-
-

AI Desktop Agent
-

Category of Project
-

Key Features
-

why choose it
-
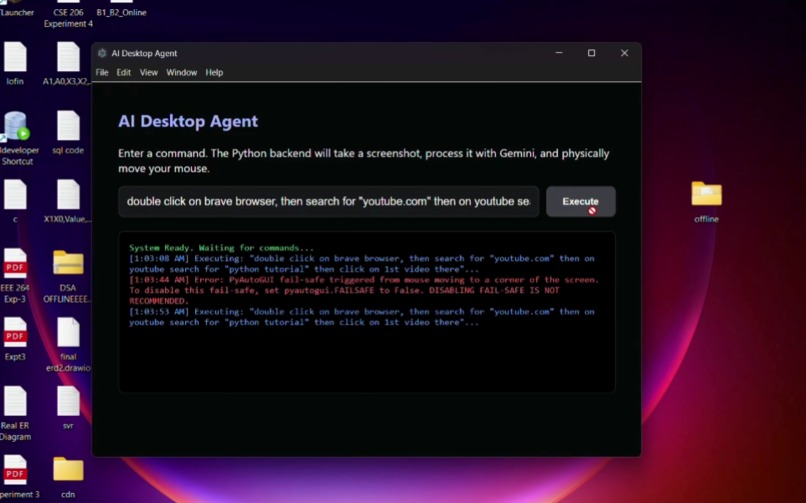
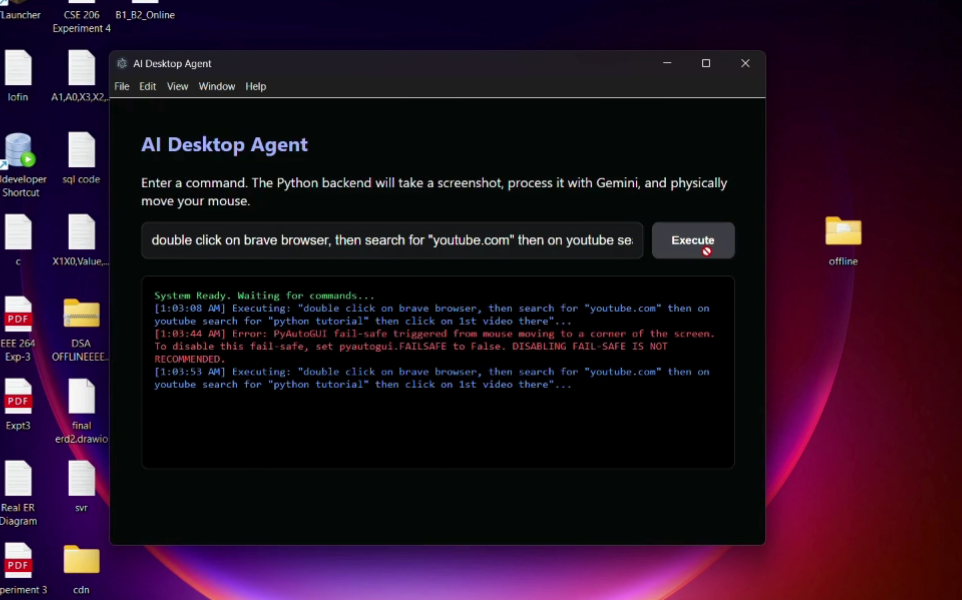
our agent in action
-
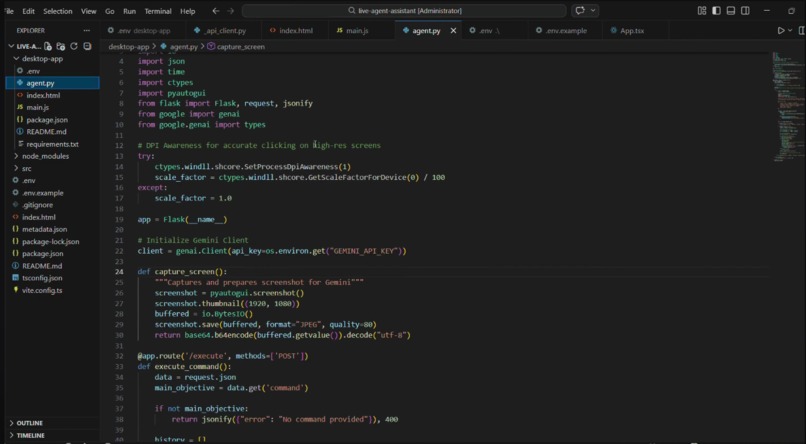
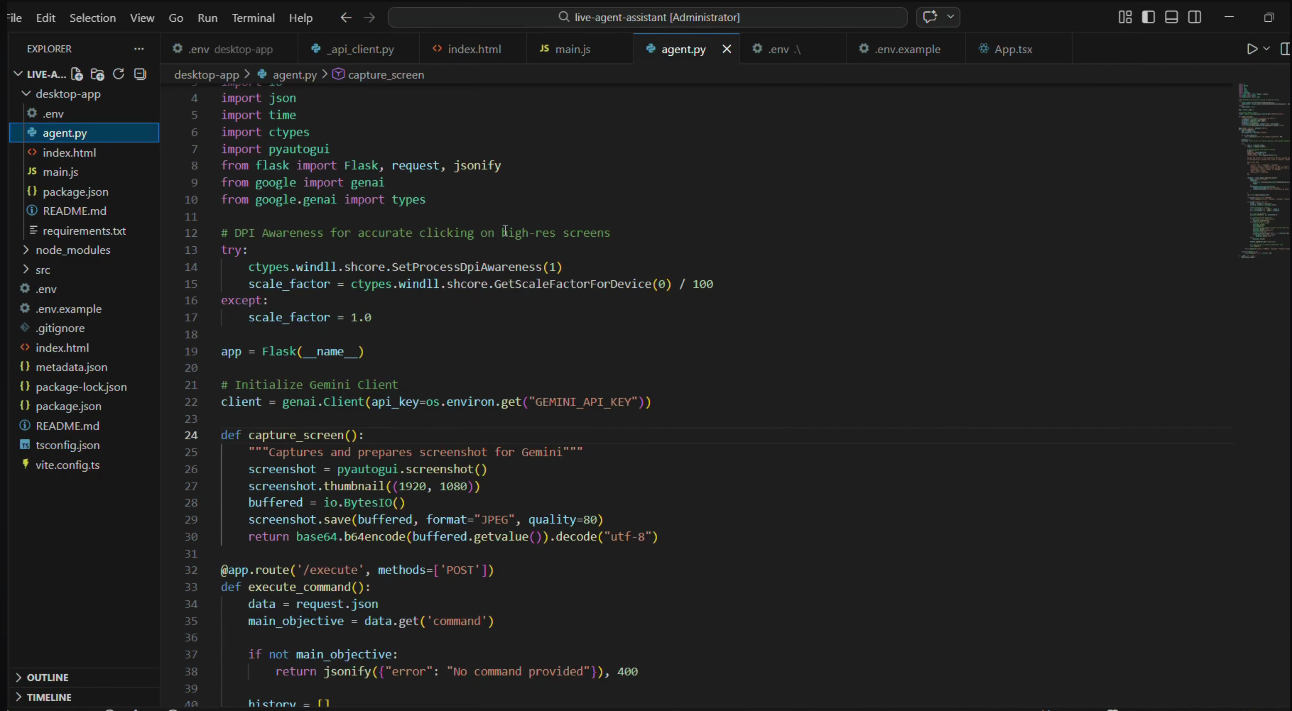
Works Behind
-

Team behind





Inspiration:
Every day we interact with computers by clicking, searching, opening tabs, and navigating interfaces. These small actions feel simple, but they consume a surprising amount of time and attention. We began asking a simple question: what if a computer could understand its own interface and perform these actions for us? With the emergence of multimodal AI like Gemini and the capabilities provided by Google Cloud, we saw an opportunity to explore that idea. Instead of building another chatbot, we wanted to build something that could actually operate a computer, the way a human would.
What it does:
AI Desktop Agent is an autonomous system that can understand what is happening on a computer screen and perform tasks based on natural language instructions. The agent observes the screen, interprets the interface using Gemini’s multimodal reasoning, and decides the next action needed to move closer to the user’s goal. It can navigate applications, click buttons, search information, and interact with real interfaces. Even when unexpected interruptions appear—like notifications or pop-ups—the agent evaluates the situation and decides how to resolve it before continuing the task.
How we built it:
We built the project around a simple but powerful loop: observe, reason, and act. The system captures screenshots of the current screen and sends them to Gemini running on Google Cloud. Gemini analyzes the visual context and returns reasoning about what action should happen next. A Python backend then executes that action on the computer through automation, allowing the agent to interact with the system just like a user would. This cycle repeats continuously, enabling the agent to gradually move toward completing the objective.
Challenges we ran into:
One of the hardest parts was teaching the system to make reliable decisions from visual information. Real computer interfaces are unpredictable—notifications appear, layouts change, and unexpected windows interrupt the flow. Making the agent handle these situations required experimenting with reasoning prompts, refining the action loop, and designing a system that could adapt when things didn’t go exactly as expected.
Accomplishments that we're proud of:
What makes this project special to us is that it goes beyond generating text. The agent doesn’t just talk about completing a task—it actually does it. Watching the system observe the screen, reason about what it sees, and interact with the computer autonomously was an exciting moment for us. Building a working perception–reasoning–action loop felt like taking a small step toward a future where computers collaborate with us instead of waiting for instructions.
What we learned:
This project taught us that building AI systems is not only about models, but about how those models interact with the real world. Combining Gemini’s reasoning abilities with automation and system design showed us how powerful multimodal AI can become when it moves beyond text and begins interacting with real environments.
What's next for AI Desktop Agent:
This is just the beginning.We want to expand the agent so it can handle more complex workflows, support voice instructions, and navigate across multiple applications seamlessly. Our vision is to evolve AI Desktop Agent into a true digital partner—one that can understand our intentions and help us accomplish tasks more naturally and efficiently.



Log in or sign up for Devpost to join the conversation.