-
-
Abstract
-
Experiments (Memory)
-
System Design
-
Experiments (Skills)
Inspiration
Agents today are frozen. Everything they "learn" mid-task lives in the context window, leading to degraded performance over long horizons, wasted tokens from re-reading history, and an inability to specialize without an offline training run. However, we ask: what if an agent could rewrite its own weights at inference time? Sakana AI recently released a hypernetwork (Doc-to-LoRA) that turns text into a LoRA adapter in a single forward pass, a primitive that we integrate into an agent system for long-horizon memory, rapid personalization, and self-improving skills. AgentHN is able to self-improve at the weight level during inference time, an early step towards agentic continual learning.
What it does
AgentHN edits its own weights as it works, using Doc-to-LoRA in several ways on a frozen gemma-2-2b base:
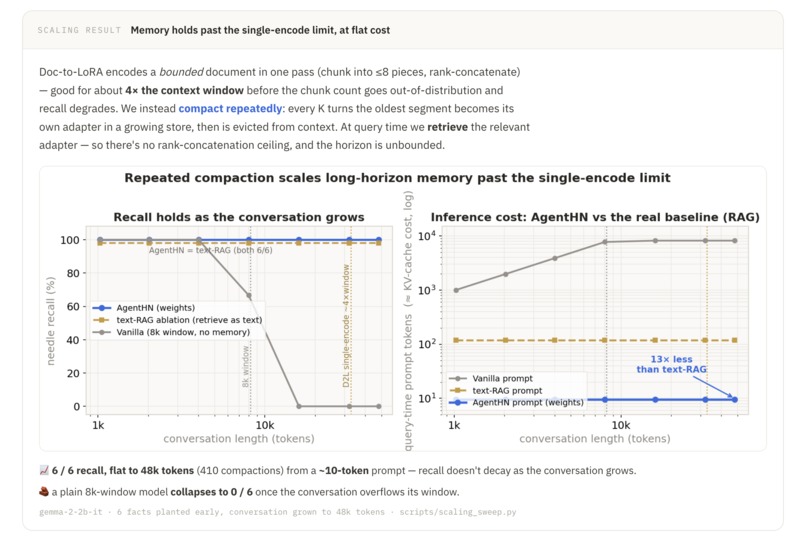
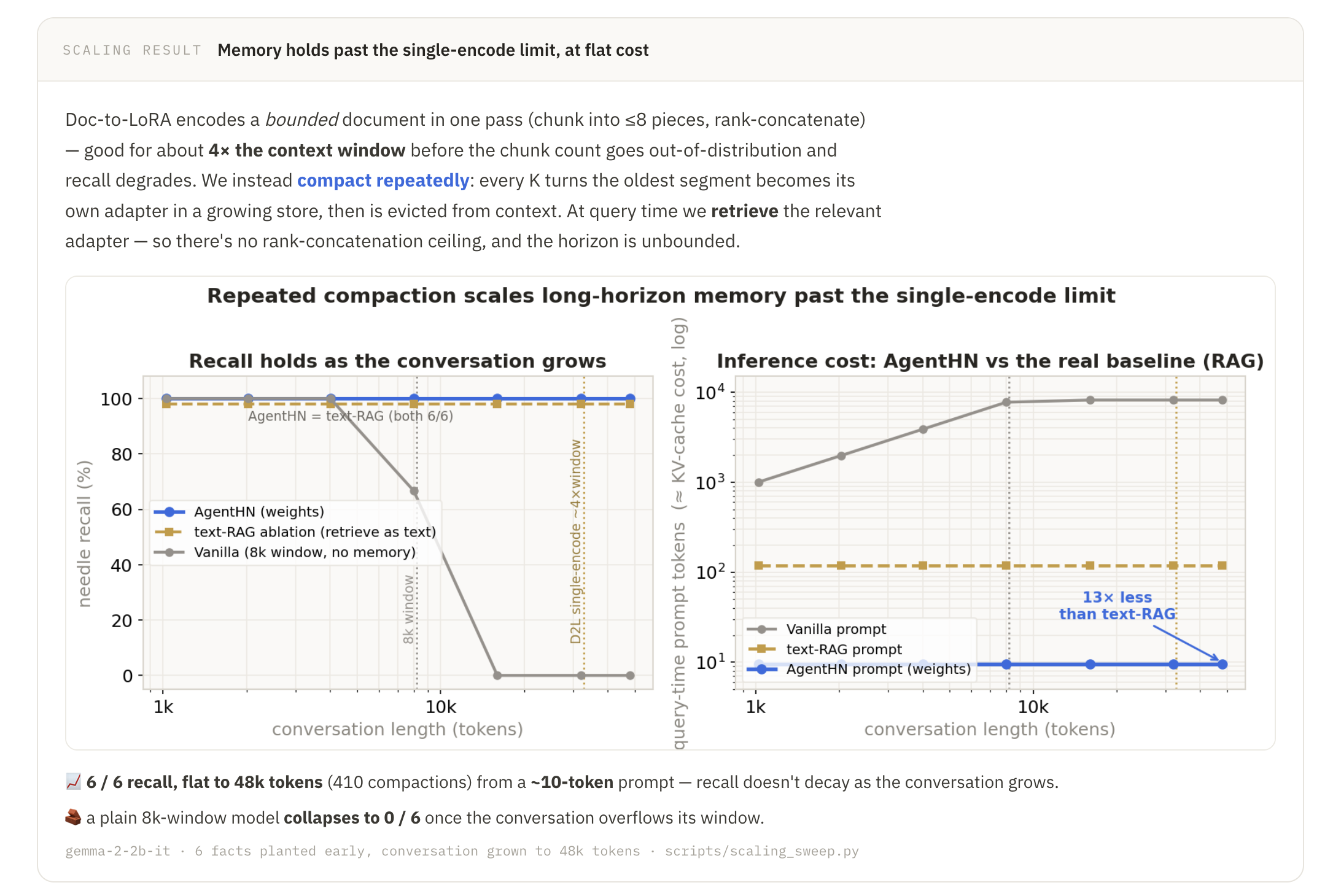
Memory: Conversation turns are offloaded into a running log and re-internalized with D2L every K steps, clearing those turns from context. The live context window stays bounded and the adapter is a fixed ~50MB, letting the agent carry history far beyond what the 8k window alone could hold. On a synthetic Needle-In-A-Haystack (NIAH) task on conversation histories, AgentHN demonstrates the ability to automatically compress then recall user facts across 80 turns with a fixed 10-token context window, 13x less tokens than RAG and 800x less than full in-context learning.
Personalization: After each user turn, the agent updates a user preference log with diff-style edits (add, update, or remove). Periodically, the agent internalizes the current log into a LoRA adapter, allowing it to remember a user's style details with nothing about them in the prompt. New conversations remain personalized without a full fine-tuning run.
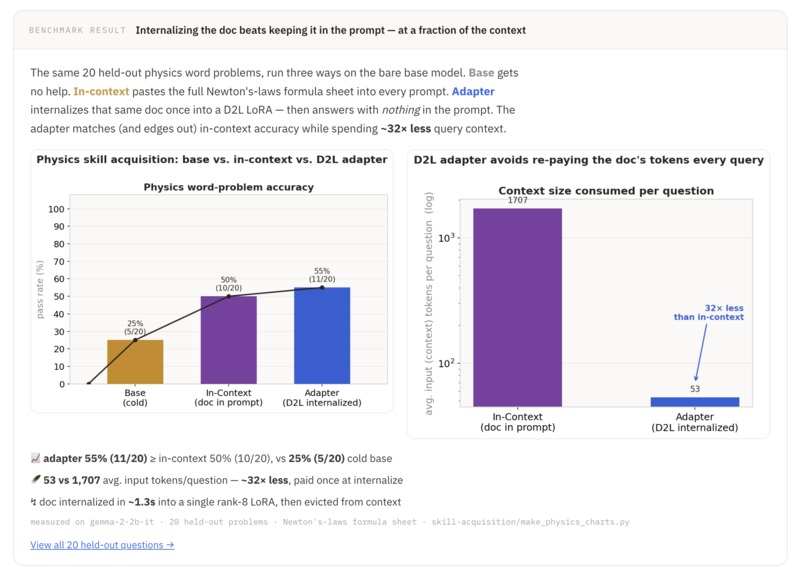
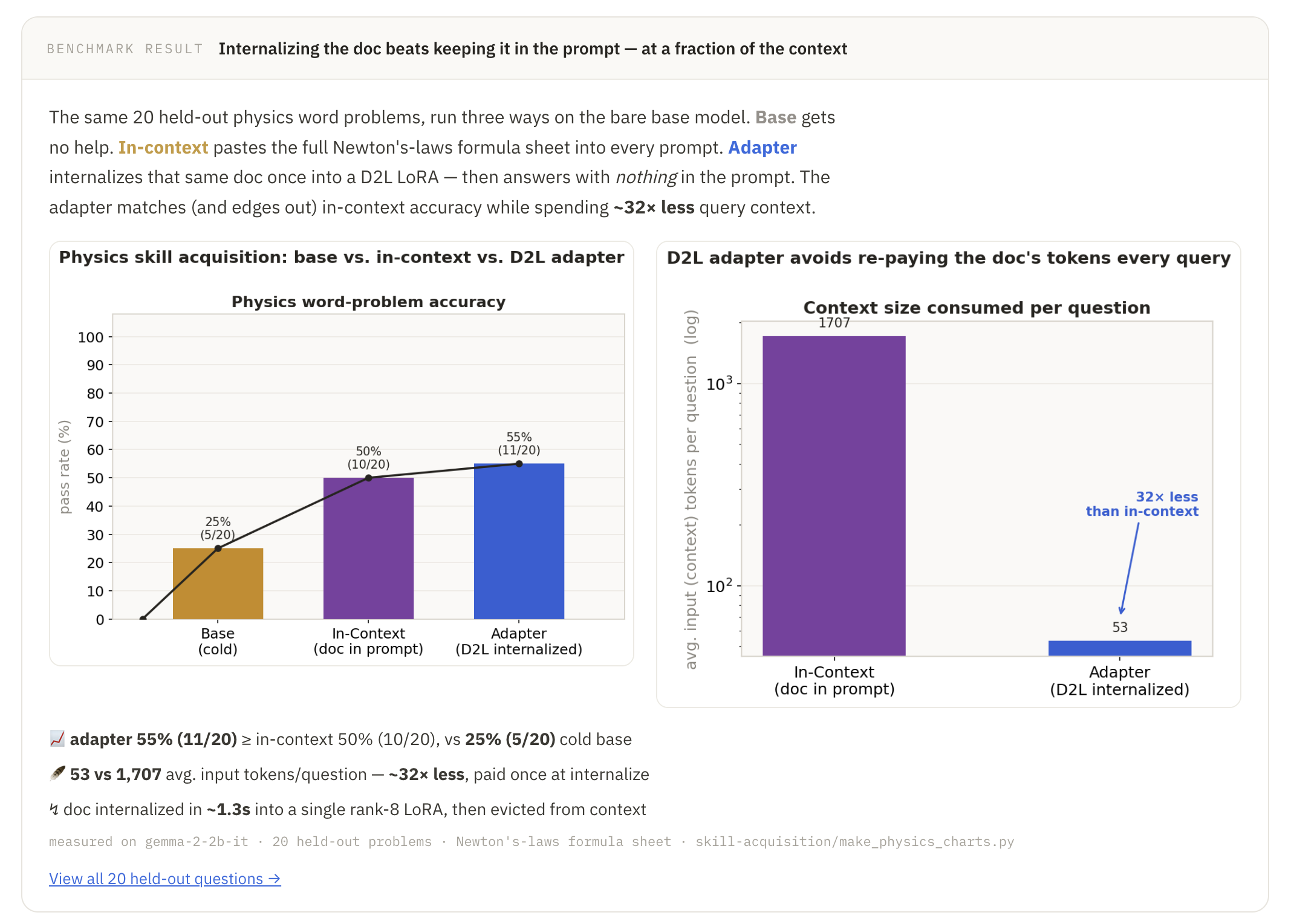
Skills: Instructions and resources can be added into a skills document, which is internalized via D2L. During reasoning tasks, the agent is prompted to recall domain-specific info before attempting the problem. On a multi-turn physics reasoning benchmark, internalized skills achieve 55% compared to 50% with in-context learning.
Self-improvement: AgentHN demonstrates early self-improvement behavior by extending the skills system, refining its own doc and re-internalize after each turn. On a synthetic knowledge Q&A benchmark, AgentHN improves 50% across 3 rounds of self-improvement.
How we built it
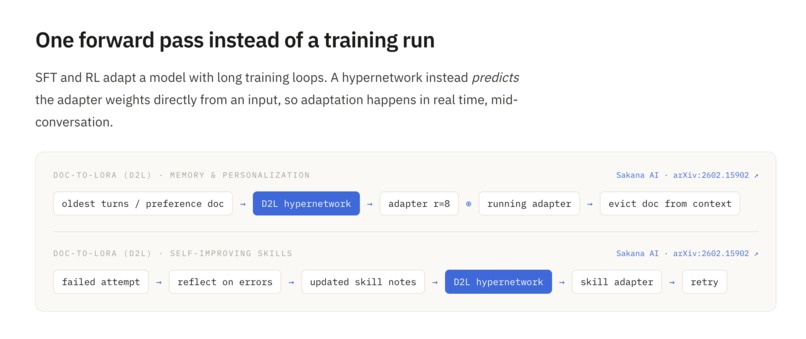
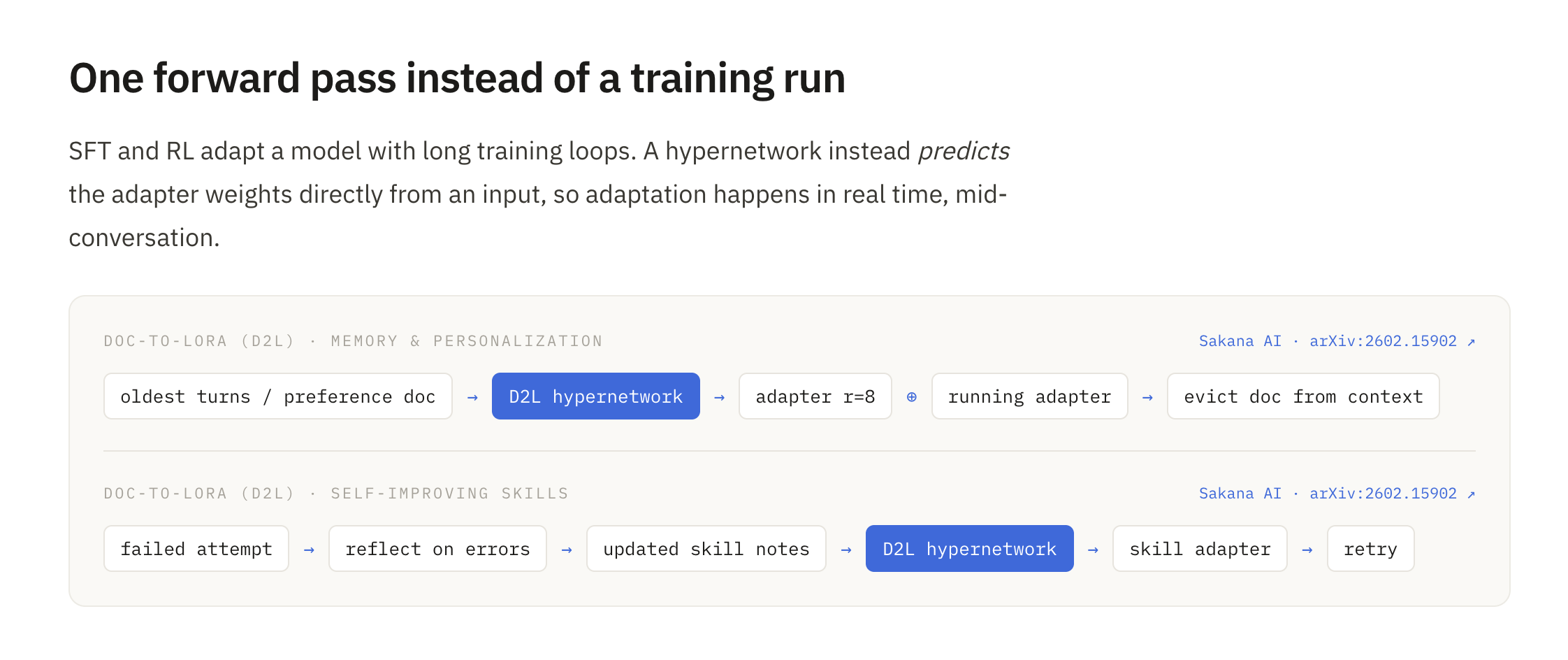
AgentHN is based on one base model, gemma-2-2b, steered at inference time by Sakana AI's Doc-to-LoRA (D2L) hypernetwork, which turns a document into a LoRA adapter in a single forward pass. We load D2L's checkpoints through its ctx_to_lora library and wrote a wrapper that exposes a small surface for the overall project: internalize(doc) to write a doc into the active weights, internalize_segment to snapshot a detached adapter, snapshot/restore to swap adapters per user, and chat/respond/count_tokens.
On top of that wrapper, each feature is its own package. Memory internalizes the oldest conversation turns into adapters, indexes them in a TF-IDF retriever, and at query time retrieves and composes only the top-k relevant ones. We benchmark against markdown-note, RAG, and vanilla baselines. Personalization extracts a running profile document from the conversation and internalizes it into a single per-user adapter that's cached and swapped in. Skills internalizes a reference doc (formulas, formats) once and adds a behavioral nudge so the model actually applies what it memorized. Self-Improvement runs a self-refine loop: the agent attempts a held-out benchmark cold, reflects on what it got wrong, rewrites its own study notes, re-internalizes them into a fresh adapter, and retries over rounds. All four are served by a FastAPI app that loads one shared D2LModel behind a single lock, wraps each feature in a thin JSON/SSE service, streams live runs to a static single-page UI, and can run the page from Vercel against the GPU box over a tunnel/replay recorded runs when the backend is down.
Challenges we ran into
Composing memories destroyed them: Our initial plan for long-horizon memory was to internalize each old slice of the conversation into a LoRA adapter and, at query time, rank-concatenate all of them into one composed adapter. While this should theoretically work according to the D2L paper, our real-world attempt showed signs of destructive interference between weight deltas. We fixed it by not composing everything: a lightweight TF-IDF retriever indexes each napped segment, and at query time we retrieve only the top-k relevant adapters and compose just those.
Text-to-LoRA was a dead end for our setting: For the skills feature, we'd planned to use Text-to-LoRA (T2L), which generates an adapter from a task description. However, T2L is trained on short-answer SuperNatural-Instructions, and on gemma-2-2b it destroyed generative quality by nudging classification up a few points while breaking everything else. We pivoted the skills and self-improvement tracks to a D2L study-doc loop instead: the agent studies a document (or its own notes), internalizes it into the weights, and at test-time, a prompt nudges it to first recall relevant info before answering the question.
Accomplishments that we're proud of
Four live applications on one hypernetwork: We shipped memory, personalization, skills, and self-improvement as working, interactive demos, all running on a single gemma-2-2b + Doc-to-LoRA on one GPU, which a judge can actually click through and run in real time. We leverage the same primitive in creative ways to generalize to different agentic features. We're also proud that we built it as a team working in parallel on a brand-new codebase, coordinating four tracks without the pieces drifting apart.
Extensive experimentation and ablations: Besides the live demos, we also ran rigorous experiments across the different features. On a synthetic Needle-In-A-Haystack task over conversation histories, memory compresses and recalls user facts across 80 turns from a fixed 10-token context window — 13× fewer tokens than RAG and 800× fewer than full in-context learning — and we reinforced that result with a measured cost model and a trained Cartridges baseline. Skills internalized via D2L beat in-context learning on a multi-turn physics reasoning benchmark (55% vs. 50%), and self-improvement climbs by roughly 50 points across three rounds on a synthetic knowledge Q&A benchmark.
What's next for AgentHN: Self-Editing Agents via Hypernetworks
The biggest limitation we hit is the hypernetwork itself: Doc-to-LoRA only adapts a single module and only reliably internalizes the document-QA distribution it was trained on, which bounds how much an agent can truly rewrite about itself. The natural next step is a more general hypernetwork — one trained across more target modules, more base models, and a far broader mix of inputs (documents, task descriptions, trajectories, and an agent's own reflections) so that memory, personalization, skills, and self-improvement all flow from one stronger primitive instead of four careful workarounds. With a hypernetwork that can write richer, composable deltas without destructive interference, AgentHN's self-editing loop could move from an early proof-of-concept toward genuine agentic continual learning.

Log in or sign up for Devpost to join the conversation.