-
-
architectural
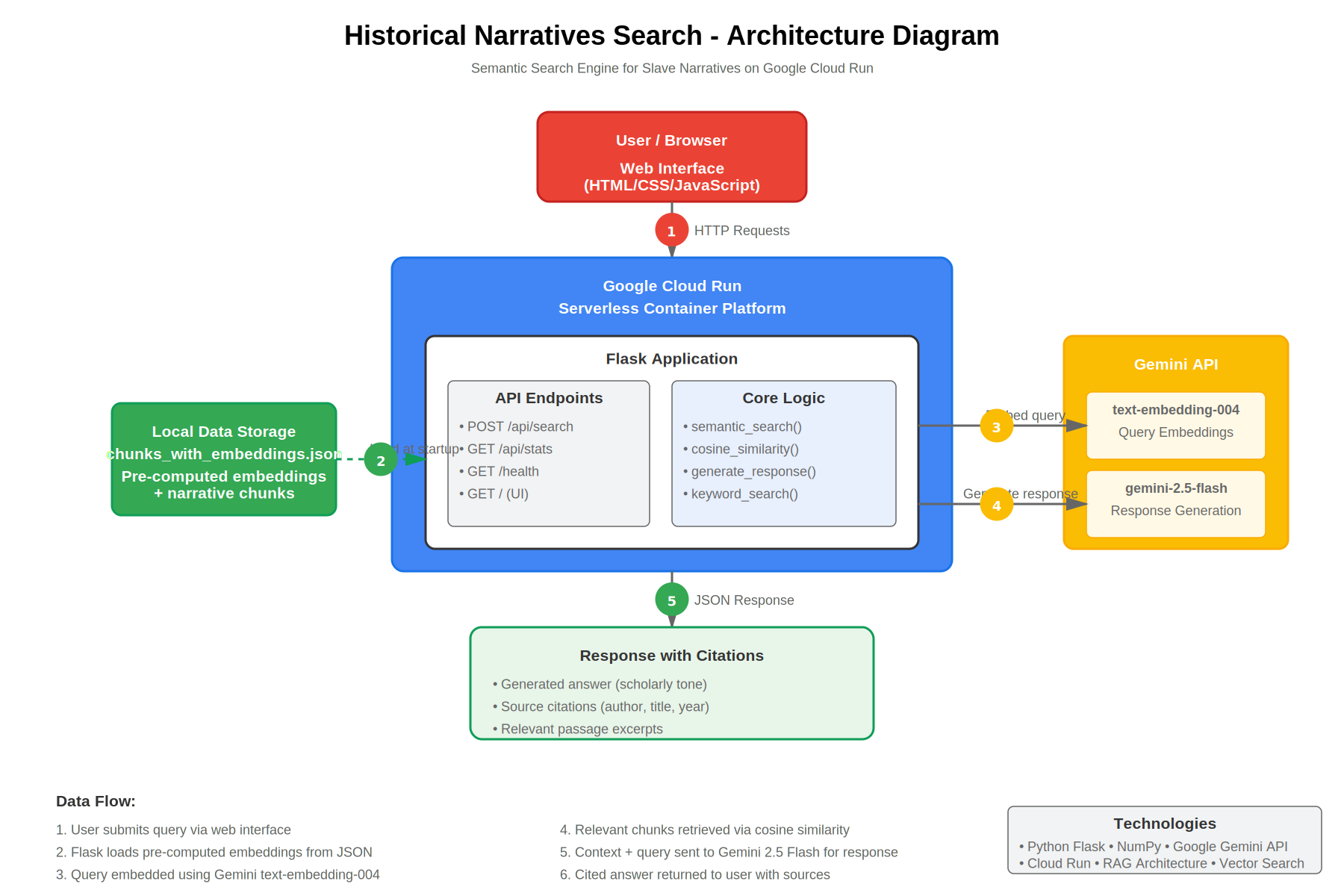
Inspiration I attended a Sheffield United talk about AI in restoring old documents and was really impressed by what AI could do for historical preservation. I realized that historical slave narratives are incredibly important primary sources, but they are practically inaccessible to most people because traditional keyword search simply does not work on these texts. I thought I could build something myself to solve this problem using semantic search to make these powerful historical voices actually discoverable. What it does The application lets users ask natural language questions about slave narratives and get back scholarly answers with proper citations from the actual historical sources. Instead of spending hours hunting through documents with keyword search, someone can just ask a question like "How did enslaved people describe their journey to freedom?" and immediately get relevant passages from multiple narratives with full source citations showing exactly which author and text the information came from. How we built it I built a RAG architecture deployed on Google Cloud Run using a Flask backend. For semantic search I used Gemini's text-embedding-004 model to create vector embeddings, and then used NumPy to calculate cosine similarity between query and document vectors. The actual response generation uses gemini-2.5-flash which takes the retrieved passages as context and generates scholarly answers. I pre-computed all the document embeddings and stored them locally in JSON format to avoid repeated API calls, and the whole thing runs as a serverless container that auto-scales. Challenges we ran into The biggest challenge was balancing response quality against API costs since every query needs an embedding call and a generation call. I solved this by pre-computing all document embeddings once and storing them, which cut costs dramatically and improved latency. Another challenge was handling the historical language in these texts because the writing style from the 1800s is very different from modern English, so I had to do careful prompt engineering to make sure the AI maintained a scholarly tone while still being accessible to students and general researchers. Accomplishments that we're proud of I am really proud that this is not just a demo but a genuinely useful tool that makes primary historical sources accessible to anyone with an internet connection. The system responds in under two seconds while maintaining accuracy through proper RAG architecture that prevents the AI from hallucinating information. Every answer includes proper academic citations so users can verify the sources themselves, which is critical for historical research. What we learned I learned that pre-computing embeddings is a game changer for document collections that do not change frequently because it reduces both latency and costs by an order of magnitude. I also learned how powerful RAG patterns are for keeping AI responses grounded in actual sources rather than making things up, which is absolutely critical when dealing with historical content where accuracy matters. The serverless model on Cloud Run turned out to be perfect for this use case because traffic is unpredictable and I do not want to pay for idle servers. What's next for AI for Historical Narratives Semantic Search I want to expand this to other historical document collections like immigration records, civil rights testimonies, and oral histories from other communities. Adding multi-language support would make it accessible to non-English speakers researching their heritage. I am also thinking about integrating this with educational platforms and adding collaborative annotation features so teachers and students can work together on analyzing these texts in classrooms.

Log in or sign up for Devpost to join the conversation.