-
-

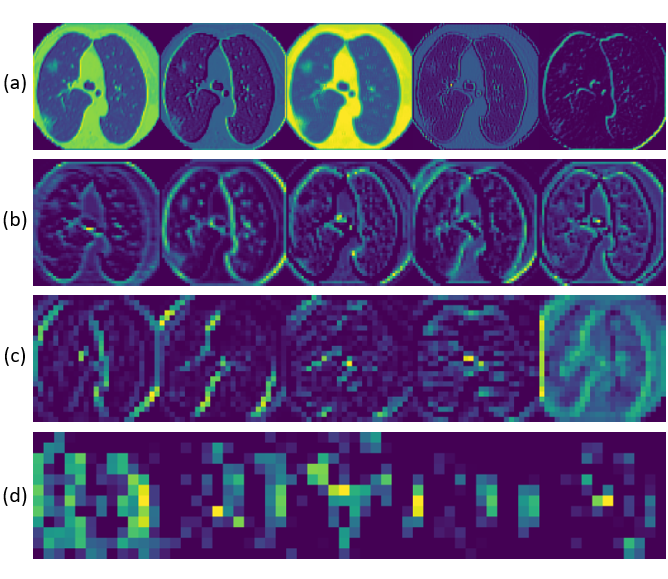
Intermediate Layer's features mapping. (a) Layer 1 (b) Layer 4, (c) Layer 8, (d) Layer 14. Shows complexity of features extracted via CNN.
-

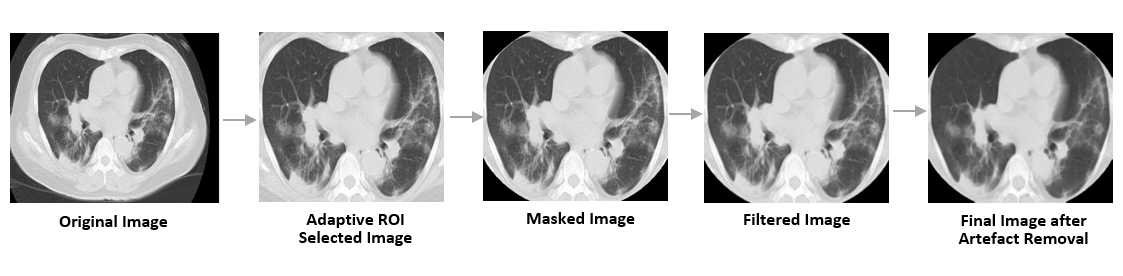
Image pre-processing visualization. Summary of the image pre-processing module. The final image is free of artifacts.
-

Architecture of the truncated VGG16 used. Truncation point was determined experimentally. Last block was fine tuned to improve performance/
-

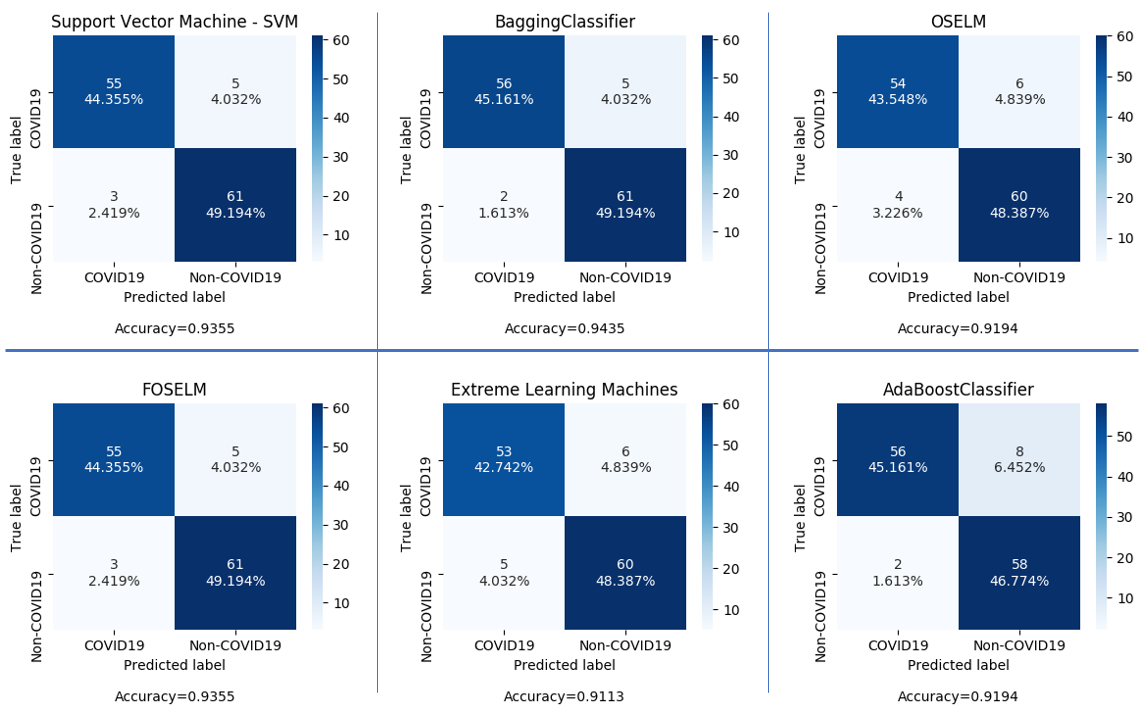
Confusion Matrix of Various Classifiers Tried. Features extracted using Truncated VGG16 architecture. Tested on test set.

Overview of the Project
Motivation
The rising cases of COVID-19 and not enough testing equipment motivated us to find a scalable solution that was accurate and at the same time cost and time efficient.
Deep learning, one of the most successful AI techniques, is an effective means to assist radiologists to analyse the vast amount of chest CT Scan images, which can be critical for efficient and reliable COVID-19 screening. In this project, motivated by the fact that CT Scans are much more accurate for diagnosis compared to X-Rays , a transfer learning-based feature extraction model, which we call VGG Feature Classifier, is proposed to screen COVID-19 positive CT scans from other healthy and non-COVID diseases.
How did we get the Resources
To evaluate the model performance, we have used 58 chest CT Scan images of 50 patients confirmed with COVID-19 and 66 chest CT Scan images of non-COVID patients. The images were collected and compiled from medRxiv and bioRxiv posted between Jan 19th and Mar 25th. To train our model we used 232 COVID-19 images and 260 non-COVID images, collected from same source as the evaluation data. We also included CT Scan images of Pneumonia and Tuberculosis patients in our non-COVID training set to improve the precision of the model.
What we have done
Our experimentation shows that our model can detect COVID-19 samples with an accuracy of 0.944. Our model has a precision of 0.968 and a F1 score of 0.946 when evaluated on the 124 test images. Thus, offering a promise of our proposed model for reliable COVID-19 screening of chest CT Scan images.
Project Structure
Summary of Model
In this work, considering the fact that CT Scan imaging systems are more accurate and precise than X Ray systems, Deep learning model is built to screen COVID-19 using CT Scans. A transfer-learning based model is proposed, which we call Truncated VGG feature based classifier. For training, other than healthy CT scan samples we have also collected Pneumonia and Tuberculosis patients’ CT Scans to increase the model’s selectivity/recall.
Performance Summary
The proposed model is validated to classify COVID-19 positive CT Scans from Pneumonia, Tuberculosis and healthy CT Scans. Using the limited number of COVID- 19 positive CT Scans, we have achieved a very high precision and recall. On the whole, in this paper, we demonstrate that the Truncated VGG features based classification model outperforms the state-of-the-art results for COVID-19 positive cases.
The project provides an Ideal solution for COVID-screening at large scales with a testing time of less than 0.5 seconds and an accuracy of over 95%.
How we built it
Inspired from the fact that COVID-19 shows patches of ground glass opacity (GGO) and consolidation in CT Scans, to detect COVID-19 cases, a multi-resolution analysis of the CT Scan images is deemed useful. The required trait is possessed by the VGG16 module. Additionally, considering the fact that the number of data samples of COVID-19 positive CT Scans is very scarce at present, a modified version of the VGG model is proposed, which we call Truncated VGG.
Pre-Processing -
 FIgure - 1 : Summary of the preprocessing module
FIgure - 1 : Summary of the preprocessing module
Since our Data is composed of images from varied sources, it is very sporadic. If trained directly on these images, the features extracted will not be homogeneous across data causing the model to have a low accuracy. To tackle this, a strong image pre-processing module has been designed.This module ensures our model can generalize well to this data.
We first have an adaptive region of interest extractor which crops, rotates, zooms, centers and straightens the image. Many images in the data-set have labelling and markings around the corners which could affect the performance of the model. To overcome this and to get a more accurate ROI selection, elliptical masks are applied to the CT Scan images. ROI selector removes all the non lung features from the images.
CT scans have artefacts like beam hardening, noise, scatter, etc. These artefacts if not handled, reduce the accuracy of the model. To overcome this, an artefact removal module is applied which uses filtering and morphological transformations to remove such artefacts. For the purpose of filtering, a bilateral filter, with a kernel of (5 x 5), is used because of its edge preserving property. Morphological transformations namely erosion and closing are applied to reduce background holes and intensify the productive features in the image.
Feature Extraction
Features are extracted from images using a transfer learning based truncated VGG Model. This section describes the implementation of the truncated VGG alongwith the reason for a truncated architecture.
Reasons for Choosing VGG Model -
VGG, ResNet 50 and AlexNet are the most popular CNN architectures for medical image classification. The three CNN archtectures are compared in Table-1 for our dataset. For Comparing the models, a Softmax layer is appended to the architectures. As can be seen from the data, VGG outperforms ResNet and AlexNet on the dataset.
Table-1 Comparing Various Architecture Accuracies
| Architecture | Accuracy |
|---|---|
| ResNet50 | 79.3% |
| Alex Net | 74.6% |
| VGG16 | 85.5% |
The combined output of the VGG module provides rich feature maps of varying perspectives. The small-size convolution filters allows VGG to have a large number of weight layers leading to an increased performance. Such a property of the VGG module explains its unique performance in medical imaging, and in our case, on the COVID-19 CT Scans.
Truncated Architecture -
 Figure-4 : Truncated VGG Architecture Summary.
Figure-4 : Truncated VGG Architecture Summary.
The VGG model was designed for imagenet database which has over 14 million images. Owing to the large size of the imagenet database, the VGG16 architecture is built to extract complex features with high dimensionality from images. Since our COVID-19 dataset is much smaller with only 492 images, a high complexity of feature set will cause the model to overfit the data. To prevent this, A truncated VGG16 architecture is proposed which contols the complexity of the features. The first three convolution blocks of the VGG16 architecture have been used for our truncated architecture and the output has been flattened. The reduced complexity of the architecture allows our model to generalize well to the small dataset.
The truncation layer was determined by evaluating performance on the test set with different points of truncation. Table-2 gives a summary of the results of this analysis. Figure-2 depicts the architecture of the truncated CNN.
Table-2 Comparing Truncating Points
| Truncation Point | Accuracy |
|---|---|
| Layer-10 | 81.8% |
| Layer-14 | 92.2% |
| Untruncated | 86.5% |
Transfer Learning
Training a Neural Network from scratch requires huge amounts of data. Since the COVID-19 dataset available is significantly smaller, we rely on transfer learning to extract accurate and concise feature set from our training data. With transfer learning a solid machine learning model can be built with comparatively little training data because the model is already pre-trained. For our purpose we use a pre-trained model i.e. VGG16 with imagenet weights.
Since the Image net set is non-overlapping to the problem, the last 4 layers i.e. the third convolution block are fine tuned on the training data. This ensures the representation extracted from the data is relevant to the classification. Through transfer learning, an accurate set of reduced feature representation of our data has been extracted.The extracted features displayed as a color map are represented in Figure-3.
 Figure-3 : Feature map of various intermediate layers.
Figure-3 : Feature map of various intermediate layers.
Summary of Feature Extraction
A Truncated VGG16 architecture is proposed for extracting features. The architecture is based on a represeantation learning model using imagenet weights. The last block of the truncated architecture is fine tuned with diffrential learning rates for more accurate extraction. The model thus gives a reduced representation of raw data with accurate features to be used for the classification.
Dimensionality Reduction
The feature extractor module, reduces the dimension of the data to 25,000 features per image for an image size of 112 x 112 pixels. However, with only 492 training examples, the model will still overfit the features. To prevent this feature selection and dimensionality reduction of data is applied.
PCA, Autoencoder and KBest have been used to select about 300 features, and then compared their accuracies after classification with an SVC. While using PCA 95% variance was retained which yeilded 358 features. The Autoencoder and Kbest were also configured to select 358 features. The results of the analysis is tabulated in Table-3. For our data, PCA gives the highest accuracy. One of the keys behind the performance of PCA is that in addition to the low-dimensional sample representation, it provides a synchronized low-dimensional representation of the variables. This provides a way to visually find variables that are characteristic of a group of samples.
Table-3 : Comparision of Feature Selector Accuracies
| Technique | Accuracy |
|---|---|
| PCA | 94.3% |
| KMeans | 84.1% |
| Auto-Encoder | 86.4% |
Classification
The extracted features from the training set are used to train the classification module to screen COVID-19 CT Scans. For classification a different model that trains on the features selected by PCA is used. In machine learning no one algorithm is suitable for all problems. Hence, for achieving the highest performance, 6 different classification model were evaluated, using test set features. Based on these results the best suited classifier for our problem is chosen. What follows are the brief details of our implementation of various classification models followed by a summary of results.
 Figure-4 : Confusion Matrices of the Various models Proposed.
Figure-4 : Confusion Matrices of the Various models Proposed.
Deep CNN
Since, VGG is itself a CNN architecture, for our Deep CNN model, a fully connected layer of size 1024 is added to the truncated VGG architecture followed by a softmax layer for classification. This gives us the most direct classification model where the feature extraction and classification are in the same CNN architecture. The deep CNN utilizes the fine tuned weights and uses it to directly predict the output. The performance of Deep CNN model is summarised in Table-4. The cocnfusion matrix is shown in figure-4.
SVM
For classification using SVM, radial basis function kernel (RBF) was used because of the high dimensionality of the data. The hyper-parameters C and gamma were experimentally determined. The summary of SVM evaluation for different values of C is given in Table-4. The confusion matrix for C = 2.5 is given in figure-3.
Bagging Ensemble
For classification using Bagging SVM, the data set was randomly divided into10 parts and trained the individual classifiers independently. They are aggregated to make a joint decision by the deterministic averaging process. The same SVC model was used as the base estimator. The confusion matrix for Bagging SVM is given in figure-4.
Extreme Learning Machine (ELM)
For classification using ELM, various activation functions like gaussian, multiquadric and polyharmonic RBFs were implemeted. The number of hidden layers in the model are 1000 with best-suited gamma(Width multiplier for RBF distance).The confusion matrix for ELM is given in figure-4.
Online Sequential Extreme Learning Machine (OS-ELM)
For classification using OS-ELM, SLFN was implemented with sigmoid activation function with 2500 hidden layers. The dataset was divided into chunks, and the model was initialized and sequentially trained. The confusion matrix for OS-ELM is given in figure-4.
Experimentation
Data Augmentation
The size of the available COVID-19 Chest CT Scan Dataset is quite small. If the model is trained on such a small number of COVID-19 positive cases, it would have a very low recall. To overcome this, Data AUgmentation has been applied. We augment each training image by random affine transformation, random crop, flip and random changes in hue, brightness and saturation of the image. The random affine transformation consists of translation and rotation (with degrees of 5, 15, 25).
Adversarial Defense
Deep learning models are easily fooled with noise perturbations. Such perturbations might also happen in the real world. To defend our model against such noise attacks, a defense module has been designed.
Three image denoisers have been applied namely total variation, guassian filter and wavelet denoising. The prediction of all 4 images is passed to an ensemble which finally classifies the image. On evaluation on the test set after adding random noise, the model gives an accuracy of 82.34%.
Data-Set

The COVID-19 data is very scarce and difficult to obtain. Despite this we collected 290 CT Scans of people tested positive for COVID-19. The dataset was collected from pre-prints uploaded on medRxiv and Biomed from 25th January 2020 to 30th March 2020. The Summary of Data set is given below.
COVID-19 Positive Scans - 290 COVID-19 Negative Scans - 326
We divided the set for training, validation and testing in a 7:1:2 ratio. We had 431 train images, 123 test images and 62 validation images.
Results
For evaluation, the dataset is randomly split in a 7:1:2 ratio as training, validation and testing sets respectively. The overview of the split is shown above. The final performance is the average of 5 random set divisions.
Our proposed model's evaluation is summarized in Table-6. Our model has a very high precision of 96.82% and an F1 score of 94.45%. Our model outperforms any other model on COVID-19 screening using CT Scan Images in terms of accuracy and F1 score.
As a model signed for COVID-19 screening, the proposed method aims to reduce the false negative rate as much as possible, since false positive cases can potentially be identified in the subsequent tests, but false negative cases will not have that chance. Our proposed model has a false negative rate of 6.58%, which is significantly lower than other COVID-19 CT Scan screening models.
Table-4 Summary of Results -
| Classifier | Accuracy |
|---|---|
| SVM | 94.35% |
| DeepCNN | 92.65% |
| Bagging Classifier | 95.38% |
| ELM | 91.93% |
| OSELM | 93.54% |
Deployment
We have also made made a GUI for our model. The GUI is basic at the moment where the user uploads the image of a Chest CT Scan and the website uses our model to predict if the case is of COVID-19 or not.
We are currently trying to publicly deploy the website and add featurres like severity score and progress tracker.
We are also working on building an app for the model.
The basic version of the model is deployed at : COVID-19 CT Scan Screener
Accomplishments that we're proud of
We built a model that outperforms any other model for CT Scan based COVID-19 Screening. This was a huge accomplishment for us. We have also launched a website for users to upload images and test CT Scans.
We are really happy and proud of our work but will be more proud when it is actually deployed in hospitals and helps fighting the pandemic.
We also built the model in a time-span of 1 week which was really difficult given the scarcity of data and complexity of the problem.
What we learned
We learnt many new techniques of Image classification and Image processing.
Overall this was a great learning opportunity for us. We look forward to implementing this solution on a scale that helps people fight the COVID-19 outbreak.
How will this help in the fight against COVID-19
As the cases of COVID-19 keep increasing globally, the pressure on the healthcare system keeps mounting. Studies have shown that people are unable to find trained professionals to check their reports. This is a flaw in screening and will lead to further spread.
If our solution gets deployed, it will help in screening patients at an accuracy that is comparable to a trained doctor in 1/1000th of the time taken by an actual professional. Bulk testing through our model will lead to better screening and isolation of patients.
A doctor on average needs 15-25 minutes to screen a CT Scan from print. This is just the doctor's time, the overall screening process takes hours. With our solution, we could screen a patient within seconds and also generate a report of how severe the infection is. Not only that the model has a feature to flag low confidence instances for a doctor to look over.
This can be really crucial especially in areas where the doctors are heavily outnumbered and trained professional can't cater to everyone's needs.
Ultimately this will help flatten the curve.
We look forward to implement this model at a wider scale.
Video Demo Link : Video Demo of Website

Built With
- angular.js
- css
- flask
- html
- image-augmentation
- javascript
- joblib
- keras
- numpy
- opencv
- pickle
- python
- scipy
- skimage
- sklearn
- tensorflow
- vgg16




Log in or sign up for Devpost to join the conversation.