
Agentic Causal Inference: Autonomous Causal Discovery for Real-Time Streaming Data
Inspiration
Scientists and researchers spend months or years manually discovering causal relationships in data. Traditional approaches require manual hypothesis generation, time-consuming data source discovery, complex statistical analysis, confounder identification, and iterative refinement of models.
We asked: What if AI could do this autonomously in real-time?
The inspiration came from watching researchers struggle with:
- Correlation vs. Causation: Most analytics tools show correlation, but can't determine which variable causes which
- Manual Data Curation: Finding and integrating data sources takes weeks
- Static Analysis: By the time results are ready, the data is outdated
- Confounder Blindness: Missing hidden variables that invalidate causal claims
We built Agentic Causal Inference to transform how scientists discover causality—from months of manual work to minutes of autonomous AI-driven analysis, all on real-time streaming data.
What it does
Agentic Causal Inference is an AI-powered research platform that autonomously discovers causal relationships in real-time streaming data. Scientists simply ask a question in natural language, and AI agents handle the entire workflow:
- Automatically discovers relevant data sources from available Kafka topics and APIs
- Generates hypotheses using domain knowledge grounded to actual data variables
- Tests causal relationships with multiple statistical methods (Granger Causality, Instrumental Variables, Transfer Entropy, PC Algorithm)
- Discovers and tests confounders automatically to ensure robust conclusions
- Refines results iteratively until statistical confidence is achieved
- Delivers insights in real-time as new data streams in
Key Features
- Fully Autonomous: No manual configuration—just ask a question
- Real-Time Streaming: Built on Confluent Cloud for live data analysis
- Domain-Agnostic: Works for cryptocurrency, healthcare, climate, economics, IoT—any domain with streaming data
- Multiple Causal Methods: Combines Granger Causality, IV, Transfer Entropy, and more for robust conclusions
- Confounder Discovery: Automatically identifies and controls for hidden variables
- Natural Language Interface: Ask questions like "Does social sentiment cause price movements?"
Example Use Case: Cryptocurrency Research
Question: "Does social sentiment cause cryptocurrency price movements?"
The system:
- Discovers Reddit, price APIs, and news sources
- Generates hypotheses:
sentiment → price,price → sentiment, bidirectional - Tests each with Granger causality on rolling windows
- Identifies confounders: market cap, trading volume, news events
- Result: "Sentiment leads price by 12 minutes with 85% confidence"
This isn't correlation—it's causation with direction and timing.
How we built it
Architecture Overview
┌─────────────────────────────────────────────────────────────┐
│ Data Sources (Any Domain) │
│ APIs, Databases, IoT Sensors, Social Media, Market Data │
└────────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Confluent Cloud │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Schema Reg. │ │ Kafka Topics │ │ ksqlDB │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└────────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ AI-Powered Agent Orchestration (LangGraph) │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Data Curation Agent (Google Gemini) │ │
│ │ • Discovers data sources from asset registry │ │
│ │ • Integrates pipelines via Confluent │ │
│ │ • Collects and prepares datasets │ │
│ │ • Computes readiness scores │ │
│ └──────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Causal Discovery Agent (Google Gemini) │ │
│ │ • Generates hypotheses from research questions │ │
│ │ • Tests with Granger, IV, Transfer Entropy │ │
│ │ • Discovers confounders automatically │ │
│ │ • Refines hypotheses iteratively │ │
│ └──────────────────────────────────────────────────────┘ │
└────────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ FastAPI Backend │
│ REST Endpoints + WebSocket for Real-Time Updates │
└────────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Streamlit Dashboard │
│ • Data Curation View │
│ • Causal Inference View │
│ • Real-Time Results Dashboard │
└─────────────────────────────────────────────────────────────┘
Technology Stack
Data Streaming
- Confluent Cloud: Managed Kafka for real-time data streaming
- Schema Registry: Data governance and compatibility
- Kafka Connect: Integration with external data sources
AI & Machine Learning
- Google Gemini: Natural language understanding and hypothesis generation
- LangGraph: Agent orchestration and state management
- LangChain: LLM integration and prompt management
Causal Inference
- Statsmodels: Granger Causality, VAR models
- DoWhy: Causal inference framework
- Causal-Learn: PC Algorithm, constraint-based methods
- PyITLib: Transfer Entropy
Backend & Frontend
- FastAPI: High-performance REST API
- WebSockets: Real-time updates
- Streamlit: Interactive dashboard
- Plotly: Interactive visualizations
Key Implementation Details
1. Asset Registry (Grounding AI to Reality)
We built an Asset Registry that catalogs all available data sources, variables, and Kafka topics. This ensures AI agents only generate hypotheses using variables that actually exist:
# Example: Available variables in registry
Variables:
- price_usd (from crypto.prices.raw)
- avg_sentiment (from social.reddit.enriched)
- volume_24h (from crypto.prices.raw)
- fear_greed_value (from analytics.unified)
This grounding prevents AI hallucinations and ensures all hypotheses are testable with real data.
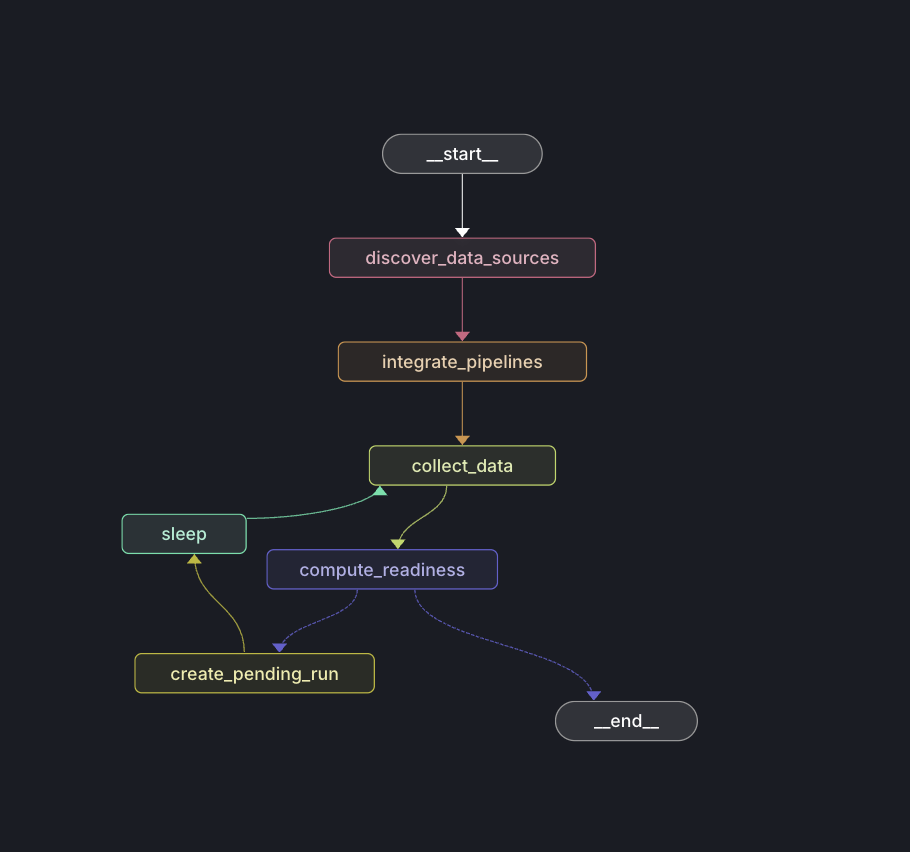
2. Autonomous Data Curation Agent
The Data Curation Agent:
- Discovers relevant data sources from the asset registry
- Integrates new pipelines via Confluent Kafka
- Collects data from multiple sources (APIs, Kafka topics, databases)
- Builds canonical DataFrames with proper time alignment
- Computes data readiness scores
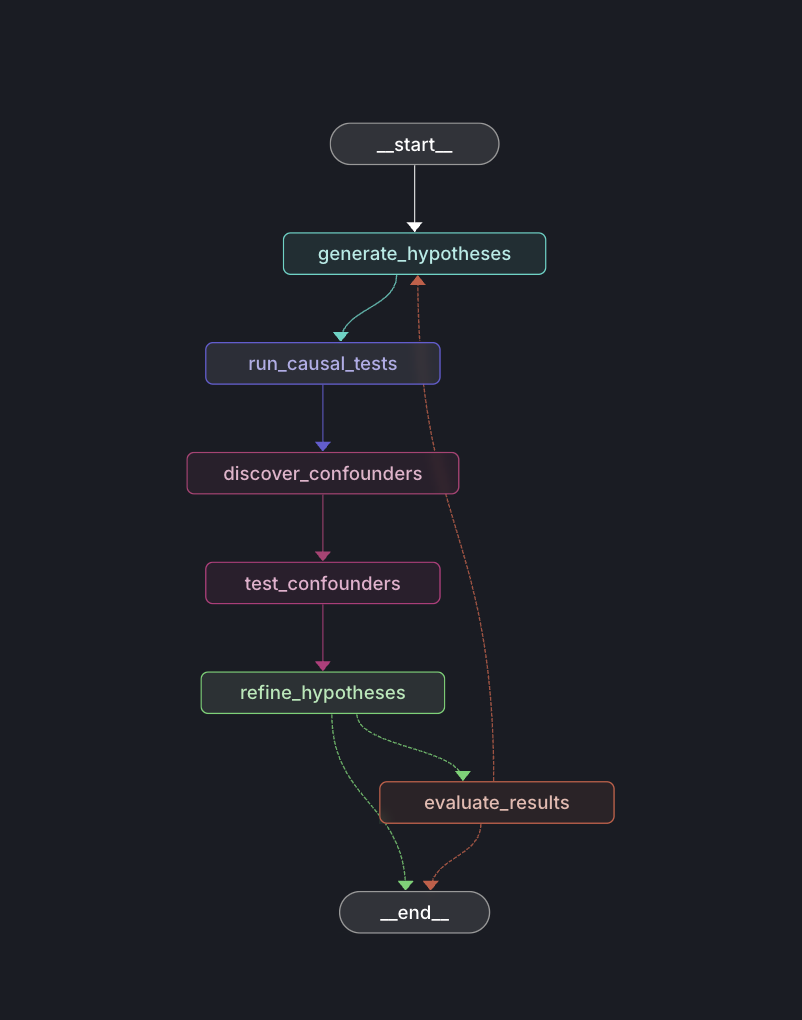
3. Causal Discovery Agent
The Causal Discovery Agent:
- Takes natural language research questions
- Generates multiple hypotheses (e.g.,
sentiment → price,price → sentiment) - Tests each hypothesis with multiple causal methods:
- Granger Causality: Temporal precedence
- Instrumental Variables: Exogenous shocks
- Transfer Entropy: Information flow
- PC Algorithm: Constraint-based discovery
- Discovers potential confounders automatically
- Refines hypotheses based on statistical results
4. Real-Time Streaming Pipeline
Data flows through Confluent Cloud:
- Producers: Collect data from APIs (Reddit, CoinGecko, News APIs)
- Kafka Topics: Stream raw and enriched data
- Consumers: Enrich with AI (sentiment analysis), perform causal tests
- ksqlDB: Stream joins and windowing for time-aligned analysis
5. Canonical DataFrame Builder
We built a system that assembles clean, analysis-ready DataFrames:
- Time alignment (1-minute resolution)
- Proper joins across data sources
- Quality checks (missing data, value ranges)
- Single source of truth for causal analysis
Challenges we ran into
1. Grounding AI Agents to Real Data Sources
Challenge: LLMs tend to hallucinate data sources and variables that don't exist.
Solution: We built an Asset Registry that catalogs all available variables and data sources. The AI agents are explicitly prompted with this registry and validate all hypotheses against it before testing.
2. Real-Time Causal Inference on Streaming Data
Challenge: Causal inference typically requires batch data with sufficient history. How do we compute Granger causality on a continuous stream?
Solution: We implemented rolling window analysis—computing causal relationships on sliding windows (e.g., 60-minute windows, recalculating every 5 minutes). This provides real-time updates while maintaining statistical validity.
3. Time Alignment Across Multiple Data Sources
Challenge: Price data arrives at different intervals than sentiment data. How do we align them for causal analysis?
Solution: We built a Canonical DataFrame Builder that:
- Resamples all data to 1-minute intervals
- Forward-fills price data (last known price)
- Averages sentiment over 1-minute windows
- Performs inner joins on timestamp
4. Confounder Discovery
Challenge: Hidden confounders can invalidate causal claims. How do we discover them automatically?
Solution: We use Google Gemini to:
- Analyze domain knowledge to suggest potential confounders
- Test variables as confounders (checking if they explain both cause and effect)
- Automatically control for discovered confounders in causal tests
5. Schema Evolution in Kafka
Challenge: As we add new data sources, schemas evolve. How do we handle backward compatibility?
Solution: We use Confluent Schema Registry with Avro schemas, enabling:
- Schema versioning
- Backward/forward compatibility
- Automatic validation
6. LLM Response Parsing
Challenge: Getting structured JSON from LLMs reliably for hypothesis generation and confounder discovery.
Solution: We use Google Gemini's structured output capabilities (when available) and robust JSON parsing with fallbacks. We also validate all LLM outputs against the asset registry before use.
Accomplishments that we're proud of
1. Fully Autonomous Causal Discovery
We built a system that requires zero manual configuration. Scientists just ask a question, and the AI handles:
- Data source discovery
- Hypothesis generation
- Statistical testing
- Confounder identification
- Result interpretation
This transforms months of work into minutes.
2. Real-Time Streaming Causal Analysis
We're one of the first systems to perform causal inference on real-time streaming data (not just batch). This enables:
- Live monitoring of causal relationships
- Early detection of causal direction changes
- Continuous refinement as new data arrives
3. Domain-Agnostic Design
The same platform works for:
- Cryptocurrency: "Does sentiment cause price movements?"
- Healthcare: "Does medication adherence cause improved outcomes?"
- Climate: "Do CO2 emissions cause temperature changes?"
- IoT: "Do sensor anomalies cause equipment failures?"
No domain-specific code—just configure data sources.
4. Multiple Causal Methods Integration
We integrated four different causal inference methods:
- Granger Causality (temporal precedence)
- Instrumental Variables (exogenous shocks)
- Transfer Entropy (information flow)
- PC Algorithm (constraint-based)
This provides robust, multi-method validation of causal claims.
5. Production-Ready Infrastructure
Built with enterprise-grade tools:
- Confluent Cloud: Scalable, managed Kafka
- Schema Registry: Data governance
- FastAPI: High-performance backend
- WebSockets: Real-time updates
The system is ready for production deployment, not just a hackathon demo.
6. Grounded AI Agents
Our AI agents are grounded to reality via the Asset Registry. This prevents hallucinations and ensures all hypotheses are testable with actual data. This is a critical innovation for production AI systems.
7. Confounder Discovery Automation
Automatically discovering and testing confounders is typically a manual, expert-driven process. We automated it using AI, making causal analysis more rigorous and accessible.
What we learned
1. Causal Inference in Streaming Context
Traditional causal inference assumes batch data. Adapting methods like Granger Causality to streaming data required:
- Rolling window implementations
- Efficient recomputation strategies
- Handling non-stationary time series
We learned that real-time causality is fundamentally different from batch causality.
2. Agent Orchestration with LangGraph
Using LangGraph for multi-agent orchestration taught us:
- State management across agent steps
- Error handling and retry logic
- Conditional branching based on results
- Human-in-the-loop capabilities
Key Insight: Agent orchestration is as important as the agents themselves.
3. Grounding LLMs to Real Data
Preventing AI hallucinations required:
- Explicit registry of available assets
- Validation layers before LLM outputs are used
- Fallback mechanisms when LLMs suggest unavailable sources
Key Insight: Grounding is not optional—it's essential for production AI systems.
4. Schema-First Design
Using Avro schemas and Schema Registry from the start enabled:
- Type safety across the pipeline
- Schema evolution without breaking changes
- Automatic validation
Key Insight: Schema-first design pays dividends as systems grow.
5. Time Alignment is Hard
Aligning data from multiple sources with different update frequencies required:
- Careful resampling strategies
- Handling missing data gracefully
- Choosing appropriate window sizes
Key Insight: Time alignment is often the hardest part of multi-source analysis.
6. Confounder Discovery is Complex
Automating confounder discovery taught us:
- Domain knowledge is crucial (we use LLMs to encode it)
- Statistical tests alone aren't enough
- Context matters—the same variable can be a confounder in one context but not another
Key Insight: Confounder discovery benefits from AI assistance but requires human validation.
7. Real-Time vs. Batch Trade-offs
Real-time analysis requires:
- Accepting some statistical uncertainty (smaller sample sizes)
- Efficient algorithms (can't recompute everything)
- Streaming-friendly methods (some methods don't work on streams)
Key Insight: Real-time causality is a new research area with many open questions.
What's next for Agentic Causal Inference
Phase 1: Enhanced Causal Methods (Next 3 Months)
- Difference-in-Differences: For event impact analysis
- Regression Discontinuity Design: For threshold effects
- Synthetic Control: For policy evaluation
- Double Machine Learning: For high-dimensional confounder control
Phase 2: Multi-Domain Analysis (Next 6 Months)
- Cross-Domain Causality: Analyze relationships across domains (e.g., "Does crypto sentiment cause stock market movements?")
- Causal Networks: Visualize complex causal graphs with multiple variables
- Hierarchical Causality: Discover causal relationships at different time scales (minutes, hours, days)
Phase 3: Production Features (Next 12 Months)
- Automated Report Generation: PDF reports with statistical summaries
- Jupyter Notebook Integration: Export analysis as notebooks
- Python SDK: Programmatic access for data scientists
- REST API Enhancements: GraphQL API for flexible queries
- Version Control: Track causal model versions over time
Phase 4: Advanced Capabilities (Future)
- Collaborative Research: Multiple researchers working on shared causal models
- Automated A/B Testing Framework: Design and run experiments based on causal insights
- Causal Graph Visualization: Interactive DAGs showing causal relationships
- Mobile App: Real-time alerts and monitoring on mobile devices
- Federated Learning: Causal discovery across distributed data sources
Long-Term Vision
Transform causal discovery from a months-long manual process to a minutes-long autonomous AI workflow.
We envision a future where:
- Scientists ask questions in natural language
- AI autonomously discovers causality in real-time
- Results are continuously refined as new data arrives
- Causal insights power decision-making across all domains
Agentic Causal Inference is the foundation for this future.
Try It Yourself
Quick Start
# Clone repository
git clone <repository-url>
cd cryptosentinel
# Install dependencies
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
# Configure credentials (see DEPLOYMENT.md)
cp env.example .env
# Edit .env with your Confluent Cloud and Google Gemini credentials
# Start the dashboard
streamlit run dashboard/app.py
Example Questions to Try
- Cryptocurrency: "Does social sentiment cause price movements?"
- Healthcare: "Does medication adherence cause improved outcomes?"
- Climate: "Do CO2 emissions cause temperature changes?"
- Economics: "Does unemployment cause crime rates?"
Documentation
- Full Documentation: See
README.mdandPITCH.md - Deployment Guide: See
DEPLOYMENT.md - Data Curation Guide: See
DATA_CURATION_GUIDE.md - Agent Guide: See
agent/README.md
Built With
- Confluent Cloud: Real-time data streaming infrastructure
- Google Gemini AI: Natural language understanding and reasoning
- LangGraph: Agent orchestration and state management
- FastAPI: High-performance REST API
- Streamlit: Interactive dashboard
- Statsmodels, DoWhy, Causal-Learn: Causal inference libraries
Team
agentic-causal-inference
Acknowledgments
- Confluent for Kafka streaming infrastructure and the hackathon challenge
- Google AI for Gemini API and Vertex AI capabilities
- LangChain for LLM integration framework
- Open Source Community for causal inference libraries (DoWhy, Causal-Learn, Statsmodels)
Built with ❤️ for the Confluent + Google AI Hackathon
Transforming how scientists discover causality in real-time streaming data.
Built With
- confluent
- flink
- gcp
- kafka
- vertexai

Log in or sign up for Devpost to join the conversation.