Inspiration
Prototyping ML models often stalled because real-world datasets were too small, sensitive, or expensive to collect. I wanted a lightweight tool that could instantly fill those gaps—no custom model training required—so I turned to powerful LLMs to synthesize tabular data on demand.
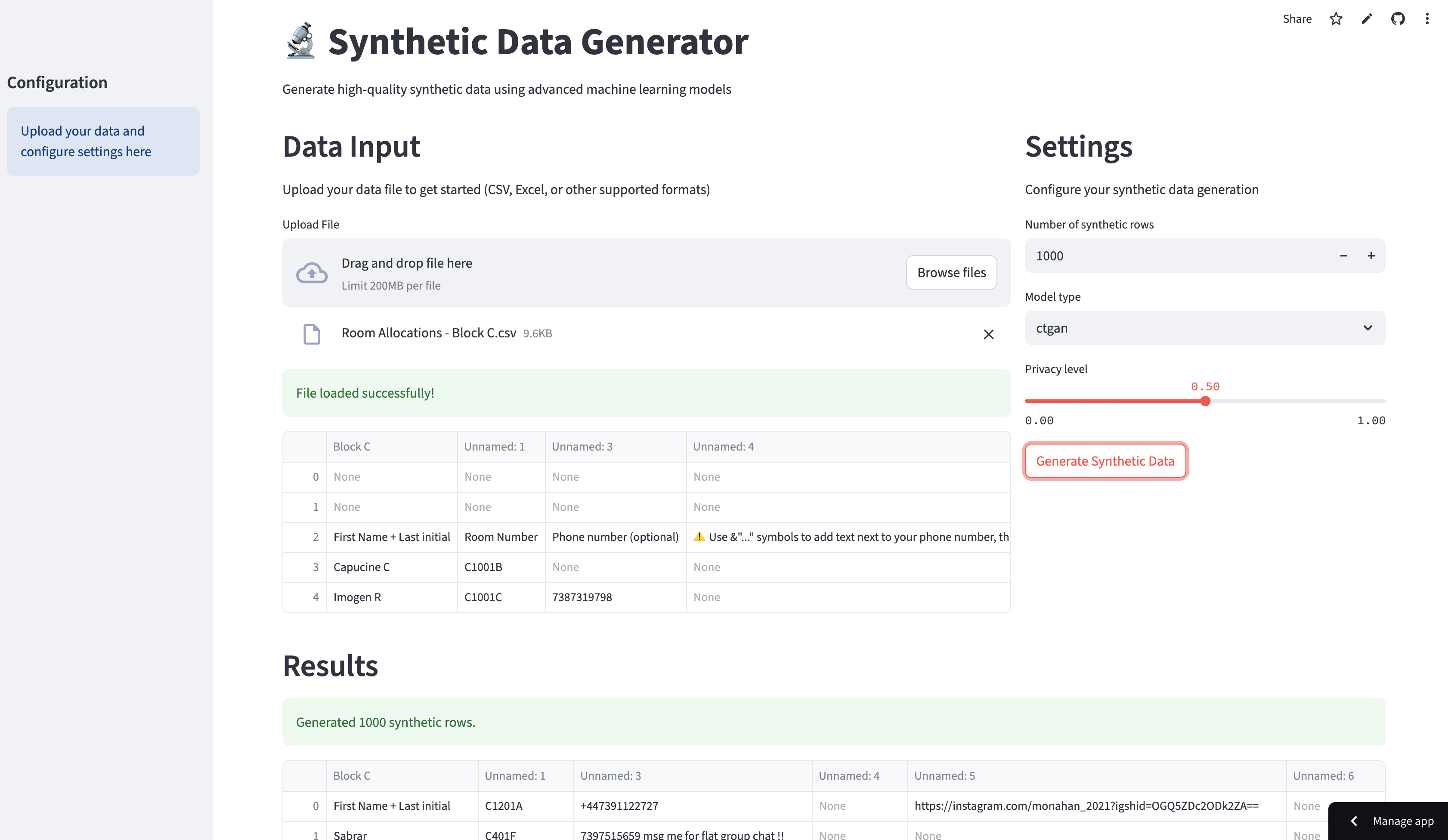
What it does
DataForge Lite lets you upload a CSV or define a set of column names and types, specify how many rows you need, and then generates a schema-respecting synthetic dataset in seconds. You can preview the results in-browser and download a ready-to-use CSV to jump-start your model training.
How we built it
- Prompt Engine: Wrote a Python function
generate_synthetic(schema, n_rows)that crafts a clear JSON-focused prompt describing each column’s type, value ranges, and format. - LLM Integration: Used Boto3 to call Amazon Bedrock’s Claude 3 model, streaming the JSON array response back to our app.
- Streamlit Frontend: Built a simple UI with file uploader and text inputs for schema definition and row count. Wired a “Generate” button to invoke the prompt function and display results as a pandas DataFrame.
- CSV Download: Parsed the LLM’s JSON into a DataFrame and provided a one-click “Download CSV” link so users can immediately plug the synthetic data into their workflows.
- AWS Setup: Created a least-privilege IAM role for Bedrock access and configured secure Boto3 credentials within the app.
Challenges we ran into
- LLM Output Variability: Occasionally received malformed JSON; solved by adding a retry-and-cleanup layer that fixes common syntax issues.
- Schema Validation: Ensuring users supplied valid types (
int,float,string,date) and handling unexpected nulls required building front-end checks and backend sanitizers. - Performance vs. Cost: Large schemas led to high token usage. We mitigated this by chunking prompts, caching repeated calls during development, and tuning prompt verbosity.
- UI Responsiveness: Streaming the LLM call without freezing Streamlit necessitated using asynchronous threads and progress spinners to keep users informed.
Accomplishments that we're proud of
- End-to-End MVP in 24 Hours: Delivered a fully functional synthetic data generator—from file upload to CSV download—within a single hackathon day.
- Seamless AWS Integration: Seamlessly wired up Streamlit to Amazon Bedrock with secure, least-privilege IAM roles.
- Robust Error Handling: Built resilient layers to detect and correct LLM JSON errors, ensuring consistent output quality.
- User-Friendly UI: Crafted an intuitive interface with progress indicators and instant previews so anyone can generate data without writing code.
What we learned
- Prompt Engineering Techniques for structured JSON output, including few-shot examples and explicit constraints.
- Working with Amazon Bedrock via Boto3, managing streaming responses and authentication.
- Streamlit Best Practices for file uploads, asynchronous workflows, and dynamic DataFrame rendering.
- Balancing Fidelity and Cost by optimizing prompt size, caching, and early validation to reduce unnecessary API calls.


Log in or sign up for Devpost to join the conversation.