

Inspiration:
Thinking of projects to present at ZiHack and looking at Simona's idea in regards to Open.AI Pilot, together with our experience in Data Analytics + Google Cloud, sparkled this idea. We've started from these aspects with the goal in mind to process text via AI with Mirro for feedbacks and feedback requests as data sources.
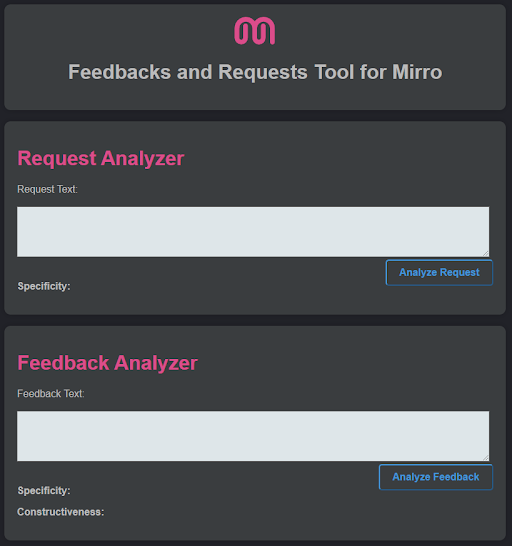
What it does
- It processes feedback requests and given feedbacks based on the models we trained
- It evaluates the feedback requests in terms of specificity
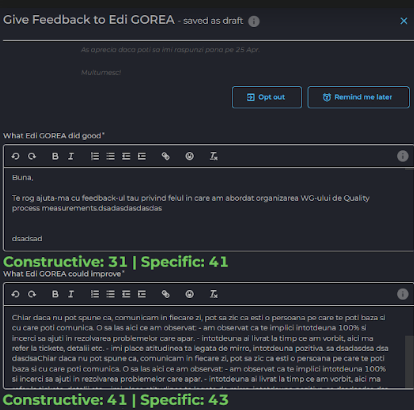
- It evaluates in how specific and constructive a feedback is It works on a dedicated webpage, in Mirro, and even as a function in Google Sheets.
How we built it
Sweat, potato chips and tear drops. Besides this, we cleaned up and prepared the data > We trained our models in Vertex AI (Auto ML) > We deployed them as endpoints and used them in Google Cloud Functions > We built the webpage stored in Google Cloud Storage, developed a Java Script code for Mirro interfacing > We developed a custom Google Sheets function using Apps Script
Challenges we ran into
- initially, in the first training session, we've considered both Mirro feedbacks - in reality there is only one feedback, hence we've realized we changed from a model with two features into a model with one feature and one predicted value applicable to all our measures regarding feedback
- finding the best and fastest way to train our models
- integration with Google Sheets
Accomplishments that we're proud of
The models were trained with favorable results and we could integrate them in a webpage and browser extension for Mirro users to see directly in Mirro app.
What we learned
We've learned a lot about Auto ML Natural Language and how we can do regressions from Text Data. Also, team work is important and how we pre-process data is vital for ML projects.
What's next for AI.N-AI
We see our model permanently in Mirro to help colleagues in regards to:
- better and more constructive feedback.
- more specific feedback requests t To achieve this we would need to improve the model based on a larger data set.
Built With
- automl
- cloudfunctions
- css3
- google-cloud
- html5
- javascript
- python
- restapi










Log in or sign up for Devpost to join the conversation.