-
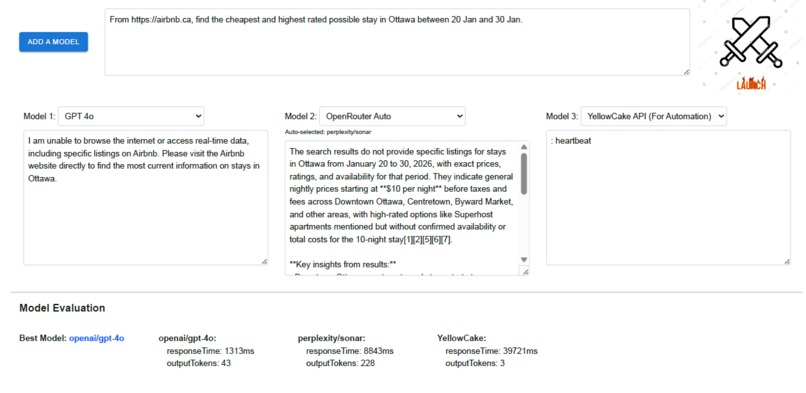
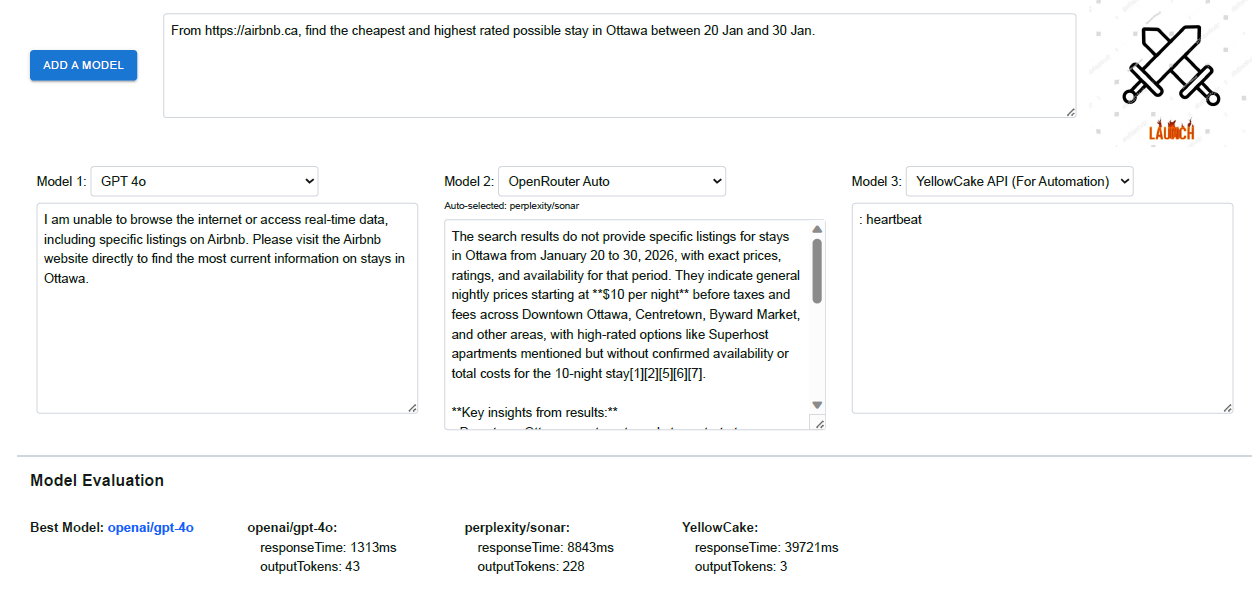
UI Preview
Inspiration
AI becomes indispensable in our lives, from our academic journey or profession settings to grocery suggestions. Yet, people might be overwhelmed by a multitude of Large Language Model (LLM) choices. AI Battleship ⚔️ aims to consult with the best choice of model given the user's need, and to encourage comparisons of responses, by the user, as well as our well-defined formula.
What it does
AI Battleship ⚔️ launches the same prompt for the user onto different models and compare with 2 core metrics - the response time and number of output tokens. We believe that, a good response must respond faster with as concise and less words (i.e., tokens) as possible. Thus, it visualizes the metrics and recommends one with minimal time and tokens.
How we built it
The frontend interface is built with TypeScript with Next framework. It is a one-paged site that consists of 3 sections - a prompting area at the top, followed by an extendable region supporting an arbitrary number of model output boxes at the middle, and the best model recommendation with evaluation metrics at the bottom of the page.
The backend provides an API endpoint for models comparison. It supports a wide range of models, including commonly kown GPT models from OpenAI, Claude models from Anthropic, and etc. Most of them are accessible via OpenRouter's API access. Their API also provides "Auto" choice of model, which allows the platform to automatically choose the best model for the user's prompt. The actual model that OpenRouter picked will also be displayed and evaluated. This brings convenience to the user's experience of comparing random models on his question. Our app specifically features a direct API access to Google Gemini free models, as well as another direct API access to YellowCake models. The YellowCake API primarily focuses on web automation and data scraping tasks, and thus, that requires an URL in the user's prompt. What elevates our app is the ability to firstly consult Gemini some valid URLs for the user's need, before launching the prompt to YellowCake's API.
Challenges we ran into
To provide better user experience (UX) with minimized latency, the app displays whatever response that has been completed first. Unlike traditional REST-based APIs, there isn't a need to wait for all the models to finish responding before visualizing on the screen. This is an important UX consideration as long as we are able to keep entertaining the user in a timely manner.
However, achieving this causes the major struggle of implementing an event streaming mechanism. Since the backend returns responses in an asynchronous manner, the (frontend) client should catch responses that matches with the model's name. It is important that we match model responses with an ID on the frontend. Apart from matching responses, in some occasions either the frontend makes repeated requests to the backend, or the backend mistakenly returns repeated responses to the frontend, causing incompatible amount of requests and responses. Communication between components is the key to a successful app. We further analyzed the root cause which refers to the user's ability to choose the same model twice, for comparison. As a result, we have made certain model choice options remain disabled from selection once it has been selected elsewhere. A very-specific scenario concerns the 'Auto' ability of OpenRouter. If the app makes 2 (or more) requests both with an automatic model choice from OpenRouter, it will only return the same model's response twice. We personally believe it could be the expected behavior from OpenRouter, where multiple automatic decisions are not permitted. This is probably because the process of determining the best model, given the exact same prompt, is always deterministic. To avoid response catching issues on the frontend, multiple 'Auto' LLM responses are not allowed.
Speaking of event streaming, YellowCake API also works in the same way. It keeps returning chunks of events until completion, because behind the scenes, the model behind is trying to automate from a website in real time, so it ought to provide timely feedback based on what the program 'sees' on the website. With the design of our app, as we only require the completed stream as the model's final outcome, it took us almost an hour to dig into analysing and parsing the stream data, making sure being readable to the end user.
Accomplishments that we're proud of
From backend to frontend, the app involves many different components. Integrating asynchronous streams into the frontend webpage causes some hassle. I am glad we sailed through all the challenges:
- Successfully built an end-to-end functional app despite certain unhandled edge cases.
- Explored the nature of various LLMs.
Although critics sometimes complain how certain models misbehave and hallucinate themselves, through an app with model comparisons, we are looking forward to make AI great again!
What we learned
Confidently speaking, this hackathon allows us to learn a lot! Speaking of technical skills, we started our journey to learn how we should handle asynchronous events other than traditional REST-based responses.
What's next for AI Battleship
Presumably, users would prefer to have a persistant chat dialogue, even in a comparative manner. A database would be ideal to store chat histories. Storing vectors of some chat contents at a retrieval-augmented-generation (RAG) source could also be a decent way to update those models' knowledge timely.
As we are not very skillful on the frontend design, a prettier UI and most importantly, more useful functions that aid users' experiences are yet to be developed onwards.
Built With
- fastapi
- githubcopilot
- materialui
- next
- python
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.