-
-
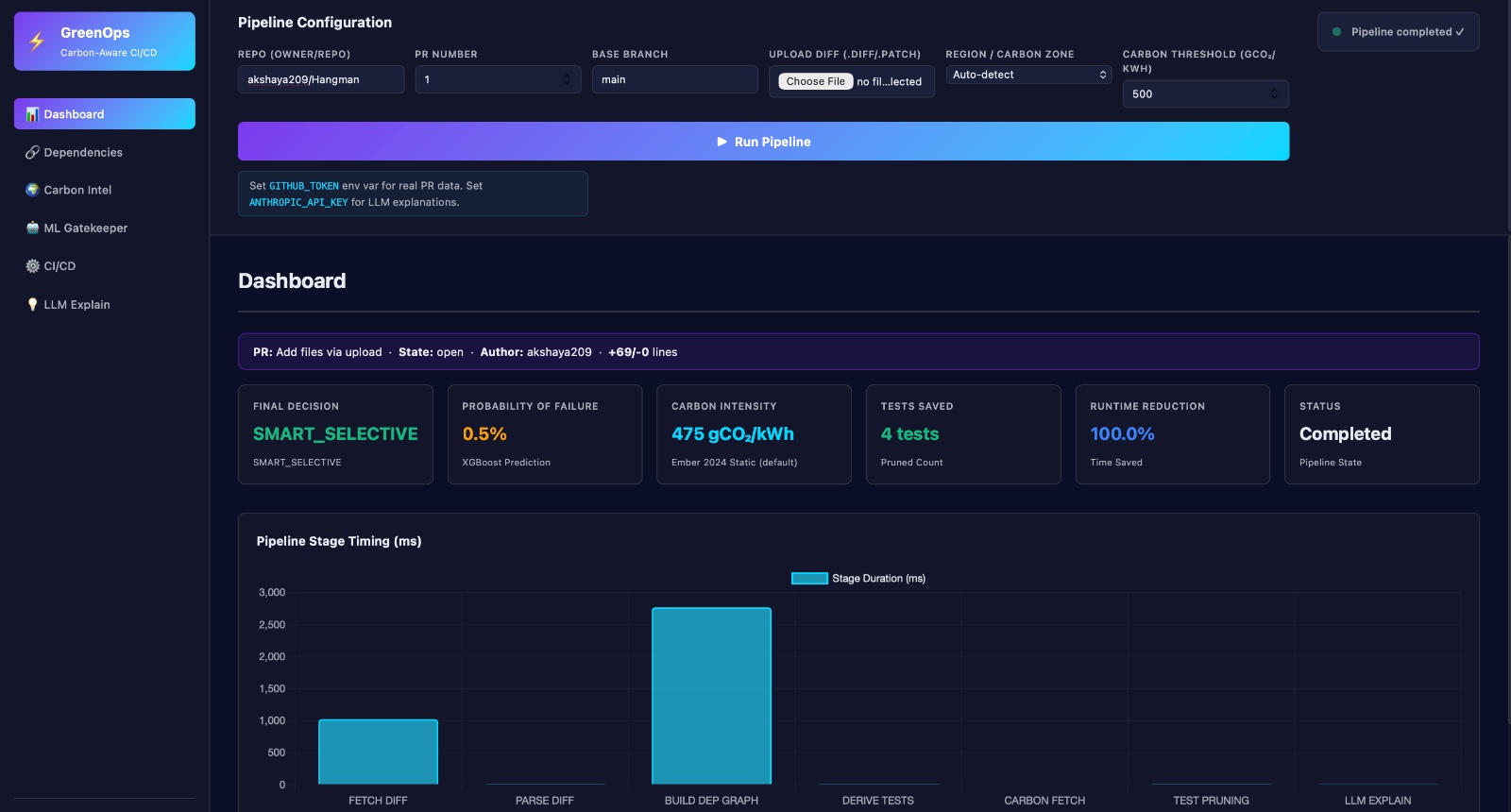
Dashboard
-
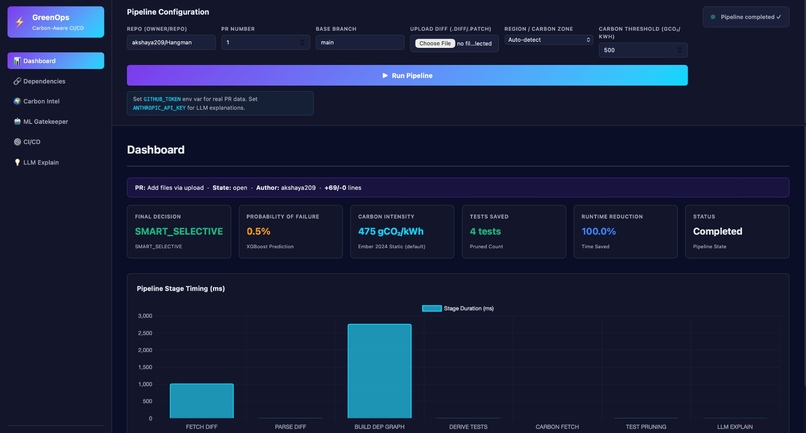
Analytics
-
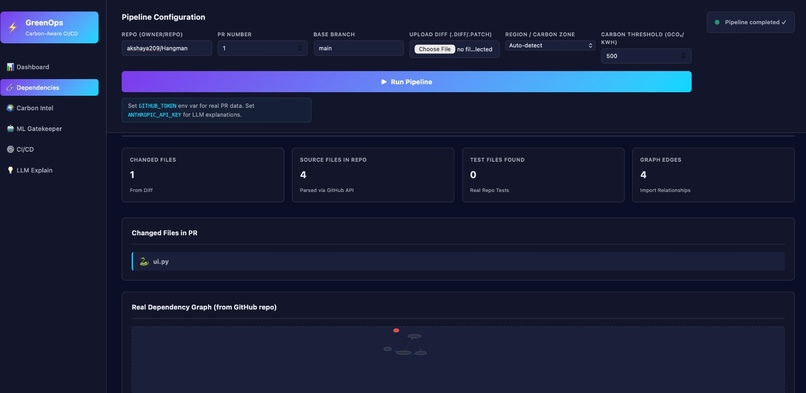
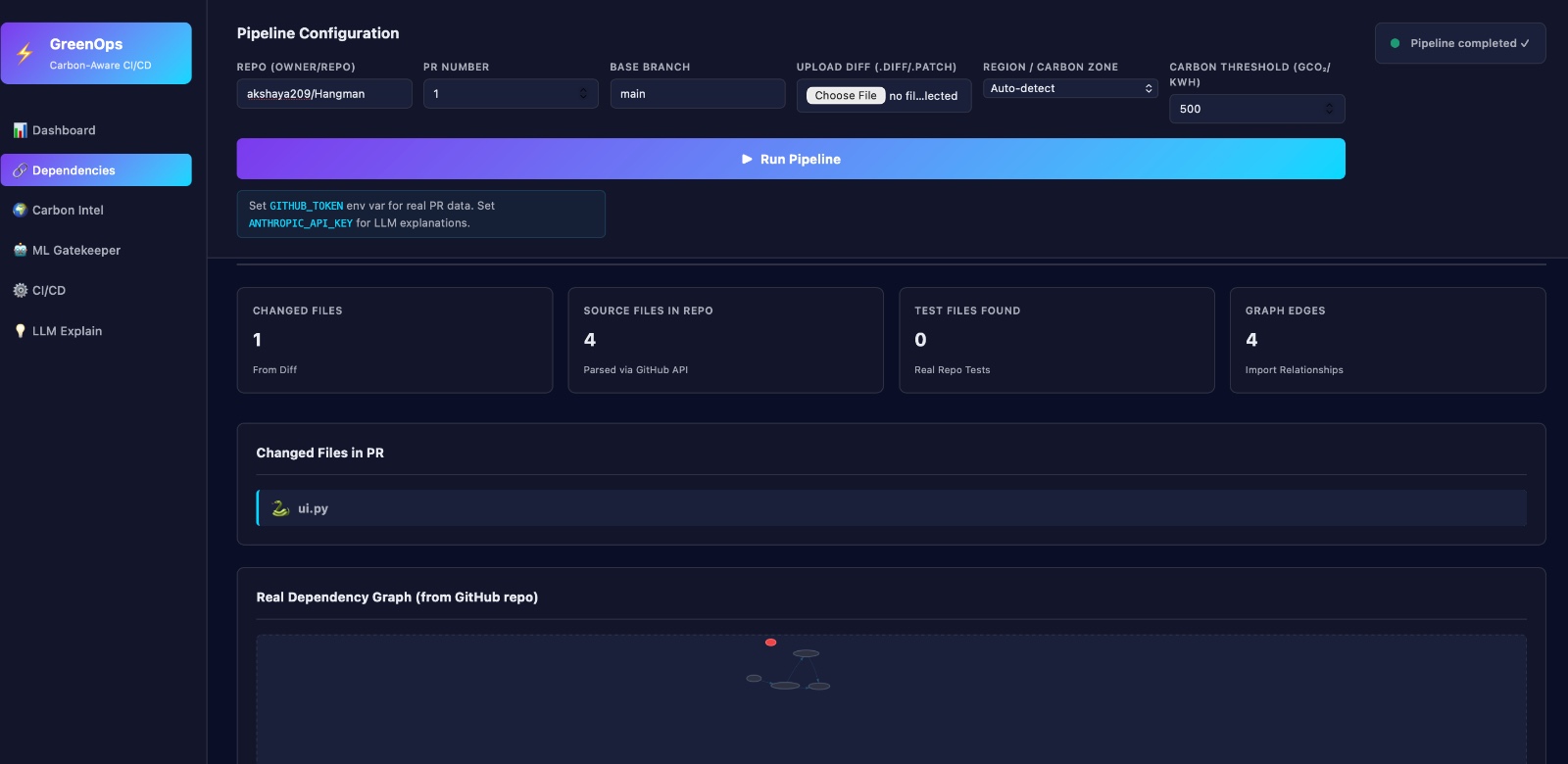
Dependency graph generation
-
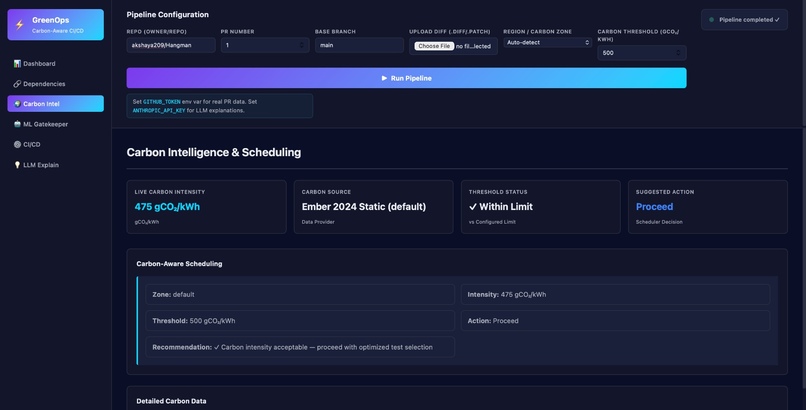
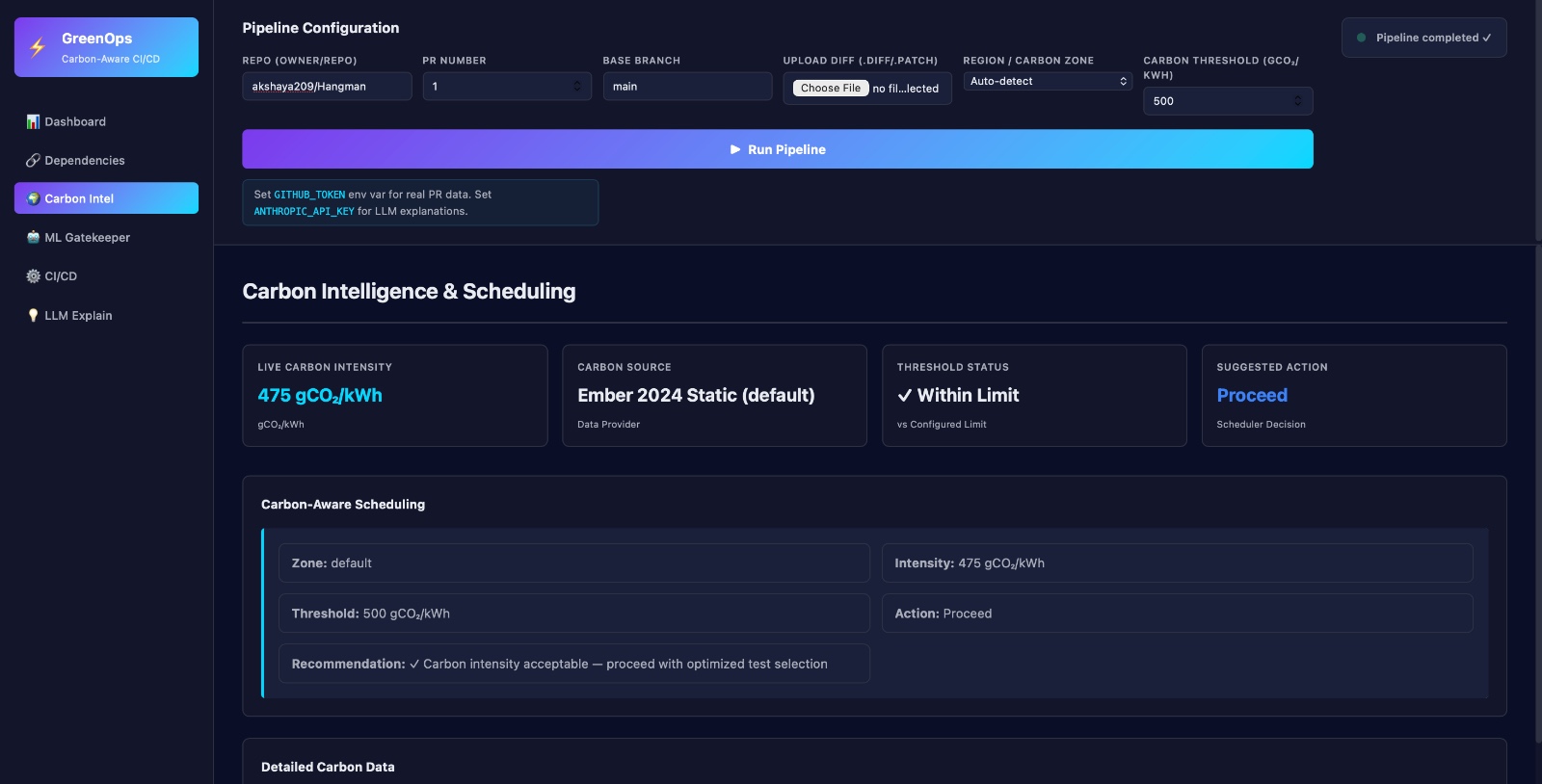
Carbon aware scheduling
-
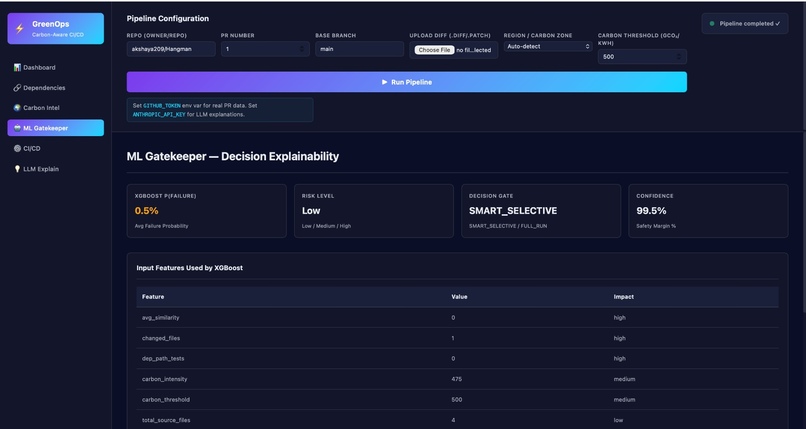
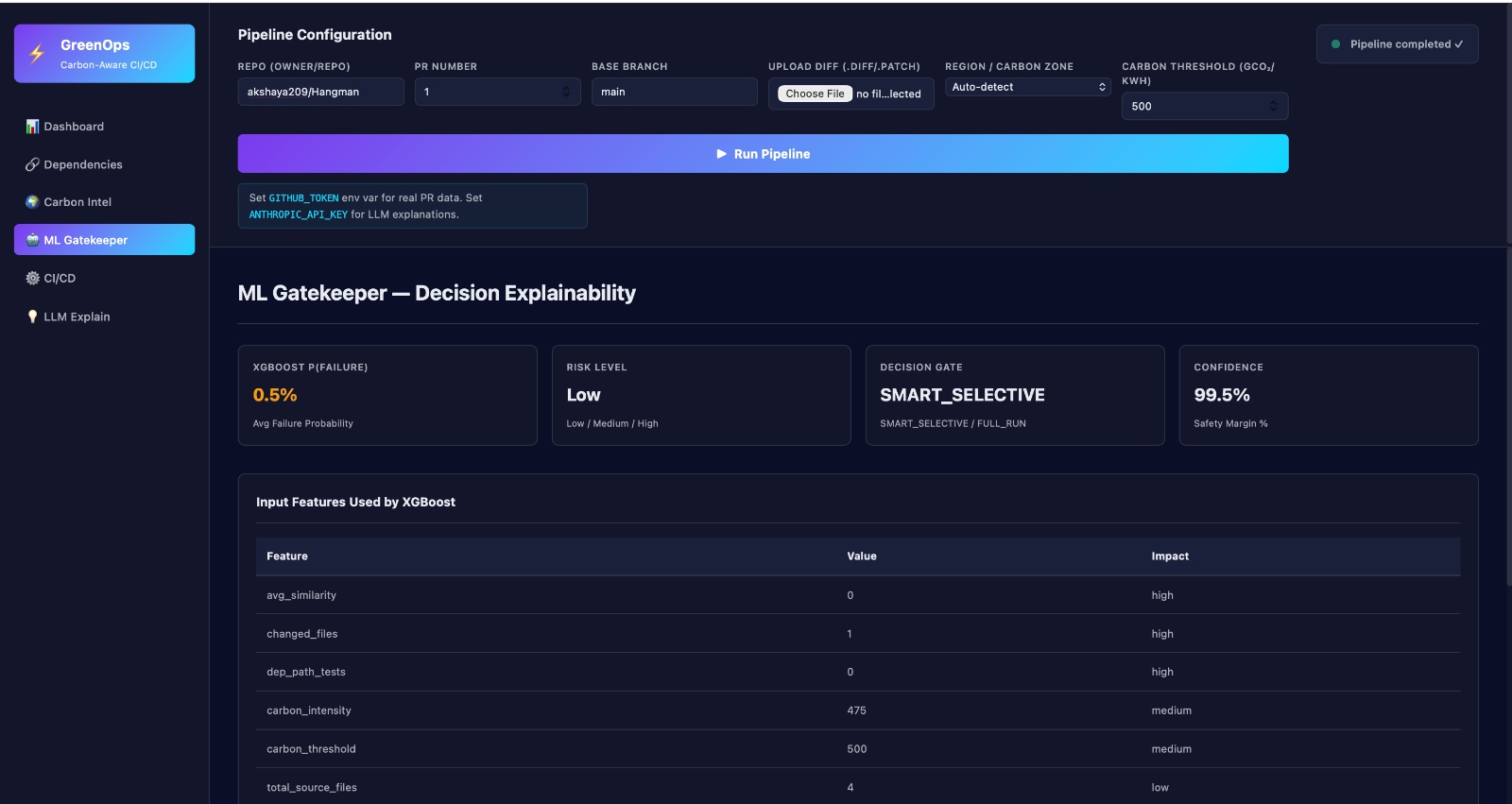
ML gatekeeper
-
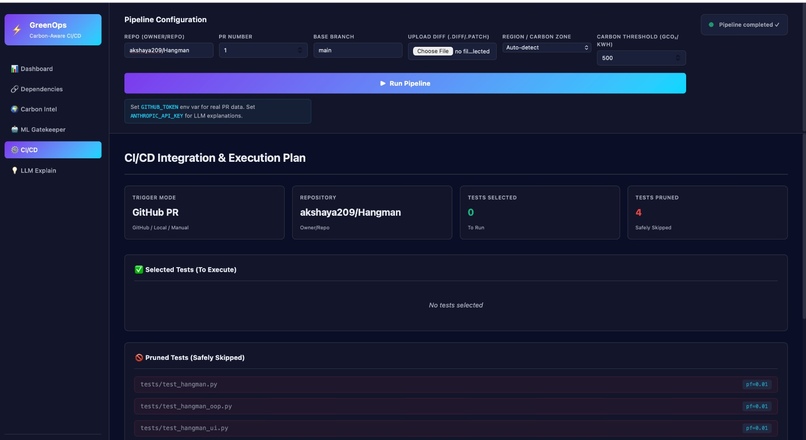
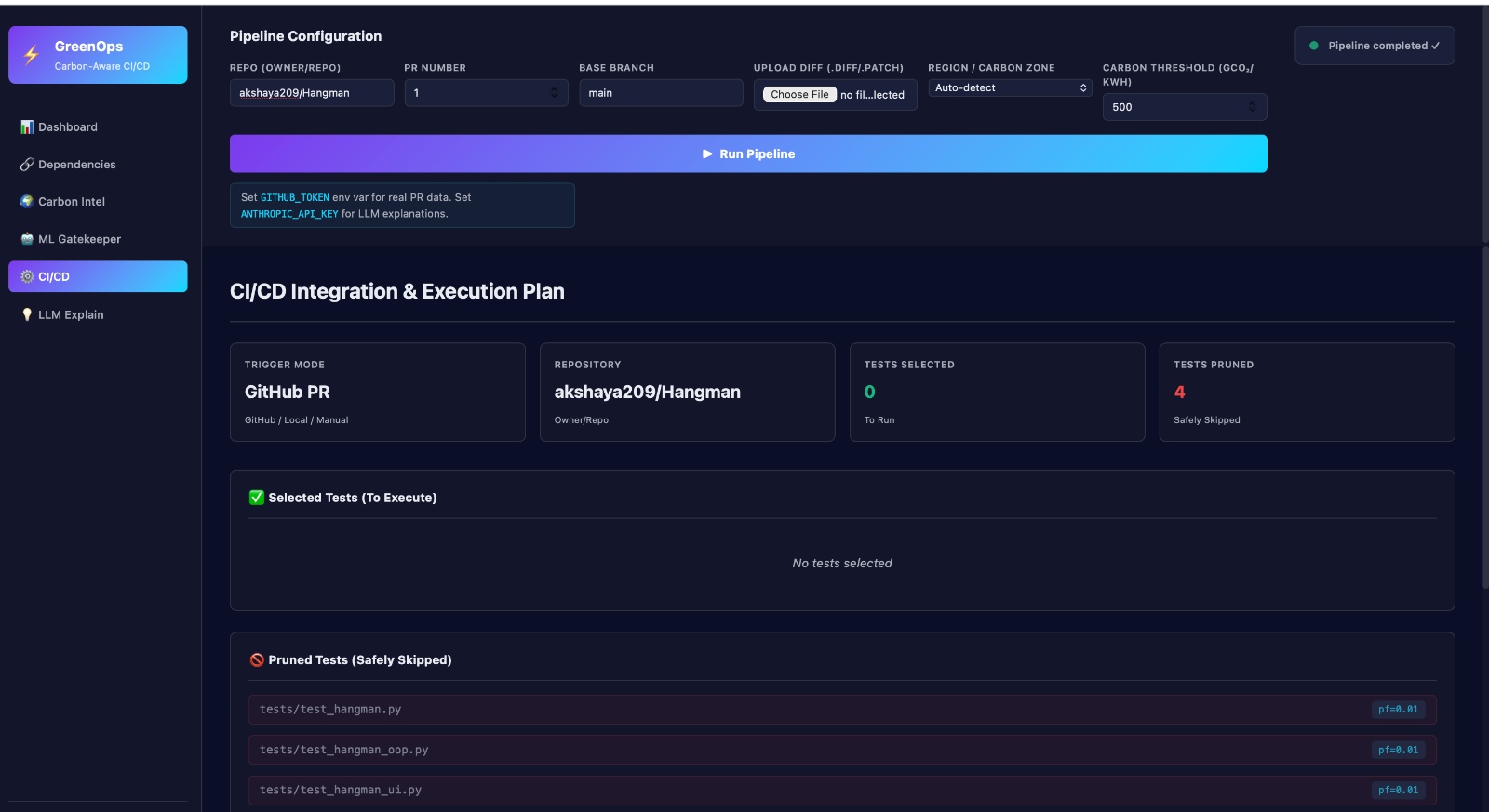
CI/CD integration
-
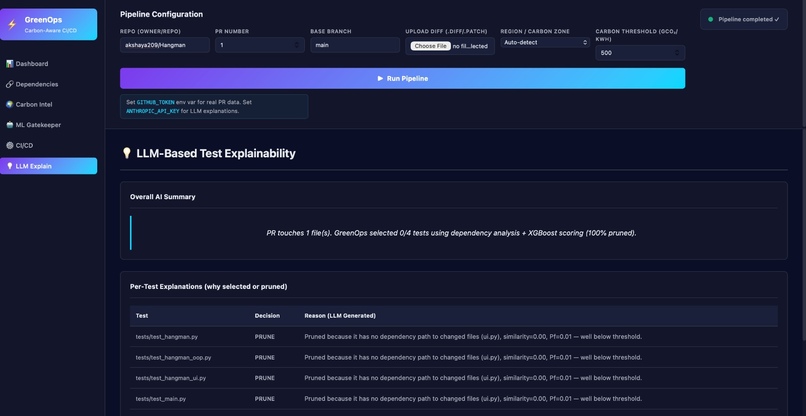
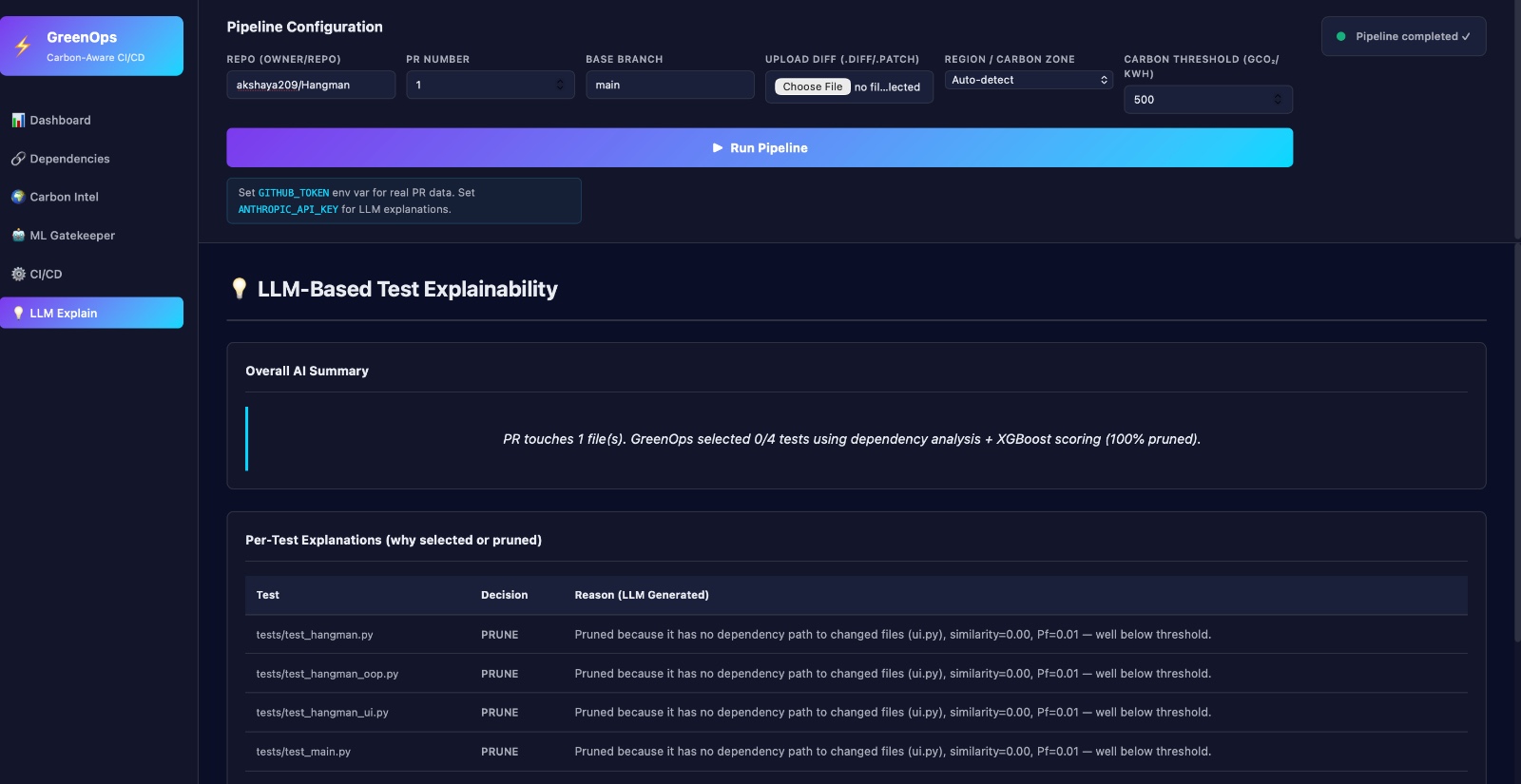
LLM explanations
-
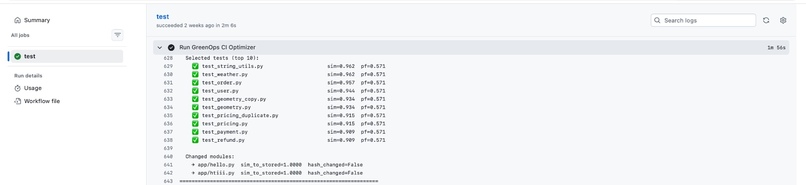
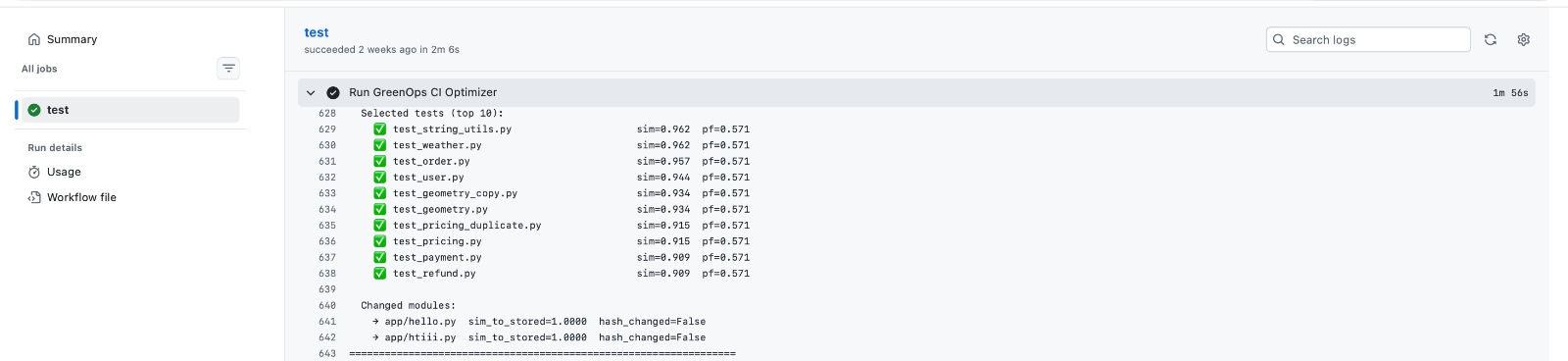
GitHub Actions integration
Inspiration
Modern cloud pipelines look clean—but they aren’t. Every build, test run, and deployment silently consumes energy in distant data centers, contributing to carbon emissions that engineers rarely see or consider. Today’s CI/CD systems optimize for speed and cost—but ignore environmental impact entirely. Ideas: Make things that are hidden clear. Your pipeline might: Show the real-time carbon intensity per job on the surface Show "this deployment puts out X grams of CO₂" Make emissions a top-notch metric, like cost or latency. This changes the way engineers think about decisions completely. Our pipeline : 1.Shows real-time carbon intensity per job 2.Display: “This deployment emits X grams of CO₂” 3.Treat emissions as a first-class metric, just like cost or latency
What it does
This project is an intelligent, carbon-aware CI/CD optimization engine that reduces unnecessary computation while minimizing environmental impact. Instead of running all tests for every pull request, it: Understands code changes using AST (structure) and embeddings (semantics) Identifies exactly which modules are affected Predicts which tests are most likely to fail Executes only the highest-value tests Schedules workloads in low-carbon data centers End Result: Lower compute costs Smaller carbon footprint Faster feedback cycles without compromising reliability
How we built it
How we built it We designed a modular system where each component addresses a key inefficiency in traditional CI/CD pipelines.
- Analyzing and Fingerprinting PRs Generate a unique hash for each PR Build an AST (Abstract Syntax Tree) to understand structure Compare with historical PRs to reuse insights
- Finding Similarities Detect previously seen AST patterns Reuse dependency analysis if available Avoid redundant computation by skipping full re-analysis
- Semantic Understanding with GraphCodeBERT Capture code meaning, not just syntax Identify: Hidden dependencies Cross-module impact Non-obvious relationships
- Building a Dependency Graph Combine: AST structure Import relationships Shared services (DBs, Kafka, etc.) Produce a complete dependency graph of the PR
- LLM Reasoning Layer Takes embeddings + dependency graph Performs contextual reasoning to: Identify affected modules Generate dependency flow Provide explanations for decisions
- Failure Prediction with XGBoost Input: Dependency data Historical test failure telemetry Output: Probability of test failures Prioritized test suite 👉 Result: Smaller, high-impact test execution
- Scheduling with Carbon Awareness 🌱 This is the core differentiator. Energy Estimation: Based on: CPU cycles Operation counts Carbon Modeling: Uses: Regional energy mix (hydro, nuclear, thermal) Carbon intensity datasets (e.g., Ember) External carbon APIs Smart Execution: Dynamically selects the lowest-emission data center 💡 Example: Run workloads in Mumbai or Delhi based on real-time carbon intensity—not just latency.
Challenges we ran into
1.GraphCodeBERT setup latency slowed GitHub Actions pipelines 2.Trade-off between accuracy and execution speed 3.Integrating real-time carbon data reliably
Accomplishments that we're proud of
1.Significant test case pruning without loss of reliability 2.Generated dependency flow graphs for transparency 3.Provided LLM-based explanations for every skipped test
What we learned
Combining ML models + LLM reasoning creates powerful real-world systems Optimization isn’t just technical—it’s contextual and environmental Visibility drives better engineering behavior
What's next for Ai powered Carbon aware CI/CD pipeline optimiser
Scale to real-time, enterprise-grade codebases Reduce GraphCodeBERT embedding latency Optimize LLM reasoning for faster dependency analysis Integrate directly into developer workflows (GitHub, GitLab) Expand carbon-aware scheduling across global regions
Built With
- anthropic-api
- electricity-api
- fastapi
- github-actions
- graphcodebert
- javascript
- python
- sql
- xgboost


Log in or sign up for Devpost to join the conversation.