-
-

AgentTweet
-

Converting Data to CSV
-
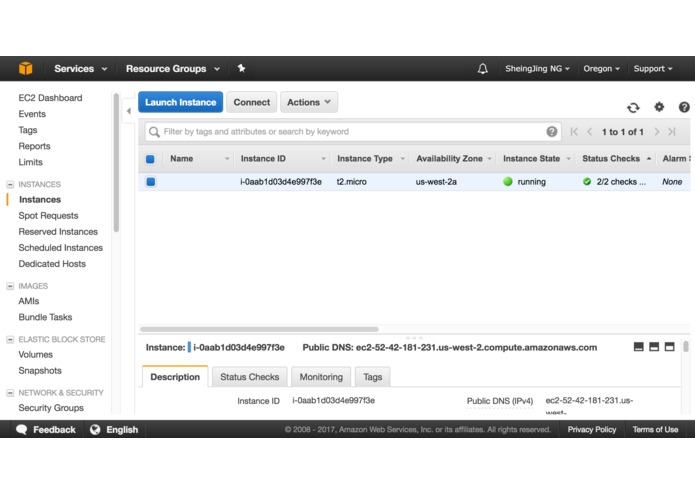
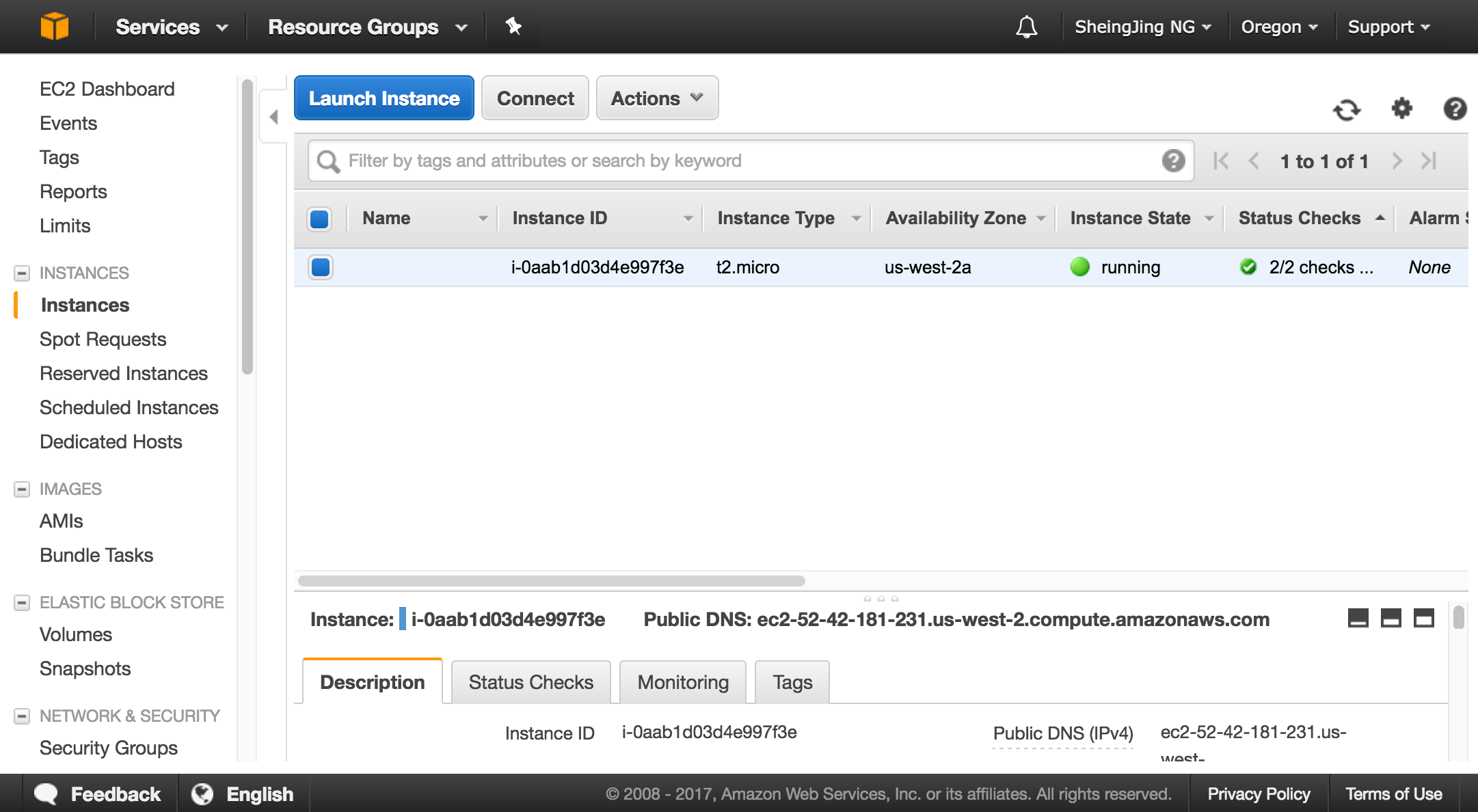
AWS EC2
-

Filter Output to Track Most Follower Account


HACKISU-2017-AgentTweet

What it can do
-Collect instantaneous data from recent feeds (stream with tweepy API) using keywords within a person’s tweet
-Sort collected data by different features (most followers, location, hashtags, terms, etc.)
-Collected data library is stored into Amazon Web Service-EC2 for easy access and downloading
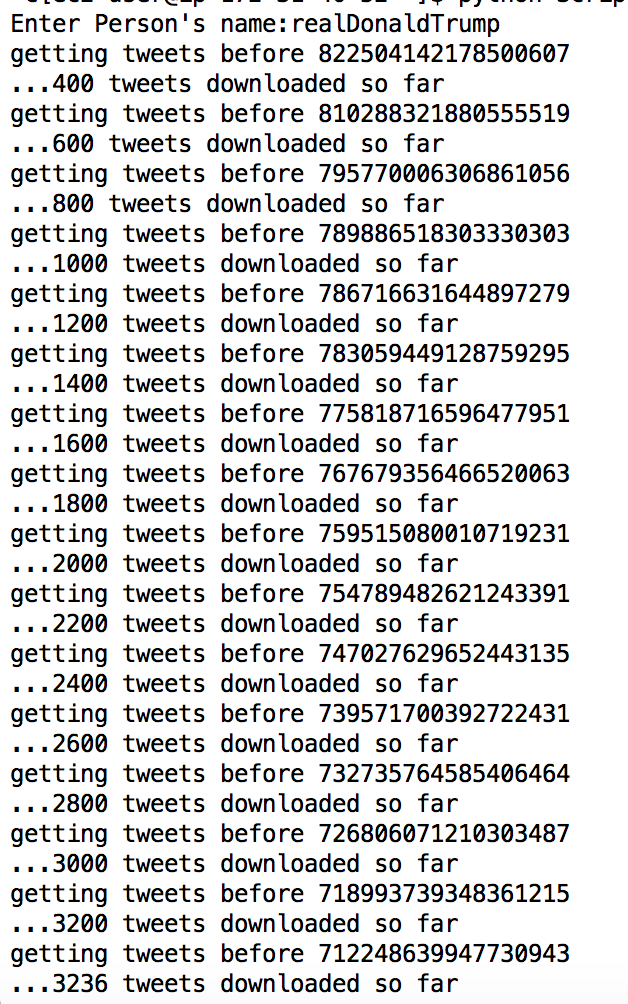
-Convert targeted person's information based on query result to a CSV file (max: 3200 tweets) in less than 5seconds For example: Download realDonalTrump's tweet
-Upload and Download files from cloud using ssh and scp
Why it is useful
-An organized CSV data set can be used for multiple research purposes (e.g: machine learning, surveying, text analysis, etc.)
-Further implementation of text analysis using beautiful-soup and scikit-learn to do sentiment analysis.
-Marketing Campaign and Human Resource recruitment purposes. (e.g: Background Check, Drug Involvement, Professionalism)
-Prevent #Online #Harassment by identifying users that harass others on social media. (Sensitive Keywords)
How we built it
-Language:Python
-Object Notation:JSON
-noSQL: MongoDB
-Cloud Service: Amazon Web Service(EC2)
-Package: Tweepy
-Authentication: Key/Access token auth from TwitterAuth
Setting UP:
Create a new Amazon Web Service account
Start up a new server on
EC2dashboard and select the top "Amazon Linux" option-->General PurposeAt the next prompt, press the "Launch" button.
Connect to your instance using its Public DNS: (e.g: ec2-user@ec2-52-XX-181-231.us-west-2.compute.amazonaws.com:)
sshto your new instance: (example: ssh -i "sheing-pair.pem" ec2-user@ec2-52-XX-181-231.us-west-2.compute.amazonaws.com)
6.IMPORTANT Create a new Twitter app and get your own API keys/access token. Remember to change it in the auth.py and scriptCSV.py.
Getting Started:
Clone Repo #Github.com/Sheing
Open Terminal-->
pip install tweepyorbrew install tweepy(provided you havehomebrewinstalled)Connect to your EC2 server, type
sudo mongod. If it runs successfully, you will see2017-02-26T07:58:33.208+0000 waiting for connections on port 27017Open another window terminal, upload all python files to your own EC2 server using
scp: (e.g: scp -i "sheing-pair.pem" hackISU.py ec2-user@ec2-52-XX-181-231.us-west-2.compute.amazonaws.com:)Run the HackISU2017.py using this command: python HackISU2017.py4. If you see the terminal showing Connection Successful! and loading a bunch of numbers! Congratulation! It is collecting twitter streaming feeds to your database.
After collected enough amount of data, press:
CTRL-Cto stopGo to mongoShell by command>>
mongo, -->show dbs-->use xxx_database(you should change the database name in py file at line 36)Use mongdoDB query in the
Query.txtfile to experiment--> (e.g: People that recently posted about HACKISU: db.posts.find({"text": /hackisu/}))After querying, if you want the targeted person's full information dataset. RUN hackCSV.py
Enter that person's screen name on promt based on your query result. [File will be automatically downloaded in less than 5 seconds]
FINAL STEP To display csv file. exit mongoShell--> type> cat sheing.csv. DONE! You can easily download the csv file from server to your directory using scp.
Challenges I ran into
Building a user-friendly interface --Due to time constraint, we were unable to figure out how to convert python-mongodb to a more interactive interface.
Setting up Amazon Web Service with limited guidance --It is hard to set up cloud service that integrates python and mongodb.
Streaming too many results might resulted in broken pipelines --When excecuting the python file to collect data, heavy data might potentially break the connection pipelines.
Accomplishments that I'm proud of
--Able to collect streamed data instantaneously
--Query those data with what I want based on available features
--Able to track down that individual's location coordinate
--Efficiently convert targeted person feed into csv.
What's next for AgentTweet
--Integrating all these into a user friendly interface or make it as an app.
--Collaborate with companies that requires data mining on twitter, e.g: Health Care Provider, Marketing and Advertising Company.
--Upgrade to a bigger cloud server


{kind=link}
Log in or sign up for Devpost to join the conversation.