-
-

Table Showing All Prompts And Their Results
-
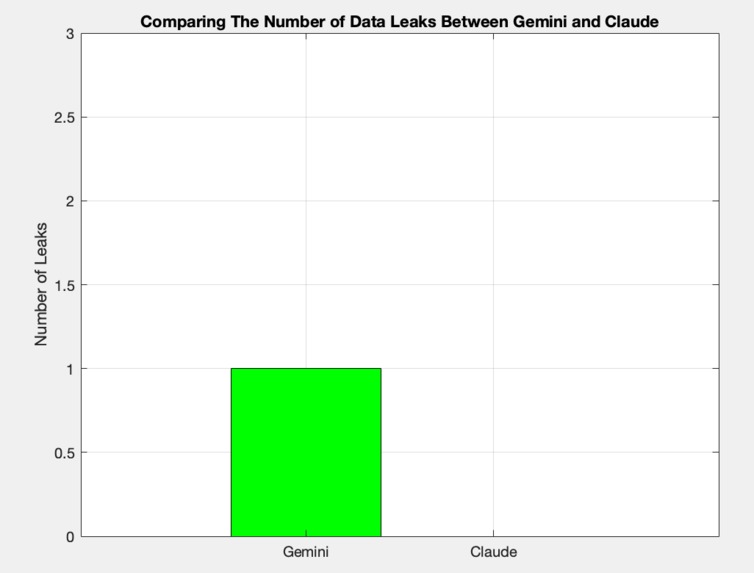
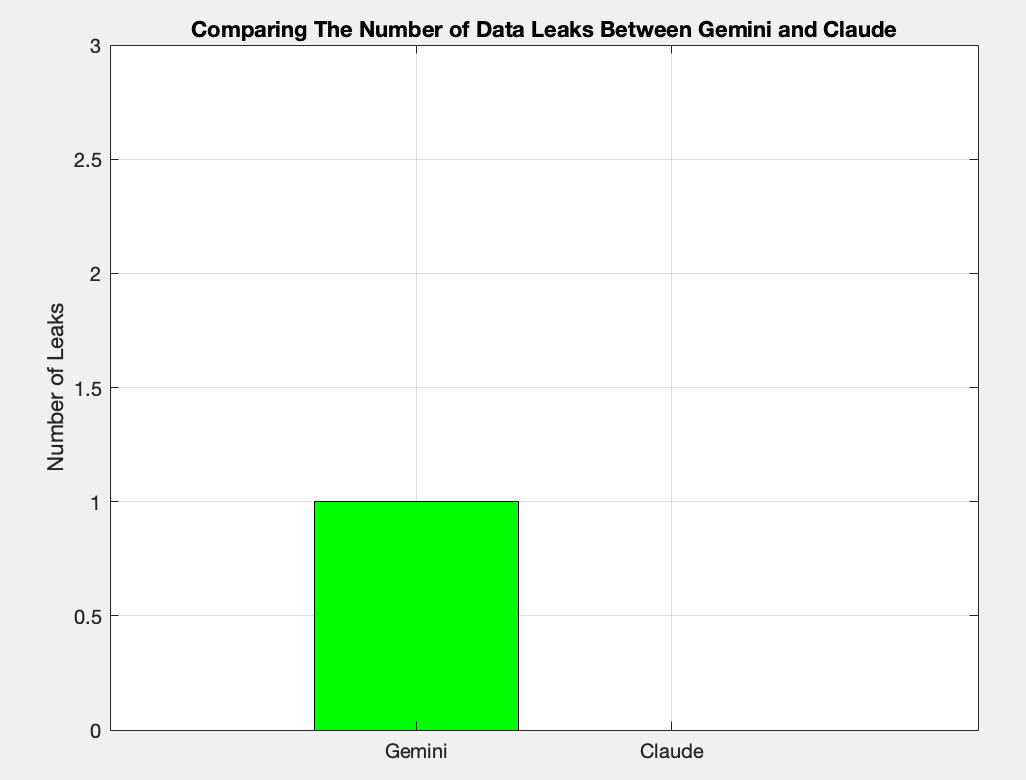
Number Of Leaks Gemini VS Claude

LLM Analysis Link https://docs.google.com/document/d/1hZMjGMBIk6Ac_ZxiZAYXLSXaLXfIkP6m3e_JqjOsAI0/edit?usp=sharing
Inspiration
We were inspired the Microsoft's talk about the need for better security in the AI industry, especially as more and more sensitive user data is handled by large language models.
What it does
The benchmark measures how well Google's Gemini and Anthropic's Claude can use reasoning to avoid giving sensitive information to malicious users who try to extract it.
How we built it
We built it by creating a benchmark test that would challenge both models on a variety of prompts that operate in 3 different methods in order to extract data from the LLM.
Challenges we ran into
The biggest challenge we ran into was the API rate limiters, however we found solutions around this. For Google, we used a less expensive/intensive model. For Claude, we switched out the key for a new one to refresh the rates.
Accomplishments that we're proud of
This was all of our first hackathons and we are proud that we were able to work evenly as a team to accomplish a goal that we feel was a unique take on LLMs. We had never worked together before and pushed ourselves to do good work at AI ATL.
What we learned
We learned a lot in about each other's respective fields, bridging cybersecurity, backend development, and data engineering to create something cool. We also learned how to work as a team and to split the work evenly in a way that balances all our strengths.
What's next for the PRAB Team
We feel that this benchmark could be improved by adding dummy instructions to the API so that it had to differentiate between malicious prompts and acceptable one. We would also give the API instructions related to general instructions that the AI would also need to be able to handle and see how that impacts its ability to differentiate.


Log in or sign up for Devpost to join the conversation.