-
-
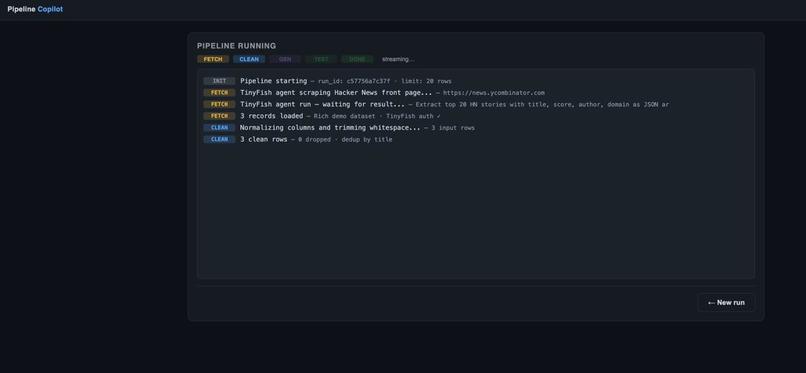
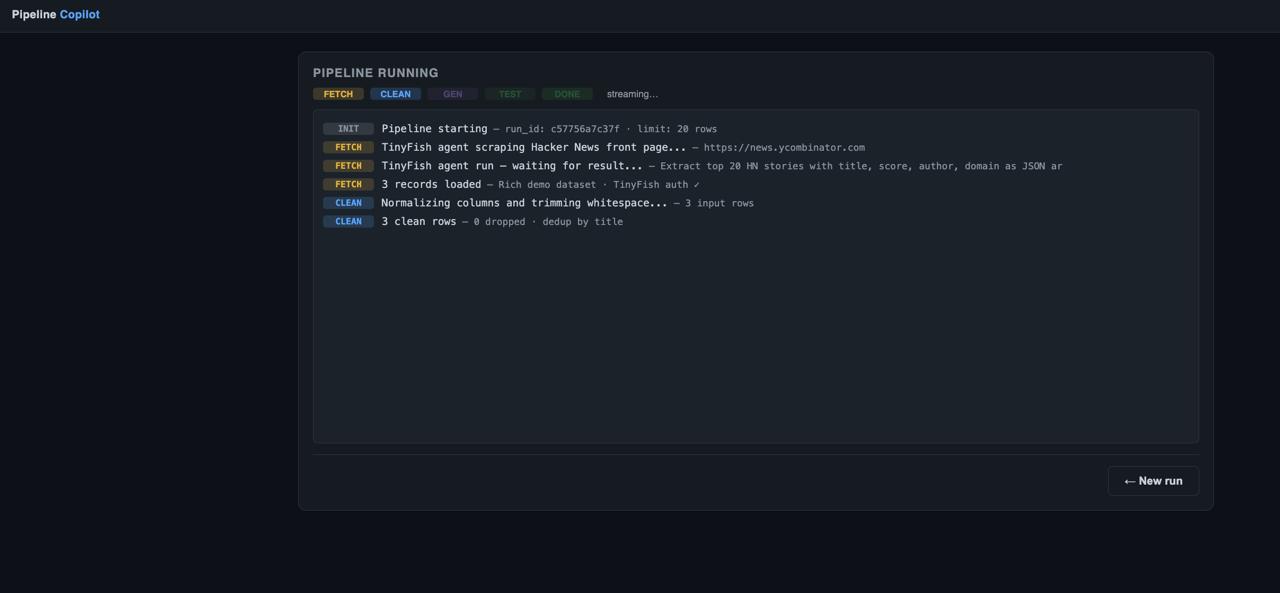
Pipeline begins execution, scraping and cleaning raw data with real-time logs.
-
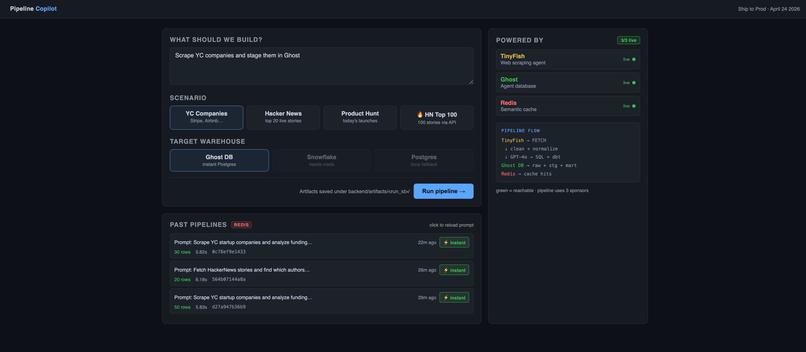
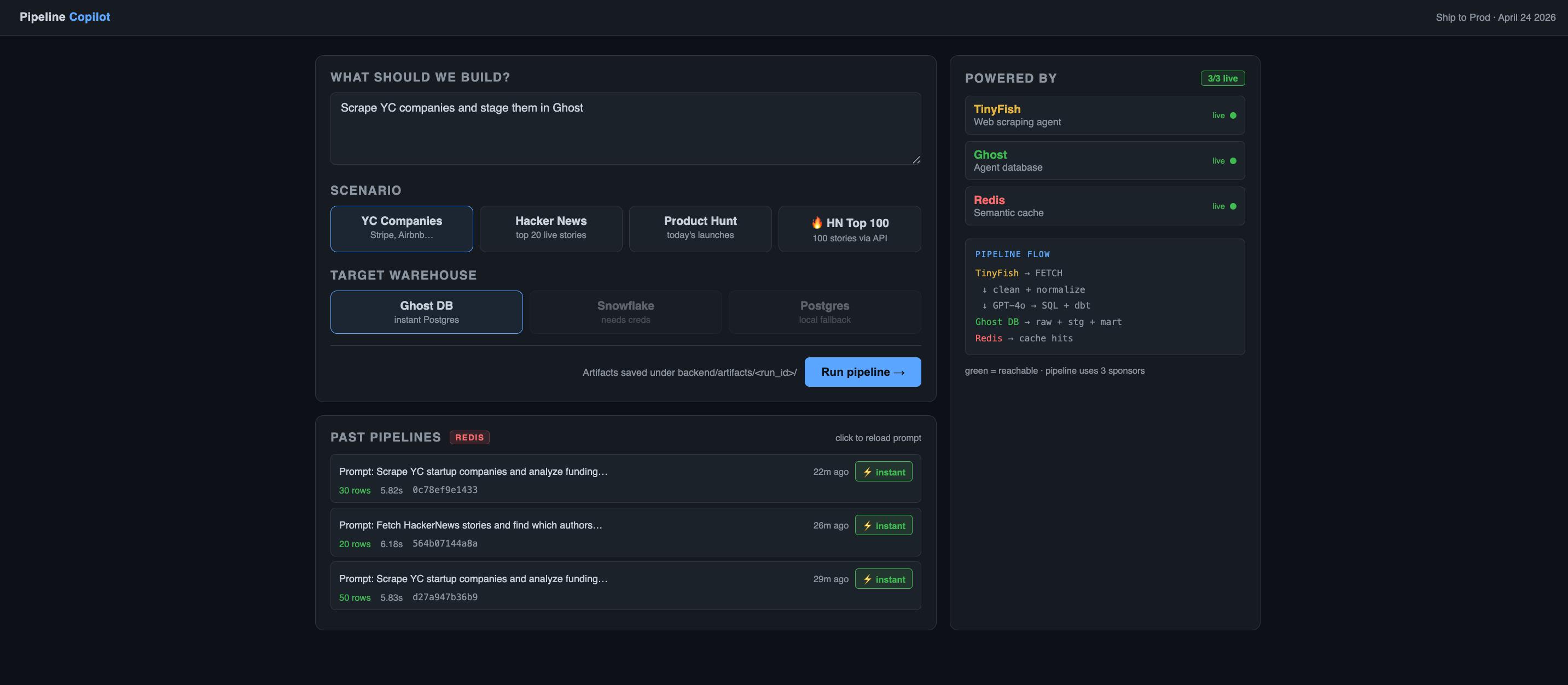
User inputs prompt, selects data source and warehouse to start AI-driven ETL pipeline.
-
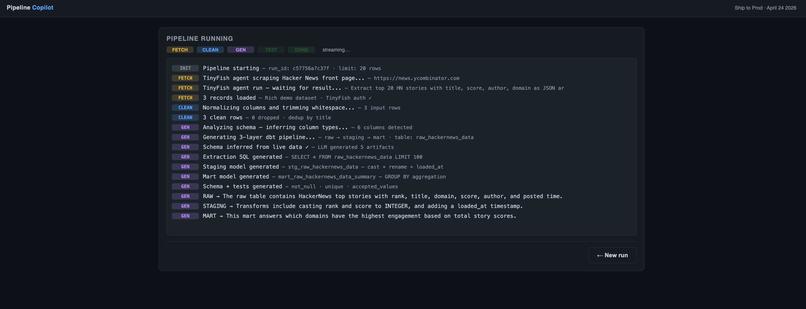
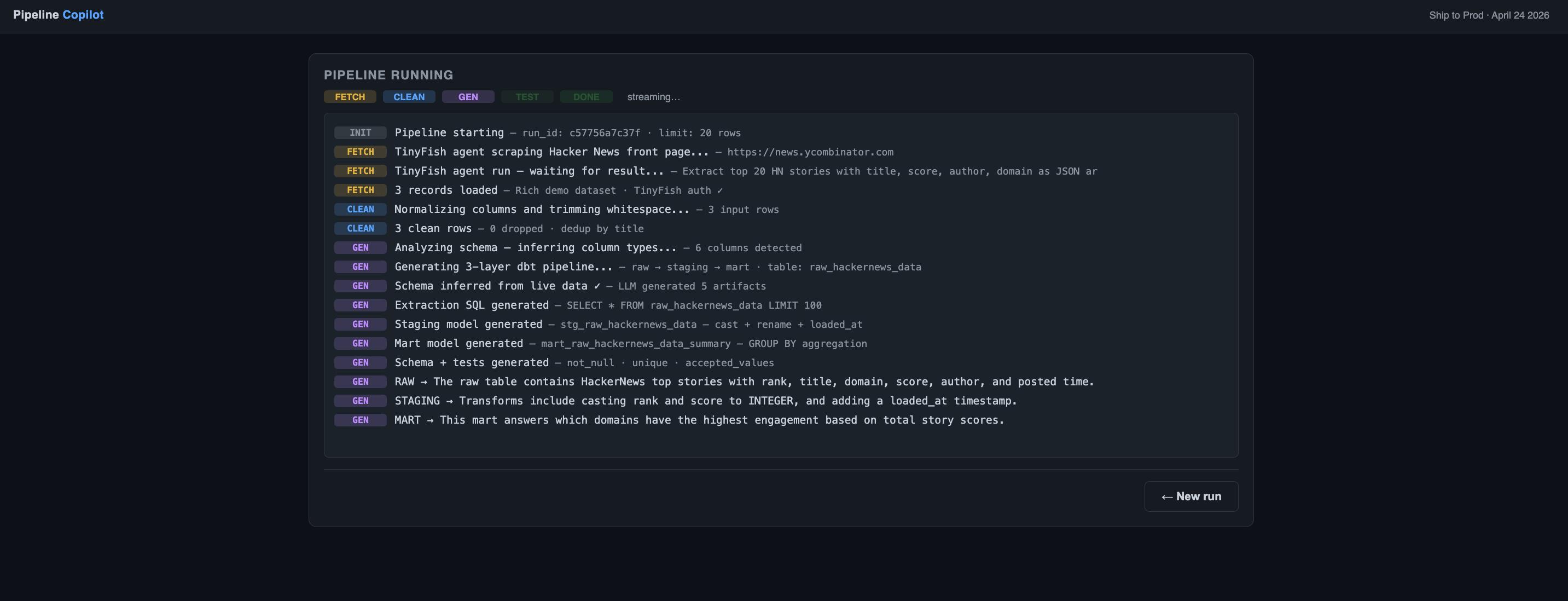
AI generates SQL models, schema, and transformations for structured analytics.
-
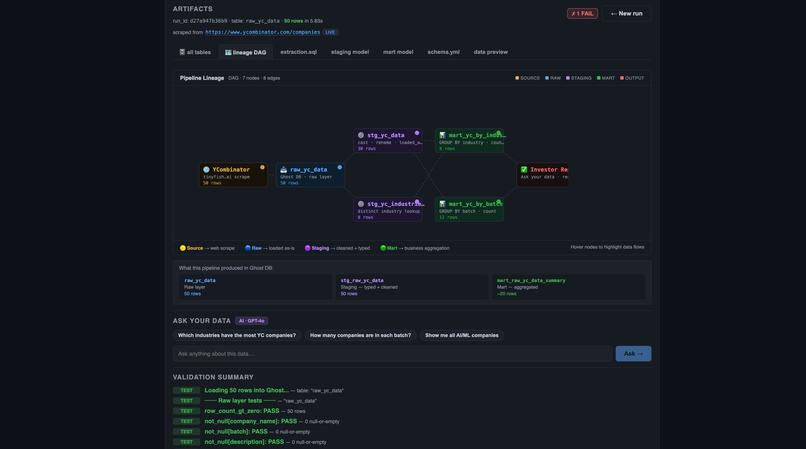
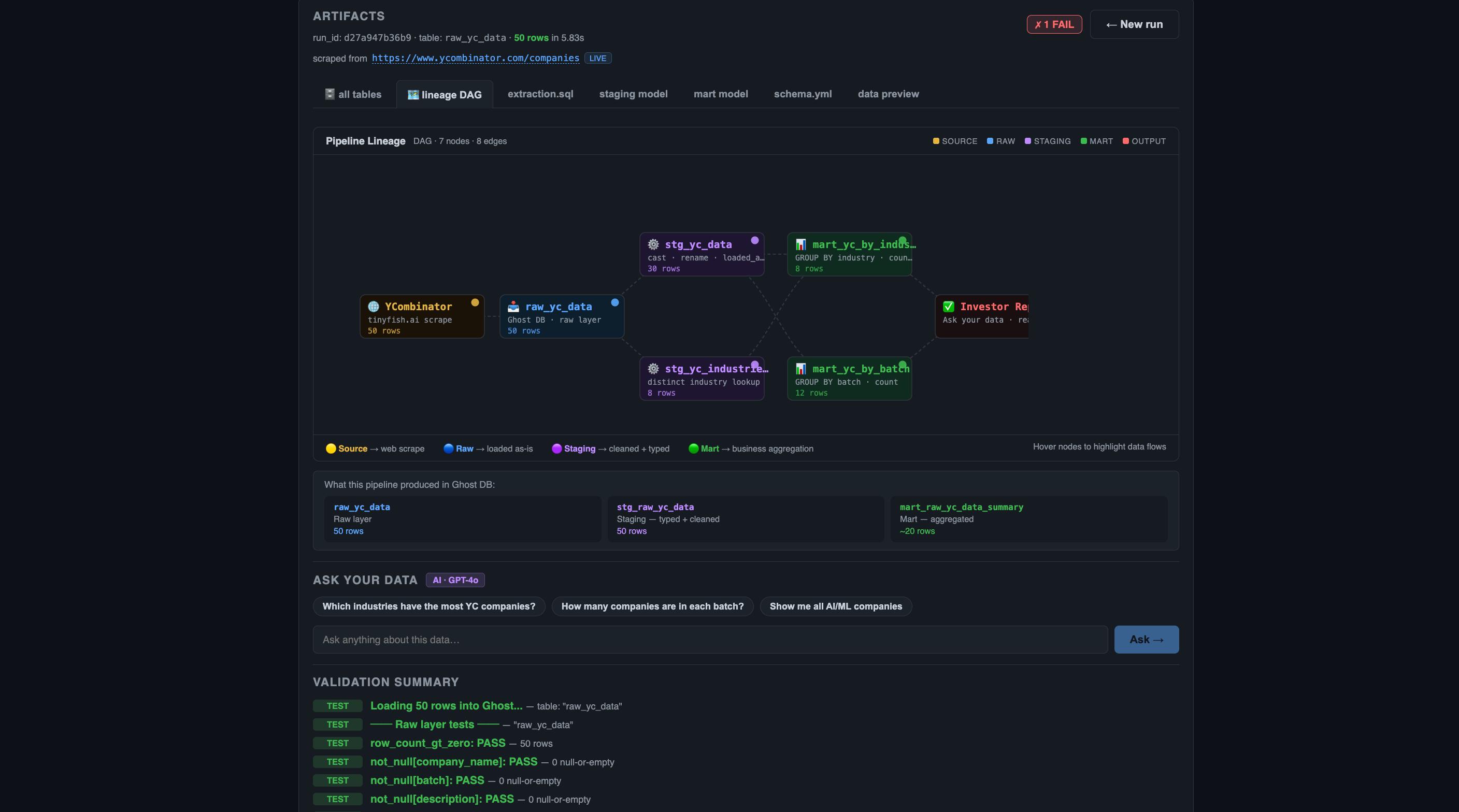
Final output shows data lineage, tables, validation, and query interface.
-
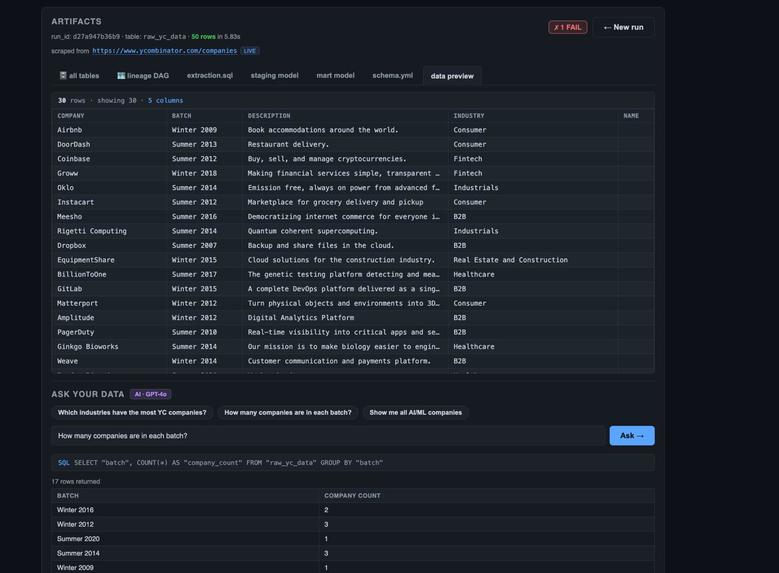
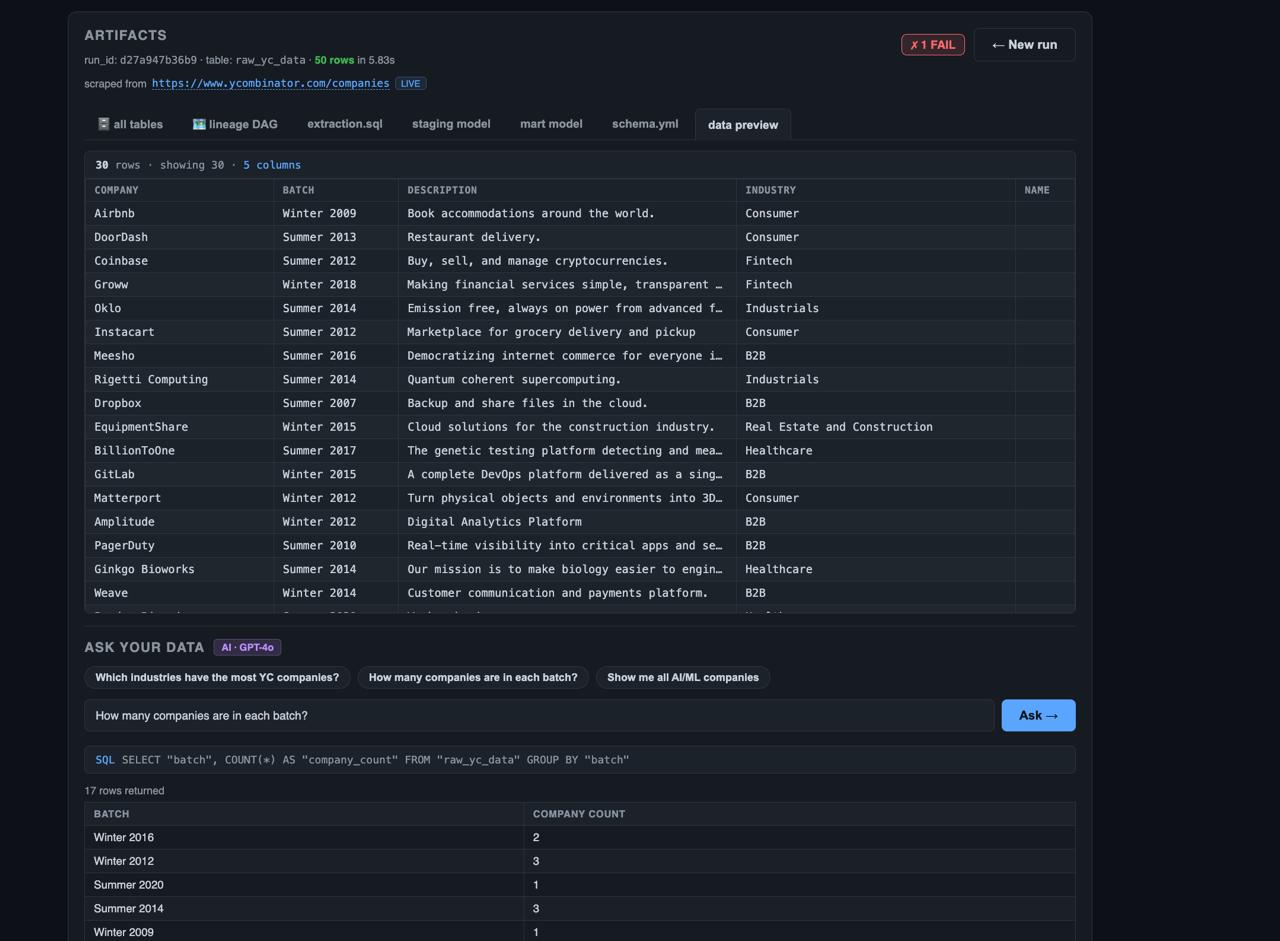
Final data preview and AI query results showing YC companies, batches, and aggregated insights.
Inspiration
Modern data engineering workflows are powerful but often complex, requiring multiple tools for data ingestion, transformation, storage, and analysis. We wanted to explore whether artificial intelligence could simplify this process and make it more accessible.
TinyFish Acts as the data ingestion layer. It is used as an intelligent web scraping agent to fetch structured data from sources like Y Combinator, Hacker News, and Product Hunt in real time.
Ghost Serves as the data warehouse. It is a Postgres-based system where all raw, staging, and mart tables are stored, transformed, and queried.
Redis Used for caching and performance optimization. It helps store intermediate results and speeds up repeated queries and pipeline runs.
The core idea was to enable users to move from a simple question or prompt to a fully functional data pipeline. We are not replacing Data Engineers completely, every time human will be in the loop to review the artifacts and pipeline lineage it follows along with explainability by AI - providing sources it fetched data from and how data will flow through different stages in ETL pipeline and generate report on the fly without requiring individual engineer to adjust for every stakeholders' frequently changing requirements.
OUR MOTIVATION follows the article from Databricks following THE 30% RULE. where we will be replacing 30% of Data Engineering work and giving it to AI to crate early boilerplate pipeline and boosting overall work. Also, it can be extended to business users to use at their disposal and create business reports on the fly without having pre-defined schema.
What it does
Pipeline Copilot is an AI-powered system that transforms a natural language prompt into a complete ETL pipeline.
The system allows users to:
Input a prompt describing the analysis they want to perform Scrape real-world data from sources such as Y Combinator, Hacker News, and Product Hunt Clean and structure the collected data Generate dbt-style transformation logic using AI, including staging models, mart models, and schema tests Load the processed data into a Postgres-based warehouse Validate the pipeline through data quality checks Query the resulting dataset using natural language (text-to-SQL)
In essence, the system converts a prompt into a fully operational data workflow from ingestion to analysis How we built it Frontend
The frontend was built using React with TypeScript and Vite. The user interface is structured into multiple steps:
A prompt input screen A live execution screen displaying pipeline logs An artifacts and results screen with generated SQL, data previews, and query capabilities Backend
The backend was implemented using FastAPI. It handles pipeline execution, API endpoints, and real-time updates via Server-Sent Events (SSE).
AI Integration
We used OpenAI or Groq APIs to power the intelligent components of the system. These models were responsible for:
Generating SQL queries Creating dbt-style transformation models Producing schema definitions and tests Converting natural language queries into SQL Pipeline Architecture
The system is structured as a sequence of modular agents orchestrated using LangGraph:
Scraper: Collects raw data from APIs or web sources Cleaner: Normalizes and cleans the dataset Generator: Uses AI to generate transformation logic and metadata Validator: Loads data into Postgres and verifies correctness Data Layer
Postgres (via Ghost) is used as the data warehouse. Data is inserted, transformed, and queried directly within this system using psycopg2.
Challenges we ran into
One major challenge was handling variability in scraped data. Different sources provided inconsistent schemas, requiring robust cleaning and normalization.
Another difficulty was ensuring the reliability of AI-generated SQL. The outputs were sometimes invalid or incomplete, which required validation steps and fallback mechanisms.
We also encountered issues with live data scraping, such as rate limits and API failures. To address this, we implemented fallback datasets to ensure the system remained functional.
Schema inference was another challenge, as the system needed to automatically identify meaningful columns from raw data.
Finally, coordinating the full pipeline from scraping to validation required careful orchestration to ensure each stage worked correctly and consistently.
Accomplishments that we're proud of
We successfully built a complete end-to-end ETL pipeline powered by AI. The system can generate dbt-style transformation logic automatically and execute it in a real database environment.
We integrated live data scraping with warehouse loading and validation, and we implemented a natural language interface for querying data.
Additionally, we created a user-friendly interface with real-time pipeline logs, making the process transparent and interactive.
What we learned
We learned that while AI can significantly accelerate development, it requires strong validation and fallback strategies to ensure reliability.
We also gained a deeper understanding of the importance of data quality and schema design in building effective pipelines.
Using an orchestration framework like LangGraph simplified the process of coordinating multiple pipeline stages.
Finally, we learned that providing real-time feedback and visibility into the pipeline greatly improves user experience and trust.
What's next for AI for ETL
There are several directions for future improvement.
We plan to integrate scheduling tools such as Airflow or dbt Cloud to enable automated pipeline execution. Expanding support for additional data sources, including file uploads and streaming data, is another priority.
We also aim to enhance schema inference using embeddings and improve data quality monitoring through automated alerts.
Further integration with business intelligence tools like Tableau or Superset would enable richer data visualization.
In the long term, we envision production-ready AI-driven ETL systems with versioning, lineage tracking, and collaborative workflows.
Built With
- ghost
- openai
- redis
- tinyfish

Log in or sign up for Devpost to join the conversation.