-
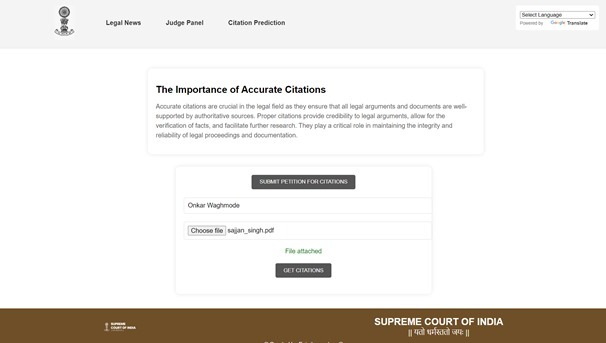
Upload Petition File page
-
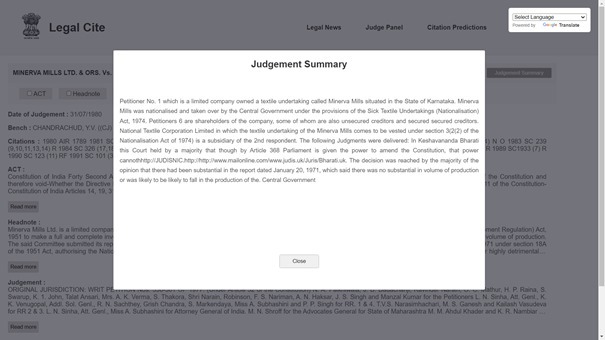
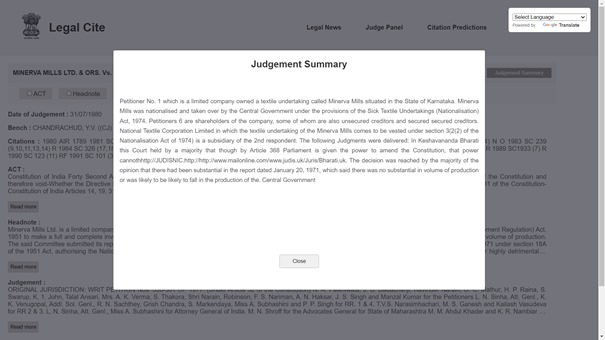
Output Judgement Citation Summary
-
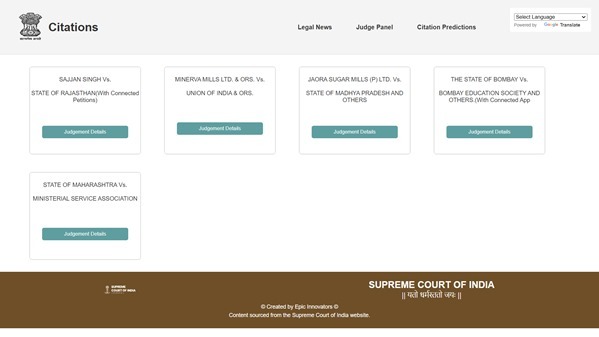
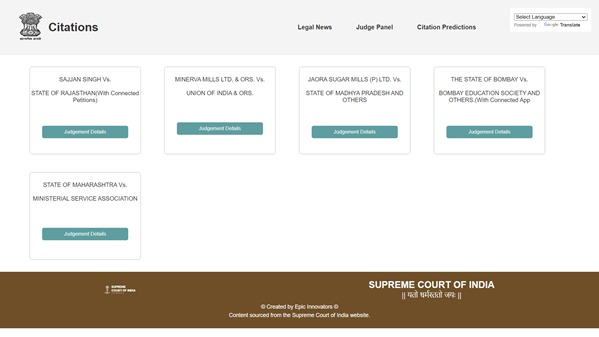
Result/Output main page: Relevant citations for uploaded petition file
AI-Driven Judicial Assistance System
Inspiration
The inspiration for this project stemmed from the inefficiencies and challenges in legal research, particularly the time-consuming process of finding relevant legal precedents and citations. Lawyers and judges often have to sift through volumes of case law to locate judgments that support their arguments, which can lead to delays in delivering justice. We wanted to leverage the power of Artificial Intelligence to streamline this process, reduce human effort, and ensure precise recommendations for legal professionals.
What it does
The AI-Driven Judicial Assistance System processes petition files submitted by users and recommends the most relevant cited judgments. The system ranks the judgments based on their relevance and provides concise summaries to explain why a specific judgment is pertinent to the user's case. Additionally, it highlights how legal professionals can use these recommendations effectively in their arguments and explains the reasoning behind the court's reliance on the cited judgments.
How we built it
The project was built using a combination of machine learning, natural language processing (NLP), and web technologies. Key components include:
-Frontend: Built with React for an interactive user interface. -Backend: Developed using Flask to handle data processing and API integration. -NLP Models: Leveraged BERT for semantic analysis and ranking of judgments. -Libraries and Tools: Used libraries like NLTK for tokenization and PyPDF for extracting text from petition files. -Data: Historical judgments, legal documents, and case law data were preprocessed for training the system.
Challenges we ran into
-Data Availability: Collecting and preprocessing high-quality, annotated legal datasets was a significant challenge. -Model Optimization: Fine-tuning the BERT model for legal-specific use cases required extensive experimentation and resources. -Explaining Recommendations: Developing a system that not only recommends judgments but also provides meaningful and human-readable explanations was technically demanding. -Integration: Ensuring seamless interaction between the frontend, backend, and ML models was a complex task.
Accomplishments that we're proud of
-Successfully implementing a robust citation recommendation engine that ranks judgments based on relevance. -Building an intuitive user interface that simplifies the legal research process. -Achieving precise and meaningful summaries of judgments, making the system highly user-friendly for legal professionals. -Overcoming challenges in preprocessing large-scale legal data and integrating ML models effectively.
What we learned
-A deep understanding of legal domain challenges and how AI can address them. -The importance of clean data preprocessing for building efficient ML models. -Advanced use of NLP techniques, particularly BERT, for semantic understanding in niche domains like law. -The significance of designing systems that not only provide results but also explain their reasoning to end-users.
What's next for AI-Driven Judicial Assistance System
-Broader Dataset Integration: Expanding the dataset to include judgments from more jurisdictions for a global perspective. -Argument Generation: Enhancing the system to generate draft arguments based on the recommended citations. -Real-Time Assistance: Integrating real-time capabilities for lawyers to use the system in courtrooms. -User Feedback Integration: Incorporating user feedback to continuously refine the recommendation engine.


Log in or sign up for Devpost to join the conversation.