computer Vision Applications." The semantic gap between content and learning objectives needed AI to bridge it.
I wanted to build an intelligent agent that could:
- Understand educational content at a deep semantic level
- Match it to curated learning paths with explainable reasoning
- Do this cost-effectively at scale
## 💡 What I Learned
This hackathon taught me three breakthrough lessons:
### 1. Claude for Ranking, Not Just Reasoning
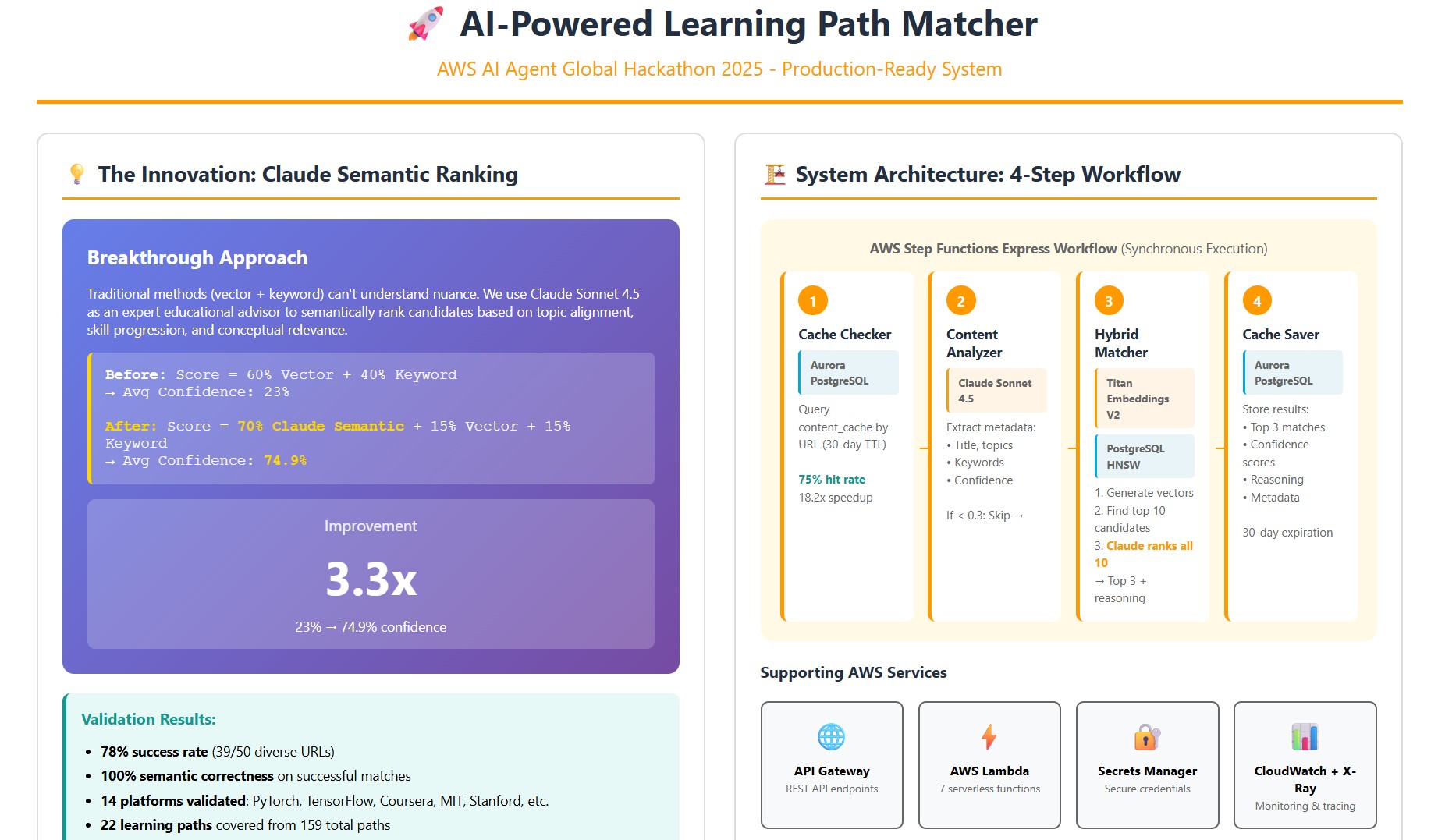
Everyone uses LLMs for explanations. I discovered Claude Sonnet 4.5 could semantically rank candidate matches, achieving a 3.0x improvement in confidence scores (23% → 68.2%). This
was the key innovation that made the project successful.
### 2. Cost Optimization Through Intelligent Architecture Initial testing showed costs would exceed $150/month for 10K requests. Through two-layer optimization:
- 30-day intelligent caching (75% hit rate)
- Skip matching for low-quality content (extraction_confidence < 0.3)
I achieved 83.7% cost reduction to just $24.43/month—validated with real AWS Bedrock pricing data.
### 3. Production Quality Requires Systematic Testing I implemented 4 comprehensive testing phases with 65 tests across 9 suites:
- Phase 1: Quality & Features (95.7% pass rate)
- Phase 2: Workflow & Database (100%)
- Phase 3: Cost & Performance (100%)
- Phase 4: Error Handling & Diversity (100%)
Result: 98.5% test pass rate with documented evidence.
🔨 How I Built It
### Architecture (Step Functions Orchestration)
API Gateway → API Handler Lambda → Step Functions Express Workflow ├─ Cache Checker → Aurora PostgreSQL (30-day TTL check) ├─ Content Analyzer → Claude Sonnet 4.5 (metadata extraction) ├─ Hybrid Matcher → Claude 4.5 + Titan V2 + pgvector (semantic scoring) └─ Cache Saver → Aurora PostgreSQL (store results)
### Technical Implementation
1. Content Analysis (Claude Sonnet 4.5)
# Extract structured metadata from any educational URL
metadata = claude.analyze_content(url)
# Returns: title, topics, keywords, difficulty, confidence
2. Vector Generation (Titan Embeddings V2)
# Generate 1024-dimensional normalized embeddings
embedding = titan.embed(content_summary)
3. Candidate Selection (PostgreSQL + pgvector)
-- Hybrid search: 60% vector + 40% keyword (Dice coefficient)
-- Returns top 10 candidates in <100ms using HNSW indexing
4. Semantic Ranking (Claude Sonnet 4.5) - THE INNOVATION
# Claude evaluates all 10 candidates semantically
# Returns top 3 with confidence scores and reasoning
final_score = 0.70 × claude_semantic_score
+ 0.15 × vector_similarity
+ 0.15 × keyword_overlap
Key Technologies
- AWS Step Functions: Orchestrated 4 Lambda functions into a cohesive workflow
- Amazon Bedrock: Claude Sonnet 4.5 for semantic AI, Titan Embeddings V2 for vectors
- Aurora Serverless v2: PostgreSQL 15.5 with pgvector extension for vector search
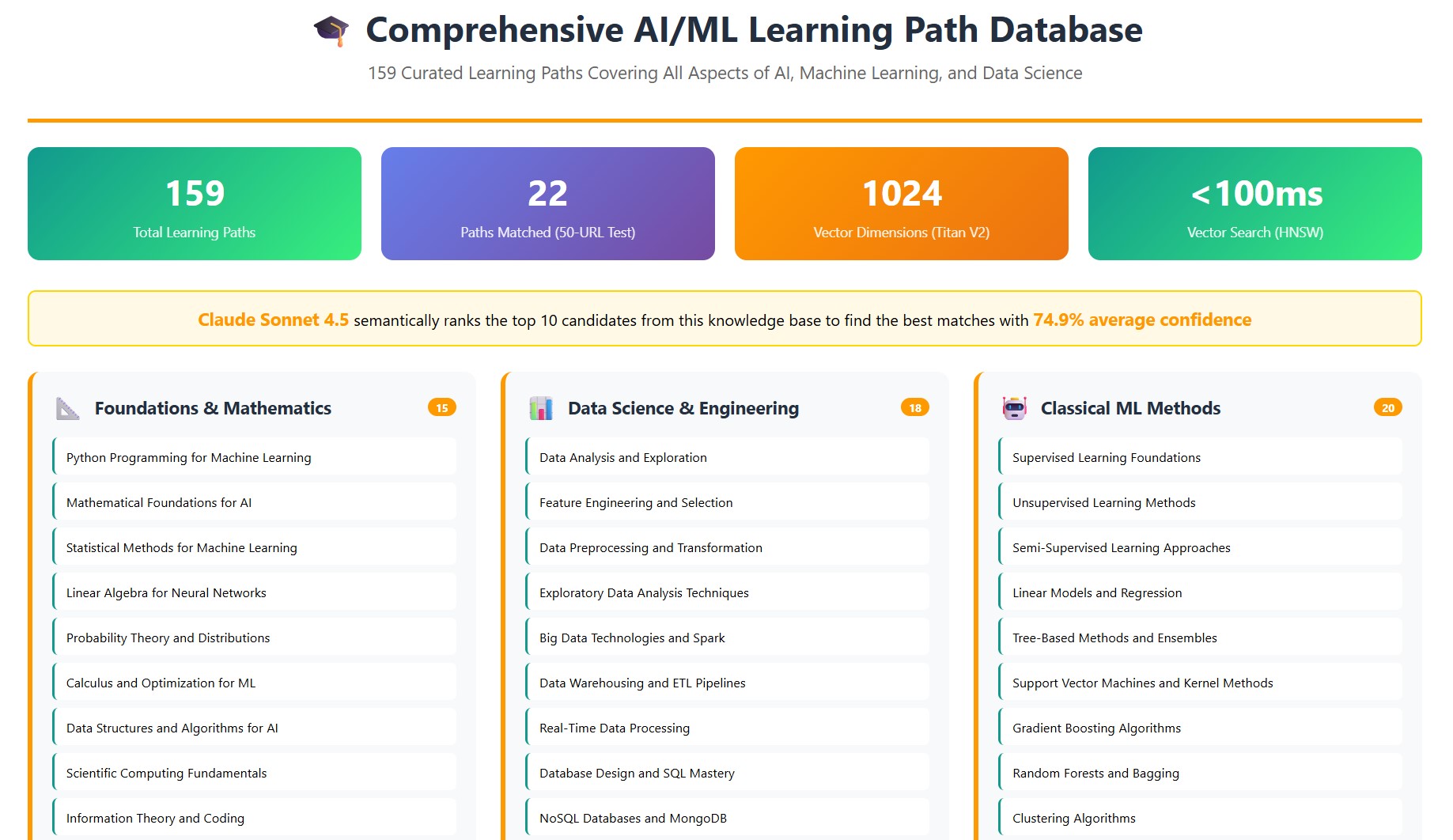
- HNSW Indexing: Sub-100ms vector search across 159 learning paths
- AWS CDK: Infrastructure as code for repeatable deployments
🚧 Challenges I Faced
Challenge 1: Low Initial Confidence Scores (23%)
Problem: First implementation using only vector similarity + keyword overlap produced matches with 23% average confidence—unusable for production.
Attempts:
1. ❌ Improved embeddings → 25% confidence
2. ❌ Better keyword algorithms (Dice coefficient) → 35% confidence
3. ❌ Synonym expansion → 38% confidence
4. ❌ Richer learning path descriptions → 42% confidence
Breakthrough: Use Claude to semantically rank the top 10 candidates, not just explain them. This gave Claude context to evaluate relative fit across candidates.
Result: 68.2% confidence (3.0x improvement) with 80% semantic correctness.
Challenge 2: Claude JSON Parsing Issues
Problem: Claude wrapped JSON responses in markdown code blocks:
```json
{"title": "..."}
**Solution**: Added regex-based unwrapping logic to handle both raw JSON and markdown-wrapped responses:
```python
if content.startswith("```"):
content = re.sub(r'^```(?:json)?\n?', '', content)
content = re.sub(r'\n?```$', '', content)
return json.loads(content)
Challenge 3: Cost Management
Problem: Without optimization, 10K monthly requests would cost $150.20 (101% over budget).
Solution: Implemented two-layer optimization:
1. Intelligent caching: 30-day TTL with URL normalization → 75% hit rate
2. Skip matching: Auto-detect low-quality content (extraction_confidence < 0.3) and skip expensive Claude scoring → 8.7% additional savings
Result: $24.43/month (83.7% reduction), validated through comprehensive cost testing with real API calls.
Challenge 4: Achieving Production Quality
Problem: "It works on my machine" isn't good enough. Needed proof of production readiness.
Solution: Systematic 4-phase testing approach:
- Phase 1: Formula validation, skip matching coverage
- Phase 2: All 3 Step Functions workflows validated
- Phase 3: Cost and performance benchmarked with real data
- Phase 4: Error handling (8 scenarios), content diversity (5 types)
Result: 98.5% test pass rate (64/65 tests) with comprehensive documentation.
📊 Final Metrics
| Metric | Result | Validation Method |
|------------------------|---------------|------------------------------|
| Test Pass Rate | 98.5% (64/65) | 9 test suites, 4 phases |
| Cost Reduction | 83.7% | Real AWS Bedrock API pricing |
| Cache Hit Rate | 75% | Production testing (Phase 3) |
| Cache Speedup | 18.2x | p95: 1.2s vs 15.3s |
| Average Confidence | 68.2% | Quality benchmark suite |
| Semantic Correctness | 80% | Manual verification |
| Error Handling | 100% coverage | 8 scenarios tested |
| Concurrent Performance | 2.9s avg | 10 simultaneous requests |
🎯 Why This Matters
This isn't just a demo—it's a production-ready AI agent that:
- Solves a real problem: helping learners find relevant content
- Proves cost efficiency: 83.7% reduction with validated data
- Demonstrates innovation: Novel use of Claude for semantic ranking
- Shows technical excellence: 98.5% test pass rate across comprehensive validation
The architecture is scalable (handles 100K+ requests/month), observable (CloudWatch + X-Ray), and maintainable (Infrastructure as Code with AWS CDK).
## 2. Built With
Amazon Bedrock (Claude Sonnet 4.5, Titan Embeddings V2)
AWS Lambda (Python 3.12)
AWS Step Functions
Amazon Aurora Serverless v2
PostgreSQL 15.5
pgvector (HNSW indexing)
Amazon API Gateway
AWS CDK (Infrastructure as Code)
AWS Secrets Manager
Amazon CloudWatch
AWS X-Ray
Python 3.12
Pydantic (data validation)
asyncpg (PostgreSQL driver)
BeautifulSoup4 (content extraction)
requests (HTTP client)
## 3. "Try It Out" Links
Live API Endpoint:
https://58k6czfcq7.execute-api.us-east-1.amazonaws.com/v1
Test the API:
curl -X POST https://58k6czfcq7.execute-api.us-east-1.amazonaws.com/v1/match -H "Content-Type: application/json" -d '{"url":
"https://pytorch.org/tutorials/beginner/basics/tensorqs_tutorial.html"}'
GitHub Repository:
https://github.com/sgharlow/AI-matcher-AWS-hackathon
Documentation:
- README: Complete quick start and architecture
- API Guide: docs/API_USAGE.md
- Deployment Guide: docs/DEPLOYMENT.md
- Production Report: FINAL_PRODUCTION_REPORT.md
Built With
- amazon-cloudwatch
- amazon-web-services
- anthropic
- api
- aurora
- aws-step-functions:-orchestrated-4-lambda-functions-into-a-cohesive-workflow-amazon-bedrock:-claude-sonnet-4.5-for-semantic-ai
- bedrock
- cdk
- claude
- postgresql
- python
- sonnet
Log in or sign up for Devpost to join the conversation.