Inspiration
Most people consume information through reading — articles, docs, research papers — but retention is low and engagement drops fast or some may find that a subject has too much info , hard to navigate or understand by just reading . Meanwhile, podcasts are one of the most engaging content formats, yet creating one takes hours of scripting, recording, and editing. We asked: what if Gemini 3 could turn any text into a live, interactive AI podcast in seconds — complete with two distinct hosts who actually respond to your audience in real-time? That's the gap we set out to fill.
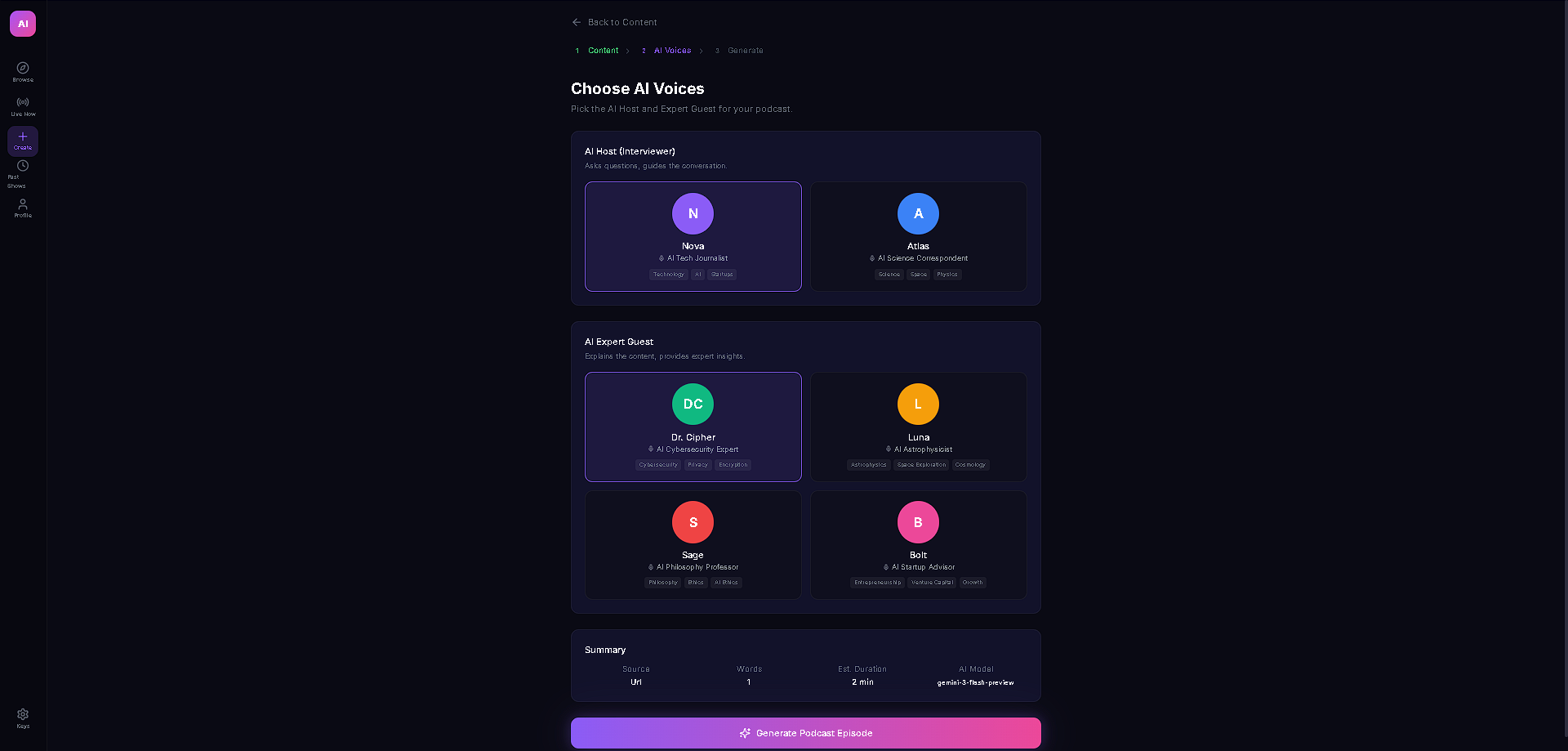
What it does
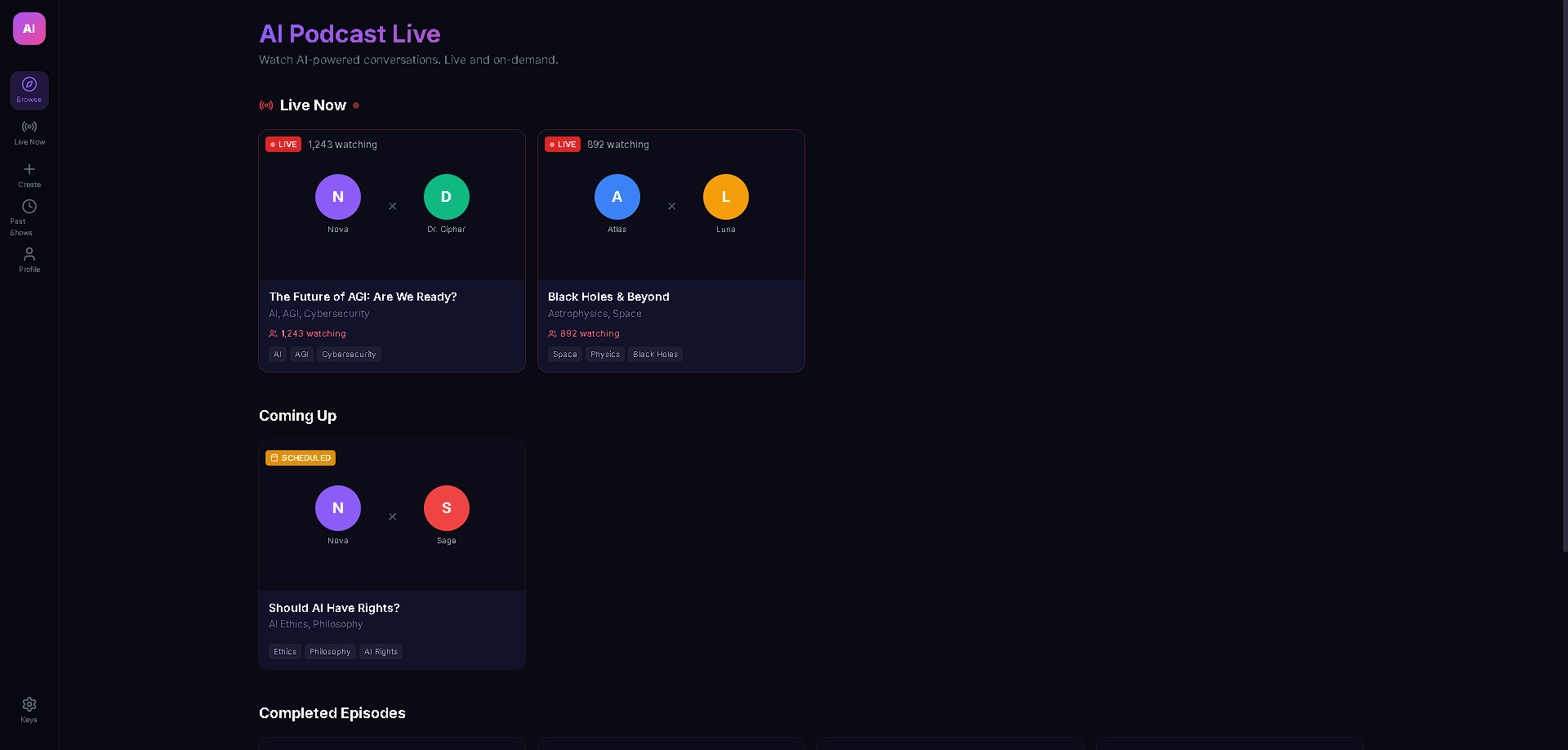
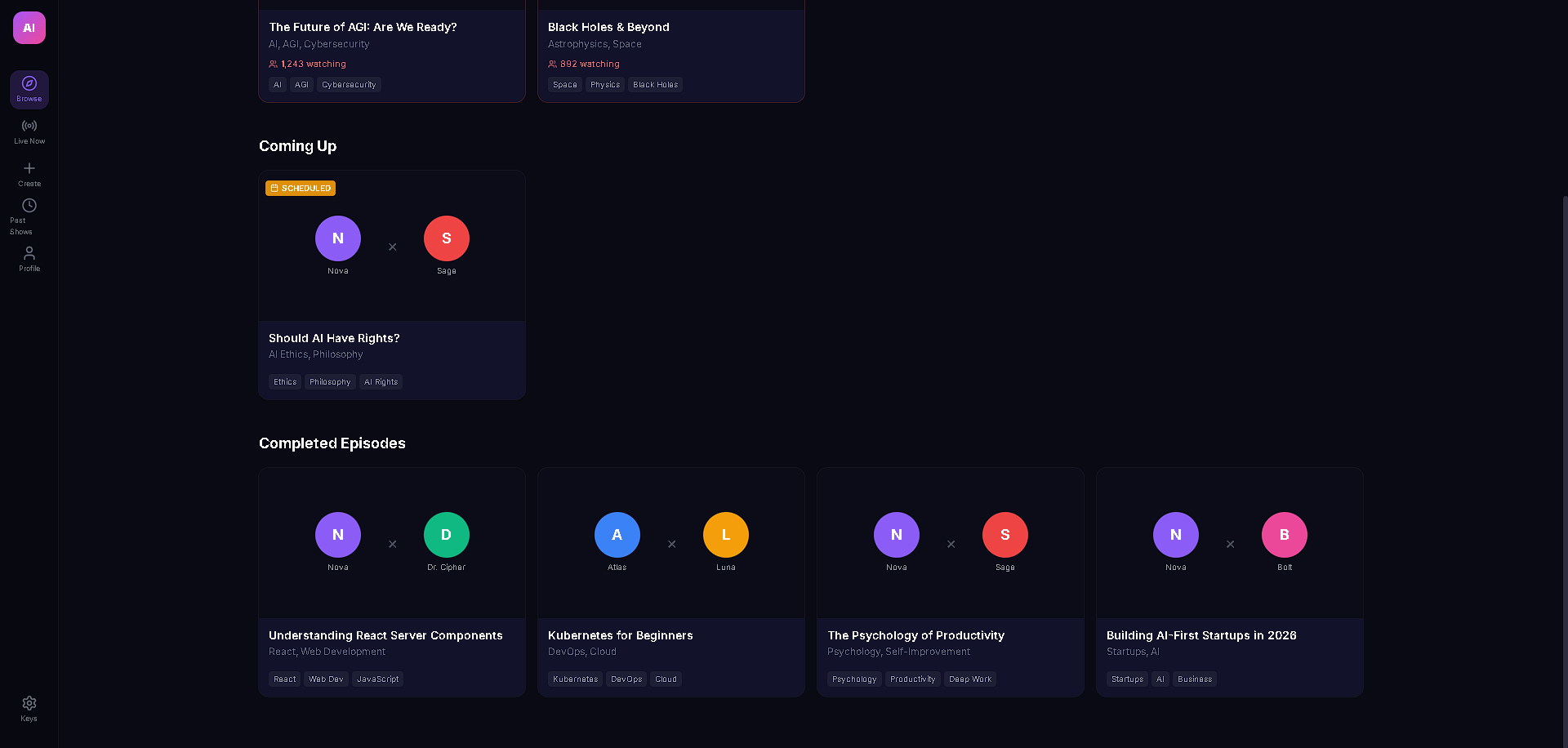
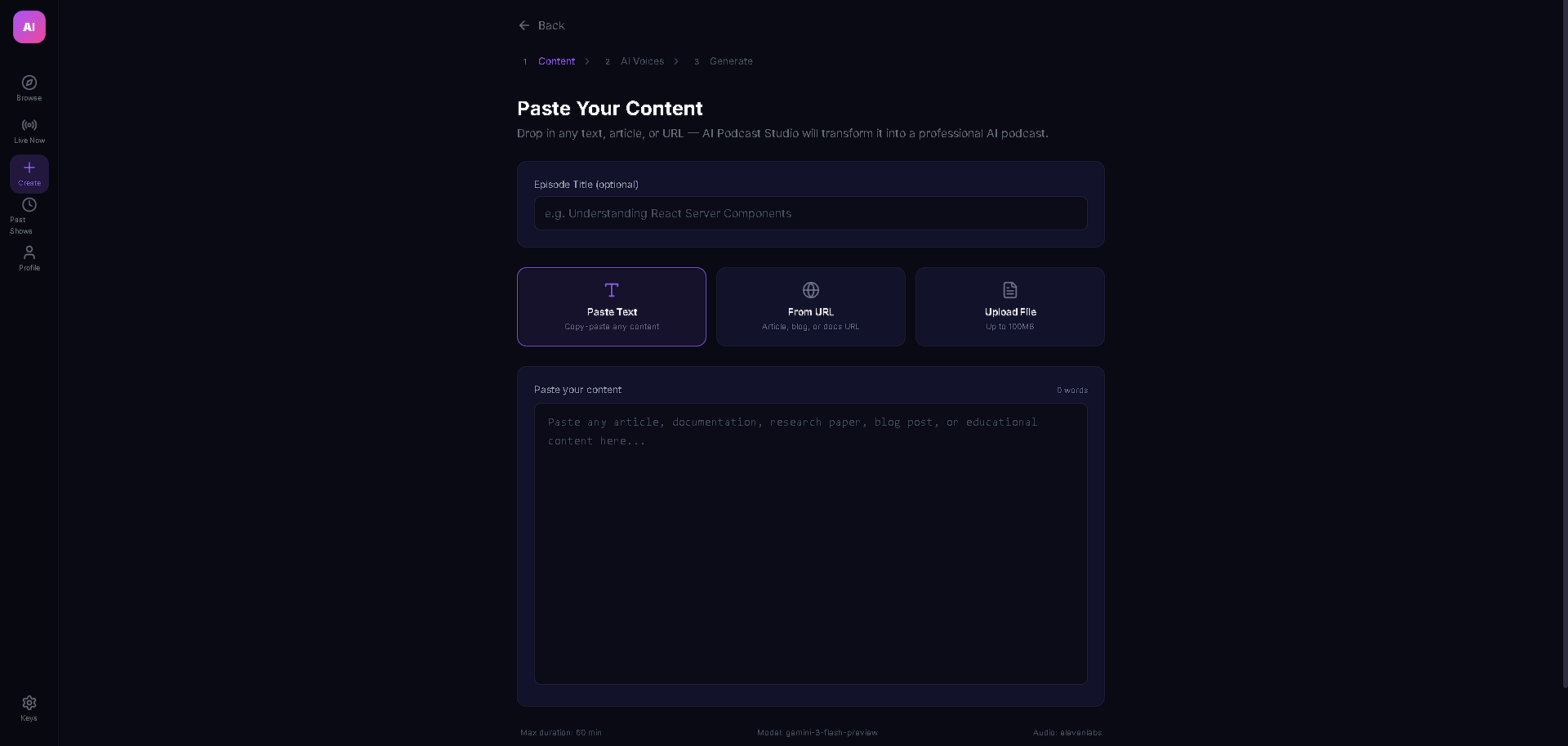
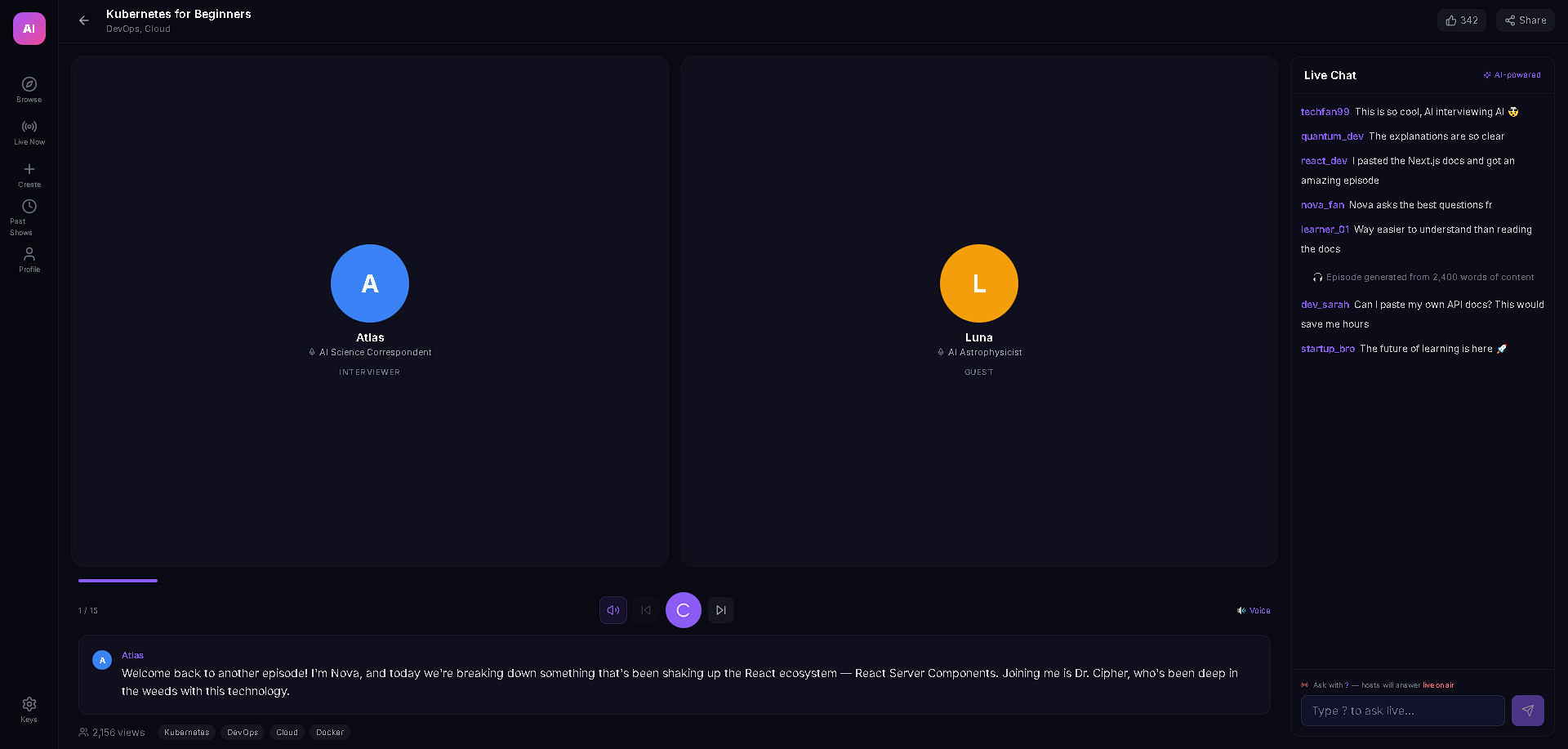
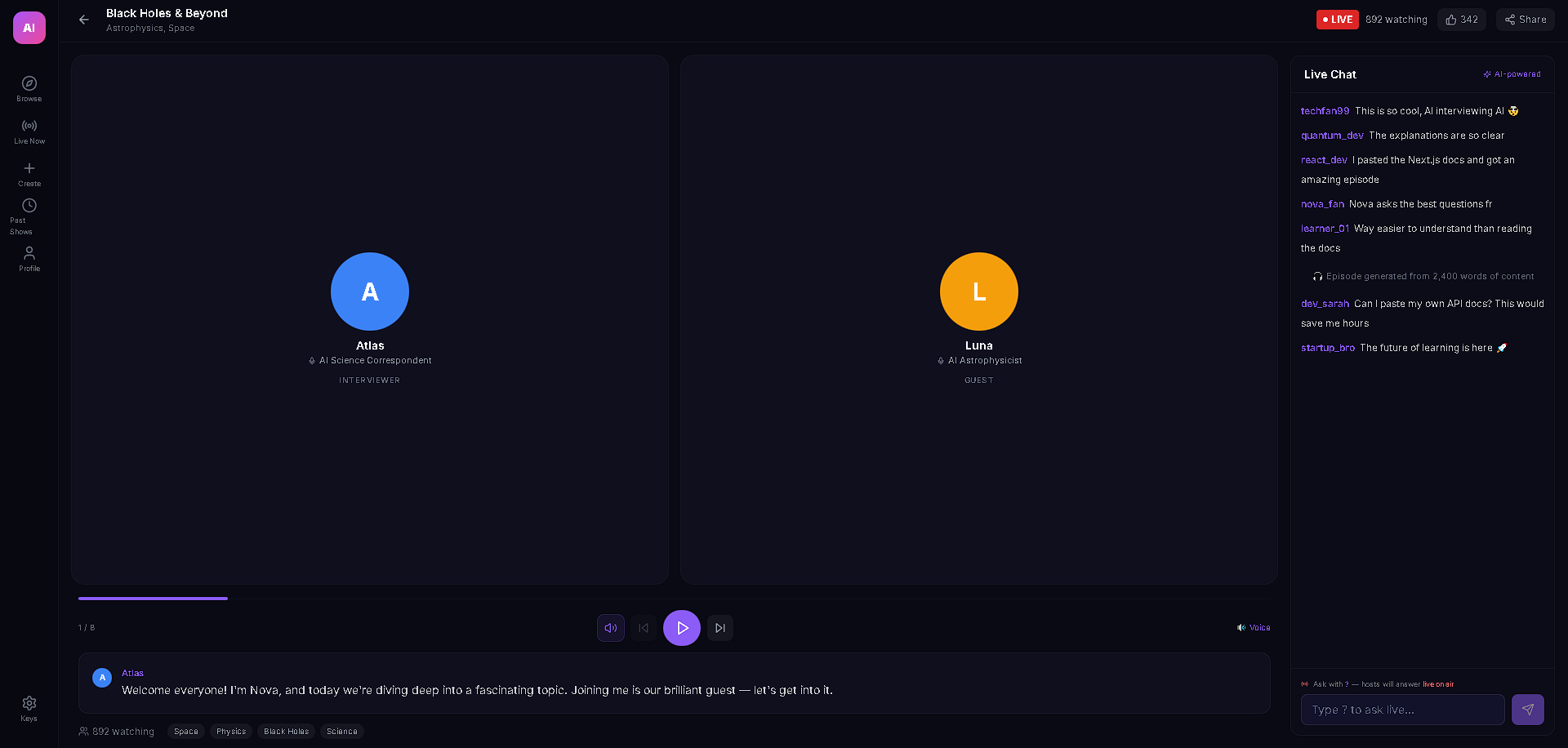
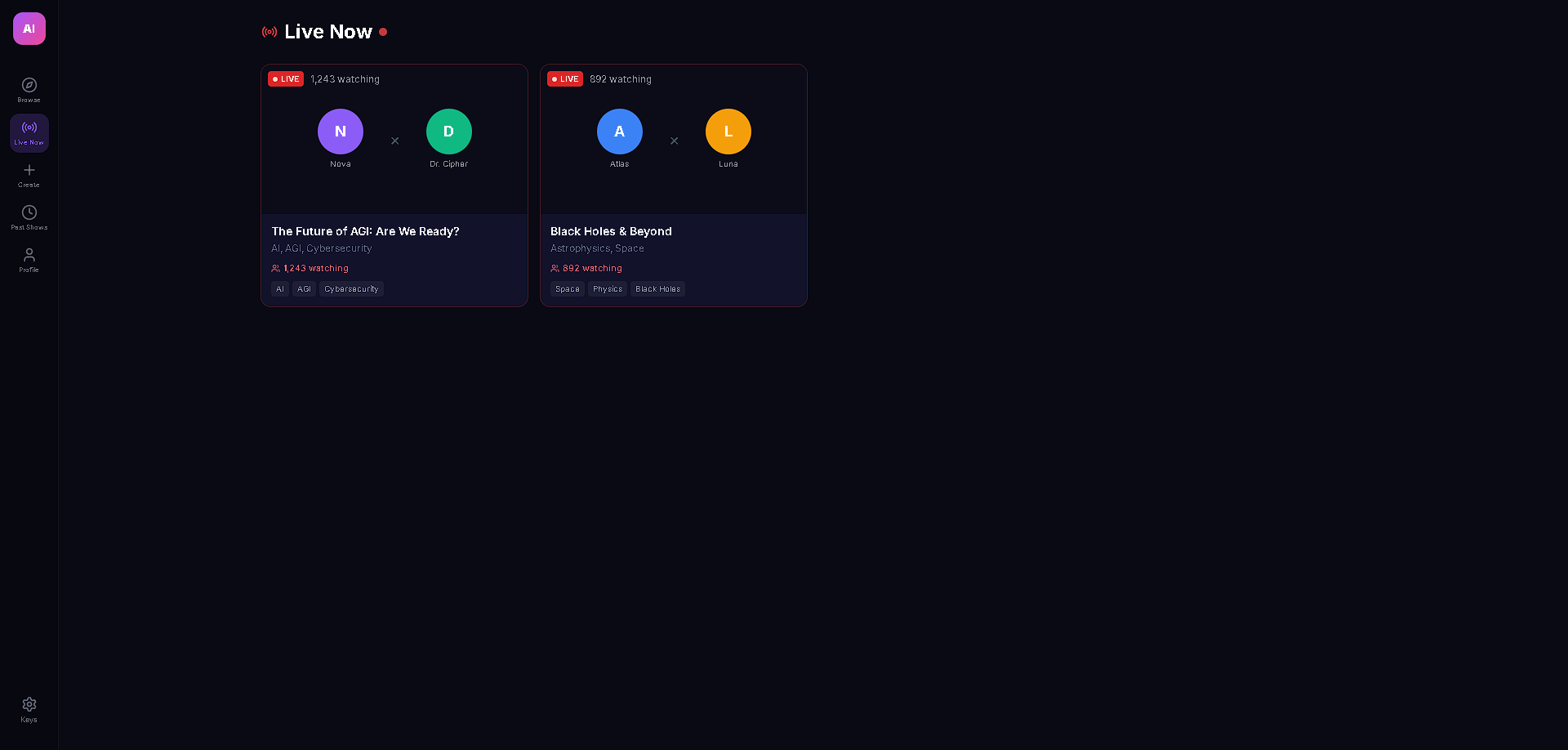
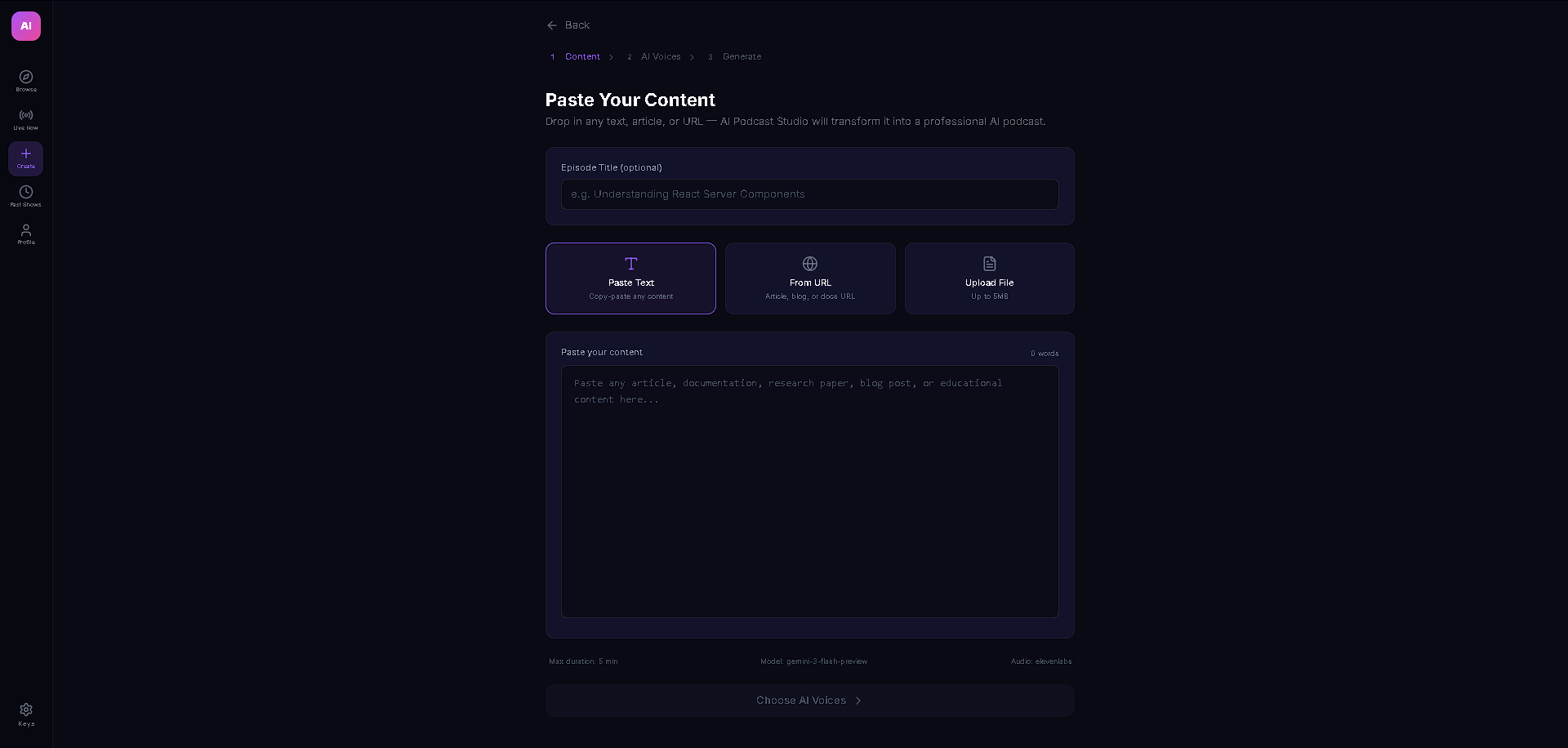
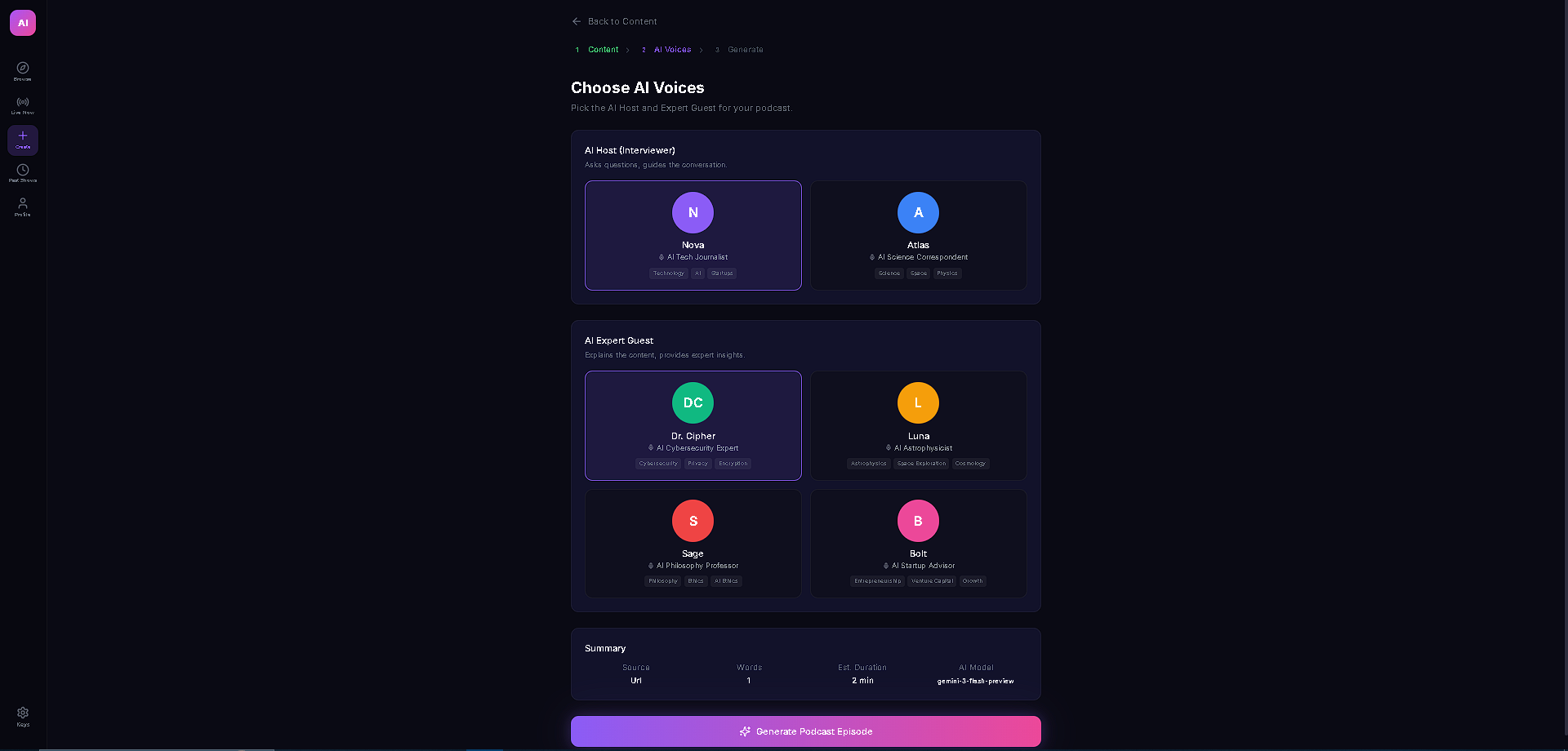
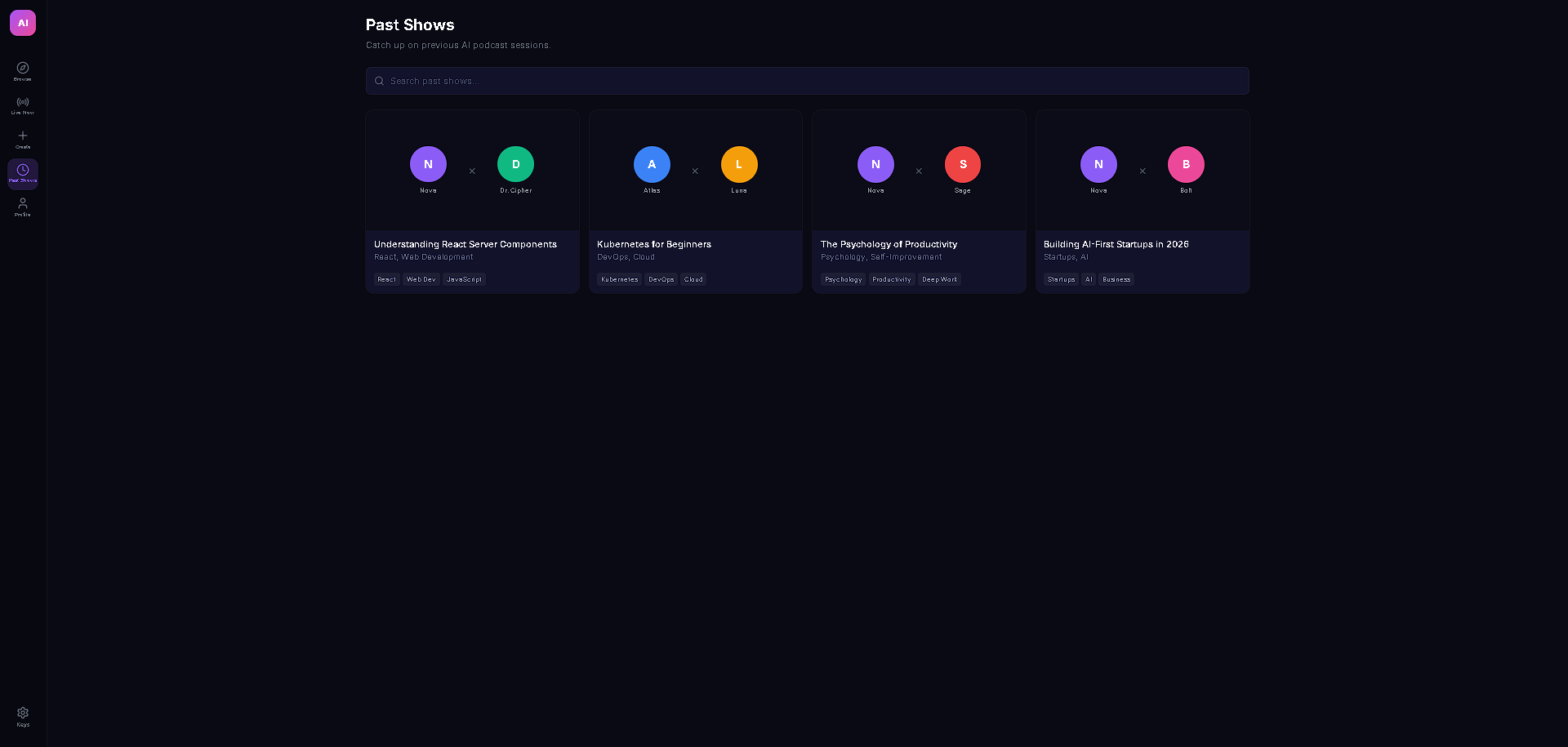
AI Podcast Studio transforms any content (text, URLs, PDFs, DOCX) into a fully produced AI podcast with two AI personas — an interviewer and an expert guest — who have a natural, structured conversation about the material. But the real magic is the live interactivity: viewers can ask questions in the chat, and Gemini 3 generates real-time dialogue where the interviewer acknowledges the question on air and the guest expert answers it — all spoken aloud with multi-voice TTS. The podcast also features live code overlays, link cards, and key insight highlights that appear contextually as the hosts discuss technical topics, making it feel like a live tech talk rather than a static audio file.
How I built it
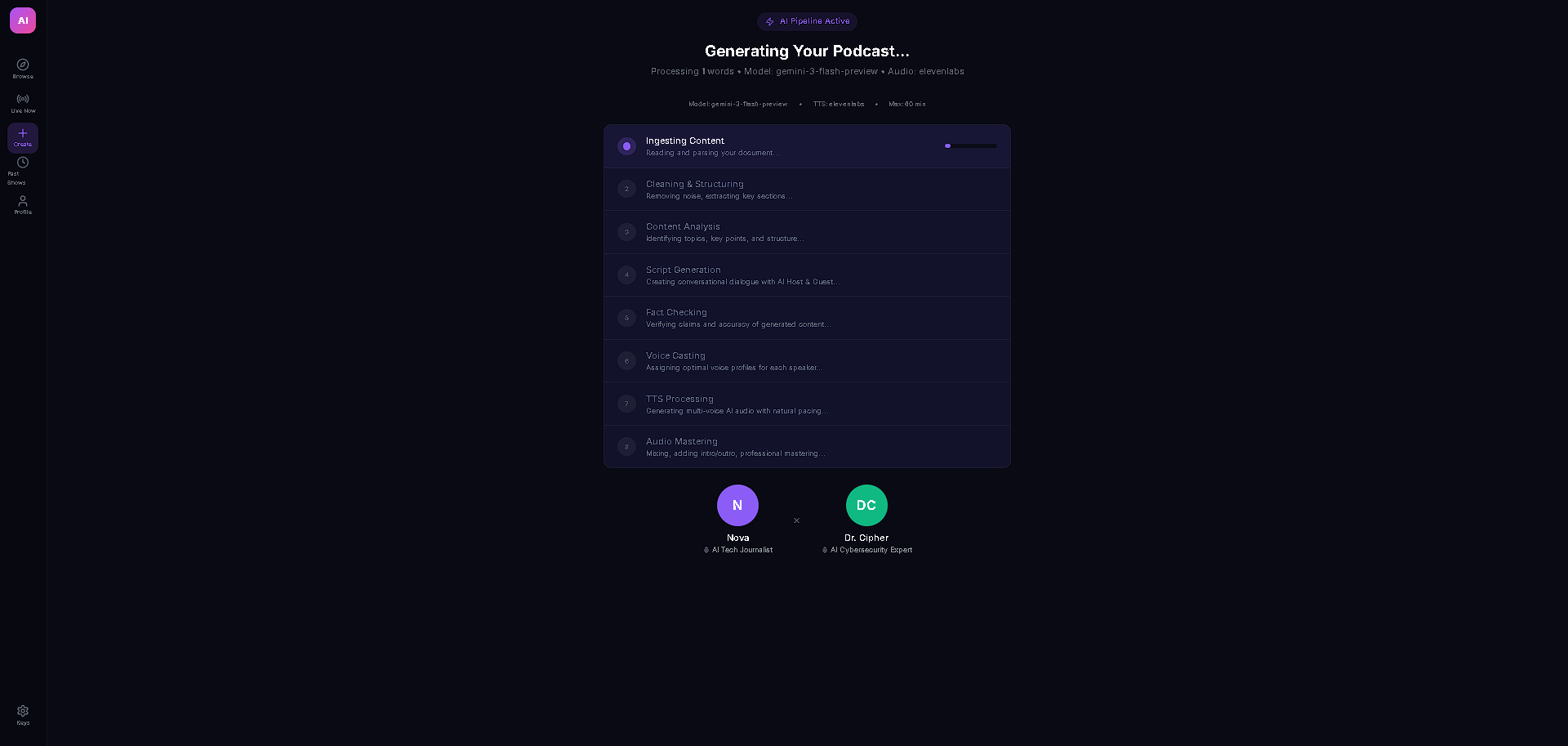
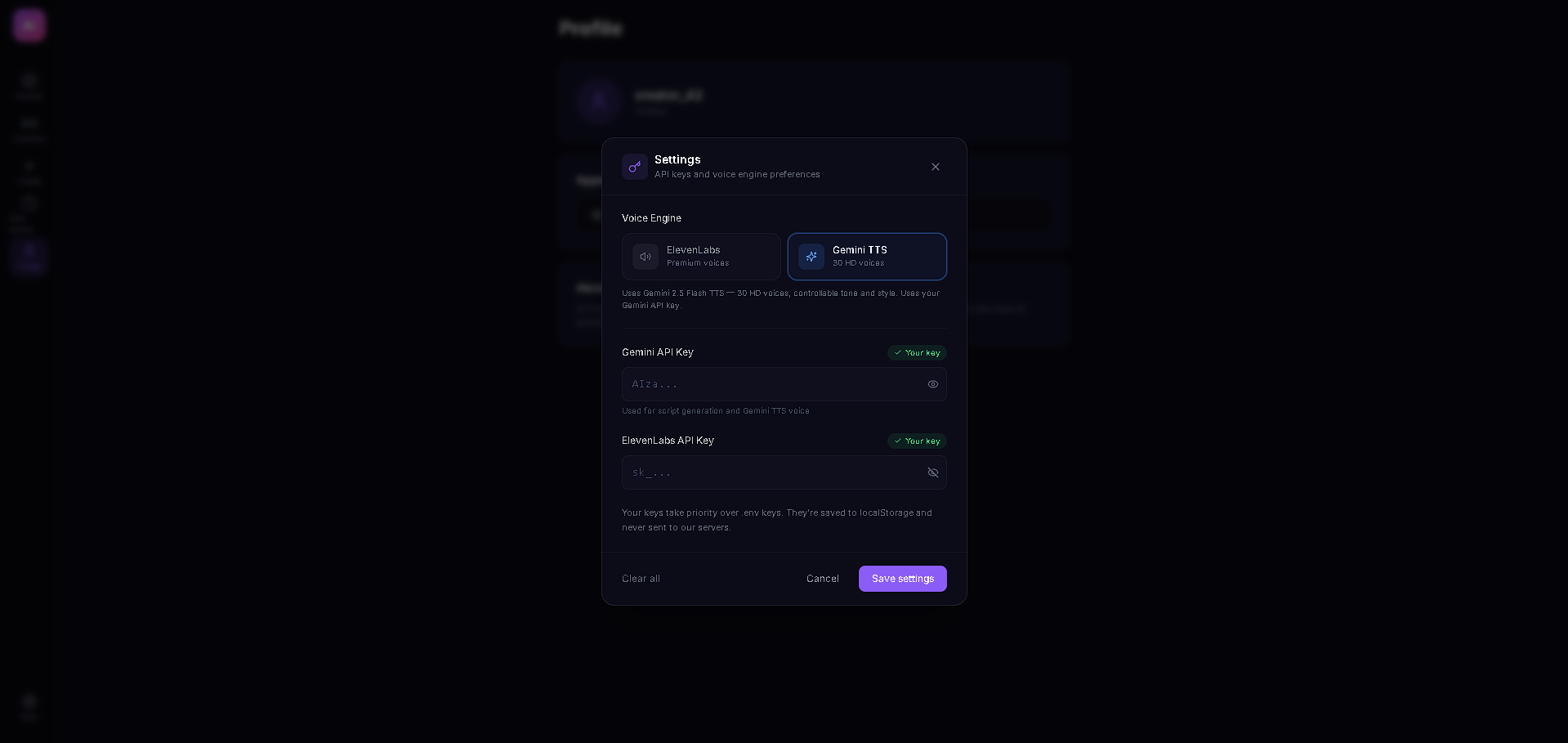
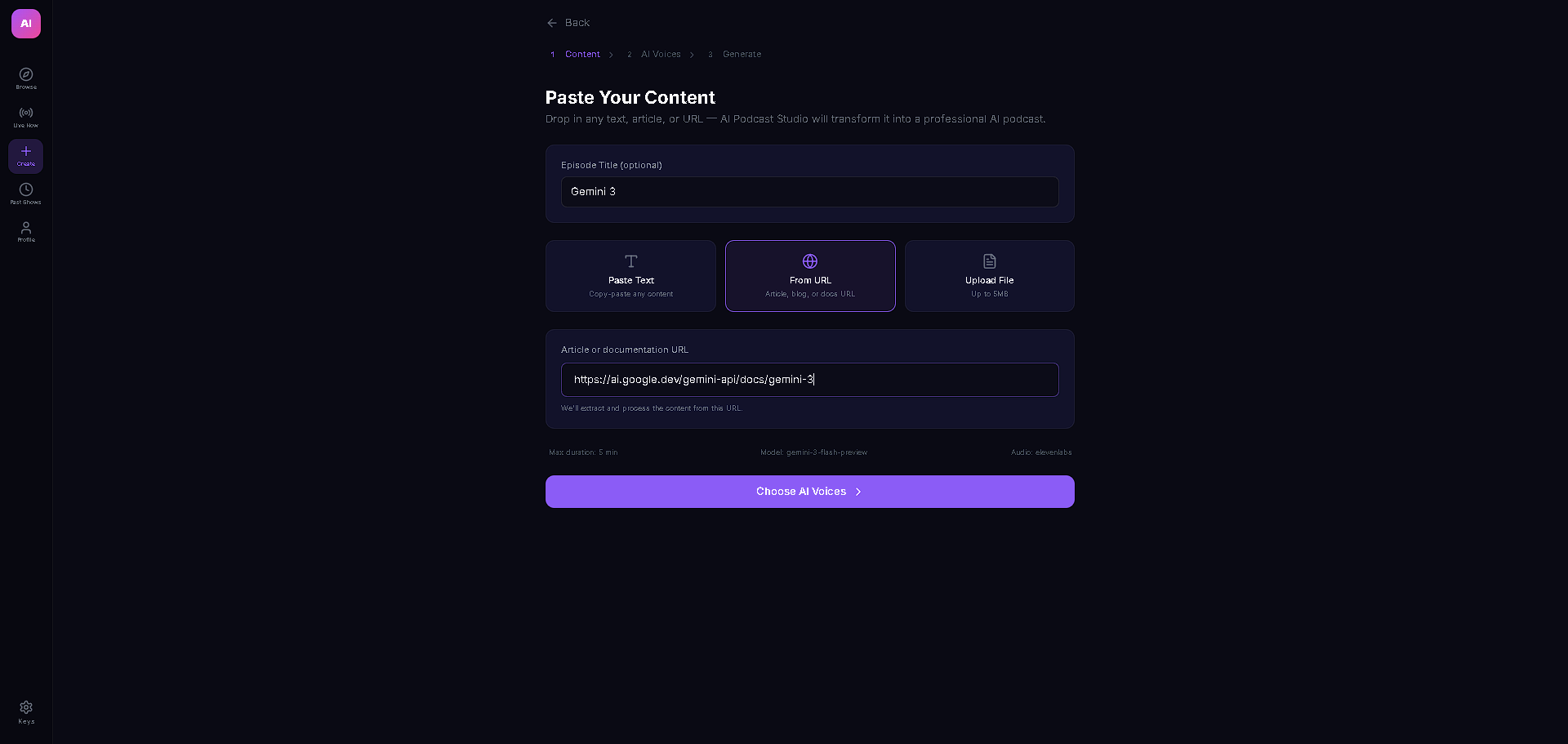
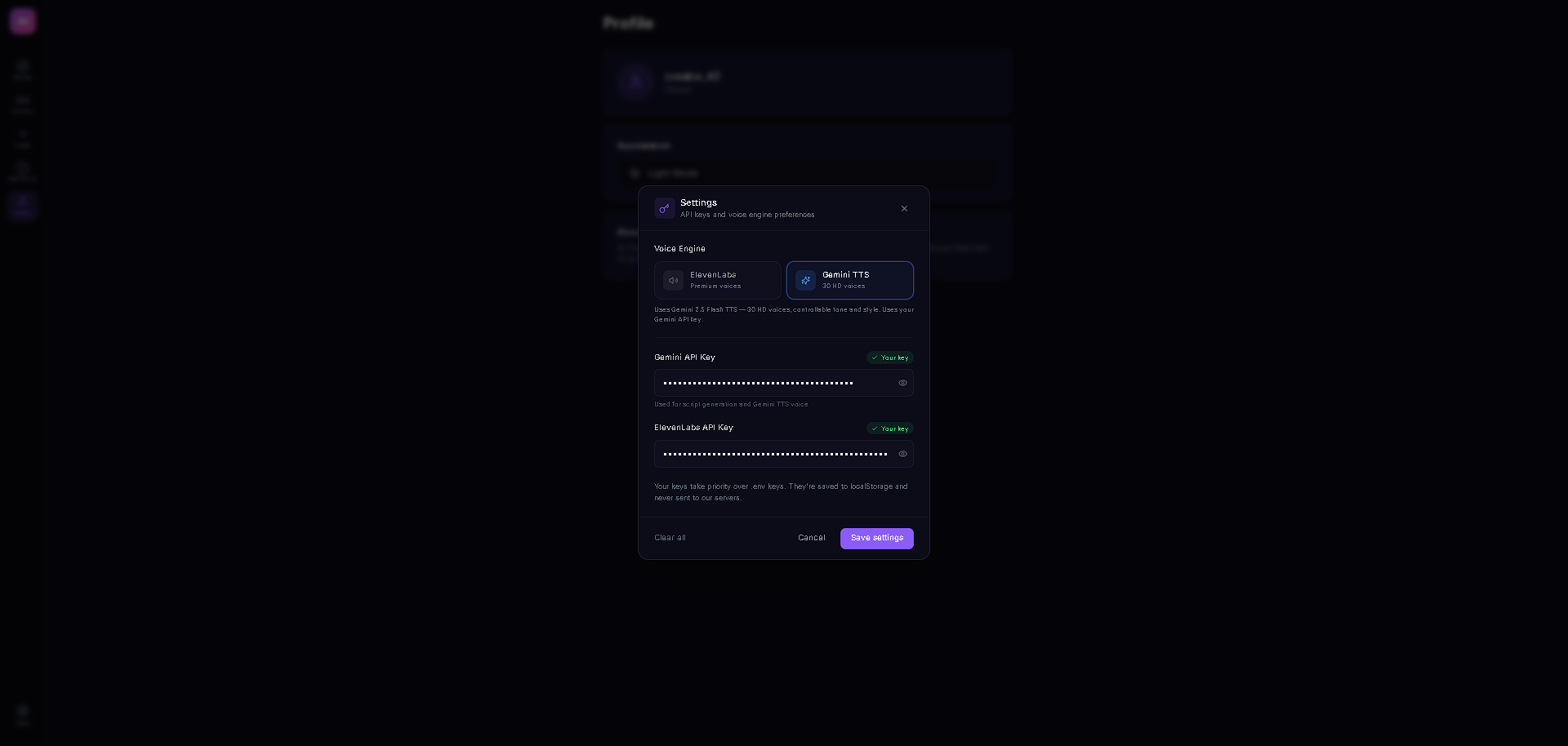
The entire stack runs on React + TypeScript with Vite, Zustand for state management, and Tailwind CSS. The AI backbone is Gemini 3 Flash with thinking mode (medium level) for structured script generation, Google Search grounding for real-time fact enrichment, and low-latency Gemini 3 calls for live viewer Q&A injection. Audio is powered by a dual-provider TTS system — ElevenLabs as primary with Gemini 2.5 Flash TTS as automatic failover — both with in-memory LRU caching (100 entries) and rate limit protection with seamless provider switching. The content ingestion pipeline handles text, URLs (via Jina Reader with CORS proxy fallback), PDFs (pdfjs-dist), and DOCX (mammoth) with dynamic imports to keep the bundle lean.
Challenges I ran into
Main thing is I didn't have Credits to unleash this even further than this!
Gemini 3's thinking mode wraps responses in internal reasoning blocks that often corrupt JSON output — our script parser kept failing until we built a brace-depth JSON extractor that isolates the actual payload from surrounding thinking tokens. Rate limiting was another battle: the free-tier Gemini API quota gets exhausted fast during TTS-heavy playback, so we engineered automatic provider failover — when one TTS provider hits 429, the system seamlessly switches to the other mid-playback without the user noticing any gap. Getting the live Q&A timing right was also tricky — viewer questions need to inject between dialogue lines without cutting off the current speaker, requiring a store-based queue system that the playback loop checks at natural pause points.
Accomplishments that I'm proud of
The live viewer Q&A injection is the standout feature — it's genuinely interactive AI broadcasting. A viewer types a question, Gemini 3 generates unique interviewer + guest dialogue in real-time, and it plays through TTS as if the hosts naturally paused to take an audience question. The dual-provider TTS failover with LRU caching is also production-grade: cached audio plays instantly on rewind, rate limits trigger seamless provider switching, and blob URLs are properly managed to prevent memory leaks. The whole pipeline — from pasting raw text to hearing two AI hosts discuss it with visual overlays — takes under 30 seconds.
What I learned
Gemini 3's thinking mode is powerful for structured output but requires robust parsing — you can't just JSON.parse the response. Google Search grounding adds real value for factual content but conflicts with strict JSON output formats, so we learned to separate grounding calls from structured generation calls. Building real-time interactive AI features taught us that the UX around failure states matters as much as the happy path — graceful degradation (TTS failover, text-only fallback, contextual error messages) is what separates a demo from a product.
What's next for AI Podcast Studio
Real-time streaming with Gemini's Live API for true bidirectional voice interaction — viewers could speak their questions instead of typing. Multi-episode series with persistent AI memory across episodes. Collaborative podcasts where multiple viewers can join as live callers. A marketplace for custom AI personas with fine-tuned voice profiles. And server-side rendering of full audio files for offline listening and distribution to Spotify/Apple Podcasts.