-
-
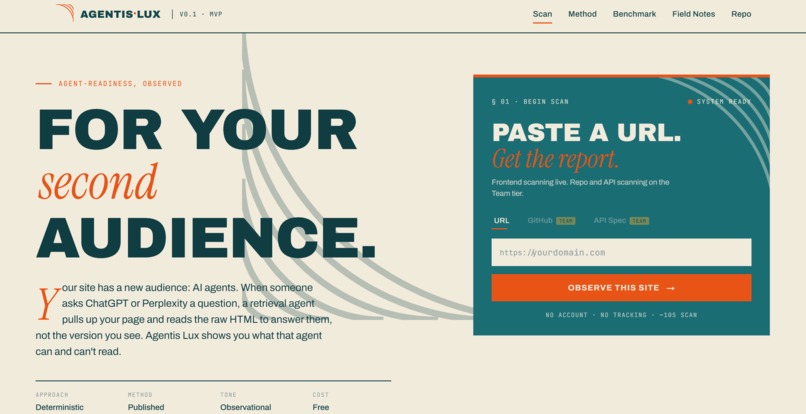
Agentis Lux (AL) Landing Page
-

Scorecards on agentislux.io website
-
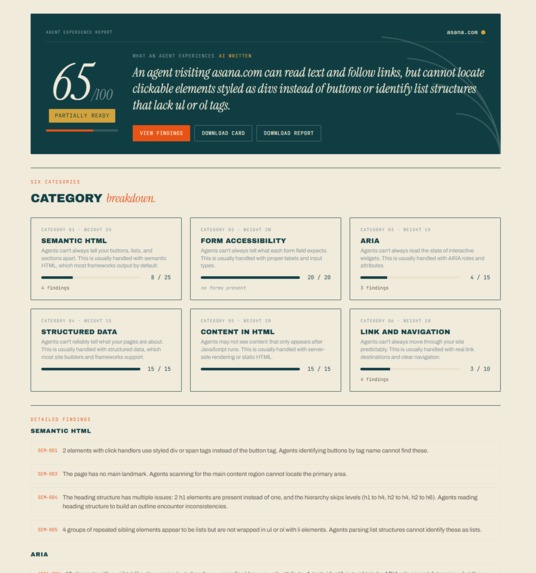
Agentis Lux Report
-
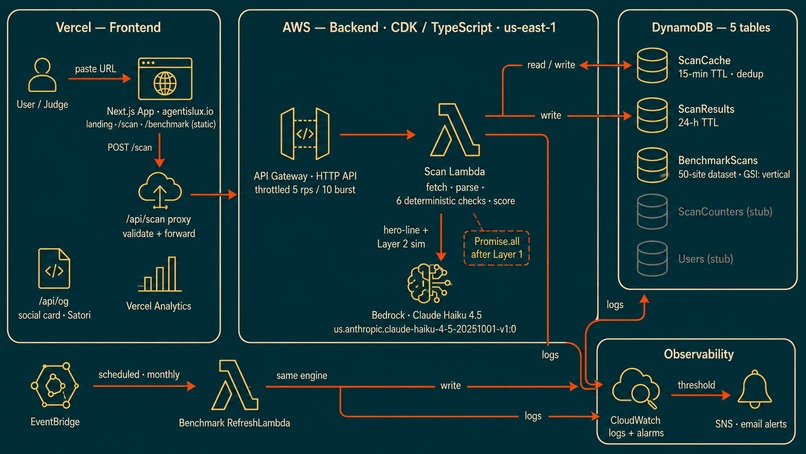
AL Architecture
-
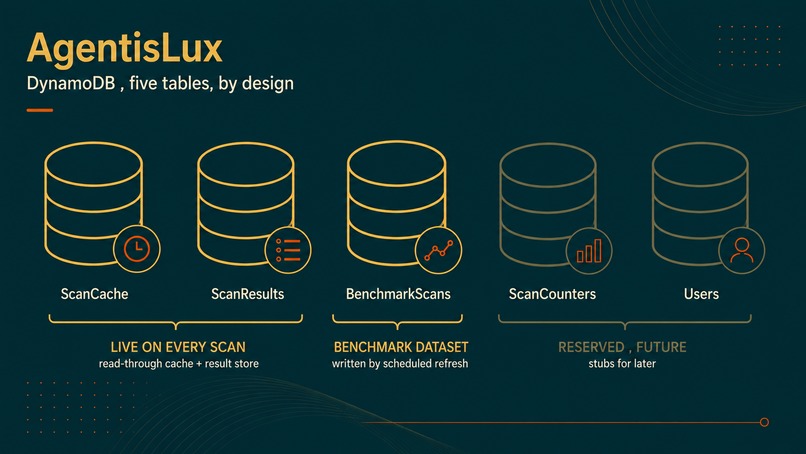
Dynamo DB
-

DynamoDB Data Model
-
DynamoDB AWS Console
-
ScanCache Table DynamoDB AWS Console
-
50 site benchmark
-

Agentis Lux Scan Steps
-
Project Structure
-

Can a robot read this?



Inspiration
The spark was a comment. At a hackathon, a you.com employee said the thing out loud: the web has a second audience now. Retrieval agents like ChatGPT, Perplexity, and Google's AI Overviews fetch pages by the million, read the HTML, and decide what a page is about. Most of them don't run your JavaScript, so they often see far less than a person does. And almost no one is building or testing for that reader.
That comment sent me to build. My first answer to it was Hermes Clew, for the GitLab Duo Agent Platform Challenge. Hermes lived inside GitLab Duo Chat with no frontend and no database: a Python engine that scanned the HTML, JSX, and TSX files in a repo, scored them across six categories of agent-readiness, and had an LLM reason over the findings. It proved the core idea, deterministic scan plus AI reasoning, but it was repo-bound, it told developers how to fix things, and it lived inside one vendor's chat.
Agentis Lux is not a re-skin of Hermes. It is the idea taken to the open web and rebuilt with a different stance. It scans any live URL, not just files in a GitLab repo. It runs as its own product on a real cloud architecture, not inside a chat window. And it deliberately drops fix suggestions: Hermes told you what to fix, Agentis Lux only tells you what an agent experiences, because suggesting a fix implies I know your codebase and I don't. Same six-category bones, a new body and a sharper philosophy.
Accessibility and agent-readiness overlap, semantic HTML, real labels, ARIA roles, structured data, so building for a screen reader moves you toward building for an agent. But agents are their own audience with their own needs, not a subset of the accessibility one. The tools hadn't caught up. So I built the one I wanted.
What it does
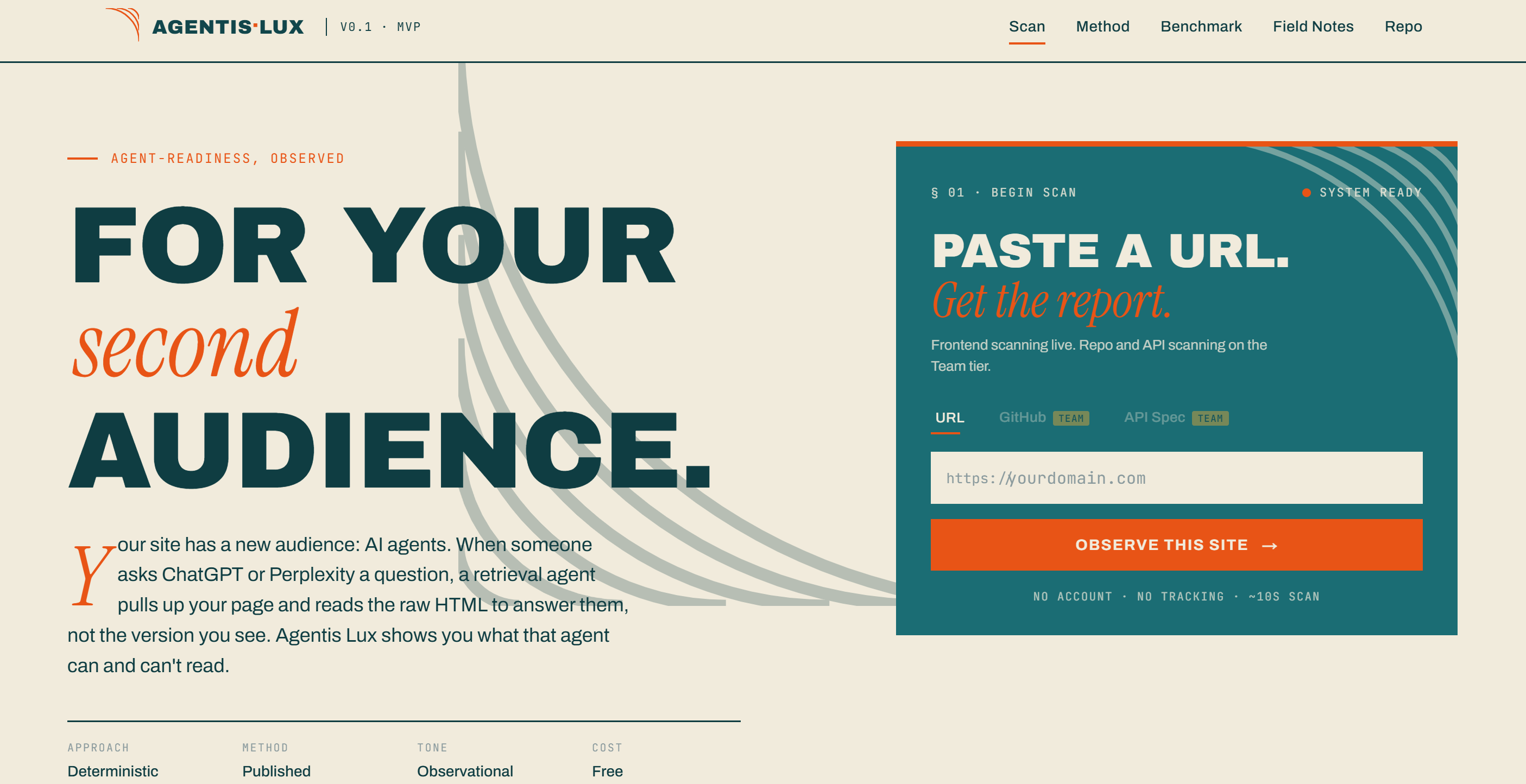
Agentis Lux scans your site and shows you what a retrieval agent experiences when it tries to read it. You paste a URL. You get a report.
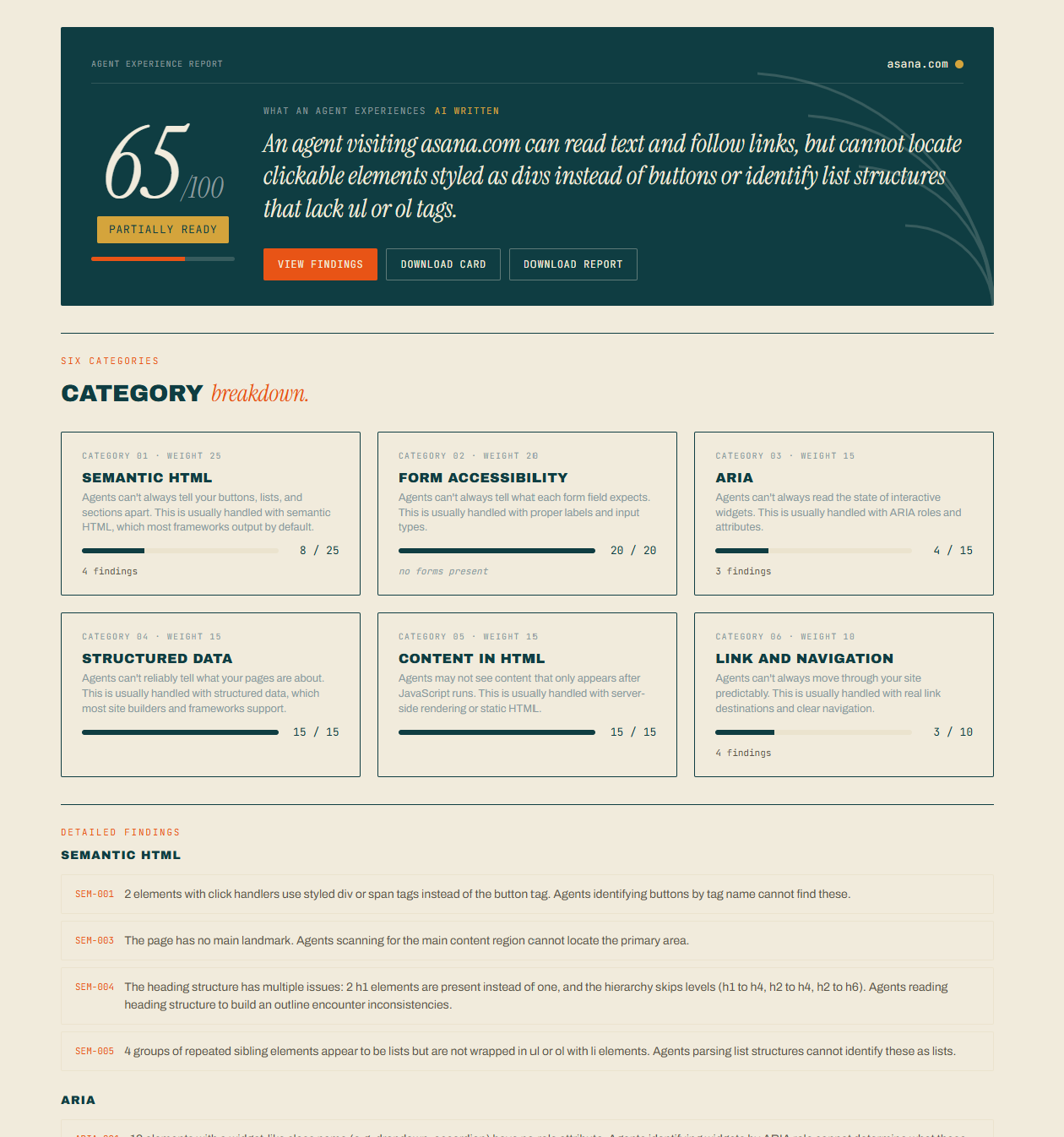
The report is written from the agent's point of view. Not "this is broken," but "an agent landing on this page can't tell which element starts checkout, because it's a styled div and not a button." It reports findings. It does not suggest fixes, on purpose. I know what the agent sees, not what you should change. That is the value: visibility, and you decide what to do with it. Awareness, not judgment.
Six deterministic checks score the frontend out of 100:
- Semantic HTML (25)
- Form accessibility (20)
- ARIA and accessibility (15)
- Structured data (15)
- Content in HTML (15)
- Link and navigation (10)
A parallel set of six API checks runs on the backend and powers the benchmark.
How I built it
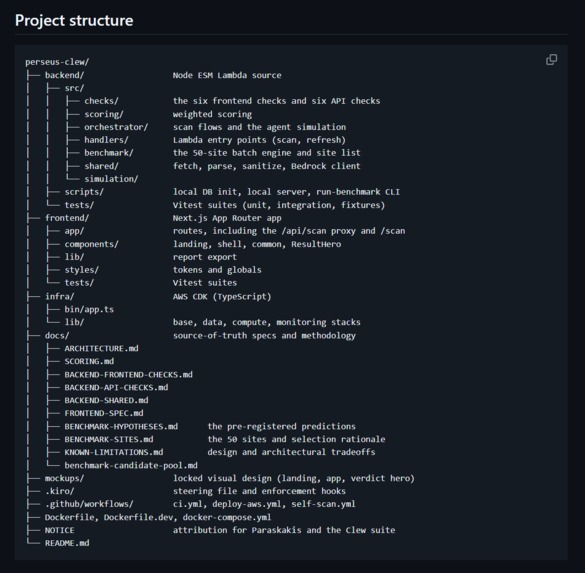
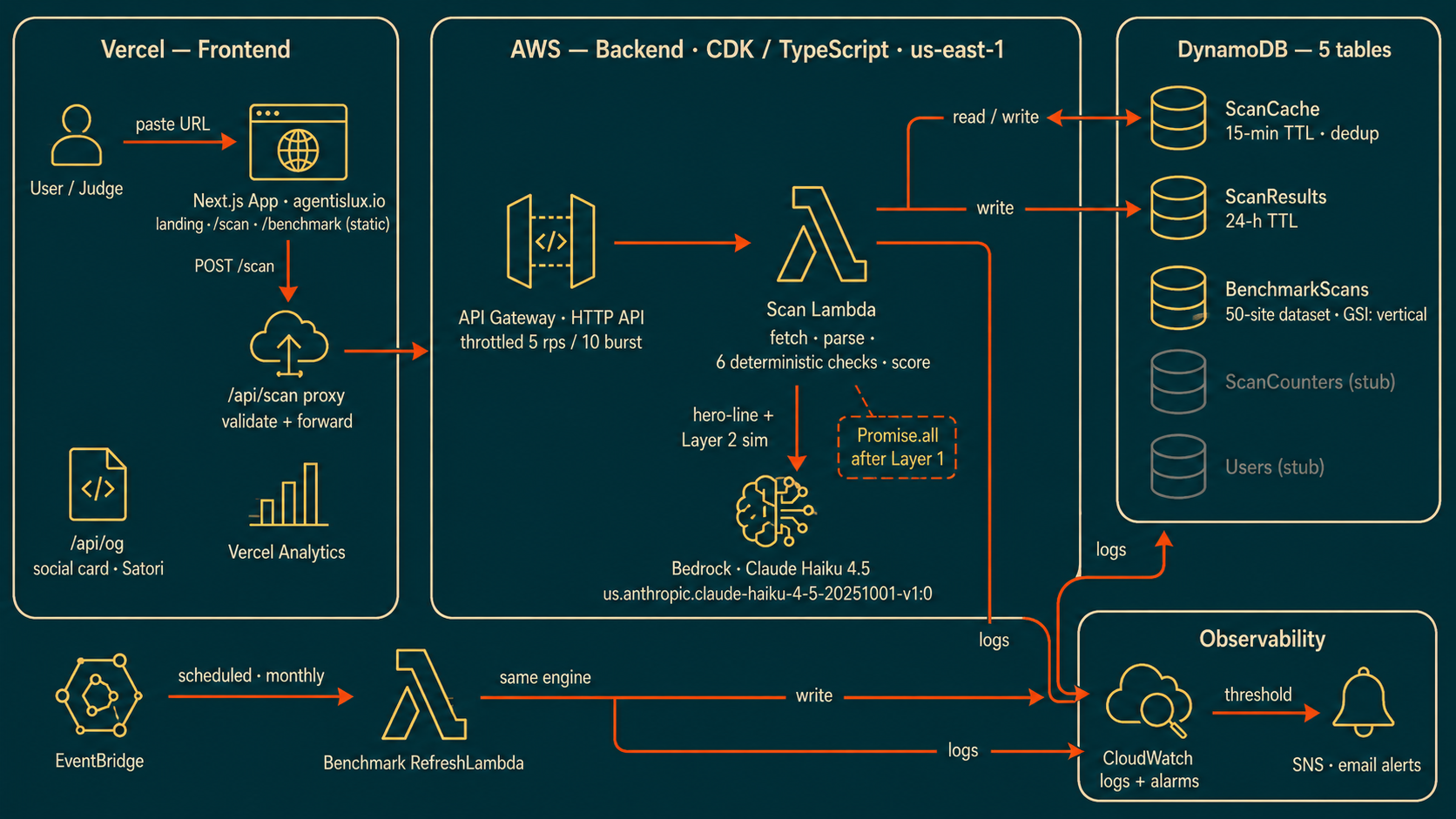
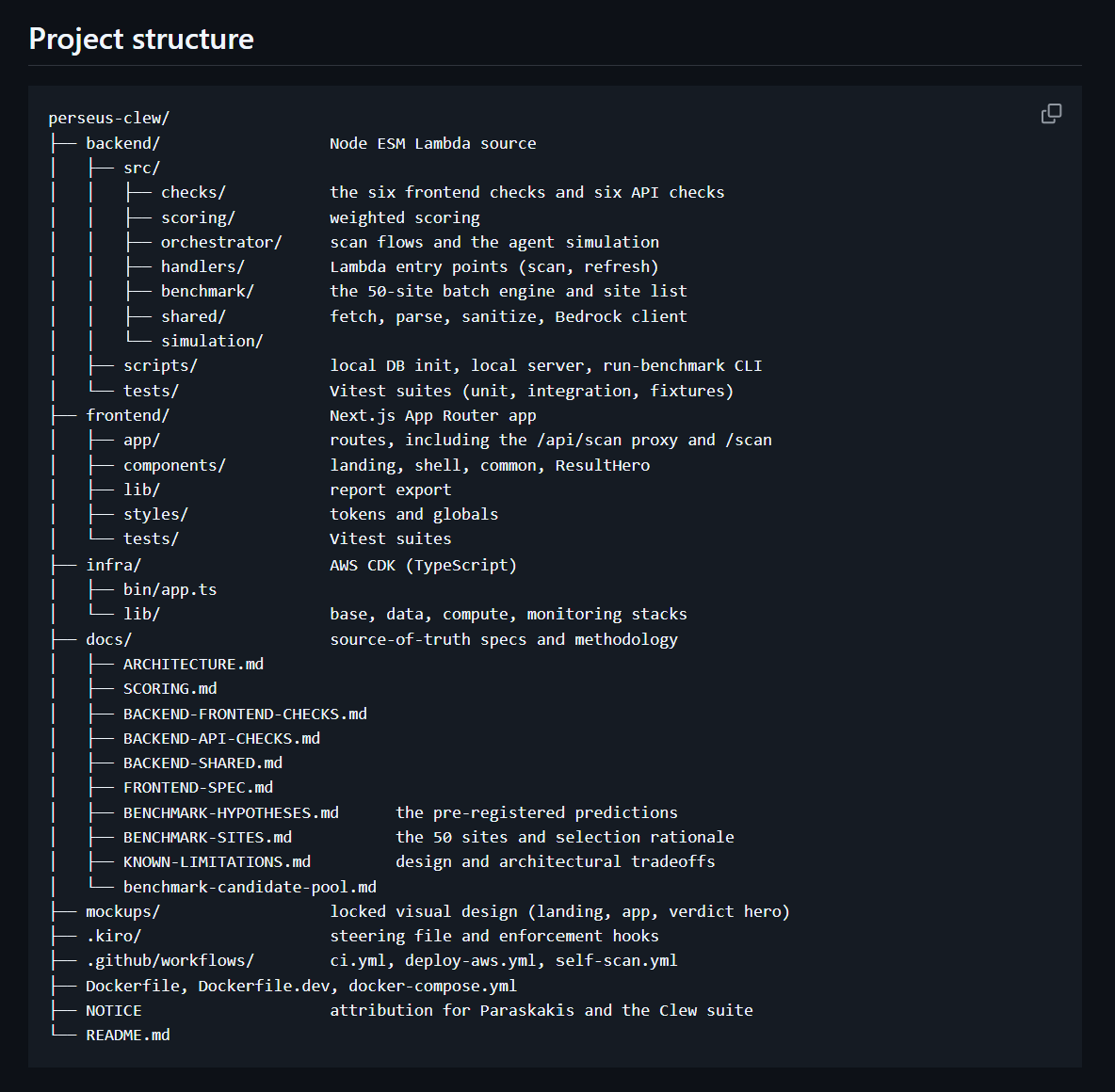
Built for H0 Track 2 as a monetizable B2B app on Vercel and DynamoDB: deterministic scoring, a cache-first scan path, and benchmark data designed around explicit DynamoDB access patterns.
The whole thing runs on the hackathon stack: a Next.js frontend on Vercel, an AWS backend, and Amazon DynamoDB as the data layer. The AWS Databases and Vercel integration was built during the submission window.
One idea runs through the architecture: the structure is deterministic, the flavor is AI. Same input, same score, every time. The checks and the scoring are pattern matching, no model involved. AI is used in exactly two places where a regex can't help. A Bedrock call (Claude Haiku 4.5) writes the one-line plain-language verdict, and a second Bedrock layer runs an agent simulation: it reasons about what a retrieval agent would experience on the page and reports what it could and could not accomplish, not an autonomous agent acting on the page. Math stays math, so you can trust the number. Language and simulation are AI, because that is where judgment adds value.
The AI is constrained, not creative. Low temperature, capped tokens, and a system prompt that encodes the product's own rules: no fixes, no judgment words, no em dashes. The simulation returns structured JSON, and any finding it references is filtered against the deterministic findings, so the model can't invent something the math didn't catch. If it fails validation, it falls back to a template. Math for trust, and the AI is fenced into exactly the two jobs where judgment helps.
The stack:
- Frontend: Next.js (App Router) on Vercel, with an
/api/scanproxy route. The benchmark page serves a published static snapshot. - Backend: AWS Lambda as a Docker image, behind an API Gateway HTTP API, in us-east-1.
- AI: AWS Bedrock, Claude Haiku 4.5, for the verdict line and the agent simulation.
- Data: Amazon DynamoDB.
- Refresh: EventBridge, monthly, to rescore the benchmark dataset.
- Monitoring: CloudWatch metrics and alarms wired to SNS.
- Infrastructure: AWS CDK in TypeScript, four stacks.
Why DynamoDB, and how I used it
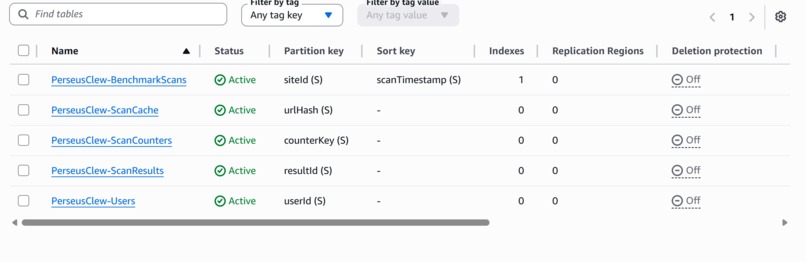
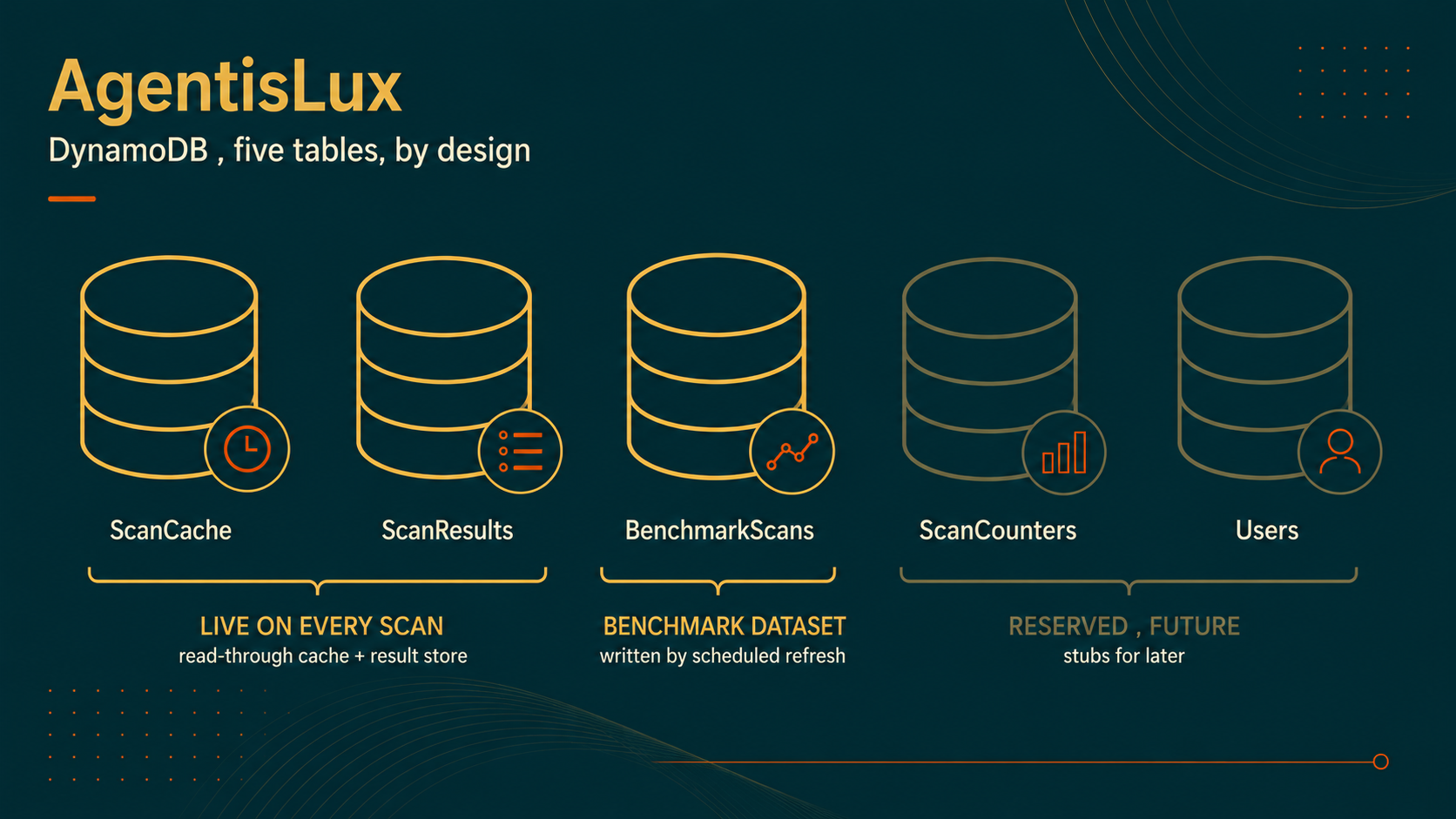
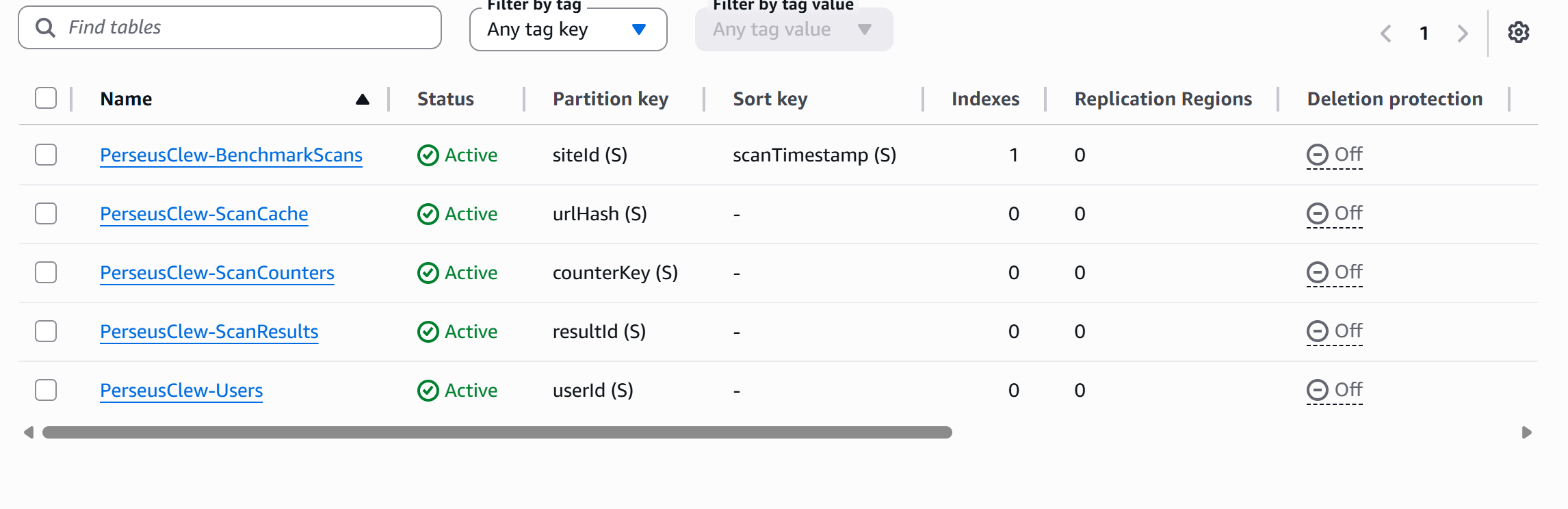
DynamoDB is the back end, and I tried to use it as a deliberate data model rather than a key-value afterthought. Every access pattern in this product is a single key lookup, which is exactly what DynamoDB is built for. Five tables, each with one job:
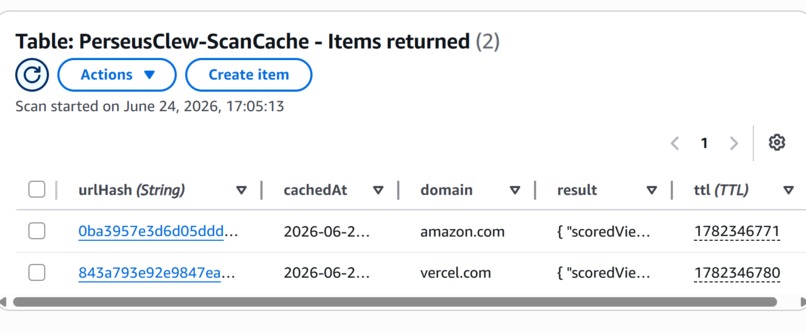
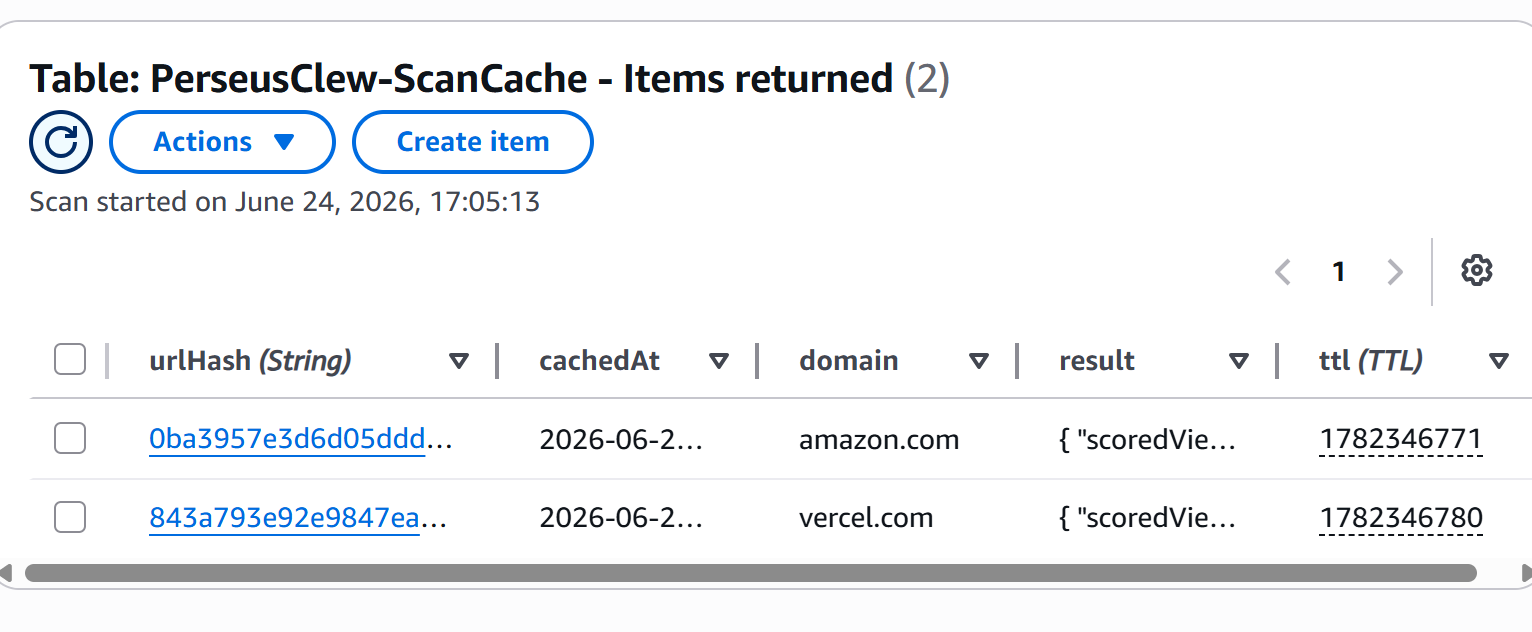
- ScanCache: 15-minute TTL, keyed by a hash of the URL, to dedupe target fetches and keep Bedrock cost down.
- ScanResults: 24-hour TTL, keyed by an opaque result id, anonymous, for scan results that expire on their own.
- BenchmarkScans: the 50-site dataset, partitioned by site with a sort key on scan timestamp and a GSI on vertical, rewritten monthly by the EventBridge refresh.
- ScanCounters: server-side scan counts, no PII. Reserved for the team tier.
- Users: reserved for signed-in history. A stub for the team tier.
Of the five tables: two are live on every scan (ScanCache, ScanResults), one holds the published 50-site benchmark dataset written by a scheduled refresh (BenchmarkScans), and two are reserved stubs for the v2 team tier (ScanCounters, Users). Two TTLs, two lifetimes, two reasons. Per-vertical rollups use the GSI, not a second database. No joins, no schema migrations, no idle server. The write on a live scan is fail-soft and async: the scan returns to you whether or not the write lands, and a failed write goes to CloudWatch instead of your screen. The scan result is the product. Persistence is a side effect.
The product is Agentis Lux. The engine is Perseus Clew, part of my Clew suite of developer tools, which is why the AWS resources carry the PerseusClew prefix.
The benchmark, and a bet I made in public
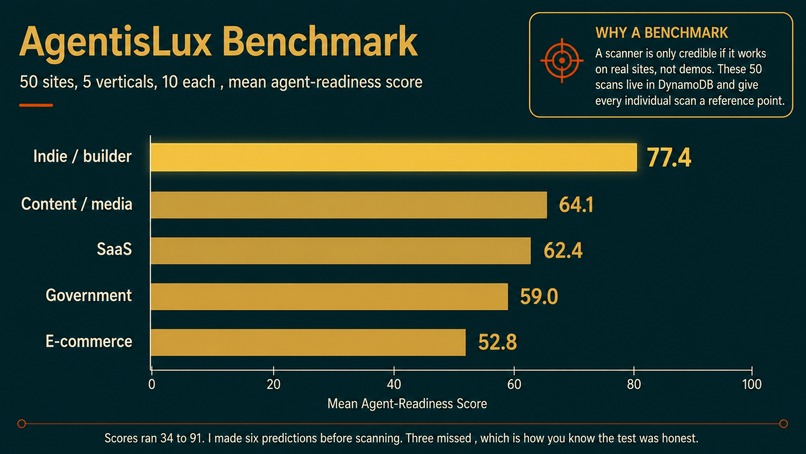
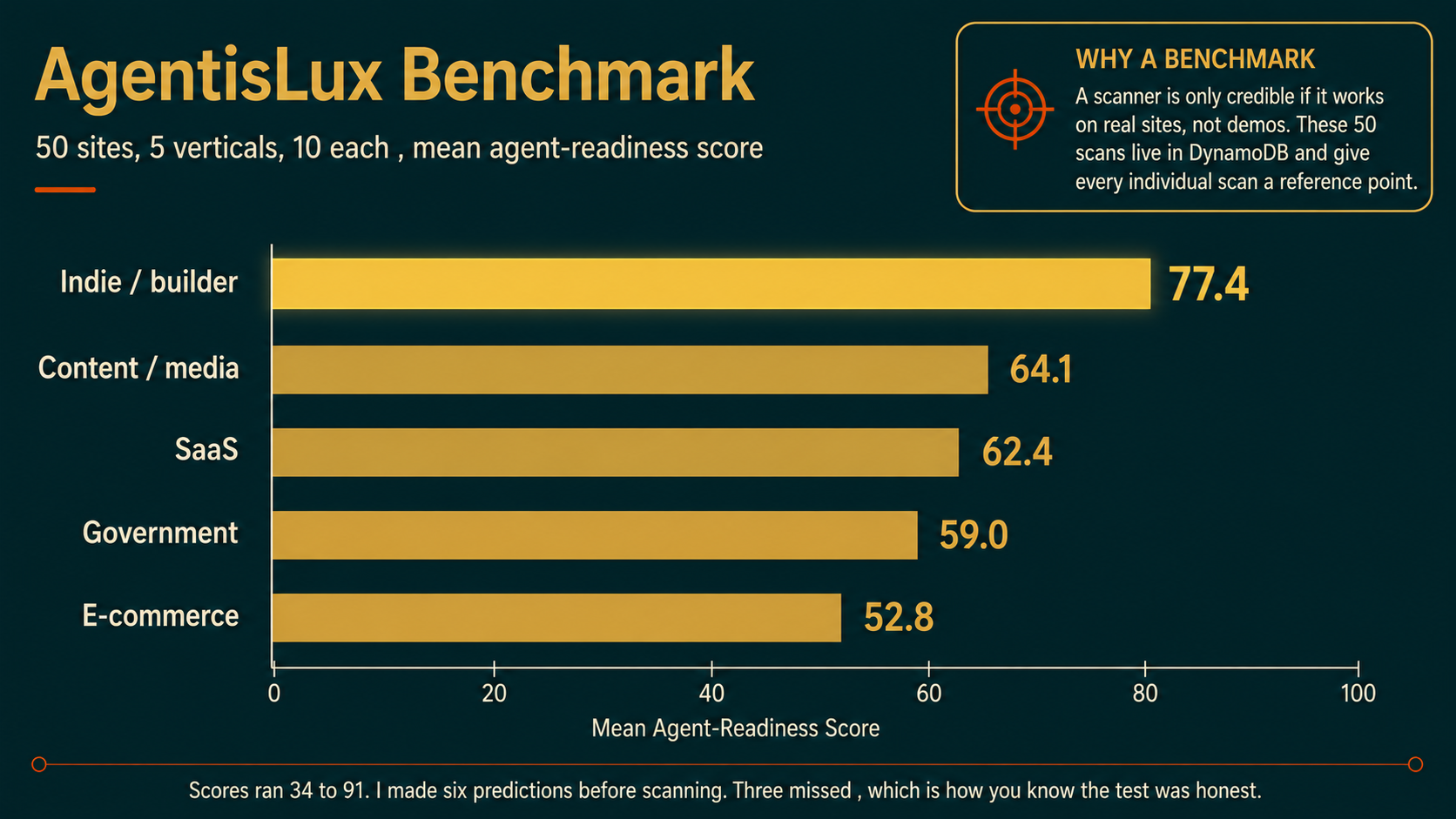
Before the engine scanned anything, I wrote down what I expected it to find across 50 sites and committed it with a timestamp. Predictions first, data later.
Then I scanned them: ten each in e-commerce, SaaS, content and media, US government, and indie builder projects. Indie builders scored highest, a mean of 77 out of 100, ahead of government, SaaS, and e-commerce. Scores ran from 34 to 91. Four sites blocked the scan at the door, including OpenAI. I missed three of my six predictions, which is the point of pre-registering them. The full dataset, including the sites that blocked me, is published in the repo.
Who it's for, and the business model
Agentis Lux is built for teams who ship and maintain multiple web products and APIs: the people who need to know what AI agents experience across all of their public surfaces, not one page at a time. The free tier scans a single site's frontend. It is the front door: no account, instant result, shareable. It exists to get the tool in front of the people who will pay for it.
The paid team tier is where the B2B value lives: API spec scanning in the product (the engine already scans API specs, it scored the APIs in the benchmark, but it is not yet team-facing), combined frontend-plus-API scoring, multi-domain and shared team reports, scheduled rescans with trend tracking over time, and report history. The free tier proves the engine works and earns the trust; the paid tier serves the team that needs it at scale.
On the landscape (because I did my homework)
Agentis Lux reads what a retrieval agent reads: the raw or minimally rendered HTML, before any JavaScript runs. Many retrieval agents rely on that surface rather than a full browser render. That is its lane, agent operability on the retrieval surface. It is not alone in caring about agents:
Scrunch (acquired by Sitecore) works on AI search visibility: whether your brand gets cited when someone asks an AI. That is about being found. Agentis Lux is about whether an agent can read and use what it finds. Visibility, not operability.
Google's experimental Agentic Browsing audit in Lighthouse (May 2026) checks the agent-as-actor surface: WebMCP and whether a browser-driving agent can operate your page. Agentis Lux goes deeper on the agent-as-reader surface, the raw HTML a retrieval agent forms an impression from before it ever acts. Different door.
The agentic web is new enough that Google only added experimental, unscored agent-readiness checks two months ago. That is evidence the lane is open. The API scan is a second axis nobody in the visibility crowd touches.
Challenges I ran into
Fetching arbitrary user-supplied URLs on a public endpoint is a security problem before it is a feature. The backend does full DNS resolution and blocks private and reserved IPs, validates every redirect hop, forces HTTPS, and caps size and time. That hardening took as long as some of the checks did.
Bedrock had to be allowed to fail. If the model is slow or errors, the report still has to render. So the AI-written verdict has a deterministic template underneath it as a floor. The hero line never breaks, because the score under it was never AI in the first place.
And the part I will not paper over: this is a solo build on a deadline, and I would rather name the gaps than have you find them. The backend is JavaScript, not TypeScript. The public benchmark page serves a published snapshot rather than querying DynamoDB live. The results view still has heading-hierarchy work. All of it is written down in KNOWN-LIMITATIONS.md, as choices, with reasons. On a product whose whole thesis is readability, hiding the gaps would be the one move I could not make.
Accomplishments that I'm proud of
A few things held up better than I expected for a solo build on a deadline.
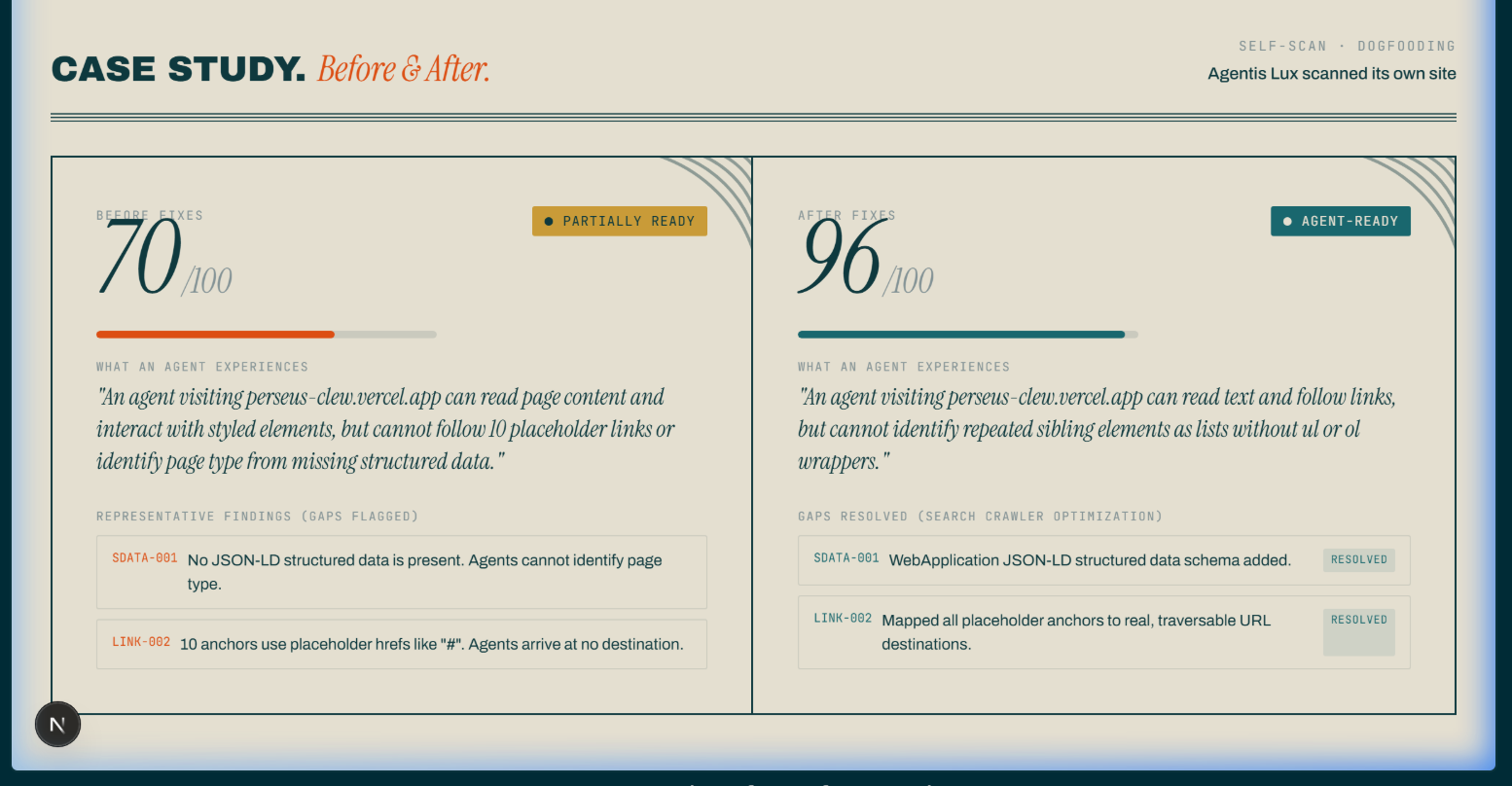
The engine is honest about itself. Agentis Lux scans its own site and publishes the result: 70 to 96 after I fixed what it found, with one finding still open and shown anyway. I would rather show a real 96 than a scrubbed 100.
The benchmark is real and pre-registered. I committed six predictions with a timestamp before scanning 50 sites, then published the full dataset, including the four sites that blocked me. I missed three of six, and the misses were the interesting part.
The AI is governed, not bolted on. Low temperature, capped tokens, a system prompt that encodes the product's own rules, and a simulation whose findings are filtered against the deterministic pass so the model can't invent something the math didn't catch. The score never touches a model.
It passed its own bar. The landing page scores 100 / 95 / 100 / 100 on Lighthouse, and 2 out of 2 on Google's experimental Agentic Browsing audit, which checks the exact thing Agentis Lux measures.
What I learned
Determinism is the trust anchor. Fix nothing, rescan, and the score doesn't move. That is what makes tracking a score over time mean anything, and it is the thing an LLM-generated score can't promise.
I also learned where AI earns its place and where it doesn't. The deterministic core is free to run at any scale, so the free tier can stay free. I only spend model budget on the sentence and the simulation, the two places a human actually reads. That is the unit economics, and it fell out of the architecture rather than a spreadsheet.
And I learned to be wrong on the record. Missing half my benchmark predictions was more interesting than getting them right would have been.
What's next
The engine already scans API specs. That is how the benchmark scored APIs. Bringing repo and spec scanning into the UI is the next tier. After that: live benchmark querying, score history for signed-in users, and eventually a render mode that shows the delta between what a non-JS agent sees and what a JavaScript-capable one sees. The second audience is not one reader. It is a spectrum, and the interesting output is the gap.
Built solo, block by block. The tool scans its own site and publishes the result: 70 to 96 after fixing what it found, with one finding still open and shown anyway.
For your second audience.
Live: https://agentislux.io Code: https://github.com/earlgreyhot1701D/perseus-clew
Created for the H0 Hackathon (Vercel + AWS Databases), Track 2 (Monetizable B2B).
AI assisted. Human approved. Powered by NLP.
Built With
- amazon-bedrock
- amazon-cdk
- amazon-cloudwatch
- amazon-dynamodb
- amazon-eventbridge
- amazon-sns
- api-gateway
- aws-lambda
- claude
- docker
- github-actions
- javascript
- next.js
- node.js
- react
- typescript
- vercel
- vetest

Log in or sign up for Devpost to join the conversation.