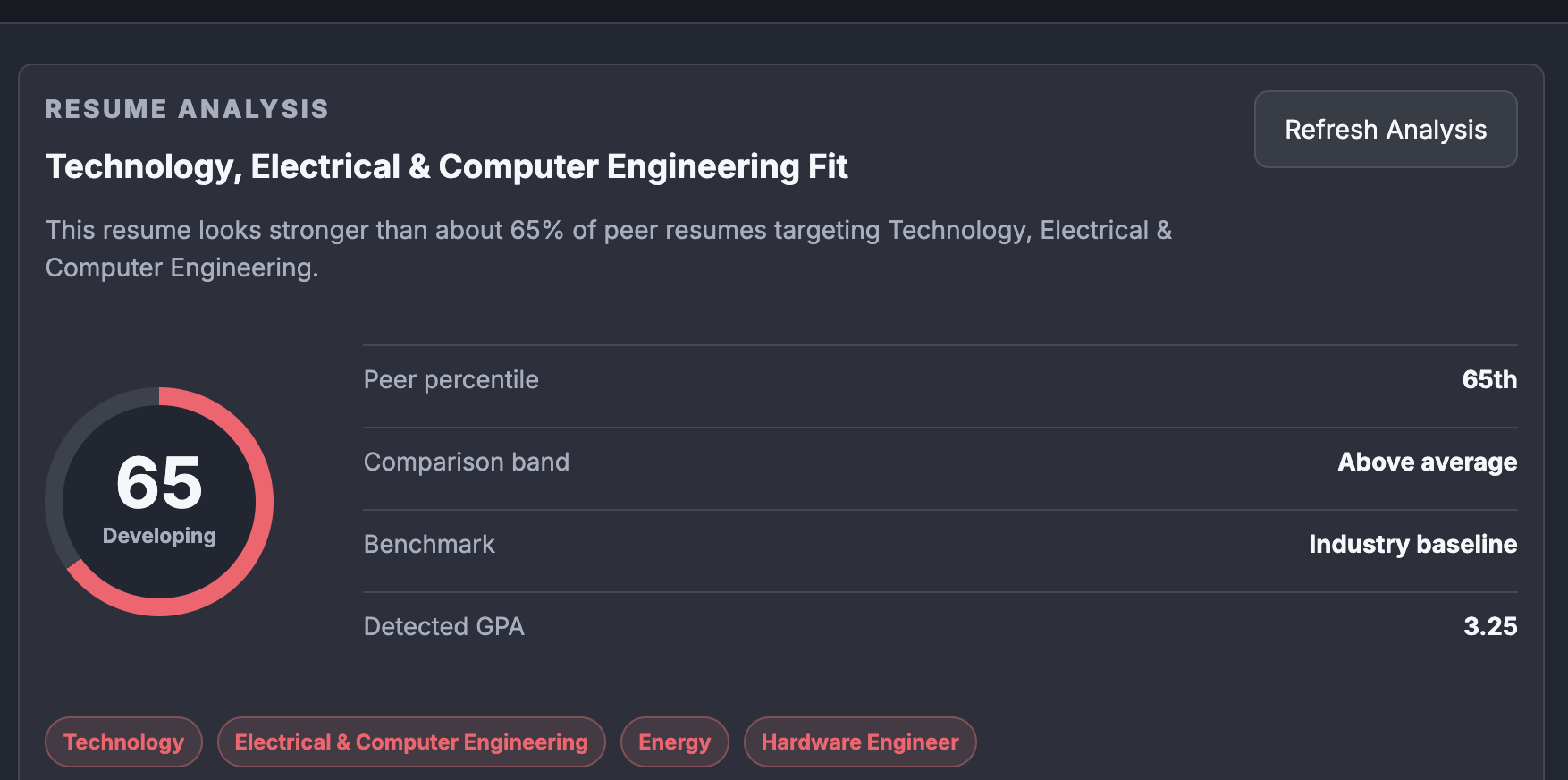
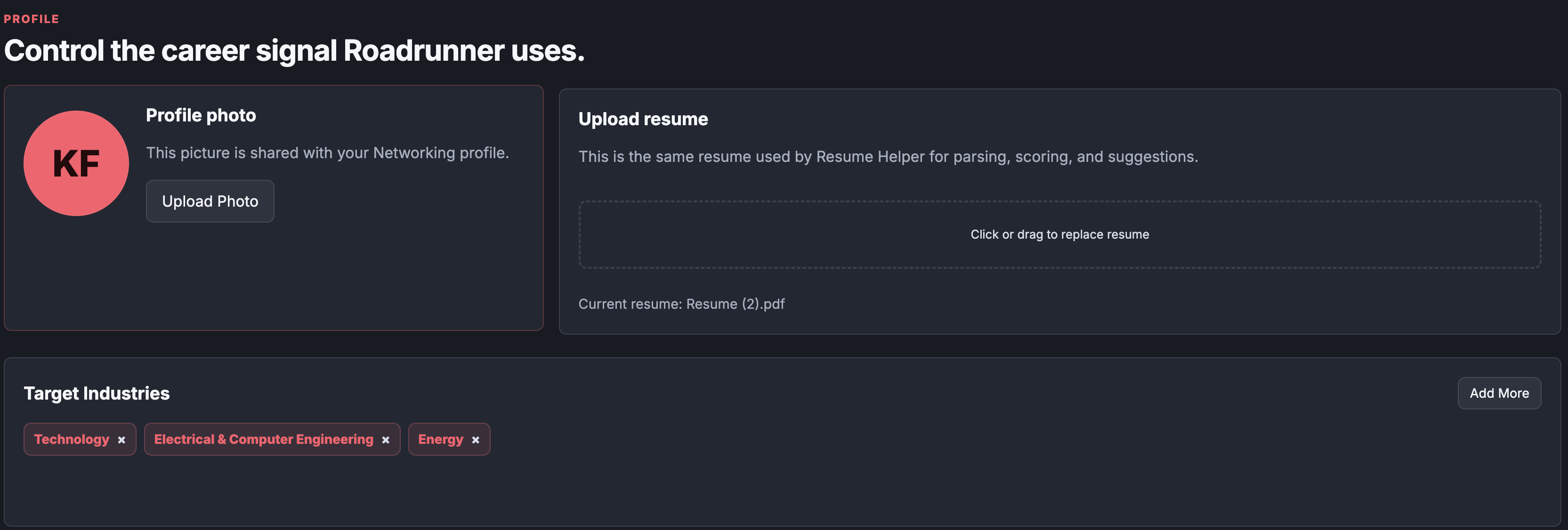
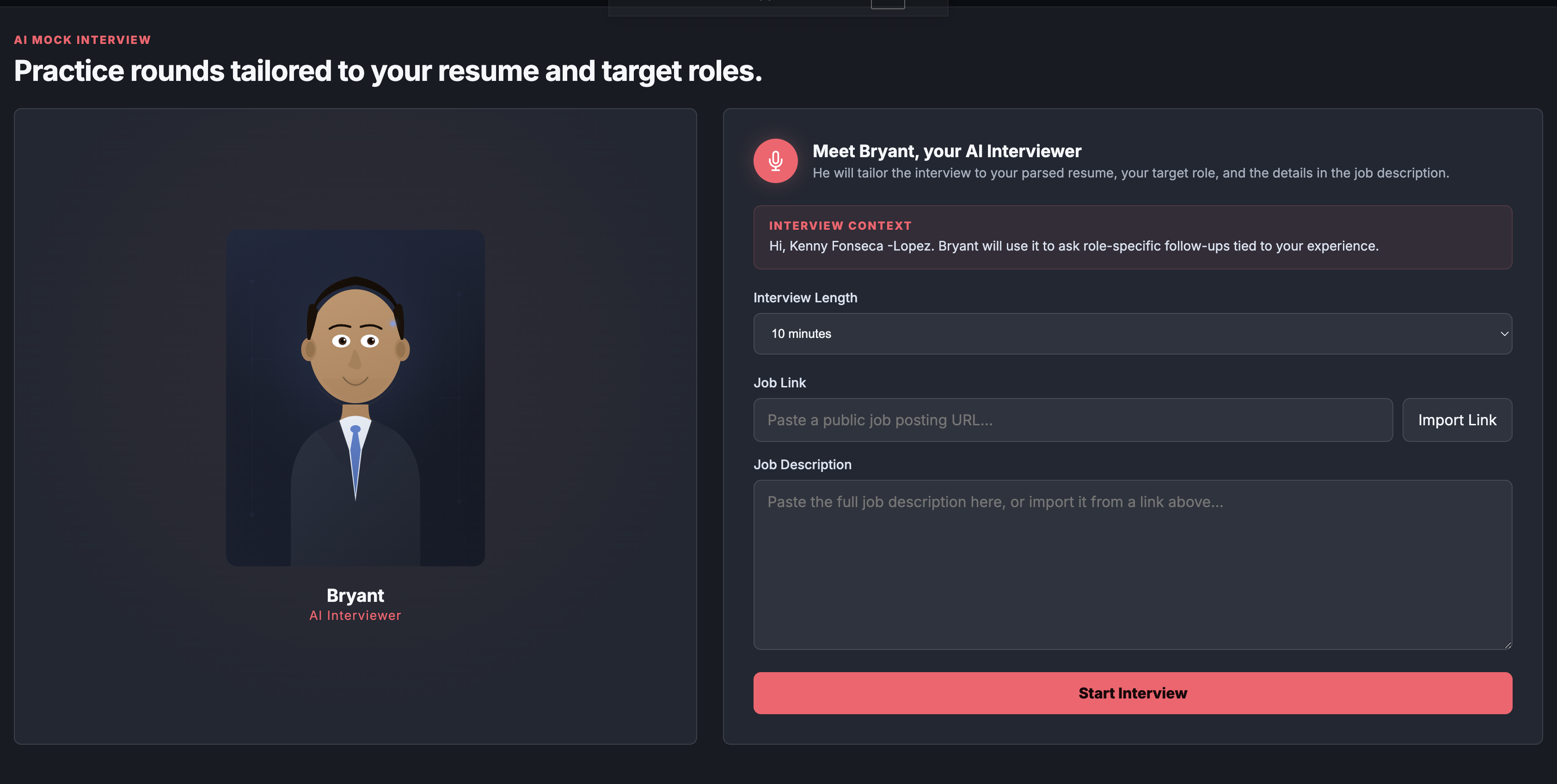
Our roommate Bryant Inspired us by conversing with AI to prepare for his interviews, so we made AI InterviewSim. Mock Interview This tab is mostly LLM-driven. When you start an interview, the app sends your parsed resume plus the pasted job description to /interview/prepare, which builds a structured interview plan with role focus areas and opening questions in backend/main.py (line 1436) and src/lib/generateQuestions.js (line 11). Right now the frontend mainly walks through those pre-generated questions in order in InterviewTab.jsx (line 640), rather than dynamically generating every next question live. When the interview ends, the app sends the actual interview questions, your captured answers, the resume, the job description, and the interview plan into /interview/feedback in backend/main.py (line 1552). If that AI feedback call fails, it falls back to a local rule-based review using things like answer length, quantified details, and hesitation patterns in InterviewTab.jsx (line 333) and InterviewTab.jsx (line 687). Resume Helper This is a hybrid system, not just AI text generation. First, the PDF is parsed with a local rule-based parser using regexes and section detection in backend/main.py (line 286). It extracts name, email, phone, summary, skills, experience, education, and projects. Then the screening itself happens in backend/resume_analysis.py (line 262). The base score is heuristic: • structure • experience depth • impact/quantified bullets • keyword alignment to target industries/roles • polish On top of that, it blends in trained ML industry-fit signals: • a Technology logistic regression model in technology_resume_model.py (line 1) • a multi-industry one-vs-rest logistic regression model in industry_resume_model.py (line 1) For the actual training data: • the technology model metadata says it used 44,130 labeled examples, with 35,304 train and 8,826 test in technology_logreg_metadata.json (line 1) • the multi-industry model says 44,895 labeled resumes, with 35,916 train and 8,979 test in industry_logreg_metadata.json (line 1) • the project also includes a curated benchmark file of 2,200 strong benchmark resumes in resume_benchmarks.jsonl (line 1) • the raw archive files behind this are large CSVs, including 54,934 people rows and 226,761 skill rows So if you ask “what algorithm was the resume screening taught on,” the honest answer is: custom feature extraction plus logistic regression, blended with hand-built scoring. Networking The networking tab is mostly product logic and stored user state, not a trained recommendation model yet. The premium contacts are currently a curated set of sample users in Networking.jsx (line 5). The outreach angle is prewritten per contact. The premium messaging feature now lets you send outreach, stores threads per contact, and keeps that conversation history in your profiles.onboarding.networking_profile.messageThreads JSON via Supabase in Networking.jsx (line 252) and Networking.jsx (line 325). So it behaves like an in-app messaging history, but it’s still simulated networking contacts rather than a real user-to-user marketplace yet. Job Finder This is not a trained recommender model right now. It builds a search profile from: • target industries • target roles • target companies • resume skills • experience titles • project tech That logic is in JobSearchPanel.jsx (line 27). It then generates several search queries, calls a Supabase Edge Function job search endpoint in searchJobs.ts (line 34), and ranks returned jobs with a rule-based match score in JobSearchPanel.jsx (line 135). So this tab is “resume-aware search + ranking,” not “trained recommendation engine.” Profile This tab is basically the control center for the rest of the app. It stores: • target industries • target companies • target roles • networking avatar/photo That is saved into the user’s profiles row in Supabase in Profile.jsx (line 76). Those saved choices then feed Resume Helper, Job Finder, Networking, and the interview context. Big Picture If I had to summarize the architecture in one sentence: • Resume Helper = heuristic scoring + trained logistic regression models • Interview = Gemini-generated planning/feedback + local fallback logic • Job Finder = query generation + rule-based ranking • Networking = premium UI + stored outreach/message history • Profile = shared preference/state layer for the rest of the app If you want, I can turn this into a polished “How InterviewSim Works” section for the website or pitch deck next.
Built With
- css
- htm
- javascript
- json
- python
- supabase

Log in or sign up for Devpost to join the conversation.