Inspiration
We wanted to find a way to automate some of the work done by editors, audio engineers, and foley artists using state-of-the-art machine learning models.
How we built it
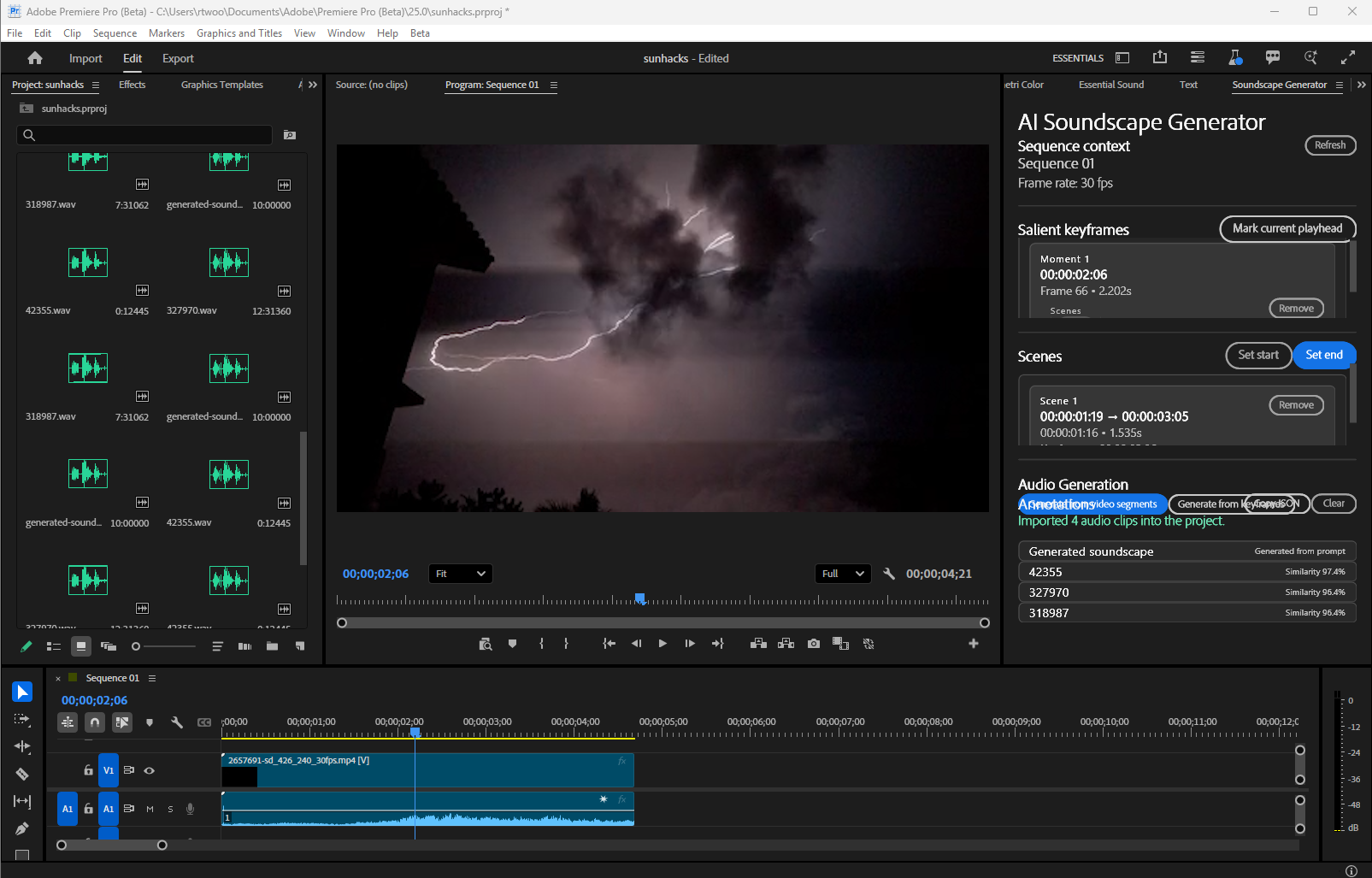
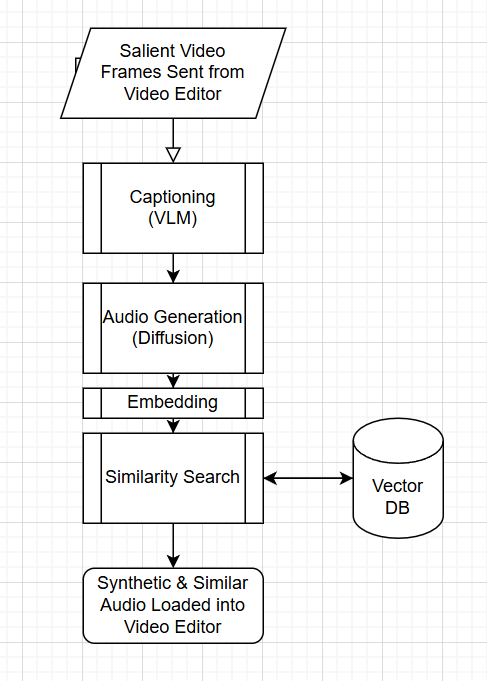
We employed a pre-trained vision language model (VLM), Qwen2.5-VL-7B-Instruct, to caption salient video keyframes for auditory descriptions. This was then fed into a audio diffusion model, AudioLDM2, to generate hypothetical audio for the video, which is then embedded for the purposes of similarity search on an existing sound library (Freesound).
Notably most existing embedding models were primarily for dialog, so our solution actually fills a minor gap as a custom hack together of a Large-Scale Pretrained Audio Neural Networks (PANN) originally trained on AudioSet, a highly generalized naturalistic audio dataset, whose audio tag outputs we developed a simple technique for vectorizing. To allow for the actual similarity search, we embedded the entire FSD50K dataset (instead of AudioSet due to time limitations as it's a substantially larger dataset ~2 million) into AWS RDS with pgvector. We deployed an MVP of this as a plugin for Adobe Premiere Pro, professional grade video editing software, alongside a GPU compute instance for hosting all of the models for inferencing.
Results
We achieved fairly good preliminary results on trivial scenes of videos of lightning, fireplaces, cars driving, etc.
Challenges we ran into
- Ran out of time to implement any data augmentation techniques (e.g. generative extension, modulation/changing the audio itself to suit corresponding video content better)
- Had difficulty getting access to AWS GPU compute instances


Log in or sign up for Devpost to join the conversation.