Inspiration
We spend a lot of time in DFIR staring at forensic images. Running the same triage commands, mentally stitching timelines together, and forming hypotheses we then test manually with yet more commands. The cognitive load isn't the individual tool invocations; it's holding the full investigative context in your head while deciding what to run next and interpreting what came back.
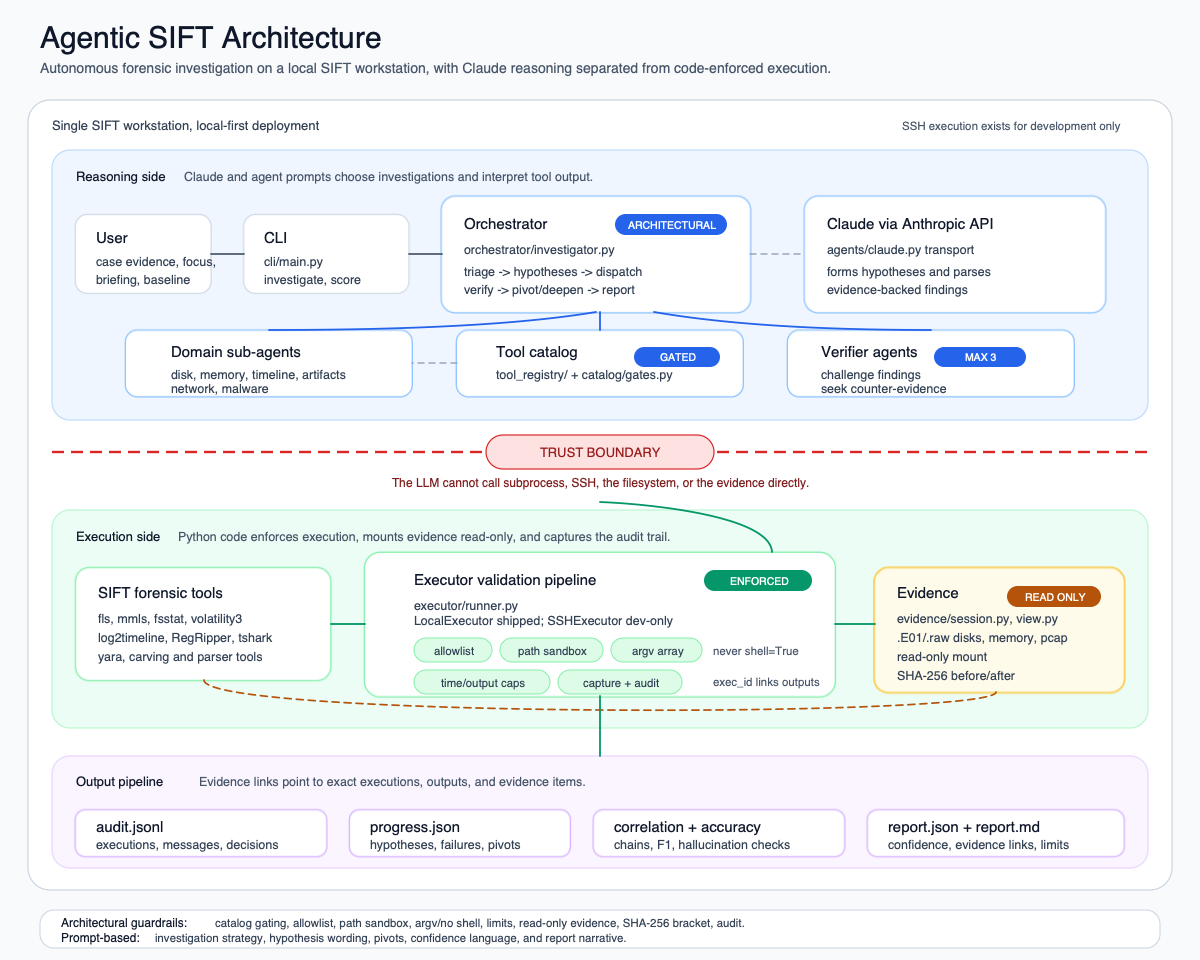
The thought was simple: what if the LLM handled the "what to investigate" and "how to interpret" parts, while the code enforced "what's allowed to run" and "what tools exist"? Not an AI that replaces the analyst, but one that operates like a junior investigator you can point at an image and say "go find evil." Hypothesis-driven, self-correcting, and fully auditable.
The SANS Find Evil! Hackathon (Apr 15 – Jun 15, 2026) gave us the deadline we needed to stop talking about it and actually build it.
What it does
AgenticSIFT is a Python CLI orchestrator that drives Claude (via the Anthropic API) through autonomous, hypothesis-driven forensic investigations on the SIFT workstation.
Point it at an evidence image (disk, memory, network capture) and it:
- Triages by running lightweight tools (mmls, fsstat, img_stat) to understand the evidence
- Hypothesises as Claude forms 1–3 hypotheses (e.g., "Ransomware via phishing," "Lateral movement via RDP")
- Dispatches sub-agents where specialised domain agents (disk, memory, timeline, network, Windows artifacts, malware) test each hypothesis using only their domain's tools
- Verifies through adversarial verifier agents that challenge findings by seeking counter-evidence and proposing alternative explanations
- Iterates as the orchestrator evaluates results, pivots if hypotheses are refuted, and re-dispatches (max 5 rounds)
- Reports structured output with confidence levels, evidence links, accuracy metadata, and full audit trail
Every single tool execution is logged with a unique ID. Any finding can be traced back to the exact command that produced it.
How we built it
Python standard library only. No pip dependencies. The orchestrator calls the Anthropic Messages API over HTTPS; everything else is stdlib.
Architectural guardrails over prompt-based ones. The LLM never touches subprocess directly. Every command passes through a validation pipeline:
- Allowlist check: is this binary in the tool registry?
- Path validation: are evidence paths under allowed roots? Symlink escape detection.
- Argv array construction: no shell interpolation, ever.
- Execution with limits: per-tool timeouts, output size caps.
- Audit logging: every execution logged for traceability.
These are enforced in code regardless of what the LLM requests. We drew a hard trust boundary between "the LLM decides" and "the code permits."
Tool registry is dynamic. A scanner crawls the SIFT workstation (PATH, dpkg, pip), enriches metadata via LLM-grounded descriptions with provenance, and gates tools by installed status, target OS, and input type. New tools get picked up automatically after a refresh. No hardcoded tool lists.
563 tests. Unit coverage across the executor, evidence session, audit logger, accuracy scorer, and correlation engine. Ground-truth baselines scored with precision/recall/F1 and hallucination detection.
Challenges we ran into
Getting the hypothesis loop right. Early iterations either tunnel-visioned on a single hypothesis or scattered across too many. We landed on a "max 3 active hypotheses, max 5 iteration rounds" constraint. Enough to pivot, not enough to waste API calls on dead ends.
Adversarial verification without infinite recursion. Verifier agents need to challenge findings, but you can't let them recurse indefinitely. The solution was a structured verdict system (confirmed / downgraded / refuted) with a single verification pass per finding. No re-verification of verifications.
Evidence integrity. Forensic images must remain unmodified. We bracket every investigation with SHA-256 integrity checks (before and after), mount everything read-only via losetup -r, and the executor's path validation prevents writes outside allowed roots. Getting the mount/unmount lifecycle right without sudo race conditions took more iterations than we'd like to admit.
Output size management. Some forensic tools produce enormous output (timeline dumps, full directory listings). Without output caps, Claude's context window fills with noise. We added per-tool output size limits and a summarisation pass for oversized results.
Accomplishments that we're proud of
- Full audit traceability. Every finding in the report links back to the exact tool execution that produced it, with timestamps and unique IDs. This isn't just nice-to-have; it's what makes the output trustworthy for a forensic context.
- Architectural trust boundary. The separation between "LLM decides" and "code permits" is clean and testable. Prompt injection can't escape the executor's allowlist.
- Self-critical accuracy scoring. The system scores itself against ground-truth baselines with precision/recall/F1 and explicitly flags hallucinated findings. We wrote a full accuracy report (docs/ACCURACY.md) documenting false positives and missed findings. If you can't measure it, you can't improve it.
- Zero external dependencies. Runs on a stock SIFT workstation with just an API key. No Docker, no pip install, no infrastructure.
- 563 passing tests. For a hackathon project, that's... probably overkill. But forensic tooling shouldn't ship with "it works on my machine" confidence.
What we learned
- LLMs are surprisingly good at forming investigative hypotheses. Given triage output, Claude consistently generates plausible, testable hypotheses. The bottleneck isn't hypothesis quality; it's efficient tool selection to test them.
- Prompt-based guardrails aren't enough for forensic work. You need architectural enforcement. "Please don't modify evidence" in a system prompt is not the same as read-only mounts and path validation in code.
- Adversarial verification catches real hallucinations. Without it, ~15% of findings in early runs were unsupported by the actual tool output. The verifier pass drops that to near-zero.
- Dynamic tool discovery beats hardcoded catalogs. Different SIFT versions have different tools installed. Scanning the actual workstation and gating on what's present means the system adapts without code changes.
- Structured audit logging should be day-one, not day-last. We added it early and it paid dividends for debugging the orchestration loop. Every "why did it do that?" question was answerable from the audit trail.
What's next for AgenticSIFT
- Multi-image correlation. Run parallel investigations across related images (e.g., compromised host + network capture + memory dump) and correlate findings across evidence sources.
- Live SIFT integration. Tighter integration with the SIFT workstation UI for interactive investigation alongside autonomous analysis.
- Playbook mode. Define investigation playbooks (ransomware response, insider threat, etc.) that constrain the hypothesis space for faster, more focused investigations.
- Model comparison framework. The
compare-agentsCLI subcommand is stubbed; we want to benchmark Claude vs other models on the same evidence with identical ground-truth scoring. - Community ground-truth baselines. Publish baseline schemas and invite the DFIR community to contribute scored findings for public forensic images (NIST CFReDS, etc.).
Demo Video
https://www.youtube.com/watch?v=thI_z_Ne-cs
Github
https://github.com/joshfrogers/Find-Evil-Hackathon
Agent Exec Logs
https://github.com/joshfrogers/Find-Evil-Hackathon/tree/main/output/nist_hacking
Built With
- claude
- python

Log in or sign up for Devpost to join the conversation.