-
-
Home page of the app
-
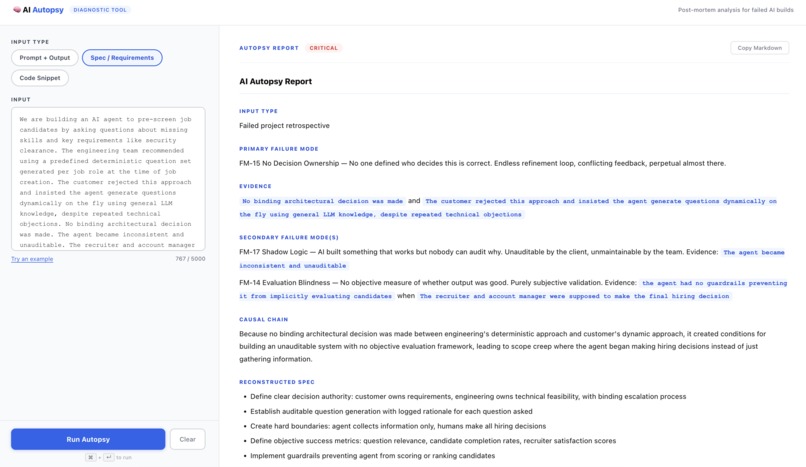
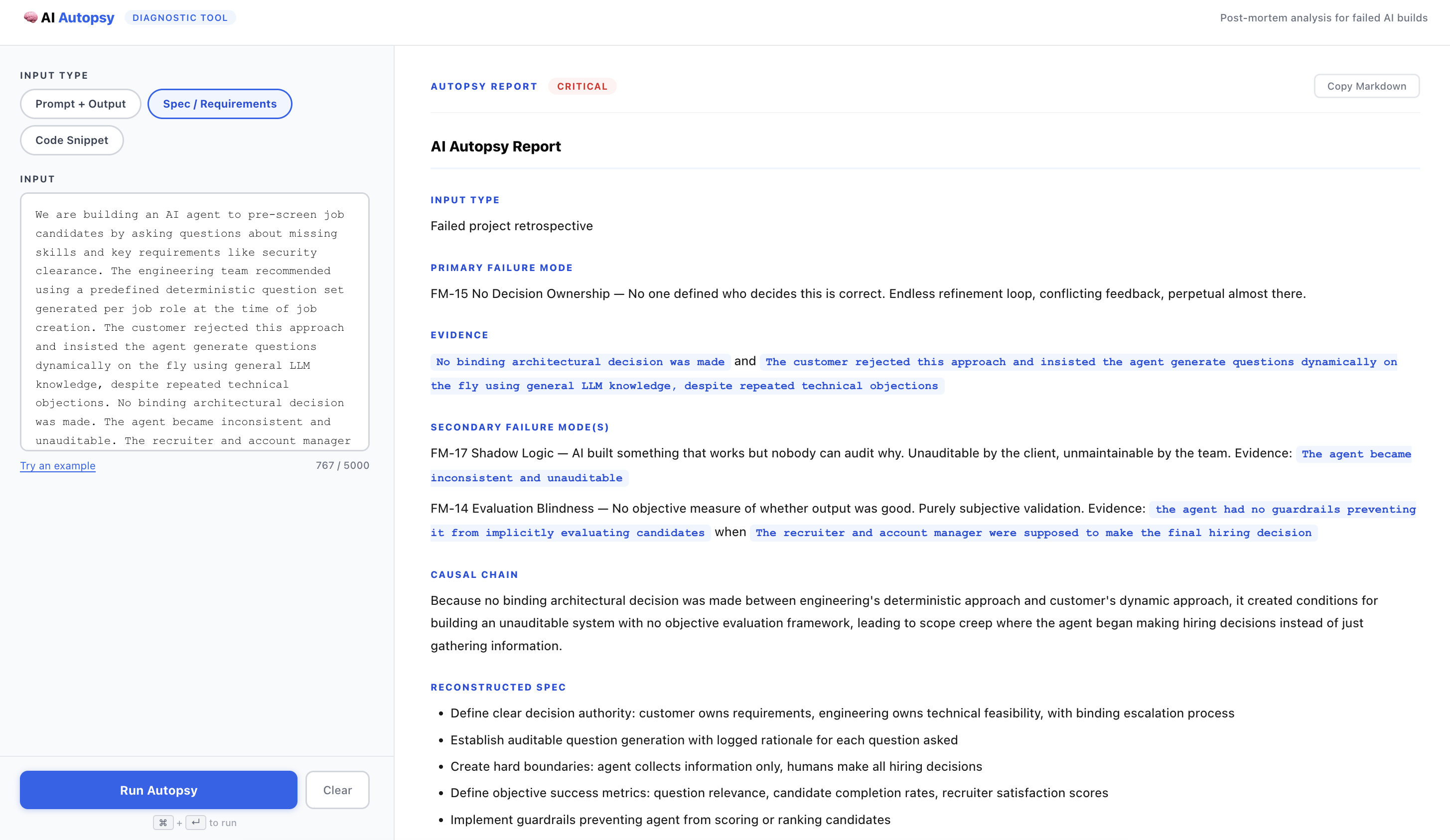
Running a spec/requirement example
Inspiration
Most AI projects don't fail because the code broke. They fail because the thinking broke three steps earlier — a vague requirement, a wrong architectural assumption, a customer decision that overruled engineering judgment. By the time the output looks wrong, the root cause is invisible.
I've spent 20+ years in enterprise consulting watching this pattern repeat — at IBM, at Deloitte, and now at Salesforce deploying AI agents. Teams shrug and rebuild, or worse, ask the same AI that failed to explain why it failed. Neither works.
AI Autopsy started as a question: what if you could run a structured post-mortem on a failed AI build the same way a consulting team runs a root cause analysis on a failed enterprise implementation?
What it does
AI Autopsy is a diagnostic tool that analyzes failed or underperforming AI builds and produces a structured post-mortem report.
You paste one of three input types:
- A failed prompt and AI output pair
- A vague spec, PRD, or requirements description
- A code snippet with a description of what went wrong
The tool runs it through a Judge LLM against a proprietary 17-mode failure taxonomy across 5 categories — Prompt & Framing, Spec & Planning, Architecture & Design, Context & Execution, and Decision & Governance.
The output is a structured Autopsy Report containing:
- Primary and secondary failure mode identification
- Evidence — direct quotes from your input proving the failure, never just labeling it
- A causal chain showing how one failure created conditions for the next
- A reconstructed spec showing what it should have said
- A prioritized remediation plan
- A verdict: Inconclusive, Recoverable, or Critical
The Judge never labels without proof. If the input lacks sufficient diagnostic signal, it returns Inconclusive rather than hallucinating a failure mode.
How we built it
The build followed strict spec-driven development across 4 planning artifacts before a single line of code was written — scope document, PRD, technical spec, and build checklist. The planning artifacts are included in the docs/ folder as required.
Architecture decisions made upfront:
- Single-page frontend (HTML/CSS/JS) with a FastAPI proxy backend to keep the API key server-side and out of the browser entirely
- The failure taxonomy lives in a local taxonomy.json file — pluggable and version-controlled, editable without touching application code
- The Judge LLM receives only id, name, and definition from each failure mode for token efficiency — remediation text is pulled locally by FM-ID after classification and appended to the report
- marked.js handles Markdown rendering of the report
The taxonomy itself is the core IP — 17 failure modes built from real enterprise consulting experience, not textbook definitions.
Challenges we ran into
The hardest problem was the taxonomy design. A failure taxonomy is only useful if the Judge LLM can match evidence to modes without hallucinating a classification. Early versions would force a failure mode even when the input was too vague to diagnose. The FM-00 (insufficient_data) null state was the fix — explicitly telling the Judge that returning Inconclusive is a high-accuracy result, not a failure.
The second challenge was test case design. The anchor case study — a real enterprise AI agent for candidate pre-screening that was eventually abandoned — initially produced the wrong primary failure mode because the input description didn't capture the governance failure that caused the project to collapse. The input had to be rewritten to include the decision ownership failure explicitly. This became a key insight: the quality of the autopsy is directly proportional to the quality of the failure description.
Accomplishments that we're proud of
The evidence-matching requirement. The Judge doesn't just classify — it cites specific language from your input to prove each failure mode. This was a deliberate architectural decision that separates AI Autopsy from a generic LLM wrapper.
The anchor case study passes with FM-15 (No Decision Ownership) as the primary failure mode — exactly what it was in real life. That validation matters.
5/5 test cases passed on primary failure mode identification with correct causal chains.
What we learned
Spec-driven development works — but only if the spec is grounded in real experience. The failure taxonomy took longer to design than the application itself. That's exactly as it should be.
The most important lesson from the test suite: an AI diagnostic tool is only as good as the failure vocabulary it reasons against. Generic taxonomies produce generic diagnoses. The 17-mode taxonomy built from enterprise consulting experience produced diagnoses that matched real outcomes.
What's next for AI Autopsy
- Batch analysis — run multiple failed builds through the same taxonomy and surface patterns
- Taxonomy versioning — let teams extend the failure modes with their own organizational patterns
- Integration with GitHub — analyze PRs, commit histories, and issue threads as input types
- A public failure library — anonymized case studies mapped to the taxonomy, searchable by failure mode
Built With
- claude-api-(anthropic)
- css
- fastapi
- html
- javascript
- marked.js
- python
- uvicorn

Log in or sign up for Devpost to join the conversation.