-
-
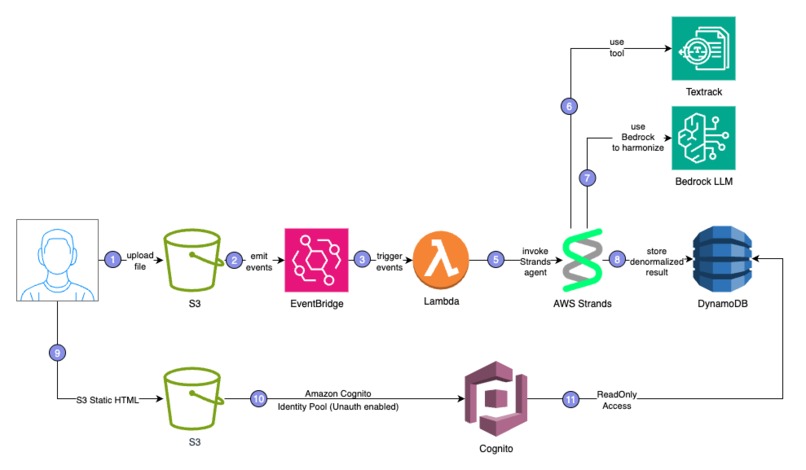
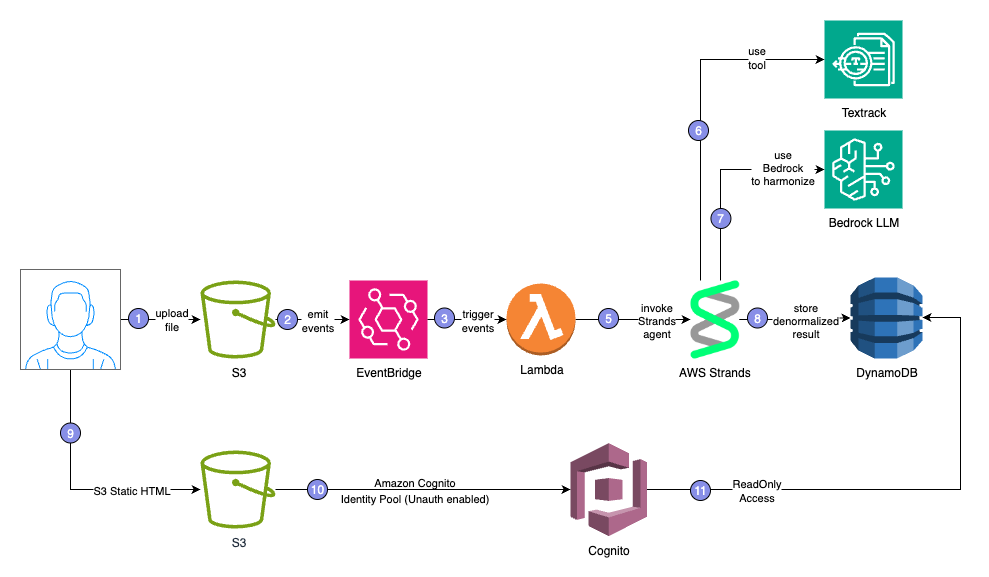
architecture
Inspiration
As a Senior Cloud Architect at IBM, my goal was to gain hands-on experience with AWS Kiro and AWS Strands — two emerging technologies redefining how we build intelligent autonomous systems. I wanted to go beyond static AI models and create an agent that can perceive, reason, and act on its own. The idea came from a simple, real-world problem: businesses and individuals still spend countless hours manually processing invoices and receipts. I wanted to automate that — but not just with OCR. I wanted an agent that could read, understand, and normalize documents intelligently.
⸻
What it does
AutoDoc.AI is an autonomous document intelligence agent that converts raw receipt images into structured JSON data using AWS Strands, Kiro, and Amazon Bedrock. It acts as a mini “autonomous accountant” — uploading an image triggers an end-to-end pipeline that reads, interprets, and stores receipt data, ready for downstream analysis or integration with financial systems.
⸻
How I built it
The solution was built as a serverless AI-native architecture entirely on AWS. • Amazon S3 hosts the uploaded receipts and a static front-end web app. • Amazon EventBridge triggers the pipeline upon each upload. • AWS Lambda orchestrates the process, spinning up a Strands Agent powered by AWS Kiro. • The agent uses Amazon Textract for OCR extraction and Amazon Bedrock (Titan) for reasoning and normalization. • Results are stored in Amazon DynamoDB, where a lightweight web app fetches and displays them.
Throughout development, I iteratively evolved the design — initially relying on two separate tools (OCR + normalization), and later merging them into a single reasoning-driven agent that can handle both vision and text processing more naturally.
⸻
Challenges we ran into
Building with new AWS technologies like Strands and Kiro came with its fair share of surprises: • Access and IAM policies for Bedrock models were tricky to align with Lambda roles. • The agent orchestration sometimes retried tools in unexpected ways, requiring deep debugging to understand reasoning flows. • CloudWatch visibility was initially limited — adding granular, structured logs was critical for tracing how the agent thought through each document. • Normalization turned out to be harder than OCR — Titan often returned text explanations instead of pure JSON, leading to multiple iterations on prompt design.
Each issue, however, provided valuable insights into how AI agents reason and interact with AWS-native tools.
⸻
Accomplishments I'm proud of
• Built a fully autonomous document-processing pipeline — no manual intervention required.
• Successfully integrated AWS Strands and Bedrock in one working agent using AWS Kiro
• Designed a scalable and event-driven serverless architecture for AI reasoning workflows.
• Created a clean web interface for visualizing structured data from real receipts.
• Learned how to debug agent reasoning — not just code — by instrumenting its thought process.
⸻
What I learned
This project reshaped how I think about AI systems. It’s not just about deploying a model — it’s about designing a system that can use models as tools. AWS Strands and Kiro bring that to life, enabling architectures where agents can autonomously chain together reasoning, perception, and action. The process taught me to treat AI agents as distributed microservices of thought — components that plan, call APIs, and reason under orchestration.
⸻
What’s next
• Extend AutoDoc.AI to handle multi-page invoices and PDFs.
• Add AWS Q or SageMaker AI for contextual reasoning and anomaly detection.
• Introduce multi-agent collaboration, where one agent handles OCR and another validates financial data.
• Open-source the project and publish a step-by-step tutorial on building autonomous agents with Strands and Bedrock.
Built With
- amazon-dynamodb
- amazon-web-services
- bedrock
- cloudformation
- cognito
- eventbridge
- kiro
- lambda
- s3
- strands
- textract

Log in or sign up for Devpost to join the conversation.