-
-

project page
-

problem
-
drone-simulation
-
robot-sim
-
mobile app1
-
mobile ui2
-
mobile ui3
-
mobile ui4
-
team
-

tech stack



Inspiration
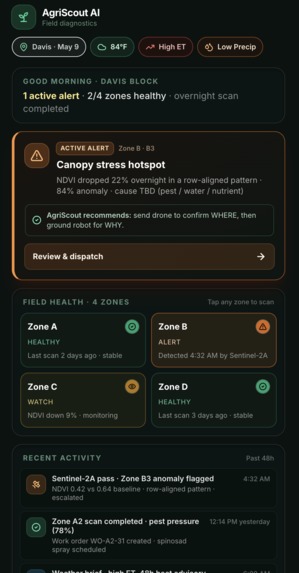
Single-zone NDVI alerts are useless without explanation. A 22% drop on a Tuesday morning tells you something is wrong in Block B-3, but not whether it's a pest outbreak, an irrigation failure, a nutrient deficit, or just a sensor glitch. The farmer still has to walk out to the field, kneel between the rows, look at the leaves, dig at the soil. The "AI alert" was a starting gun, not an answer.
We wanted to build the missing layer: a system that escalates sensing autonomously, distinguishes between pest / water / nutrient stress with physical evidence, and produces an actionable work order. Not another notification — a diagnosis.
The key insight: this is a multi-cause problem. Aerial imagery confirms where the hotspot is, but rarely tells you why. We needed a ground-truth phase with embodied reasoning — a robot that can physically inspect a leaf, compare it to a healthy reference plant, probe the soil moisture, and integrate evidence into an explainable probability distribution over causes.
What it does
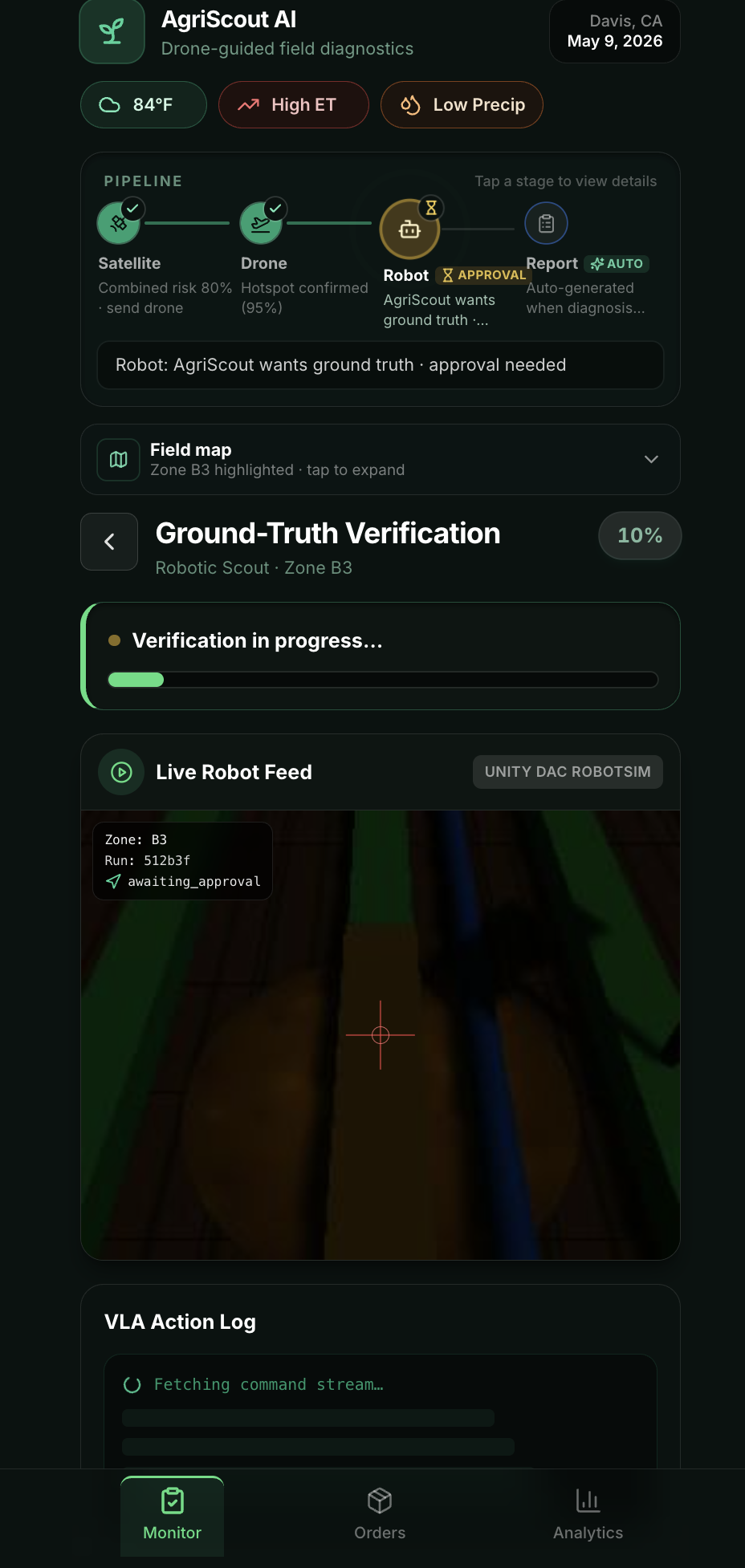
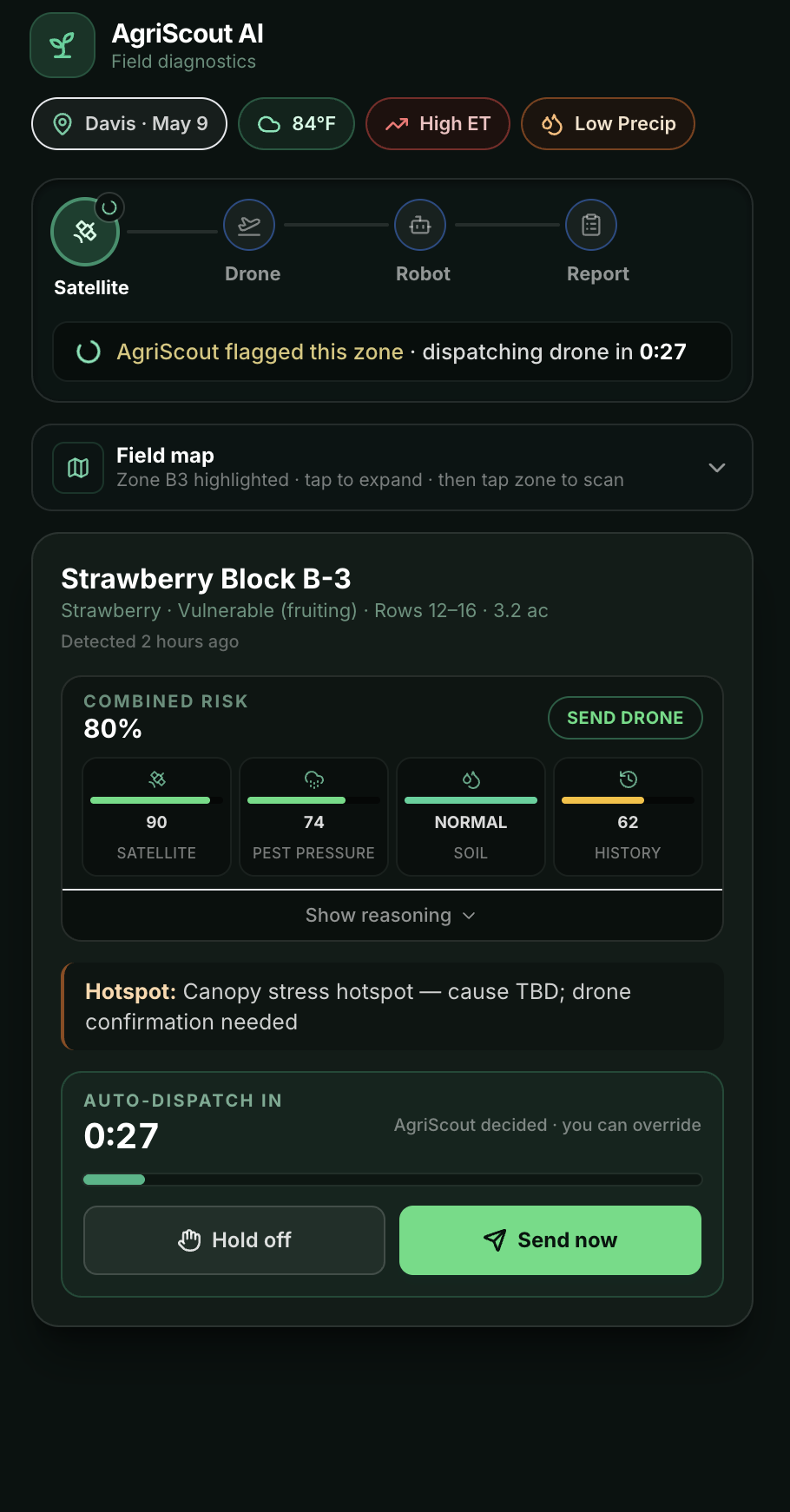
AgriScout AI runs an end-to-end agentic diagnostic pipeline the farmer watches in real time on their phone:
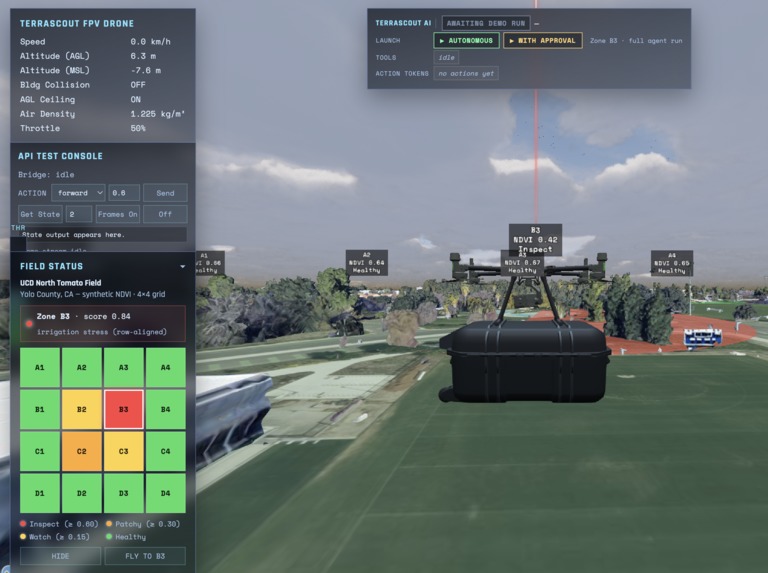
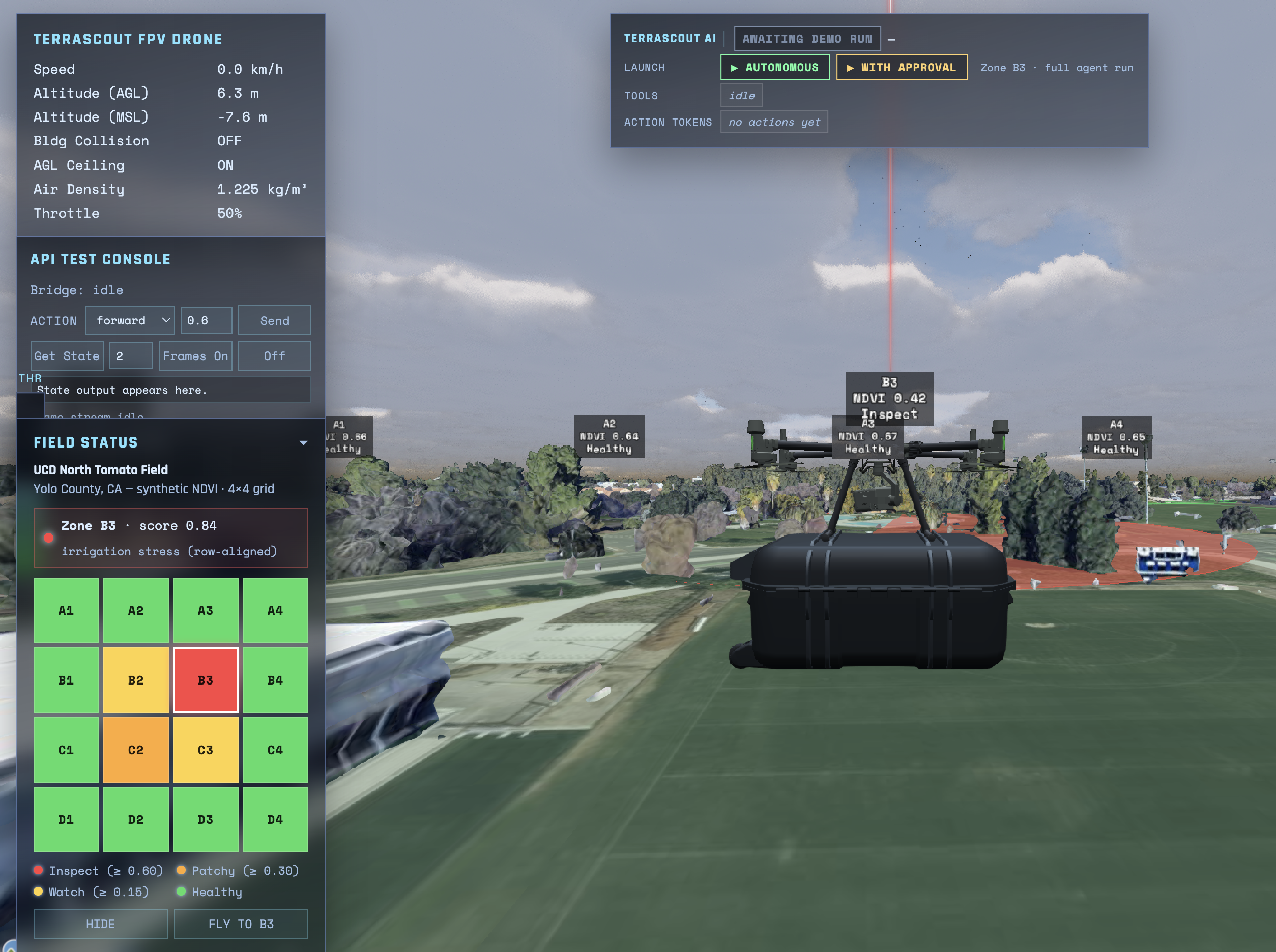
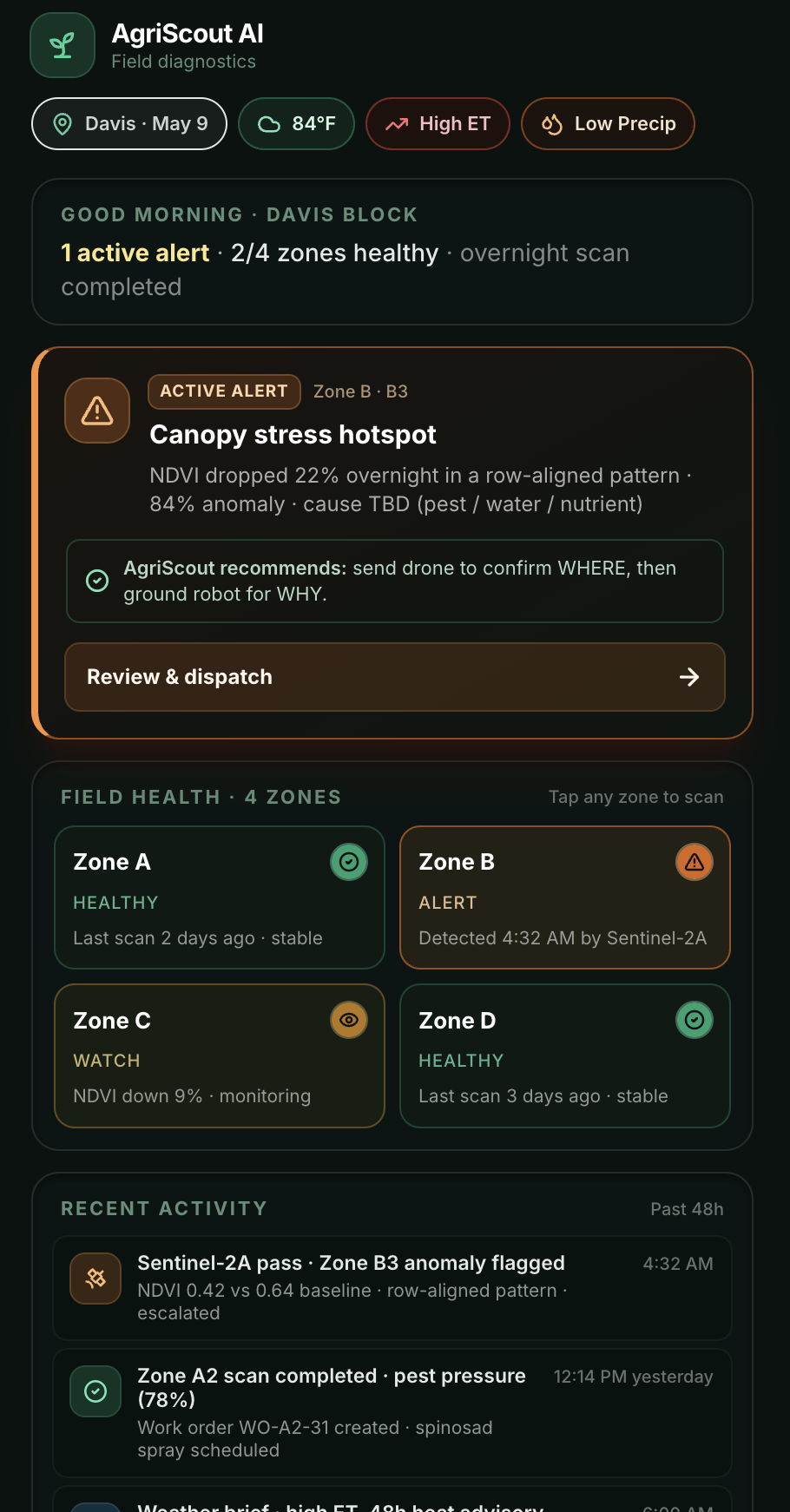
- 🛰 Satellite watch. A risk engine combines NDVI anomaly + weather + soil moisture + historical hotspot pressure to classify each zone. Anomalies above threshold get escalated.
- 🚁 Drone aerial confirmation. A drone is auto-dispatched to fly takeoff → cruise → descend → scan. The captured frame is analysed by two vision-language models in parallel: Gemini Robotics-ER 1.6 (cloud) and Gemma 4 via local Ollama. Their evidence points are cross-validated — agreement raises confidence, disagreement is flagged on the overlay.
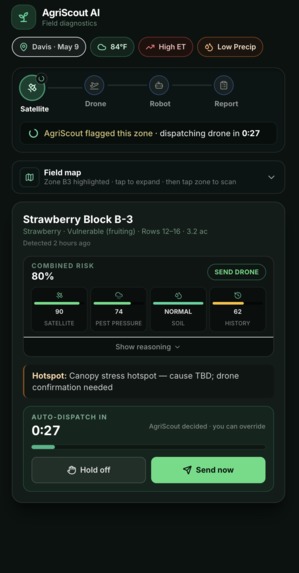
- ⏸ Human-in-the-loop gate. The drone is passive observation; the ground robot is active physical dispatch. Before sending it, AgriScout pauses for explicit human sign-off with a 30-second auto-approve countdown (operator can Hold / Approve immediately / Reject).
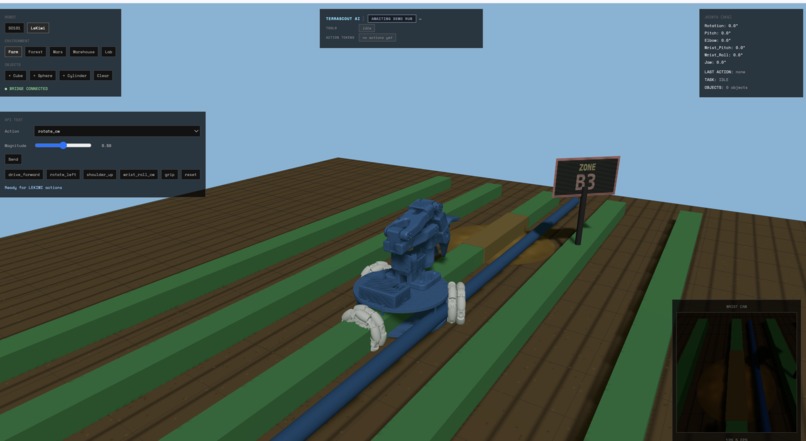
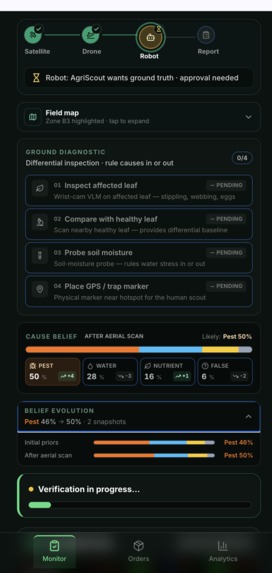
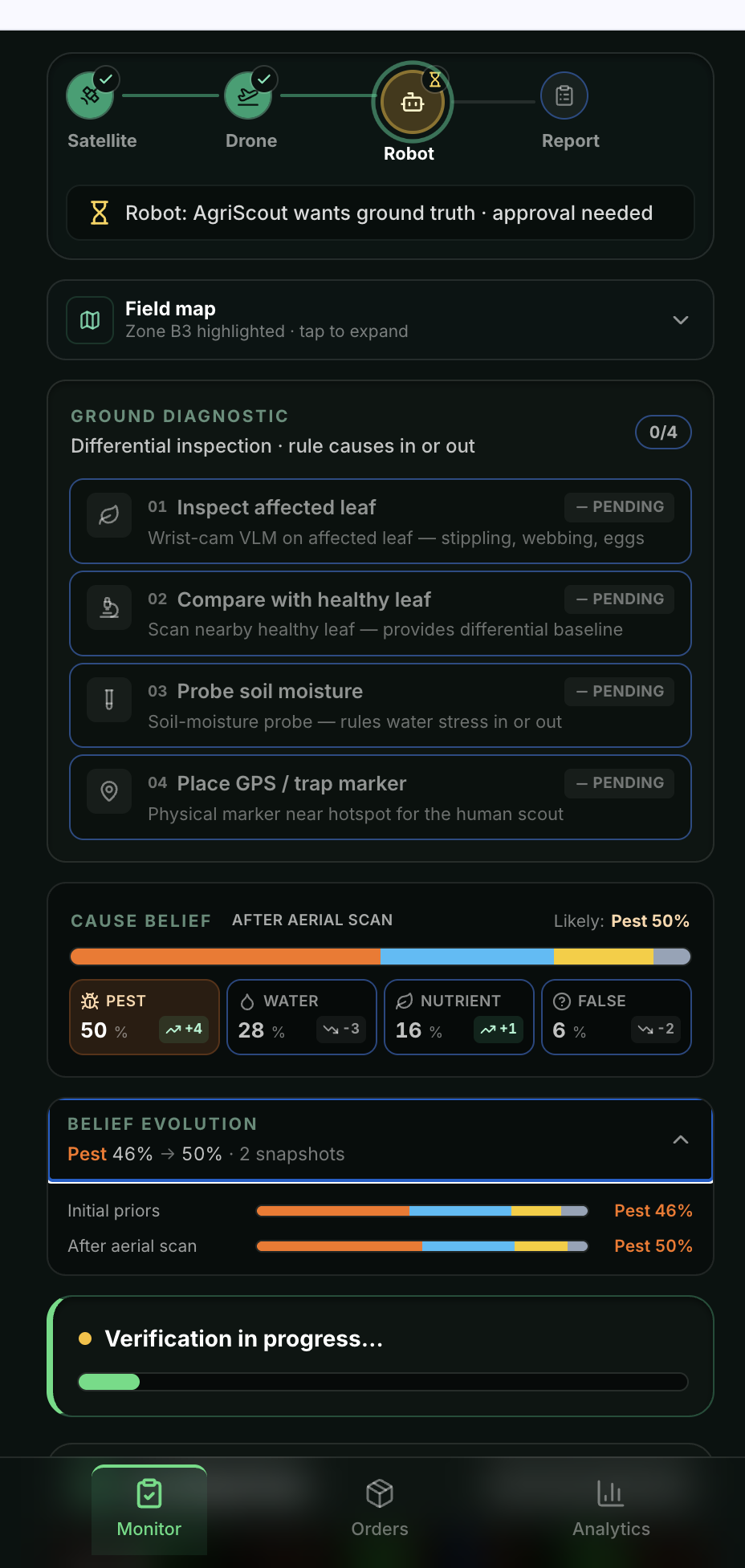
- 🤖 Embodied-reasoning diagnostic loop. The robot runs a 4-step routine driven by Gemini Robotics-ER:
inspect_leaf_with_wrist— examine the affected canopycompare_healthy_plant— pull a reference baseline from a known-good neighbourprobe_soil_moisture— test the soil to rule water stress in or outplace_pest_marker— mark the spot for the human scout
- 📊 Multi-cause belief evolution. After every observation, AgriScout updates a probability distribution over
[pest, water, nutrient, false_alarm]and records a snapshot. The farmer sees pest go from 0.46 → 0.50 → 0.30 → 0.18 → 0.80 → 0.82 with the tool that caused each shift — explainable Bayesian inference, not a black box. - 📋 Work order generation. Gemini 2.5 Pro synthesises the accumulated evidence into a structured work order with the dominant cause + recommended action.
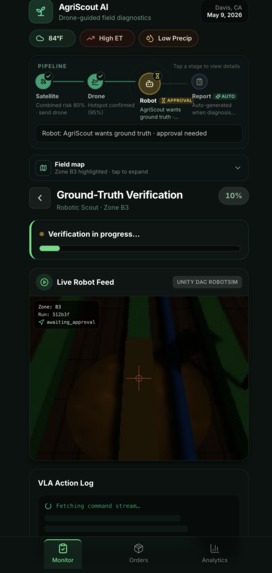
The mobile app lays it all out as a single timeline: Satellite → Drone → Robot → Report, with the active stage's detail card swapping in place. The farmer never gets lost in nested screens.
A separate "Today" tab gives the morning brief — active alerts, field health across all 4 zones, recent activity, and weather. Tapping the alert (or any zone) launches the agentic pipeline; the farmer is the trigger, not the passenger.
How we built it
Every model AND the agent harness itself is Google. No third-party LLM dependencies:
- Agent harness: Google Agent Development Kit (ADK) for Python —
LlmAgent,Runner,SessionService,FunctionToolwrappers, andbefore_tool_callbackfor safety guardrails - Orchestration brain: Gemini 2.5 Pro — the root agent that plans + sequences ~12 tool calls per run
- Embodied reasoning: Gemini Robotics-ER 1.6 (preview) — emits
target_point [y, x]+statusfor the 4-step closed-loop diagnostic - Local fallback VLM: Gemma 4 (
gemma-4-31b-it) via Ollama — cross-validates every drone/robot frame against the Gemini result; ensemble degrades gracefully if either side is rate-limited or offline
Stack
- Frontend: React + TypeScript + Tailwind + Vite, mobile-first
- Backend: FastAPI (Python 3.12) with Pydantic schemas, async ADK runner
- Agent harness: Google ADK —
LlmAgent(Gemini 2.5 Pro) withFunctionTool-wrapped diagnostic actions - Perception ensemble: Gemini Robotics-ER 1.6 + Gemma 4 (Ollama) running in parallel
- Drone sim: Cesium-based 3D simulator, WebSocket bridge to the backend
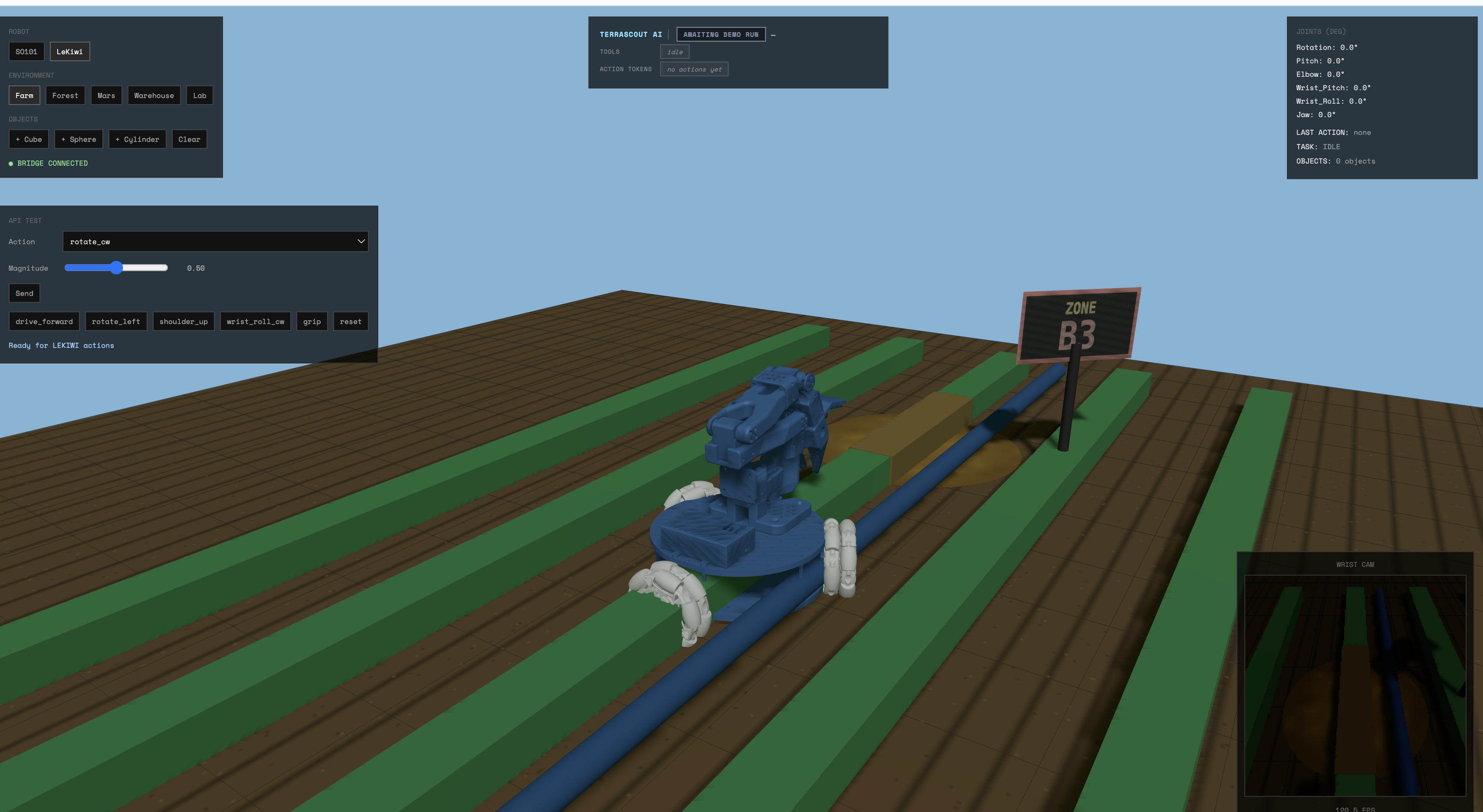
- Robot sim: SO101 arm + LeKiwi base simulator, HTTP bridge
The agentic pipeline
A single ADK LlmAgent powered by Gemini 2.5 Pro orchestrates ~12 FunctionTool calls per run (~3 minutes wall-clock):
fetch_risk_signal → fetch_anomaly → draft_inspection_plan
→ dispatch_drone_to_zone → vlm_analyze_aerial
→ request_human_approval [BLOCKS]
→ dispatch_ground_robot
→ inspect_leaf_with_wrist → compare_healthy_plant
→ probe_soil_moisture → place_pest_marker
→ create_work_order
The ADK Runner drives the loop and surfaces every tool event over its async event stream; we tap into that to record (tool, args, result, timestamp, ok) on the live run summary so the polling phone UI sees evidence accumulate as the agent works.
Key ADK pieces we lean on:
FunctionToolwrappers around the satellite / drone / robot adapters — each tool is a typed Python function with a docstring schema that ADK auto-converts into a tool descriptor for the modelbefore_tool_callbackas the safety chokepoint — every action passes through the altitude / budget / whitelist guard before reaching the sim, and the agent doesn't even see the rejection (it just gets a structured error back)- Session state for the run-id-keyed approval future, so
request_human_approvalcan park the loop until the operator clicks Approve / Reject in the phone UI - Async event stream for live polling — the phone re-polls every 750 ms and the ADK event log gives us tool chips and belief snapshots in near-real-time
Embodied-Reasoning policy
Gemini Robotics-ER 1.6 doesn't output joint commands — it outputs a target_point [y, x] in normalized image coordinates (0..1000, where (500, 500) is the frame center) plus a status field (success | continue | lost). We built a small deterministic translator (er_policy.py) that converts target points into safe SO101 action tokens within budget bounds. The model emits the where; the translator emits the how.
This mirrors Google's own stack — pairing Robotics-ER (spatial reasoning) with a deterministic motor layer is exactly how Google describes their dual-system robotics architecture. It also makes the loop debuggable AND swappable: we can drop in Gemini Robotics 1.6 (full VLA) later without changing the agent code.
Cross-validated perception (the Google ensemble)
Both VLMs are wrapped in an EnsembleVlmClient that fans out the same frame in parallel:
results = await asyncio.gather(*(
member.analyze_aerial(frame, zone) for member in members
))
Confidence is the mean of recognising members (a member that detected something is more informative than one that didn't). Evidence points from both VLMs are surfaced on the overlay — agreement raises trust, disagreement is flagged. Any individual member returning an error contributes nothing; the ensemble degrades gracefully into whichever member is up. Cloud-or-offline by design: if you lose Gemini API access mid-demo, Gemma 4 carries the load locally.
The 5-trigger UX
- T1 Satellite → Assess: automatic (passes risk threshold)
- T2 Assess → Drone: automatic (passive observation, no approval needed)
- T3 Drone → Robot: HUMAN gate (active physical dispatch always needs sign-off)
- T4 Robot → Report: automatic
- T5 Manual override: Send Now / Hold off / Reject — at every countdown
Safety
A per-action whitelist + per-run action budget (50 actions max) + drone altitude bounds (8m floor, 80m ceiling) gate every command before it reaches the sim, all wired through ADK's before_tool_callback. Every demo run logs 1–2 safety rejections — proof the system works, not decoration.
Challenges we ran into
1. Robot tipping mid-scan. Early action plans included rotate_left / rotate_right which spun the entire base — looked dramatic in dev, tipped the robot during the camera scan flourish. Fixed by replacing with arm-turntable rotates (rotate_cw / rotate_ccw) that pan the wrist cam without moving the base, and pinned the new action sequence with regression tests.
2. Drone sim retained altitude across runs. The second run started from 350m instead of takeoff because the sim never reset between dispatches. Fixed with a reset_to_launchpad action that teleports the drone to spawn, plus a safety-guard whitelist for reset so it bypasses the altitude floor check.
3. Black-frame VLM analysis. Drone sim sometimes returned solid-black frames when the WebGL canvas hadn't painted yet (~30% of runs after camera teleports). Added a wait_for_usable_frame guard with a 3s timeout and a graceful frame_unavailable fallback so the agent doesn't choke on an empty image.
4. ER policy needs a deterministic translator. Gemini Robotics-ER outputs target_point [y, x] + status, not joint commands. Built er_policy.py to convert target points into safety-bounded SO101 action tokens — the model emits the where, the translator emits the how. Keeps the loop debuggable and swappable.
Accomplishments that we're proud of
1. End-to-end pipeline in under 3 minutes. Satellite anomaly → drone aerial → 4-step robot diagnostic → work order, with live VLM analysis at every step. Real model calls, real sim motion, real evidence accumulation — no scripted demos.
2. Cross-validated Google VLM ensemble. Gemini Robotics-ER 1.6 (cloud) + Gemma 4 (local Ollama) analyse every frame in parallel. Confidence is the mean of recognising members; evidence points from both are surfaced on the overlay; ensemble degrades gracefully when either side is offline.
3. Explainable Bayesian diagnosis. Multi-cause belief over [pest, water, nutrient, false_alarm] updates after every observation, with snapshots recorded at each stage (initial → after_aerial → after_leaf → after_compare → after_probe → final). Every shift is tied to a specific tool — no black-box confidence number.
4. 69 backend tests passing, including motion-budget regression tests pinning the robot's exact action sequence so the rotate_left flipover bug can never return without a test failure.
What we learned
1. ER as policy is real. Pairing Gemini Robotics-ER (spatial reasoning) with a deterministic safety-bounded action translator is the right separation: debuggable, swappable, and honest about what the model can and can't do. We can drop in Gemini Robotics 1.6 (full VLA) later without changing the agent code.
2. Google ADK gets out of your way. LlmAgent, FunctionTool, Runner, SessionService, before_tool_callback — the framework gives you the agent loop, tool descriptors, retry policy, and safety chokepoint for free. We didn't reinvent any of it.
3. Cross-validated perception is the resilience story. Two parallel VLMs make the system cloud-or-offline by design — and "we surface where they agree or disagree" is a stronger technical pitch than picking a single model.
4. Status flips need defense in depth. Frontend logic that gates on a single backend field breaks when that field doesn't update for every state. Cross-check with adjacent evidence (diagnostic bundle, work order) and the UI stays correct even when one upstream signal is wrong.
What's next for AgriScout AI
1. Real Sentinel-2 ingest. Replace the synthetic 4×4 NDVI grid with hourly Sentinel-2 pulls and run anomaly detection on real imagery. Risk engine + zone schema are already field-ready.
2. Multi-zone parallel triage. Today scans are serial (one drone, one robot, one zone at a time). Production wants a queue manager so multiple alerts in different zones can be triaged in parallel by a fleet.
3. Real SO101 + LeKiwi hardware. Action tokens, safety bounds, and the ER policy translator are already designed for real hardware — only the adapter layer changes.
4. Deploy on Google Cloud. Vertex AI Agent Engine for the ADK runtime, Cloud Run for FastAPI, GKE / Cloud Run for self-hosted Gemma 4 endpoints, Vertex AI Model Garden for managed Gemini. Local rig → managed cloud is a config change, not a rewrite.
5. Feedback loop for VLM quality. Capture farmer agree/disagree at the work-order step, use that signal to fine-tune prompts and update ensemble member weights. The system sharpens with every diagnosis.

Log in or sign up for Devpost to join the conversation.