-
-

UI
-
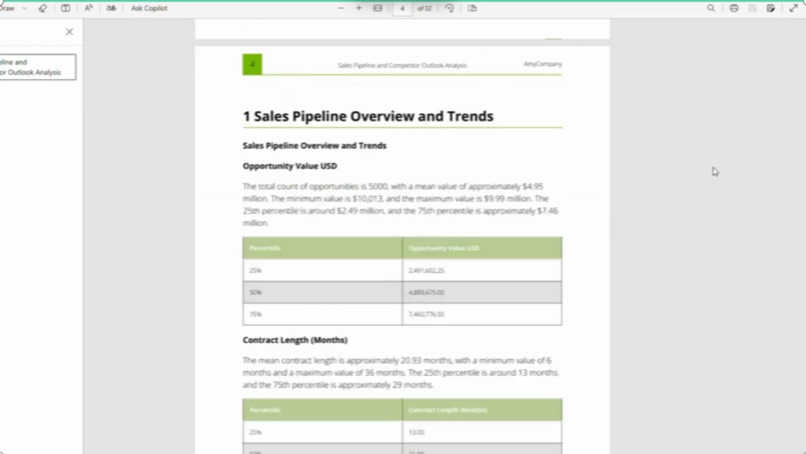
Custom PDF Report
-
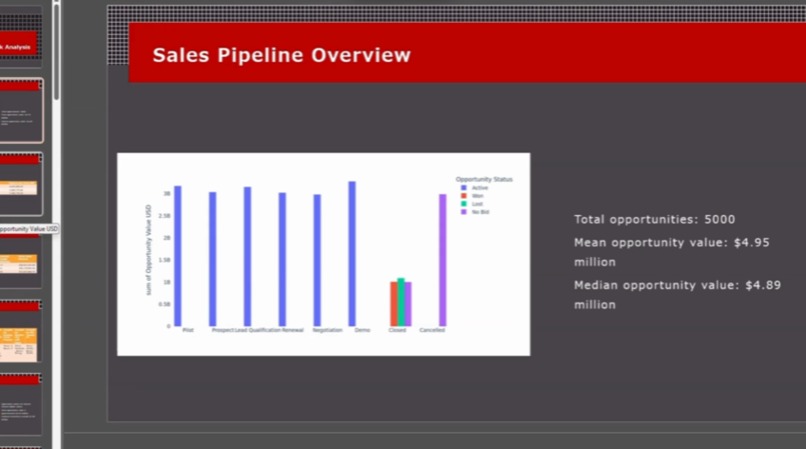
Custom Presentation
-
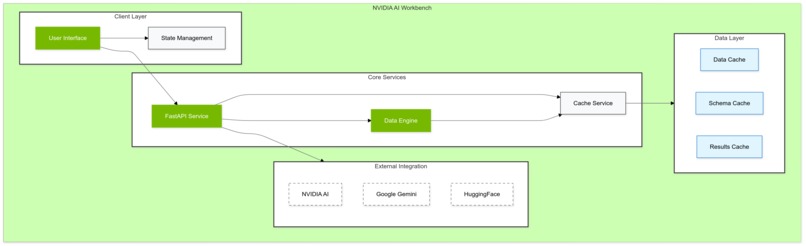
Main Flow
-
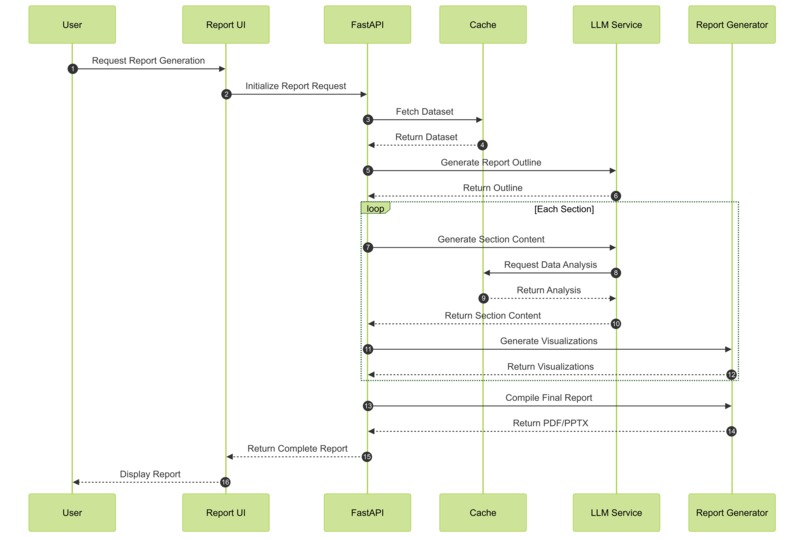
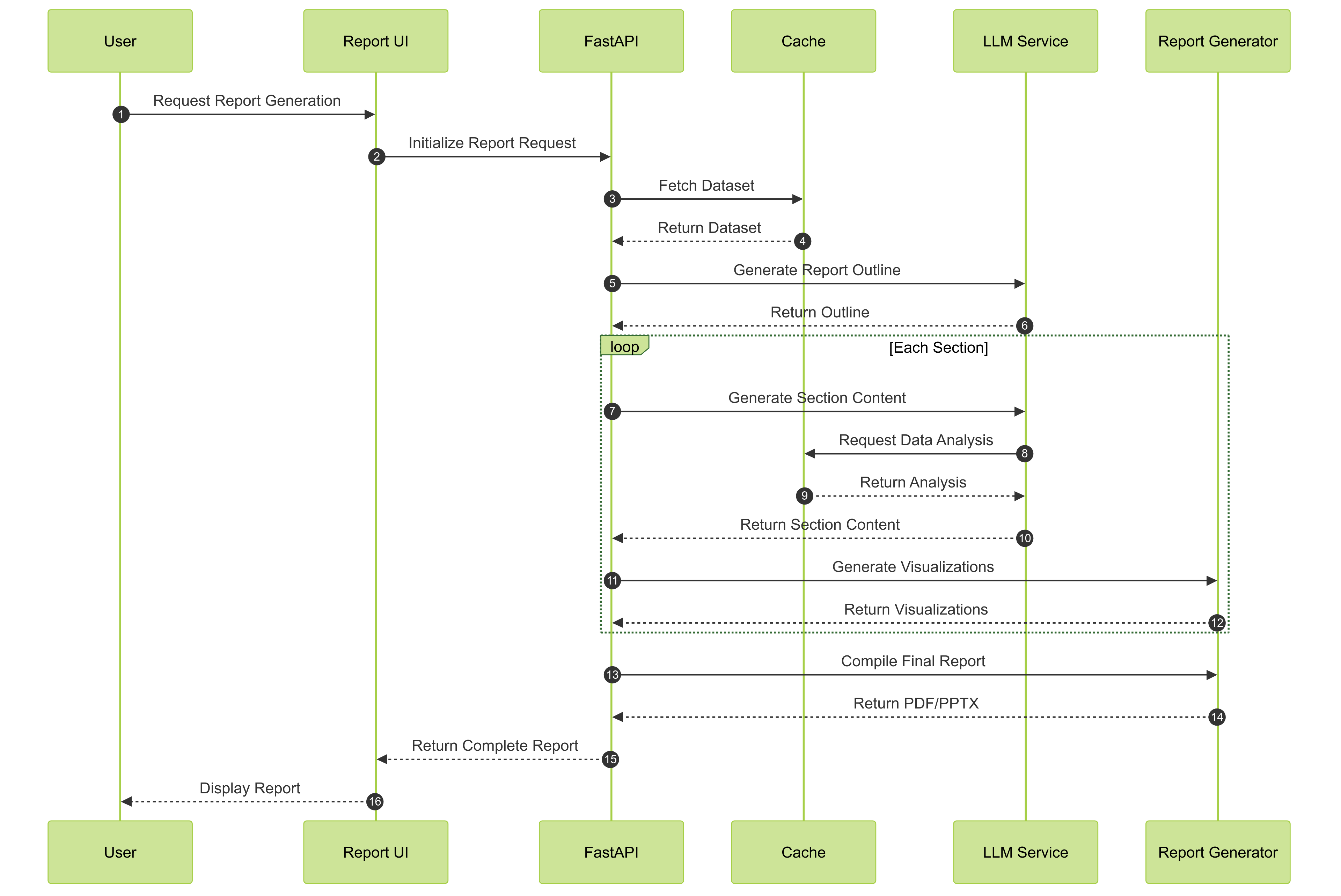
Report Generation
-
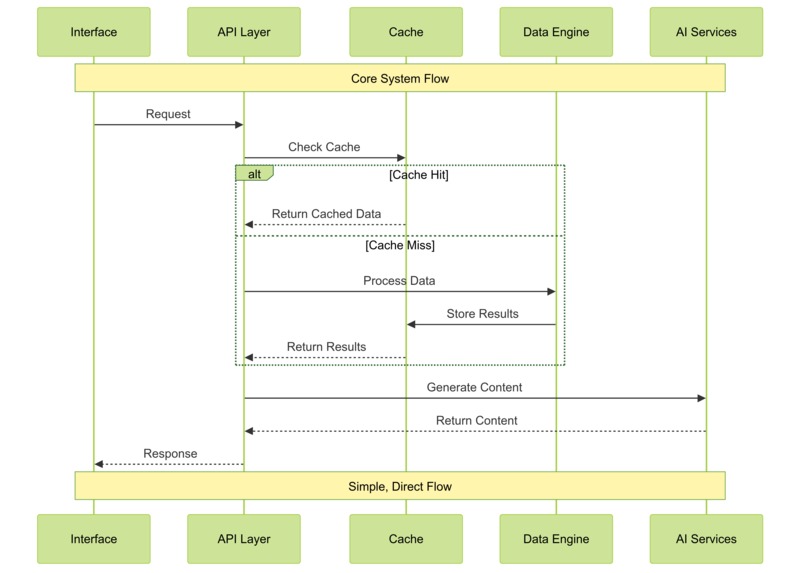
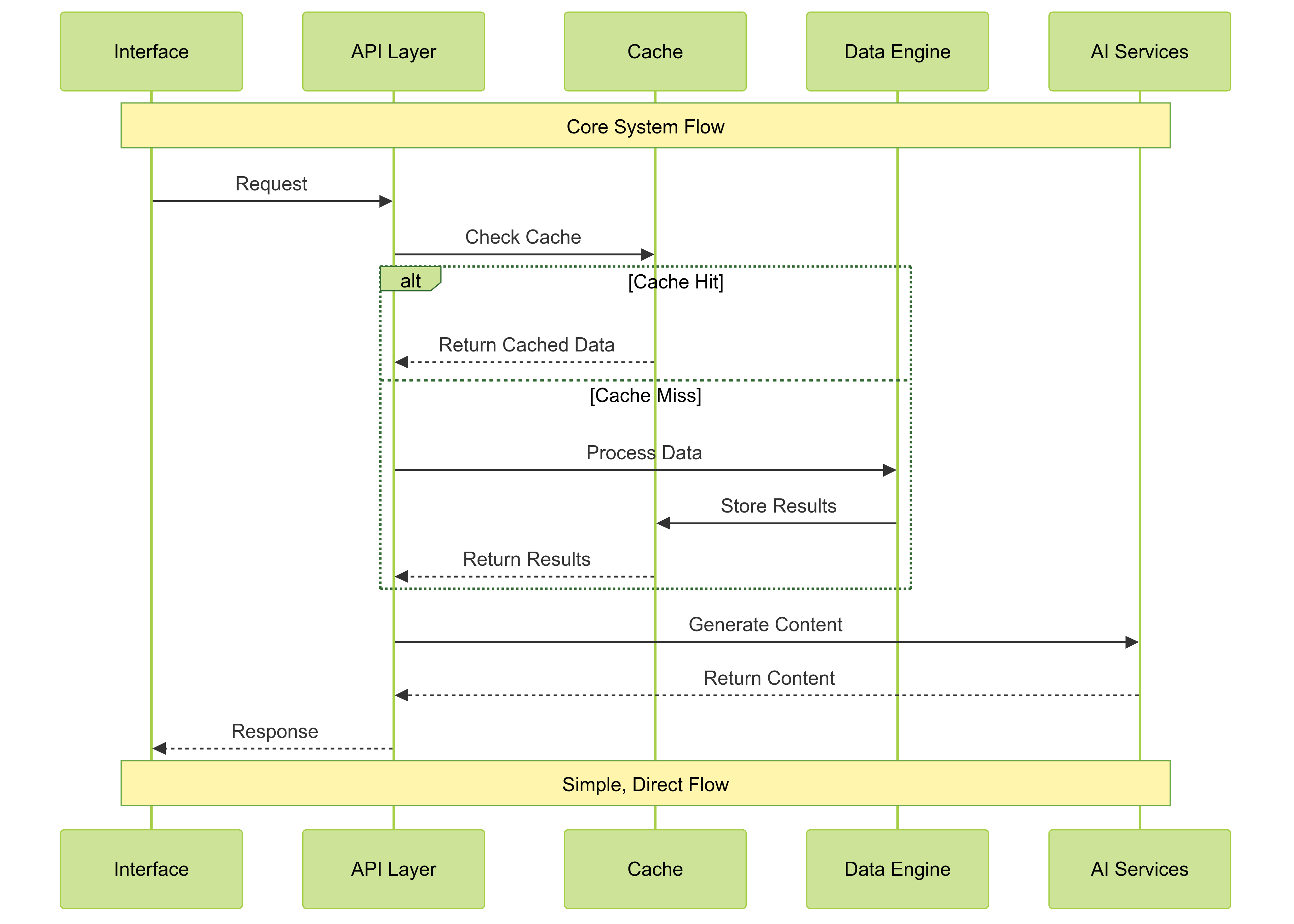
Component Interactions
-

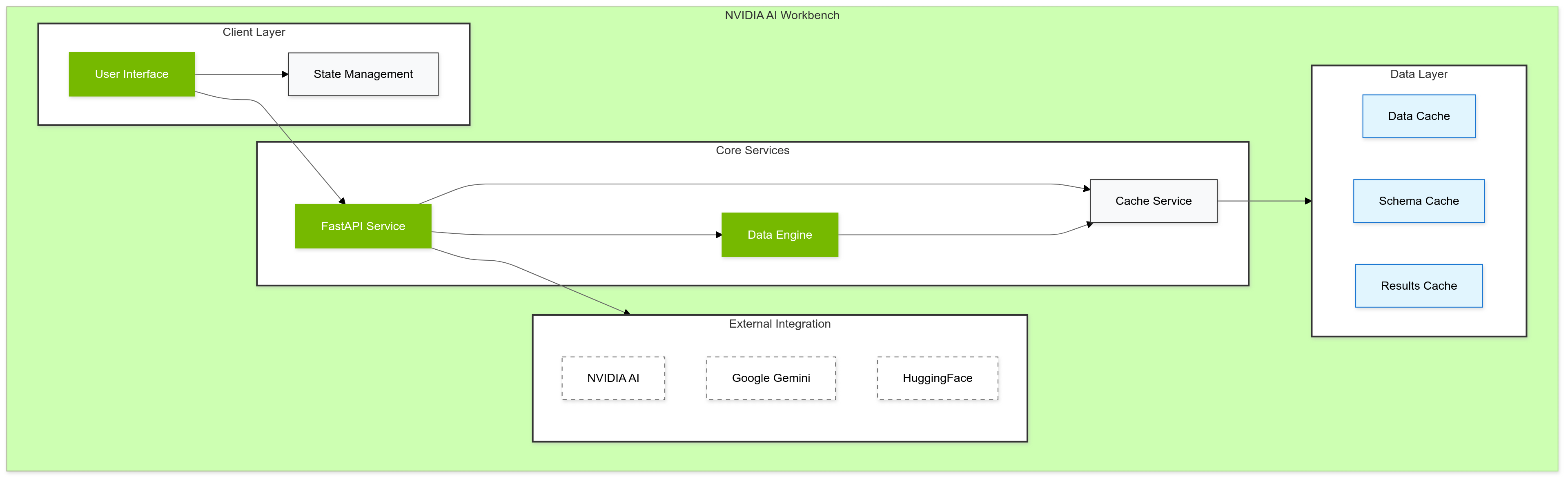
Data Flow

Inspiration
I was inspired by an idea I had in the past, but wasn't able to implement correctly due to speed and size limitations with data analysis. When I saw the RAPIDS suite and understood how cuDF would allow me to take advantage of GPU acceleration, I knew I would be able to do everything I wanted with this project.
What it does
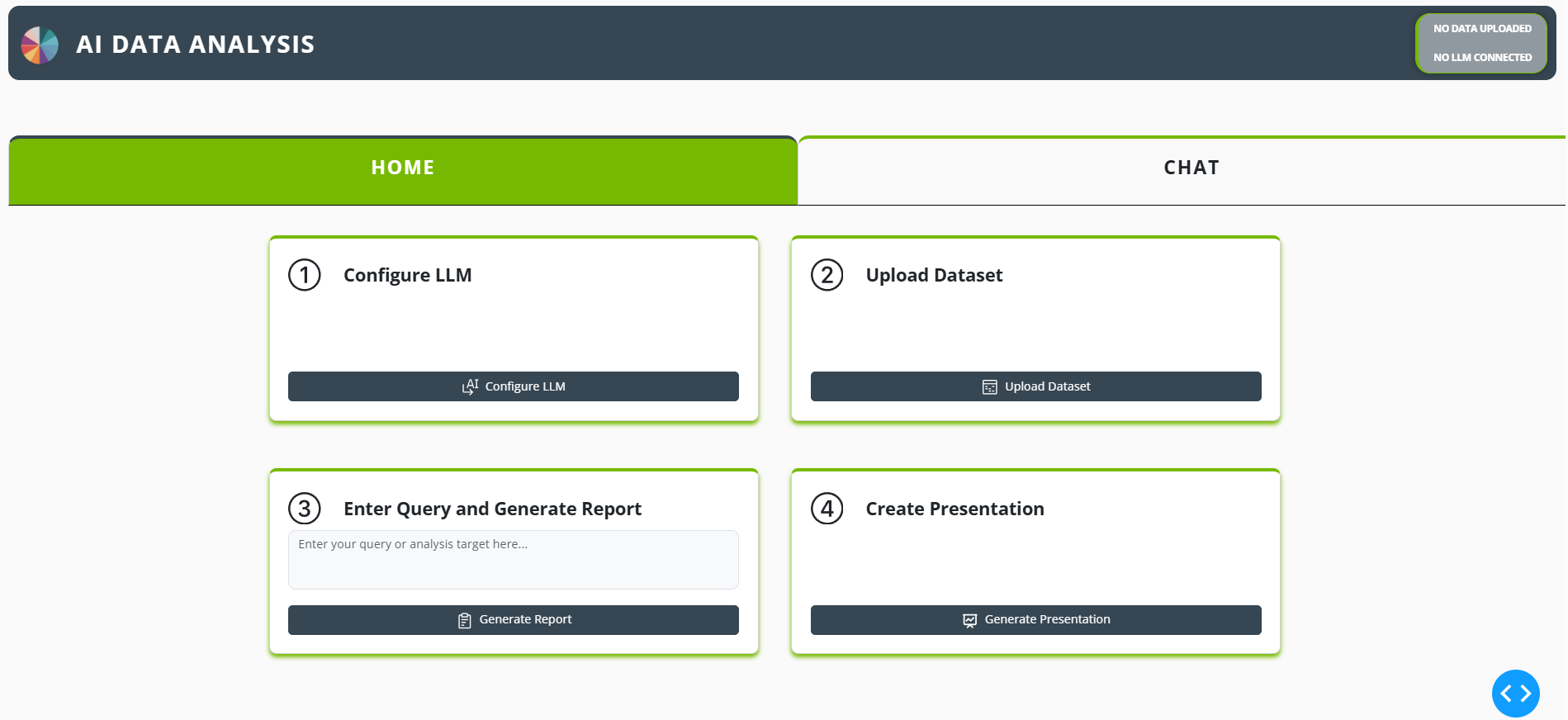
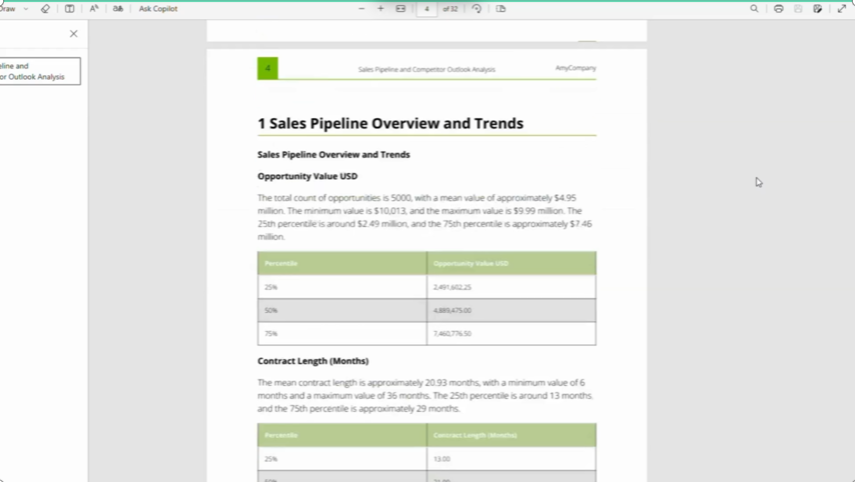
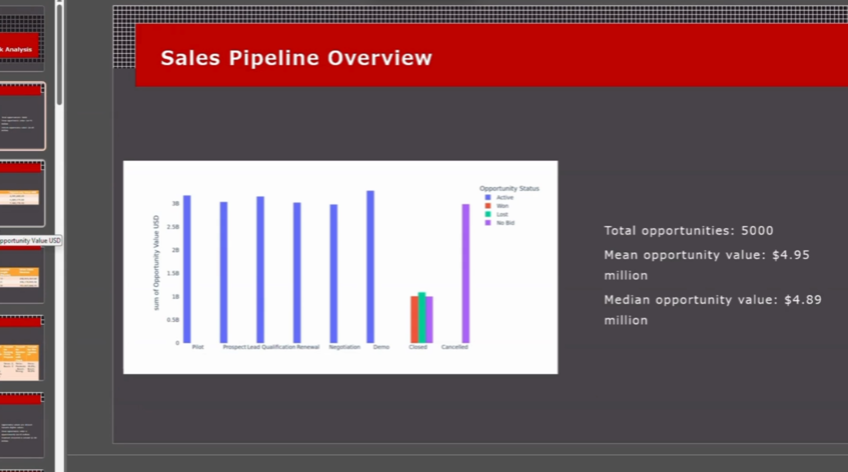
A user can upload a dataset in CSV, JSON, or Parquet format and request an analysis from an LLM (users can also choose the LLM Provider and LLM to use). The query the user gives guides the LLM through the use of a custom Data API with caching to further speed up analysis. Using the custom Data API, the LLM executes actions using cuDF dataframes to return quick results, and then finally collates the results into a coherent, actionable report that is often 20+ pages and ready for delivery. Additionally, a custom slide presentation can be created, which again uses the LLM with cuDF dataframes and the Data API to create slides with summarized data, tables, and plot visualizations. The LLM also has the option to perform cuML linear regression and output the results as a plot.
Finally, users can take advantage of a chat feature to continue exploring their data in depth.
How we built it
I chose the RAPIDS NVIDIA AI Workbench image to begin, then worked through several UI options before settling on Dash, so I could take full advantage of cuDF and visualizations.
The code is in Python, but the PDF is styled via CSS, which gave me flexibility in allowing users to upload logos and add custom company names, as well as customize the sections for the report.
Challenges we ran into
Initially, I felt I wasn't able to allow the LLM enough access to the data without hitting token limits, and reports weren't giving me the results I was looking for with limited data access. That's when I decided to create the Data API to allow execution of functions against the cuDF dataframes, so that the LLM could make decisions about what data it needed to look at and when. This removed the limitations I had with data and brought everything together.
Accomplishments that we're proud of
I'm extremely proud of the data caching and fuzzy matching I implemented. Data caching limits the overhead when the LLM needs to get a lot of information from the dataframes, and the fuzzy matching has greatly improved the results since often, depending on the LLM, even with strict prompts and data samples, column names were being returned incorrectly. The fuzzy matching ensures that the code can infer the correct column and produce the needed results.
What we learned
I learned so much using the RAPIDS suite. I hadn't been aware of it before this, but I know I'll be taking advantage of it in the future, especially the full integration with pandas and polars.
What's next for AI Data Analysis with RAPIDS
I rarely feel like any project is finished, so I'll likely continue to improve on prompts and the API in the future.


Log in or sign up for Devpost to join the conversation.