-
-

AgentRX
-
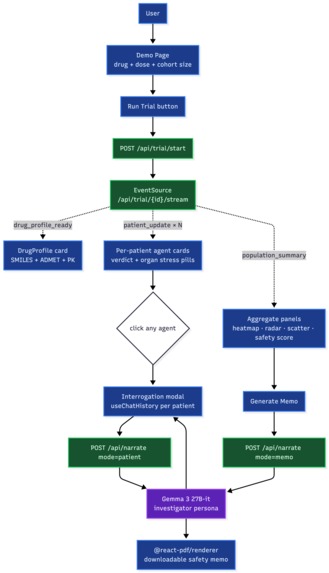
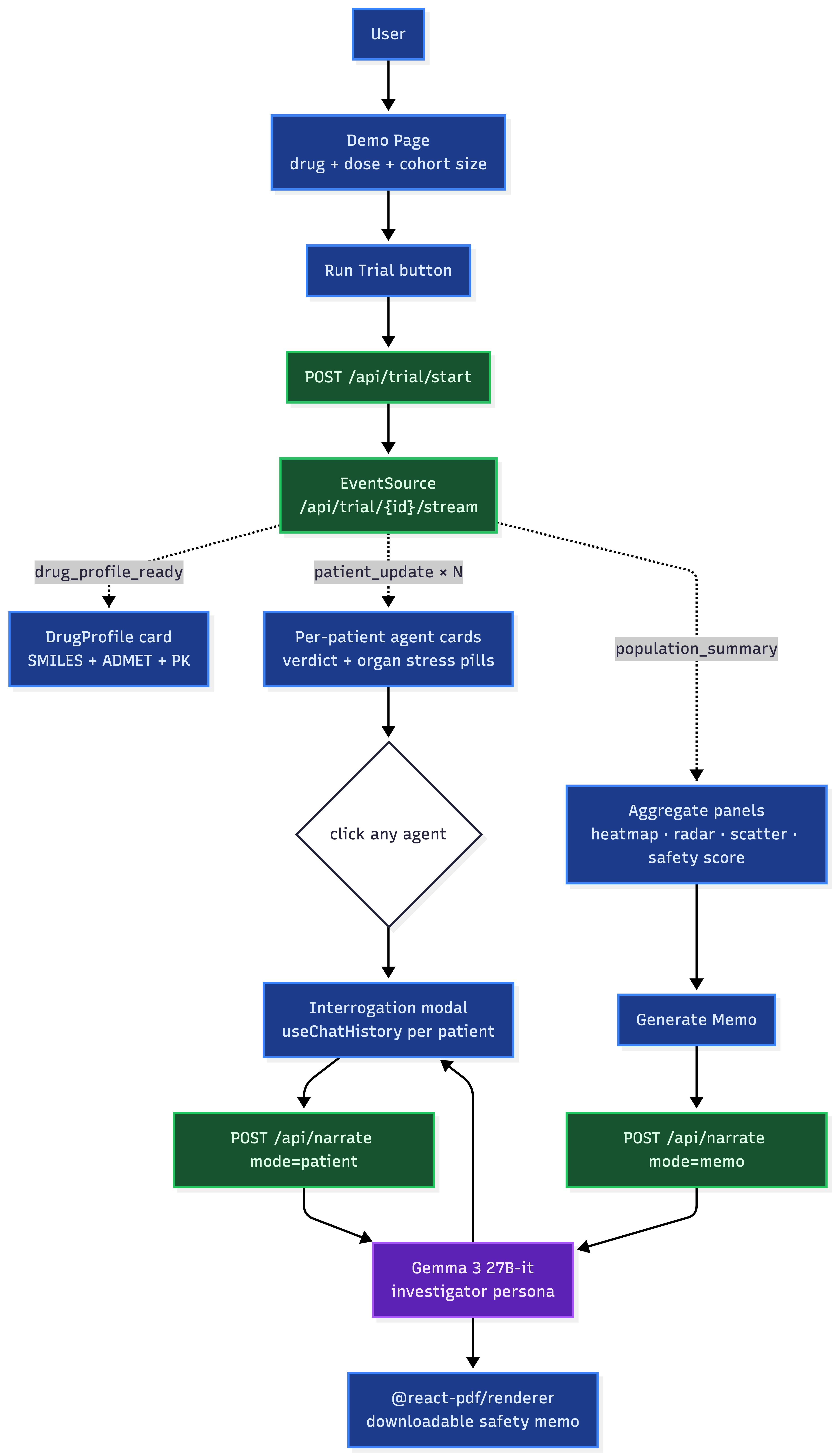
Product Demo Pipeline
-
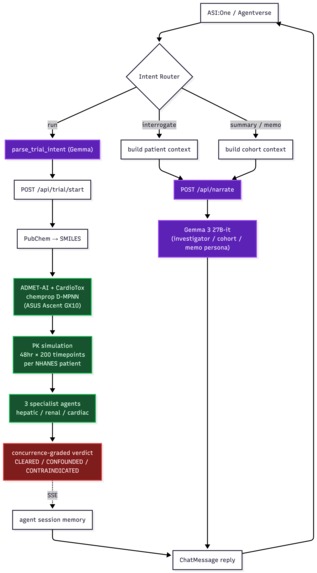
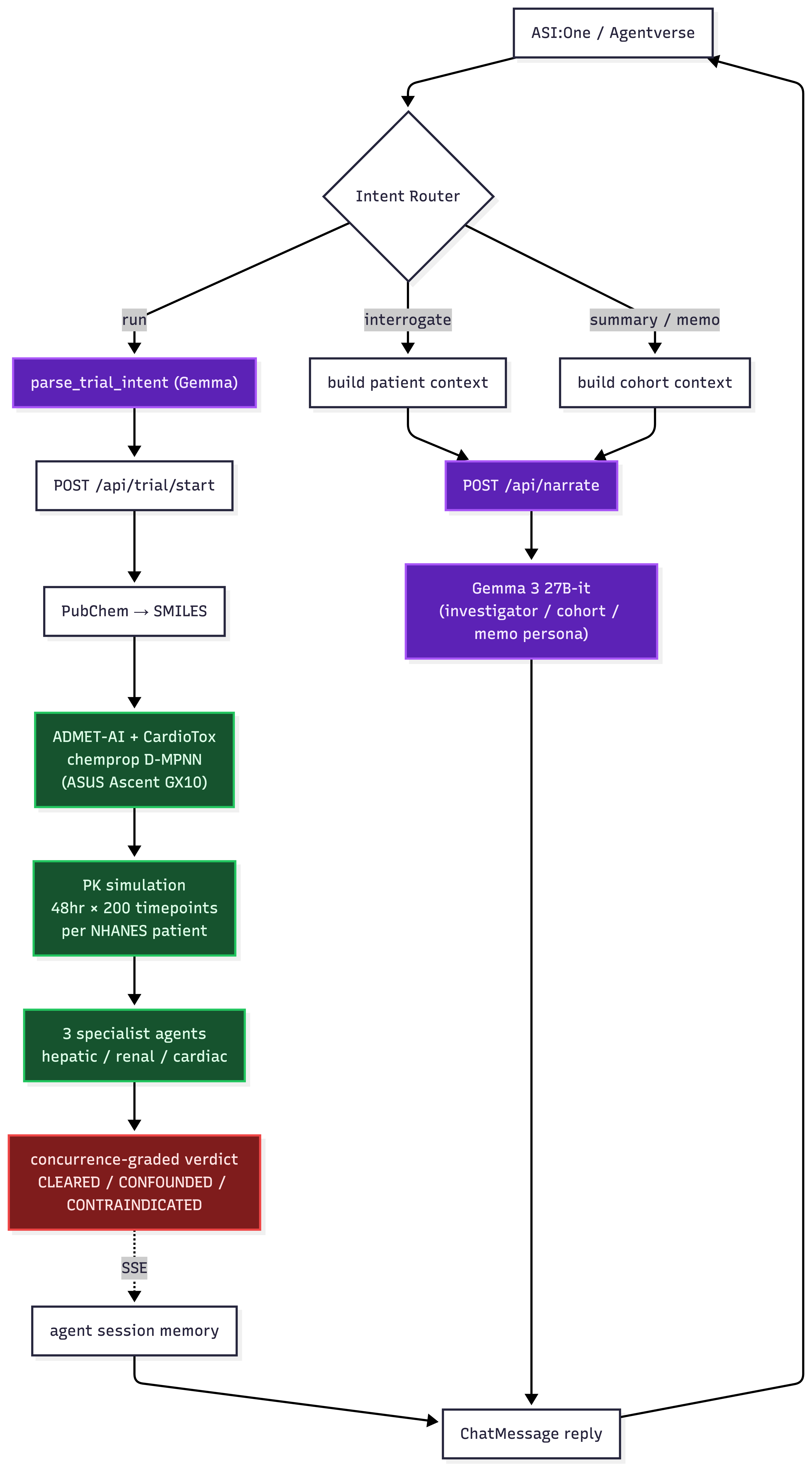
Fetch AI Pipeline

Inspiration
Clinical trials fail 90% of the time, often due to safety signals that could have been spotted sooner. AgentRX is a digital twin orchestration platform that de-risks Phase I trials before the first patient is even dosed.
What it does
We simulate drug responses across as many human biology profiles as required to find risks and help make human trial decisions, before the drug is tested on a real human.
By grounding a NHANES-derived virtual cohort in real chemical-structure-based toxicity models (ADMET-AI), we run a virtual Phase I trial in minutes instead of weeks. Each patient is evaluated in parallel by a panel of specialist agents that score per-organ stress over a simulated 48-hour observation window. Verdicts grade out as CLEARED, CONFOUNDED, or CONTRAINDICATED based on concurrence across organ systems, not a single failing endpoint.
We also host the result on Fetch.ai Agentverse (@agentrx) as a chat agent: ask it to run a trial, interrogate any flagged subject through an investigator persona, or generate a dose-escalation memo. It gives a full Phase I review committee in under a minute. Link to a fetch.ai specific demo is here: demo
Lastly, Gemma 3 27B is the only LLM in our stack, and it does two distinct jobs:
- structured extraction (parsing {drug, dose, cohort size} out of natural language so the agent can call the simulator)
- cohort summaries + dose-escalation memos
Every Gemma call is funneled through a single /api/narrate endpoint, and the model never speaks unless we hand it real simulation data first. This keeps the investigator agent honest instead of hallucinating symptoms that the simulator never produced.
How we built it
Fetch.ai uAgent + Google Gemma 3 27B-it + ADMET-AI, and built with ASUS Ascent GX10
To simulate human biology, we have to ground predictions in real biological data and models. Under the hood, every drug gets resolved through PubChem and fed into ADMET-AI running on the ASUS Ascent GX10 to produce real toxicity predictions for liver, hERG, and CYP3A4. We then simulate a 48-hour pharmacokinetic curve per patient using NHANES-derived demographics and CKD-EPI-2021 kidney function, and three specialist agents (hepatic, renal, cardiac) score per-organ stress over that window using a sigmoid anchored to a per-drug reference exposure, which is what lets the model generalize to any drug at any dose without retuning. Each patient's three peak stresses map to
risk levels, and the final verdict is concurrence-graded (CLEARED, CONFOUNDED, or CONTRAINDICATED). The FDA-style rule is that one isolated organ blip shouldn't auto-fail a subject, but two should. The agent streams verdicts back into its session memory as the trial runs, so follow-up interrogations can dig into any specific patient's labs, organ curves, or reported experience.
We offloaded ADMET-AI's chemprop D-MPNN inference onto the ASUS Ascent GX10 because the multi-task model, which was predicting hundreds of toxicity endpoints across our calibration sweeps of drug × dose × patient combinations, was too heavy for our Mac's resources. Additionally, we used the ASUS Ascent GX10 to run our PKSmartAdapter on drugs for our demo to speed up inference for our Mac at runtime.
Challenges we ran into
Simulating biology at scale is not trivial, and the biggest bottleneck was the compute + realism tradeoff.
The hardest part of a clinical-AI system isn't the ML. It's the layer between raw model outputs and a useful clinical signal. We also learned that an "AI agent" feels like a chatbot until you give the LLM grounded jobs and let the agent layer do everything else, which we believe is the difference between a demo and a tool.
We were able to overcome this by using research and data backed models.
Accomplishments that we're proud of
Every patient is evaluated twice (control + treatment), which mirrors real clinical trial design and makes the system far more credible than a single-pass model. Using agent-based orchestration, we simulate an entire cohort in parallel instead of sequentially, enabling near real-time evaluation. Users can click into any patient and ask follow-up questions about the decision. This turns the system from a black box into a decision support tool.
What we learned
Biology stuff /pharma
What's next for AgentRX
Test against larger, real datasets to benchmark accuracy against known clinical outcomes.
Built With
- agentverse
- fetch.ai
- gemma
- python




Log in or sign up for Devpost to join the conversation.