-
-
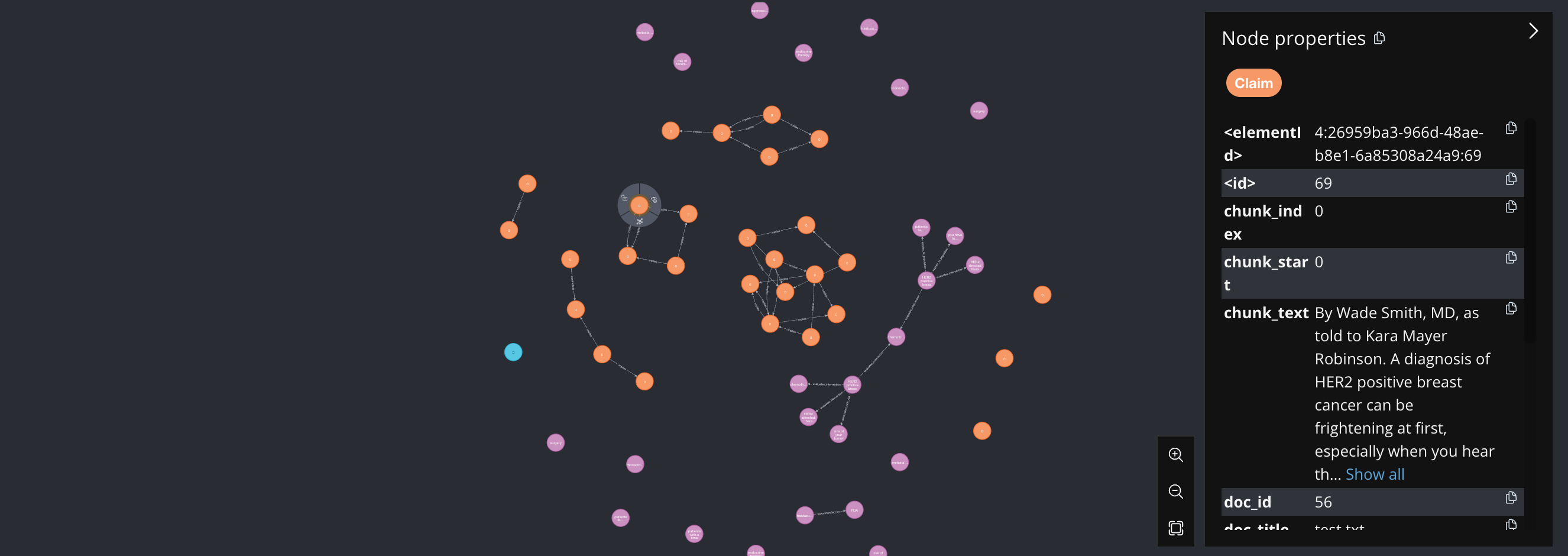
Example of the graph database after supporting materials have been uploaded. As the main document is edited, propositions are cross-checked.
Inspiration
When writing important documents, it's routine nowadays to use language tools such as Grammarly to proactively chase down and fix grammatical and thematic issues in our work. But no tool out there is capable of deep, expert-level analysis of our documents on a factual and logical level. Large language models are certainly capable of dissecting complicated bodies of text in smaller quantities, but zero-shot attempts to derive precise feedback is often limited as your deliverables and reference scale. What if we can employ LLMs to analyze our work in parallel, as we write?
What it does
Our platform serves as a document editor that, in a manner similar to Grammarly, will proactively identify logical discrepancies in your written work as you produce them. Users can first upload a corpus of supporting resources such as lecture notes, research articles, or any text-based resources of direct relevance to their writing. We'll extract the semantic relationships across your resources and merge them into a global knowledge graph - your deliverables are then scanned and systematically compared to validate the key assumptions and claims made in your current work.
How we built it
We created a GraphRAG-like pipeline to ingest documents based on information about the project, the user's deliverables, and domain-specific knowledge. The resource graph is accumulated by incrementally ingesting new resources and merging them into the global graph.
In parallel, we parse your main document as you edit within it to extract the key claims being made. When your main document is scanned, these claims are then cross-referenced with the information extracted from the global graph in order to corroborate or contradict them. The built-in text editor will then refer you to any contradictions and notable results from the comparison.
Challenges we ran into
Given the time constraints, we could not leverage vector embedding models or semantic search (i.e. vanilla RAG) as we would have hoped in our overall pipeline. Furthermore, a majority of our graph creation, processing, and revisions are made using granular LLM API calls which each performs a small, isolated task. Unfortunately due to rate limits, we had to constrain how parallel we could make our editor given our subscription tier.
Accomplishments that we're proud of
We're really happy that from a semblance of an idea this morning, we were able to fully implement an end-to-end, albiet simplified, version of our overall vision of the project. Given the amount of orchestration of graph objects and JSON inputs/outputs, we were satisfied to reach a working version with so much functionality already. In addition, our team has a clear idea of where to progress on this project from here.
What we learned
Given that we had never implemented an application with such heavy LLM use, we learned how to orchestrate API calls and use the Claude API features such as structured outputs and XML-formatted prompts. We also learned how to use and deploy graph databases for the first time, using the intermediate outputs processed by Claude.
What's next for Logical.ly
In addition to being able to upload supplementary resources from the user's files, we also want to extend a feature where users can leverage web search, sending multiple agents to scour the internet via Claude API to find online resources to eventually merge into the resource graph, further increasing the breadth of our fact-checking. As mentioned in the challenges, we'd also like to add a vector embedding model which can help us employ RAG at scale within the graph operations of our databases.


Log in or sign up for Devpost to join the conversation.