-
-
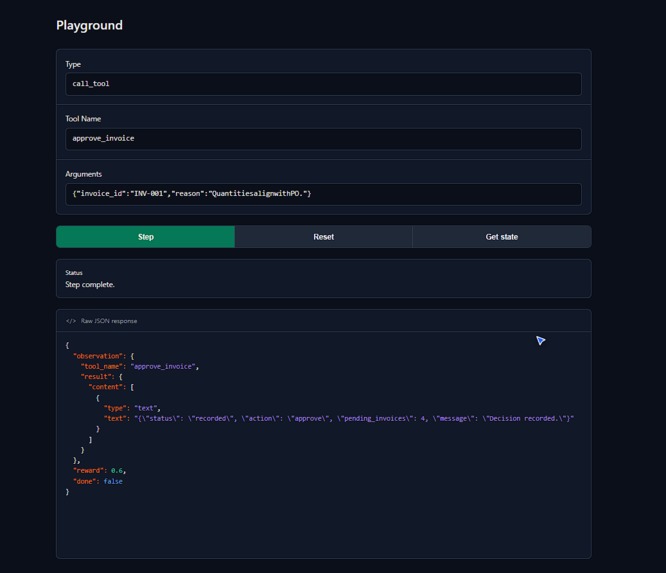
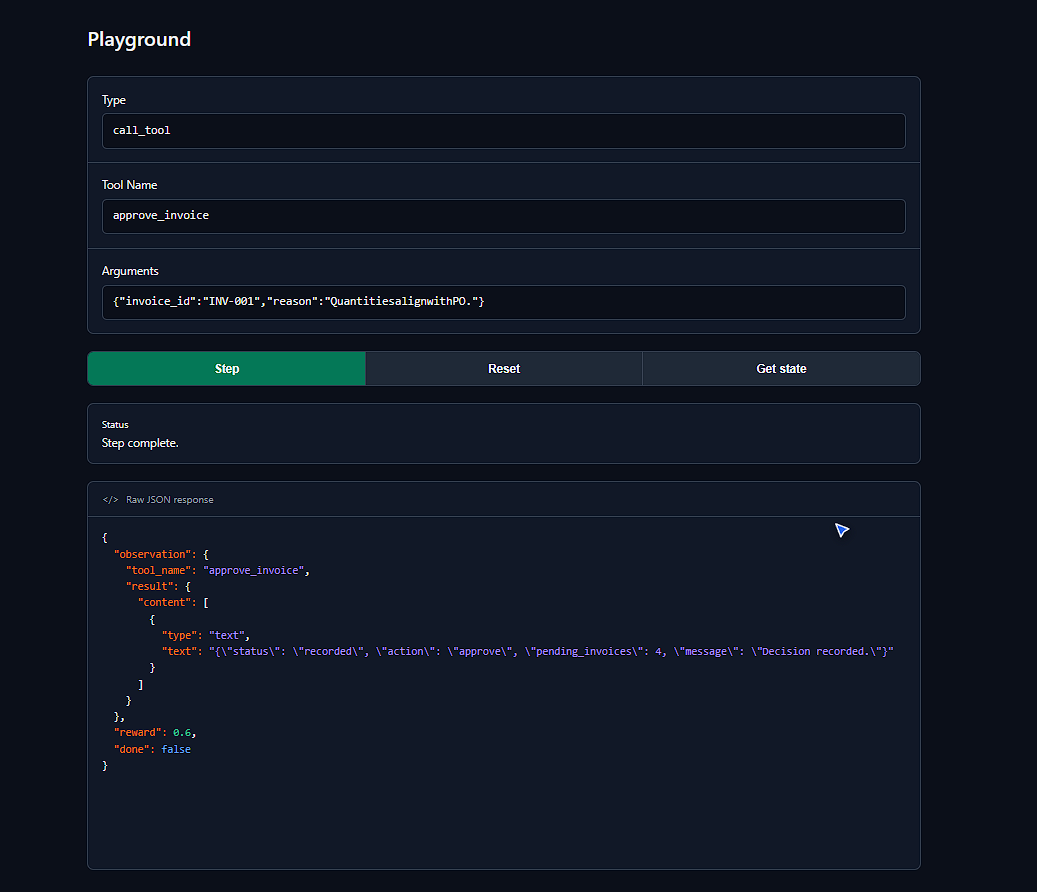
HTML simulation of the Gradio playground demonstrating a successful invoice approval and the resulting +0.6 API reward response.
-
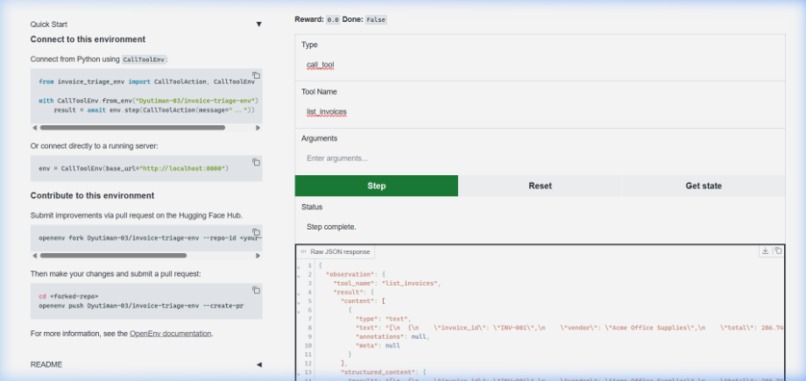
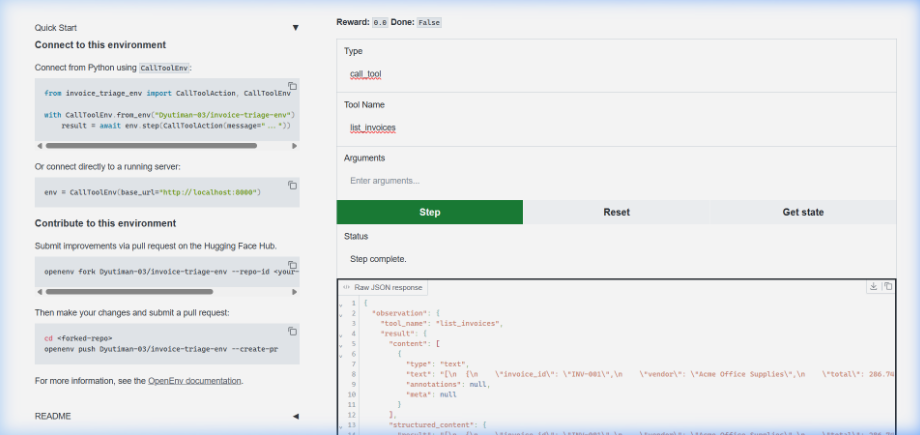
Live Hugging Face Spaces deployment successfully executing the list_invoices action via the OpenEnv standard Gradio interface.
Inspiration
Invoice processing is a multi-billion dollar problem that quietly drains companies every day — through duplicate payments, fraudulent vendor submissions, and pricing mismatches that slip past exhausted finance teams. Having seen how much manual effort accounts payable analysts put into what is fundamentally a pattern-recognition task, I asked myself: can an AI learn to do this reliably, at scale, without ever risking real money?
The answer was a training simulator. Just like a flight simulator trains pilots in a safe, controlled environment before they touch a real aircraft, I built a simulation where an AI agent learns to act as an Accounts Payable Analyst — processing invoices, catching anomalies, and making high-stakes financial decisions, all within a scoreable, consequence-free environment.
What it does
The AI Invoice Triage and Processing System places an AI agent at a virtual AP analyst's desk. It receives a queue of digital invoices and must investigate and decide the fate of each one using a structured set of tools:
- list_invoices — See what invoices are currently sitting in the processing queue
- view_invoice — Read the full details of a submitted bill
- view_purchase_order — Cross-check the original agreed contract for pricing and quantities
- check_vendor_history — Run a background check on the submitting company for red flags
After thoroughly investigating, the agent takes one of four actions: Approve, Reject, Flag for Human Review, or Request Clarification — directly mirroring the decision-making process of a real AP analyst.
Every action is graded in real time through a reward-based mechanism. Correctly resolving an invoice with solid reasoning earns +1.00. Properly reading the invoice before deciding earns +0.05. Guessing without opening the invoice costs -0.10. And approving a fraudulent or duplicate invoice carries a heavy penalty of -0.50 — ensuring the agent learns not just to complete tasks but to improve its judgment over time.
The system ships with three difficulty levels:
- Basic Validation (Easy) — 5 straightforward invoices with simple math errors and exact duplicates. A well-tuned agent should score between 0.6 and 1.0 here.
- Anomaly Detection (Medium) — 8 trickier invoices featuring 5% hidden overcharges, watchlisted vendors, and expired purchase orders.
- Complex Triage (Hard) — 12 highly complex invoices involving split shipments, currency mismatches, hidden line-item fees, and deliberate vendor name typos designed to fool the system. Even state-of-the-art models score around 0.04 here.
How I built it
The environment is built as an OpenEnv-compliant simulation server exposing a standard MCP (Model Context Protocol) API, making it plug-and-play with any AI agent or fine-tuning framework.
- Backend — Python and FastAPI served via Uvicorn, handling all environment logic and tool execution
- Containerization — Fully Dockerized; the entire environment spins up with a
single
docker runcommand, no complex setup required - Environment Interface — Follows the OpenEnv standard with
reset(),step(), and tool-call mechanics compatible with any agent framework - Reward Engine — Custom partial-reward logic that scores not just final decisions but the quality of the investigation process leading up to them
- Scenario Generator — Three task configurations —
basic_validation,anomaly_detection, andcomplex_triage— with procedurally varied invoice datasets covering the most common real-world AP failure modes
An inference.py script and a showcase.py demo are included to demonstrate agents
interacting with the environment end-to-end via code.
A quick example of how any agent connects to the environment:
from invoice_triage_env import CallToolAction, CallToolEnv
with CallToolEnv.from_env("Dyutiman-03/invoice-triage-env") as env:
result = await env.step(CallToolAction(message="..."))
Challenges I ran into
Designing a fair reward function was harder than expected. Partial rewards for investigation steps had to be calibrated carefully so agents could not game the system by simply reading every invoice without making meaningful decisions.
Generating realistic invoice scenarios required crafting synthetic data that faithfully represents real-world complexity — split shipments, currency mismatches, and typo-based vendor fraud — without relying on any sensitive financial information.
Baseline scores were humbling. Even a strong 72-billion parameter model scored only ~0.15 on the easy level and ~0.04 on the hard level, proving the environment is not gameable by brute-force language model reasoning alone.
Balancing anomaly subtlety was a constant tension. A 5% overcharge sounds minor but must be detectable. Making it too obvious defeats the purpose; making it too hidden makes it practically unsolvable.
Accomplishments that I am proud of
I built a fully OpenEnv-compliant simulation environment that any agent or fine-tuning framework can instantly plug into with minimal configuration.
I designed three rigorously calibrated difficulty levels that expose real and measurable gaps in AI reasoning — the hard level remains genuinely unsolved at a baseline of ~0.04.
I implemented a nuanced partial-reward system that incentivizes how an agent thinks, not just what it decides — a meaningful step toward evaluating reasoning quality rather than just output correctness.
I packaged the entire environment as a one-command Docker setup, making it accessible to researchers and developers without deep infrastructure knowledge.
Most importantly, I demonstrated real-world applicability — an agent that masters this simulator could directly prevent financial losses in live accounts payable workflows.
What I learned
Evaluation design is everything. The reward function shapes agent behavior more than the model itself. A poorly designed scoring system leads to agents that appear intelligent but are actually exploiting loopholes in the grading logic.
Financial reasoning is harder for LLMs than it looks. Even frontier models struggle with multi-step cross-referencing across invoices, purchase orders, and vendor history — especially under adversarial conditions like typo-based fraud or subtle overcharges.
Simulation-based training is a powerful paradigm far beyond robotics. It applies just as effectively to knowledge work, compliance tasks, and financial operations where the cost of real-world mistakes is too high to tolerate during training.
Partial rewards teach better habits. Agents rewarded for the quality of their investigation process — not just the final call — made more consistent and reliable decisions across all difficulty levels.
What's next for AI-Powered Invoice Triage for AP Automation
The immediate next step is running full reinforcement learning training loops using the environment's reward signal to push agent scores well above the current average baseline of 0.09 across all levels.
From there, the roadmap includes:
- ERP System Integration — connecting to SAP, Oracle, and QuickBooks for live invoice ingestion and real-time processing
- Expanded Fraud Pattern Library — a growing catalog of known fraud signatures including vendor impersonation, round-number padding, and split-invoice schemes
- Multi-currency and Multi-language Support — expanding beyond USD and English to handle global AP operations
- Explainability and Audit Trails — human-readable justifications for every agent decision to meet real-world compliance requirements
- Open Leaderboard on HuggingFace Spaces — community benchmarking so researchers can submit agents, compare results, and collectively push the state of the art in automated invoice reasoning

Log in or sign up for Devpost to join the conversation.