-
-
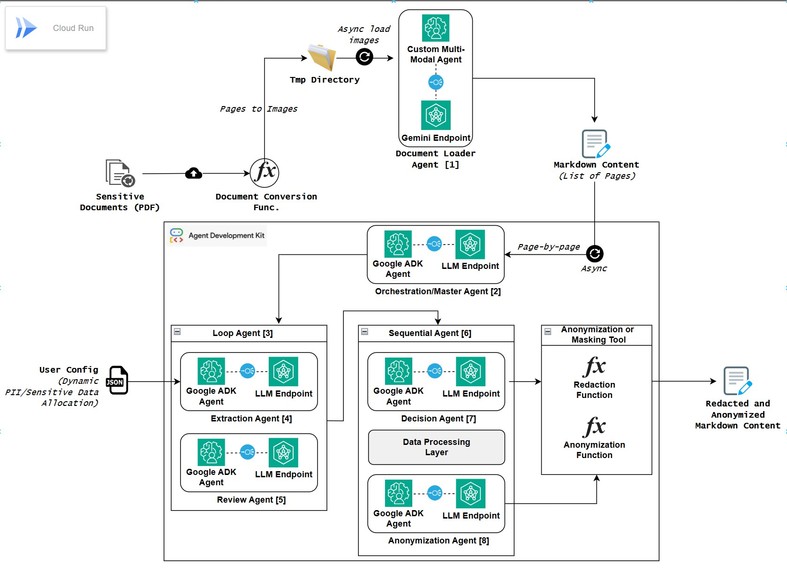
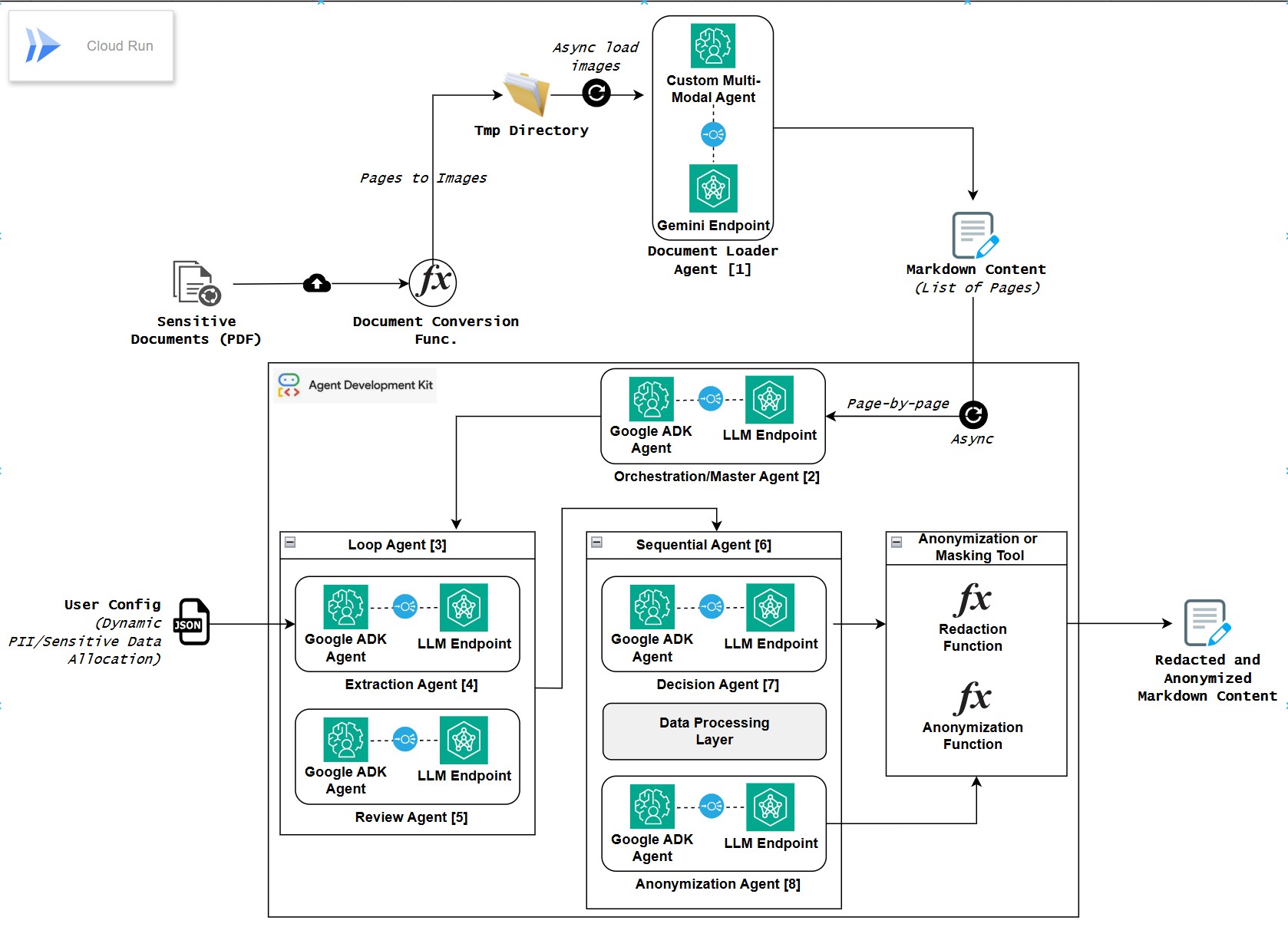
De-identifier Architecture
-
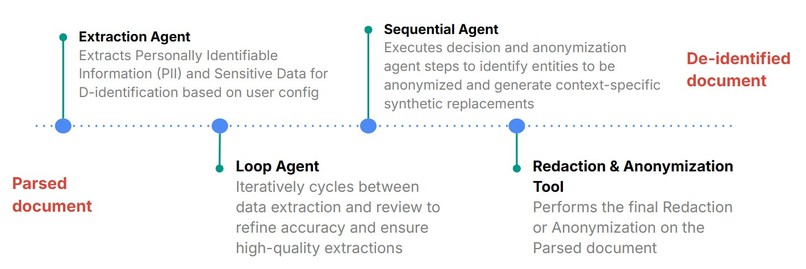
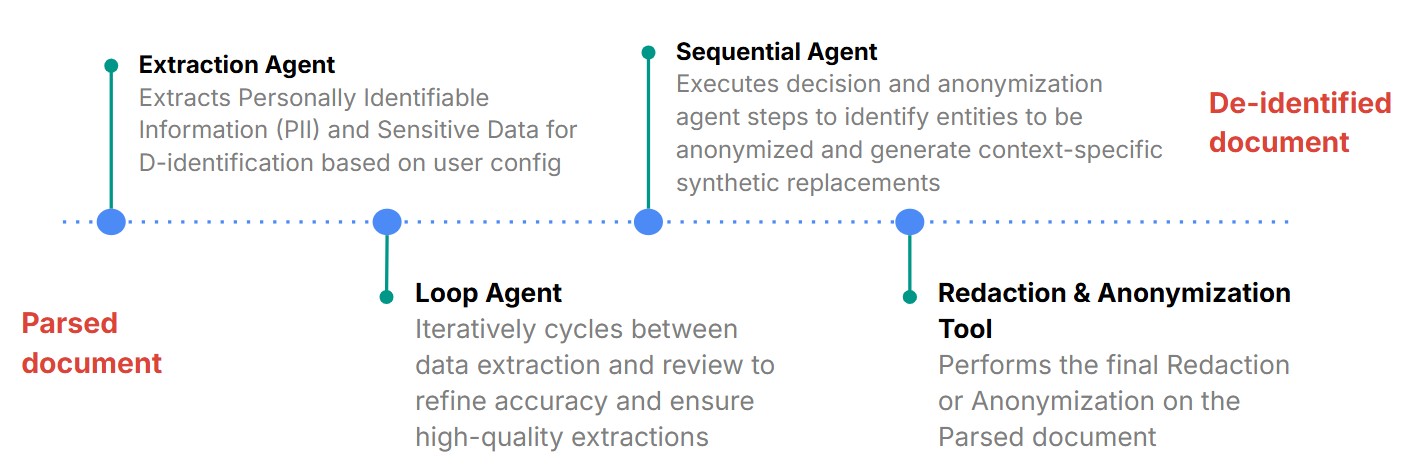
ADK Agent Orchestration
Inspiration
In modern AI workflows, huge amounts of unstructured data; such as medical records, chat logs, legal documents, and customer data — are often directly parsed, vectorized, or fed into LLMs and vector databases without adequate privacy checks This leads to risk of exposure of personally identifiable information (PII), confidential business data, and regulatory non-compliance risks (e.g., HIPAA, GDPR). Traditional rule-based anonymization tools cannot handle the contextual, multimodal, and dynamic nature of such data pipelines. Existing solutions rely heavily on rule-based masking or redaction which is secure but destroy data utility making the resulting datasets unsuitable for analytics, insights, or model fine-tuning. While some degree of redaction is essential, context-aware anonymization can preserve analytical patterns and relationships, enabling privacy-safe yet insight-rich AI systems.
What it does
Agentic De-Identifier is a Google (ADK + Gemini) powered, domain-adaptive privacy agent that dynamically detects, classifies, and de-identifies sensitive data before it enters downstream AI systems. It gives users granular control to define which parameters such as names, IDs, or medical details should be treated as sensitive, making it highly adaptable across multiple domains like healthcare, legal, or finance. Leveraging dynamic agentic reasoning, the system contextually decides whether to anonymize or redact each element, balancing privacy with data utility. This ensures compliance with data protection regulations while preserving analytical integrity, enabling organizations to harness privacy-safe yet insight-rich data for AI and analytics.
How we built it
Built with Python (backend), Streamlit (frontend), Google ADK (agent orchestration) and Google Cloud Run (deployment). The core logic leverages Gemini and Google’s Agent Developer Kit (ADK) for agentic orchestration, enabling dynamic extraction, review, decision-making between anonymization and redaction. The app integrates seamlessly as a security layer with vector databases and LLM pipelines.
Challenges we ran into
- Handling multi-modal and multi-lingual data formats.
- Ensuring consistent extraction of sensitive information and de-identification across large datasets.
- Scaling and integrating across any domain based on user requirements.
- Balancing anonymization strength with analytical utility (tradeoff between anonymization and redaction/masking).
Accomplishments
- Built a fully functional end-to-end de-identification pipeline.
- Achieved dynamic, context-aware anonymization and redaction.
- Integrated user-controlled sensitivity customization.
- Deployed on Cloud Run with scalable agentic architecture built with Google ADK.
What we learned
Learned about Google ADK and its power in building modular, agentic workflows that communicate seamlessly. Building custom agents and integrating with pre-built agents like SequentialAgent, LoopAgent or LlmAgent. Also understood how to balance privacy with analytical usability and optimize LLM-driven pipelines for domain-specific de-identification requirements.
What's next for Agentic De-Identifier
- Extend de-identification to multimodal data (images, audio, video).
- Fine-tune lightweight SLMs specialized for extraction of sensitive data and PIIs.
- Integrate with RAG systems for privacy-safe document retrieval.
- Scale across multiple domains and develop cross-platform integration through API endpoints.
Built With
- cloudrun
- google-adk
- langchain
- python
- streamlit

Log in or sign up for Devpost to join the conversation.