-
-
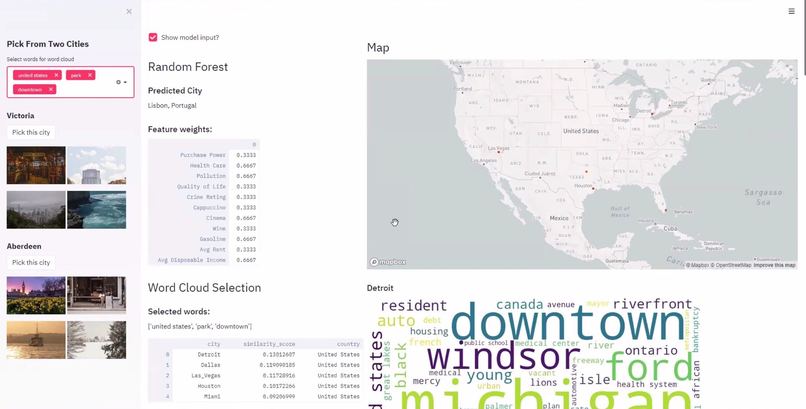
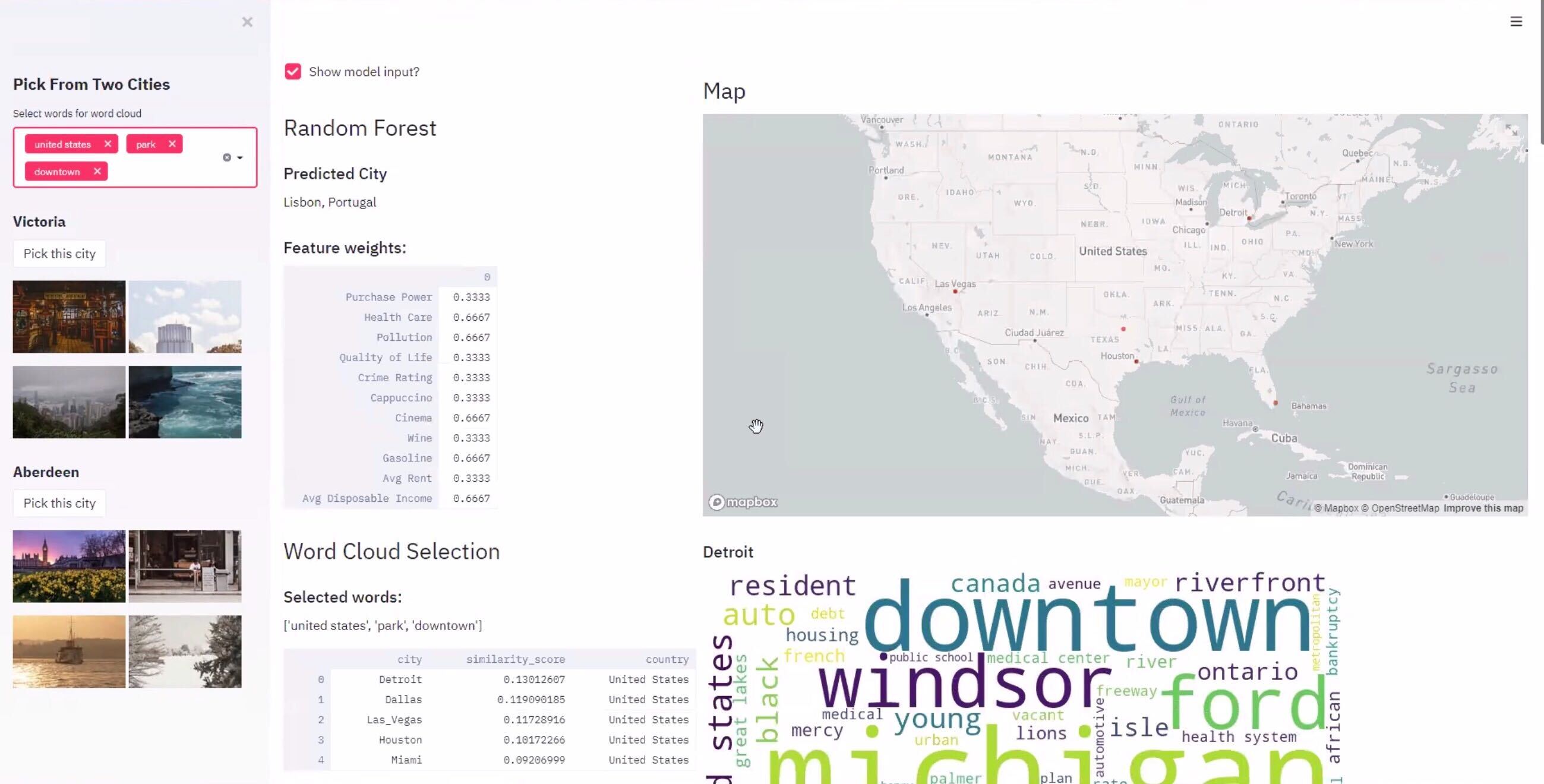
Screenshot of Visualization
-
Team Photo
Inspiration
We were inspired by the streamlined interfaces of mobile phone apps like Tinder that get data on user preferences in a visual and fun way. The gamification of the data gathering makes user more likely to finish it.
What it does
Our project is a survey that only takes in two inputs word cloud keywords and preferred city from two options, each with a set of four representative images. This approach to gathering information from the user to make the survey more engaging and more likely to be completed.
How I built it
The survey and visualizations were built using Streamlit. The Random Forest model was built using the Movehub data set. The TFIDF model was built using NLP, Cosine Similarity, and Wordcloud. Icon made by icongeek26 from www.flaticon.com
Challenges I ran into
The main challenge we ran into was designing a model structure that takes the user input and maps it to a reasonable output. Other challenges we had included handling word imbalance from wikipedia documents and handling the learning curve of Streamlit under the time constraints.
Accomplishments that I'm proud of
We are proud of how well worked extremely well together as a team. We were also proud of the model and visualizations that we have create for our project given the time constraints. We were also proud of how quickly we were able to pick up Streamlit and use it to make visualizations.
What I learned
The two big things we learned were how to use Streamlit and how to integrate learned model knowledge into a real world project.
What's next for Aggie City Matcher
Our next big step is to improve our models accuracy. We would also like to tie in a our results to information on Texas A&M Alumni who live in the cities recommended by the model.
Built With
- gensim
- jupyter
- nltk
- numpy
- os
- pickle
- python
- regex
- scikit-learn
- streamlit
- tqdm
- wordcloud

Log in or sign up for Devpost to join the conversation.