-
-
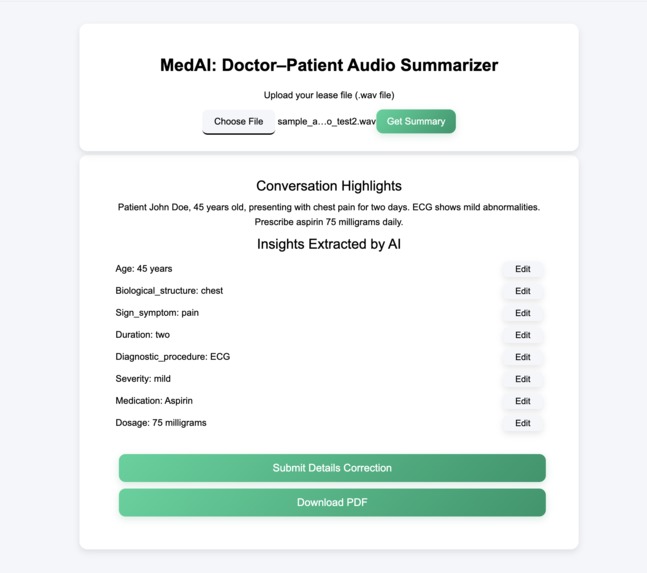
This is the User Interface that the doctor will use to upload their audio conversation file and the AI will extract the results
-

Slide 1
-

Slide 2
-

Slide 3
-

Slide 4
-

Slide 5
-

Slide 6
-
Slide 7
-

Slide 8








Inspiration
Doctors spend nearly 40–50% of their time on documentation, reducing the time available for patient interaction. During consultations, valuable details can get lost in manual note-taking or incomplete summaries. I wanted to build something that allows doctors to focus on patients and not paperwork. My inspiration was to use Speech Recognition and Natural Language Processing (NLP) to automatically convert doctor–patient conversations into structured medical summaries that includes age, medication, duration, biological structure etc, in turn reducing administrative burden and improving healthcare efficiency.
Why it matters
Every doctor knows how exhausting it is to take notes during or after consultations. MedAI: Doctor–Patient Audio Summarizer solves this by acting as an AI-powered scribe, helping reduce burnout, time, and improve accuracy. By combining speech recognition and biomedical Natural Language Processing (NLP), I am bridging the gap between raw audio and meaningful medical insight into making healthcare documentation faster, smarter, and more human-centered.
What it does/ What I built
MedAI: Doctor–Patient Audio Summarizer listens to doctor–patient consultations and automatically:
- Transcribes medical conversations in real-time using Gemini’s speech recognition.
- Extracts key medical entities like symptoms, medications, dosage, diagnostic procedures, and durations using a biomedical NLP model.
- Generates structured reports.
- Allows doctors to review and correct extracted entities through an interactive interface.
- Exports a PDF report summarizing the conversation for only the doctor
How I built it
- Frontend: React.js for UI, enabling audio file uploads, displaying transcription summary, extracted data, and interactive doctor review.
- Backend: FastAPI for managing endpoints, processing audio input, and generating structured data and PDF.
- Speech Recognition: Gemini API for transcribing audio to text.
- NLP Entity Extraction: Hugging Face model d4data/biomedical-ner-all for identifying medical entities.
- PDF Generation: ReportLab for producing downloadable structured summaries.
How It Works
- The doctor uploads an audio file of a consultation.
- The backend uses Gemini’s Speech-to-Text API to convert the recording into an accurate transcript.
- The transcribed text is passed through a biomedical NLP model (d4data/biomedical-ner-all) that extracts key medical entities like disease, symptom, drug name, and dosage.
- Each extracted entity is displayed on the frontend, making it easy for doctors to verify all the terms.
- After doctor review, the doctor can either click the button (Download PDF) directly if there's no error with the AI's extracted entity results or will first click on edit against all the entities that needs correction and then click on Submit Details Correction button to submit correct consultation details to the backend. And then click on the button (Download PDF) that generates a PDF summary that includes:
- Date and Time of consultation
- Transcribed conversation summary
- Highlighted key terms
Challenges I ran into
- Handling audio-to-text conversion accuracy, especially with medical terms. Initially I tried using the basic spacy model, but that model did not help to extract specific medical terms, hence had to try the medical NER model from Hugging Face.
- Managing tokenization artifacts (like “##” tokens) from NLP models. Some of the extracted same medical entities were separated by tokens as a result I had to merge them as a single extracted entity. For example in the extracted entities there was two occurrences of Medications. The first occurence had asp and the second occurence had irin. Hence I have to tweak the code to merge such duplicate occurences
- Designing a clean, doctor-friendly UI for reviewing entities.
Accomplishments that I am proud of
- Built an end-to-end AI pipeline from speech to a structured report by learning and implementing at the same time.
- Integrated Gemini and Hugging Face models for real-time medical entity extraction.
- Created a review system where doctors can validate and correct extracted terms by the AI, so that the control is still with the doctors.
- Successfully generated exportable PDF summaries for doctors and healthcare records.
What I learned
- How to combine Speech recognition, NLP, and healthcare data processing effectively.
- Challenges of clinical text analysis i.e entity ambiguity, overlapping terms, and abbreviations.
- Importance of human-in-the-loop AI, where doctors validate model predictions.
- Building a full-stack AI product that’s both technically robust and doctor-centric.
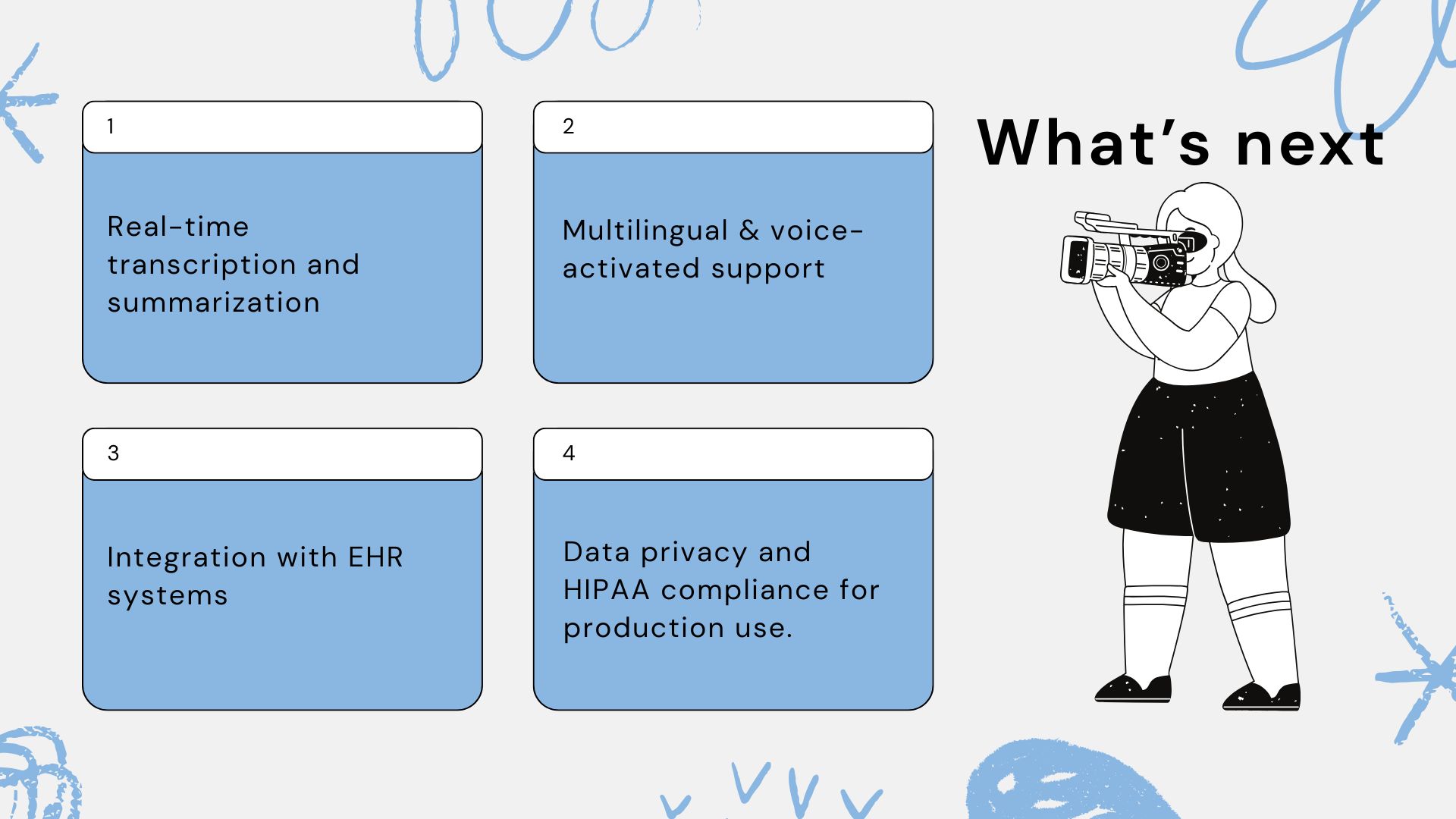
What's next for AI assisted doctor–patient audio summarizer
- Real-time streaming transcription during live consultations.
- Multilingual support (English + Hindi + Spanish).
- Integration with EHR systems using FHIR standards.
- Conversational chatbot interface for quick insights (e.g., “What medications were prescribed?”).
- Data privacy and HIPAA compliance for production use.
- Expanding the NLP pipeline to summarize key findings automatically for reports.


Log in or sign up for Devpost to join the conversation.