-
-
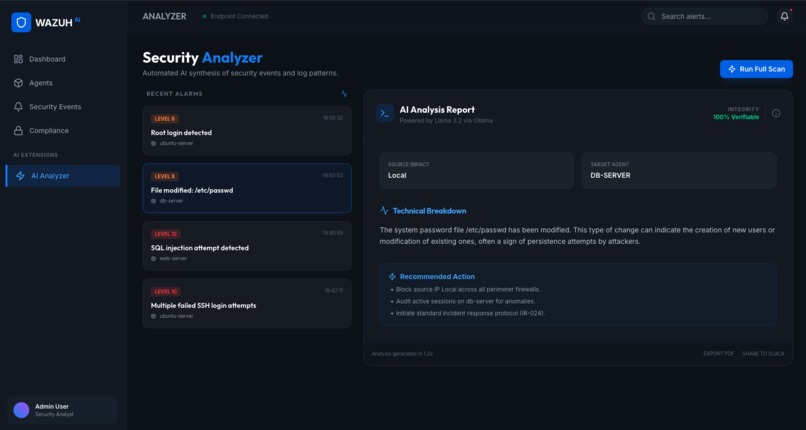
AI Log Analyser Dashboard
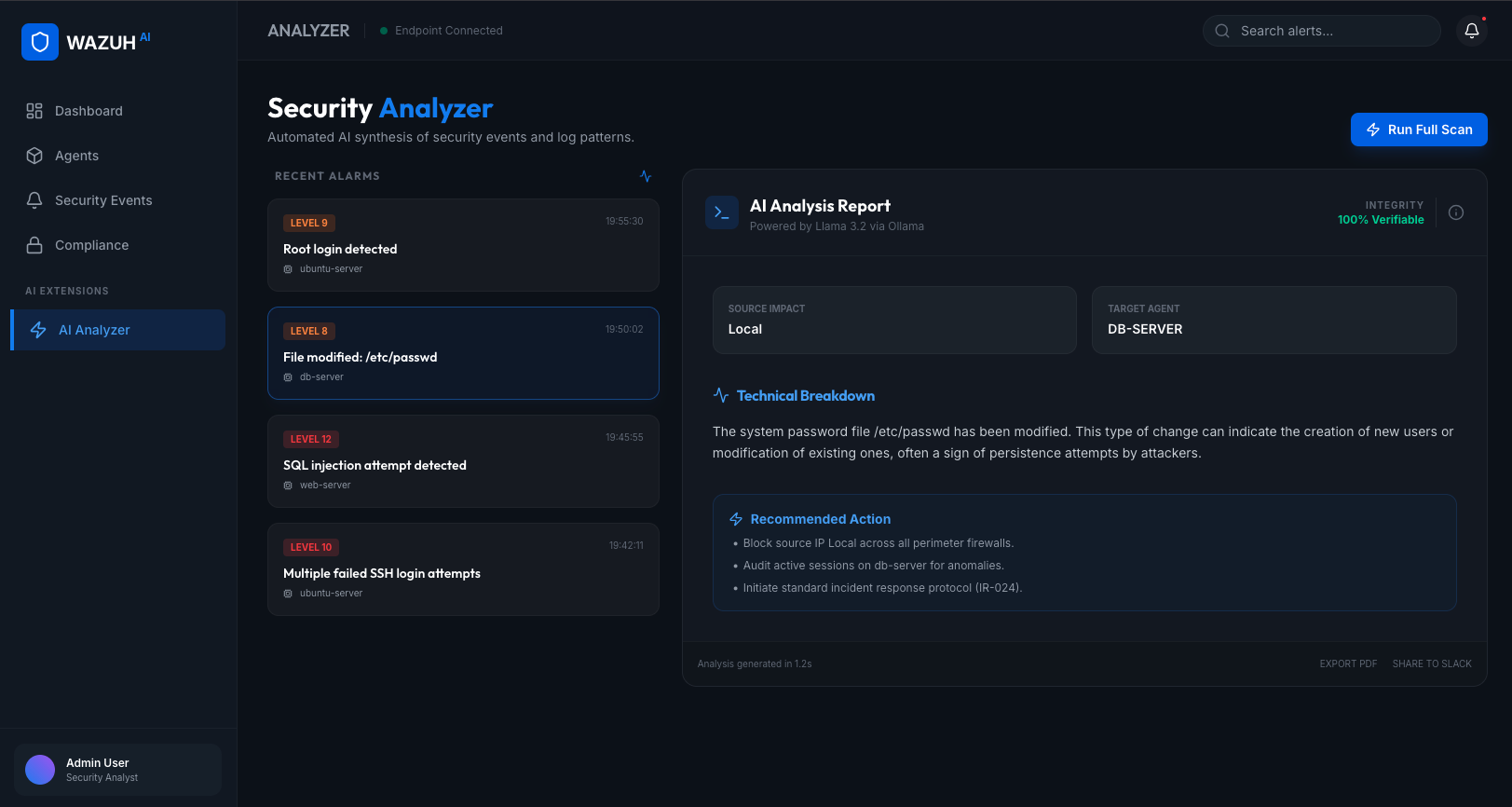
The Journey of AI Log Analyzer
🌟 Inspiration
In the modern cybersecurity landscape, defenders are overwhelmed by a sea of data. Log management systems like Wazuh provide incredible detail, but they often require specialized knowledge to interpret at speed. I was inspired by the idea of bridging the gap between raw technical data and actionable human intelligence.
The goal was simple: What if an AI could look at a security alert and explain it like a senior analyst would?
🛠️ How I Built It
The project is built using a modular Python architecture designed for flexibility and privacy.
Core Components:
- Log Ingestion Engine: A robust parser that handles Wazuh-style JSON alerts. It transforms raw log entries into structured prompts.
- Local LLM Integration (Ollama): To ensure data privacy, I transitioned the project from cloud-based APIs (Gemini) to a local inference engine using Ollama. This allows security teams to analyze sensitive logs without sending data to external servers.
- Analysis Logic: The system maps rule descriptions and data fields into localized context for the AI model (specifically
llama3.2).
Optimization Logic
I wanted to ensure that the "Noise-to-Signal" ratio was improved. If we define the raw alerts as $A$ and the valuable insights as $I$, our goal is to maximize the utility $U$:
$$U = \frac{\sum_{i=1}^{n} I_i}{\sum_{j=1}^{m} A_j}$$
Where $n \ll m$, representing the condensation of data into knowledge.
📚 What I Learned
- Local vs. Cloud Trade-offs: While cloud APIs like Gemini offer high performance, local models (Ollama) provide better privacy and zero latency costs for repetitive tasks.
- Context Engineering: I discovered that the quality of an AI's response is exponentially related to the structure of the input data.
- JSON Resilience: I learned the importance of strict schema validation when dealing with logs generated by various security appliances.
🚧 Challenges Faced
The path wasn't without its hurdles:
- The 429 Wall: Initially, using the Google Gemini API led to
RESOURCE_EXHAUSTEDerrors.- Lesson: Free-tier APIs are great for prototyping but brittle for high-volume log analysis.
- JSON Malformation: Handling logs that were serialized as individual objects rather than an array.
- Solution: I had to implement a correction layer to wrap these into a valid JSON list.
- Rate Limiting vs. Local Hardware: Transitioning to Ollama required managing local VRAM and ensuring the server was reachable. I had to solve for the "timed out waiting for server" error by ensuring the Ollama background process was correctly initialized before CLI calls.
The complexity of the analysis $C$ can be approximated as: $$C(n) = O(n \cdot L)$$ Where $n$ is the number of alerts and $L$ is the inference time of the chosen model.
🚀 Conclusion
AI Log Analyzer is more than just a script; it's a proof of concept that local AI can significanty lower the barrier to entry for security monitoring. By turning complex logs into stories, we empower defenders to act faster.

Log in or sign up for Devpost to join the conversation.