-
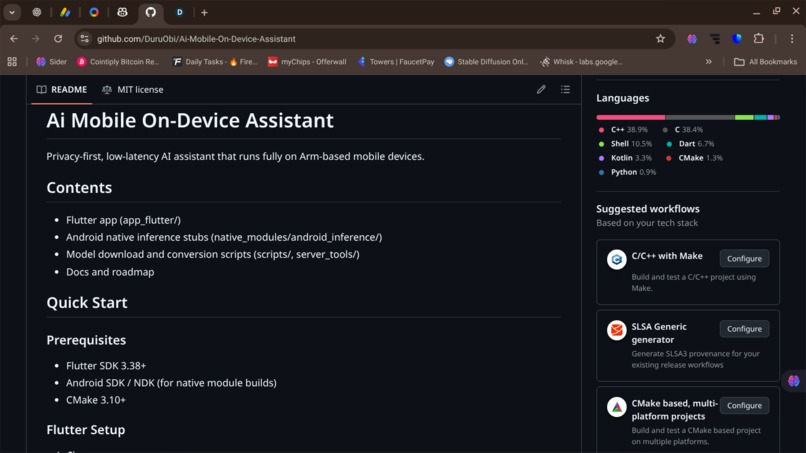
Repo screenshot 1
-
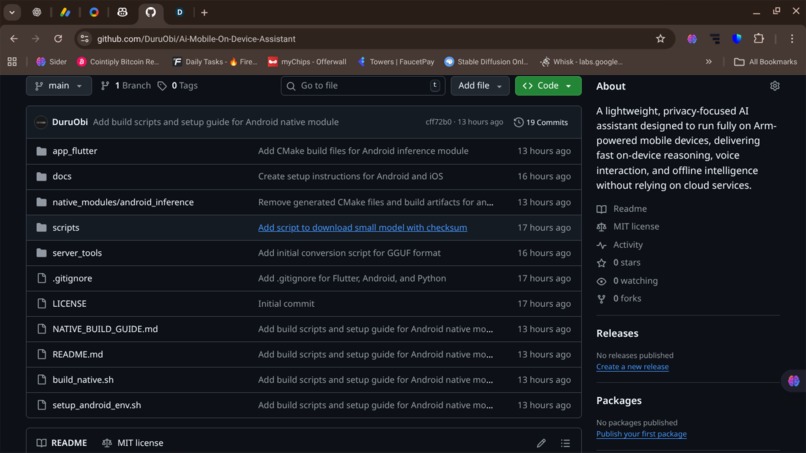
Repo screenshot 2
About the Project
Inspiration
The idea for Ai Mobile On-Device Assistant grew from a simple question: Why should AI rely on the cloud to be useful?
Most assistants today send every voice command, query, or task to remote servers. That slows things down, drains data, and raises privacy risks. I wanted something different—an assistant that works instantly, privately, and offline, powered directly by the device itself.
This project was inspired by modern edge AI acceleration, lightweight models, and the goal of giving users full control over their information without sacrificing performance.
How I Built the Project
To bring the idea to life, I focused on three core pillars:
- On-Device Model Execution I used mobile-optimized neural networks that run locally using frameworks like TensorFlow Lite, Core ML, or ONNX Runtime Mobile. For example, model quantization reduced size from:
Model Size FP32 ≈ 120 MB → Model Size INT8 ≈ 32 MB Model Size FP32 ≈120MB→Model Size INT8 ≈32MB This allowed fast inference with minimal battery impact.
- Real-Time Voice + Text Interface I implemented:
On-device speech-to-text
Natural language processing
Task execution and quick actions
No server calls, no network dependency.
- Modular Architecture The assistant is built as plug-and-play modules:
Speech Engine
NLU Engine
Task Orchestrator
App Integrations
Privacy Core
Each component can evolve independently as models improve.
What I Learned
Building this project deepened my understanding of:
Edge AI performance tuning
Model compression and quantization
On-device memory constraints
Efficient asynchronous task handling
Balancing accuracy vs. speed
Designing AI flows for real-time interaction
I discovered how much power modern devices already have—and how far you can push that power with the right optimizations.
Challenges I Faced
Every part of the project came with unique obstacles:
🔹 Model Size vs. Real-Time Speed Fitting AI models within mobile limits while keeping inference fast was a constant balancing act. Quantization, pruning, and caching became essential.
🔹 Speech Accuracy Offline Achieving reliable STT in noisy environments without cloud engines required experimentation with acoustic models and DSP preprocessing.
🔹 Memory & Battery Constraints Some operations risked spikes in RAM or CPU usage. I had to carefully schedule tasks and optimize model loading.
🔹 Integrating Multiple ML Components Running STT, NLU, and actions in parallel required tight coordination to avoid blocking UI or causing latency.
Looking Ahead
This is just the beginning. Future improvements include:
Smaller, faster transformer models
On-device embeddings for semantic search
Vision integration for contextual awareness
More offline automation workflows
The goal is to make the assistant even smarter—without ever depending on the cloud
Built With
- c
- c++
- cmake
- dart
- javascript
- kotlin
- python
- pytorch
- shell
- swift
- tensorflow
- typescript


Log in or sign up for Devpost to join the conversation.