Agentic SDLC — Project Story
Inspiration
Every AI coding demo I'd seen followed the same pattern: type a prompt, get some code, marvel at the output, and stop there. But real software delivery is nothing like that.
Real software has requirements gathering, architectural decisions, code review, test runs, QA gates, and deployment pipelines. Real software has humans who need to stay in the loop — not because automation is bad, but because judgment, context, and accountability still matter.
I wanted to answer a simple question: what does a full, AI-assisted software delivery workflow actually look like when you try to model it honestly? Not a demo. Not a highlight reel. A complete pipeline, from idea to pull request, with all the messy intermediate steps included.
That question became Agentic SDLC.
How I Built It
The architecture is built around three layers that work together:
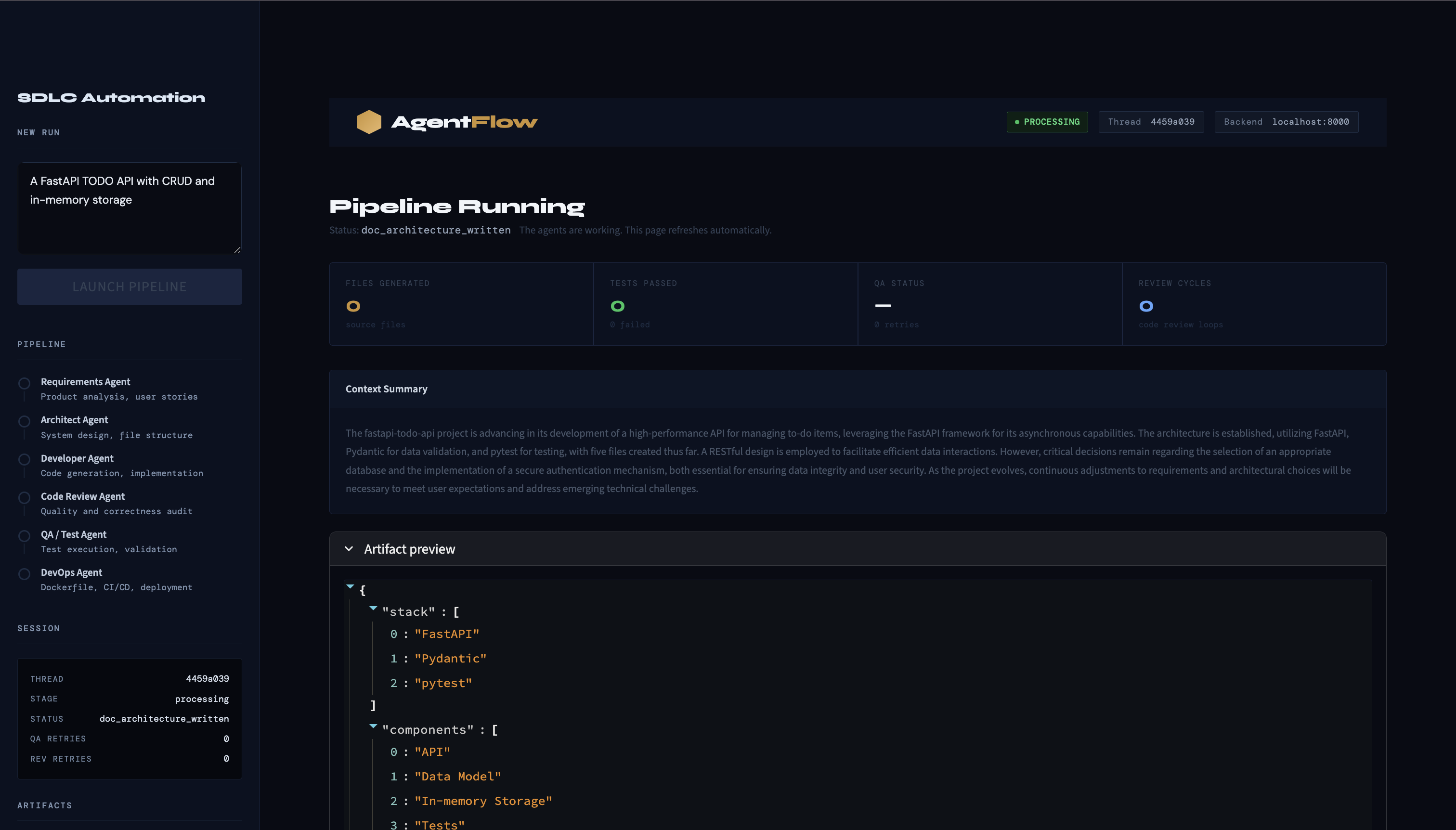
LangGraph powers the workflow engine. Each stage of the SDLC — requirements, architecture, development, code review, QA, and deployment — is a node in a directed graph. Routing logic between nodes handles branching: approvals move the pipeline forward, rejections route back for revision, and human-in-the-loop interrupt points pause execution and wait.
FastAPI serves as the backend, exposing REST endpoints for starting runs, resuming paused workflows, rewinding to earlier checkpoints, and fetching state. Keeping the workflow logic and the API separate meant I could reason about each independently.
Streamlit provides the dashboard. It connects to the FastAPI backend and gives users a way to watch the pipeline progress in real time, review generated artifacts at each stage, and approve or reject before the workflow continues.
Each SDLC stage is handled by a dedicated agent:
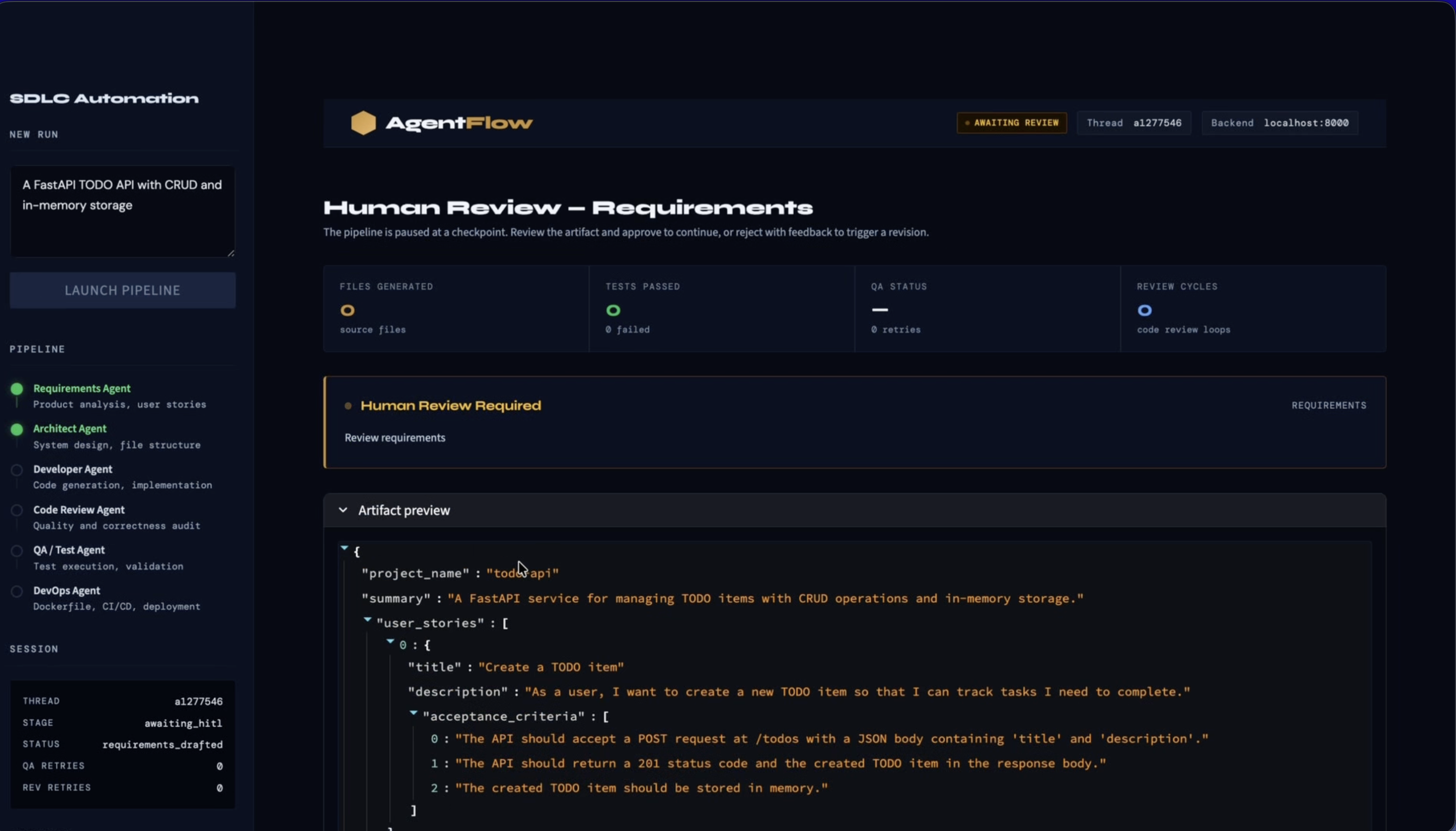
- The Requirements Agent converts a plain-language idea into structured goals and constraints
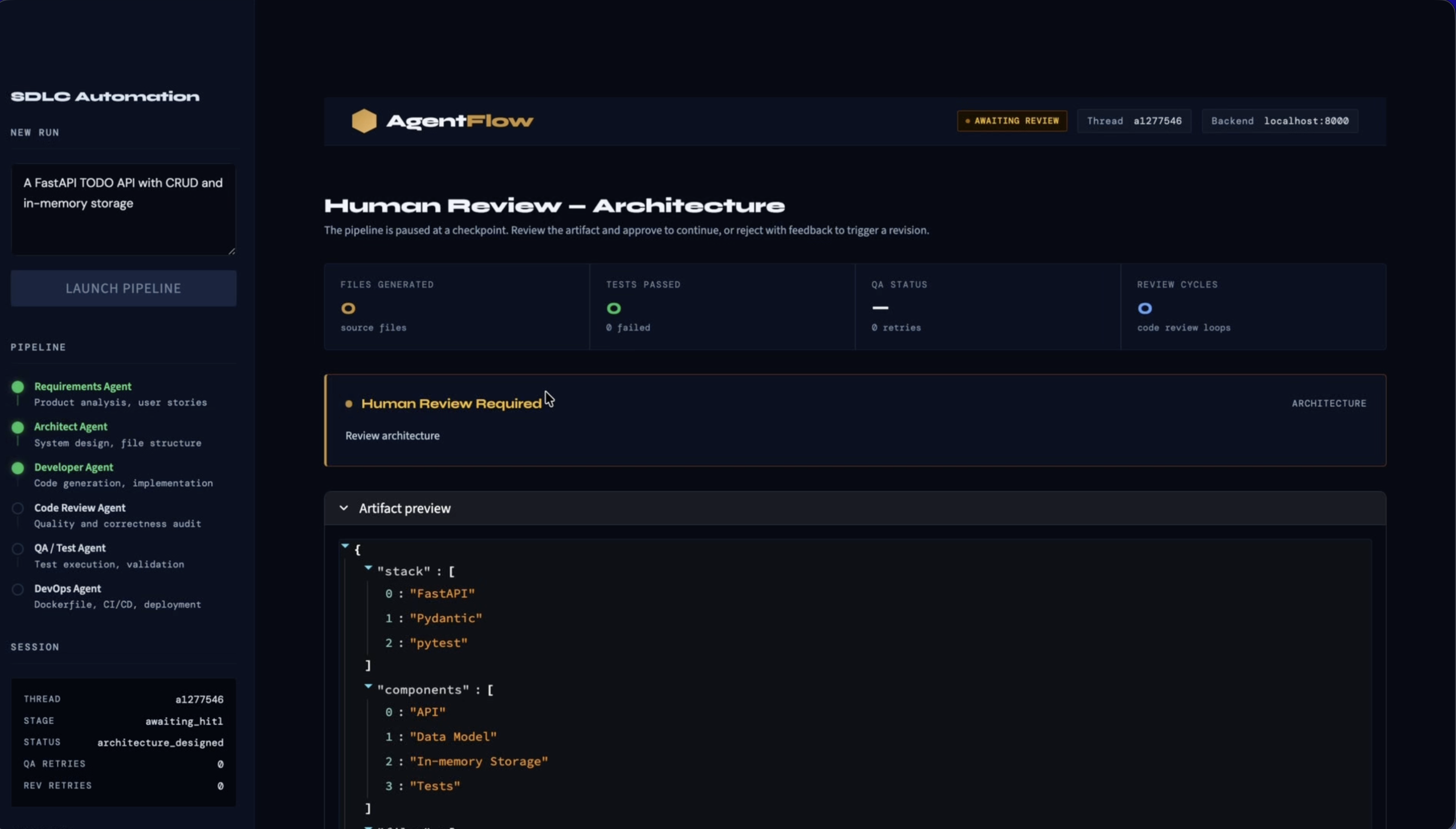
- The Architecture Agent proposes a technical design
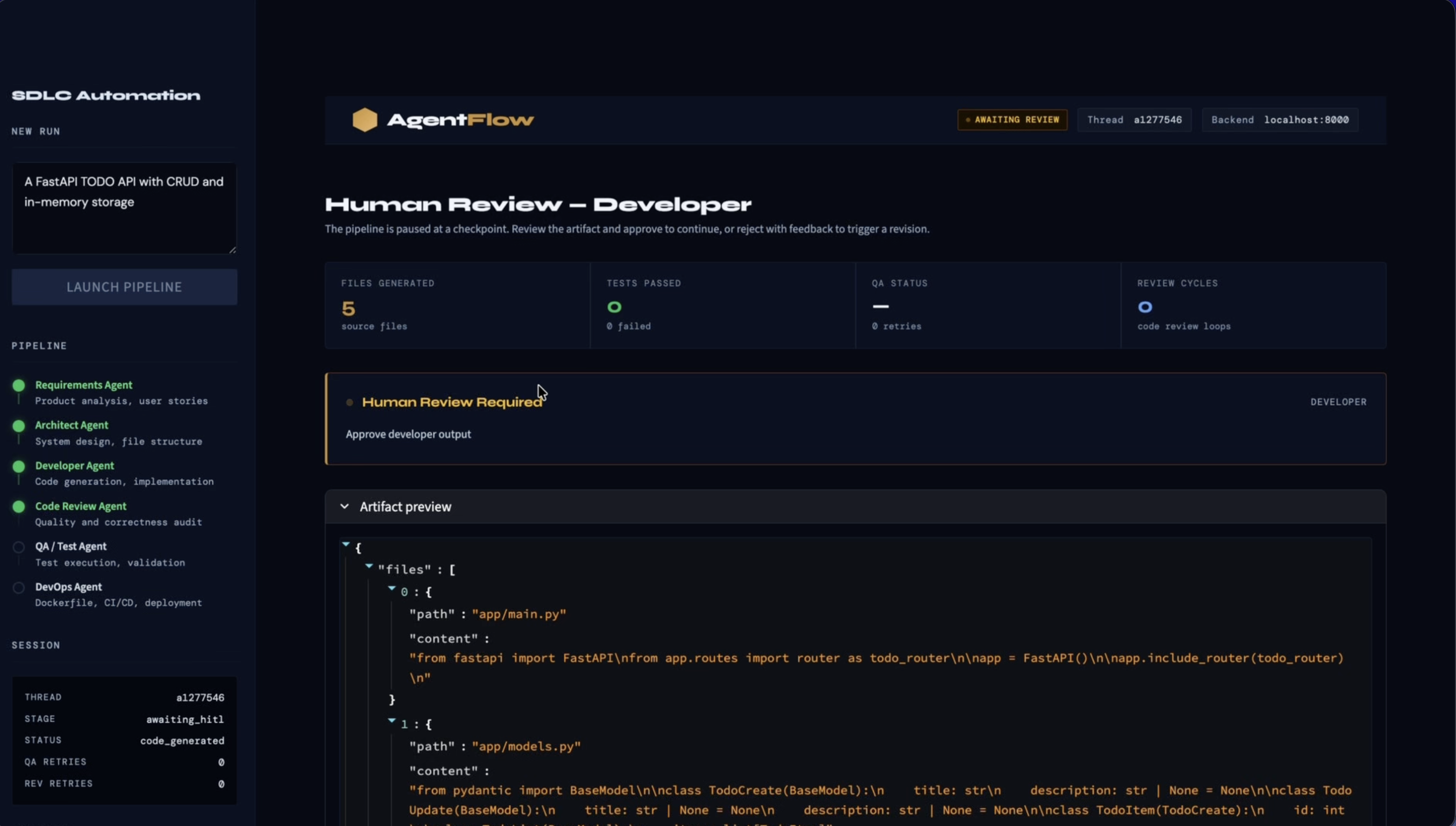
- The Development Agent generates source code, tests, and project files
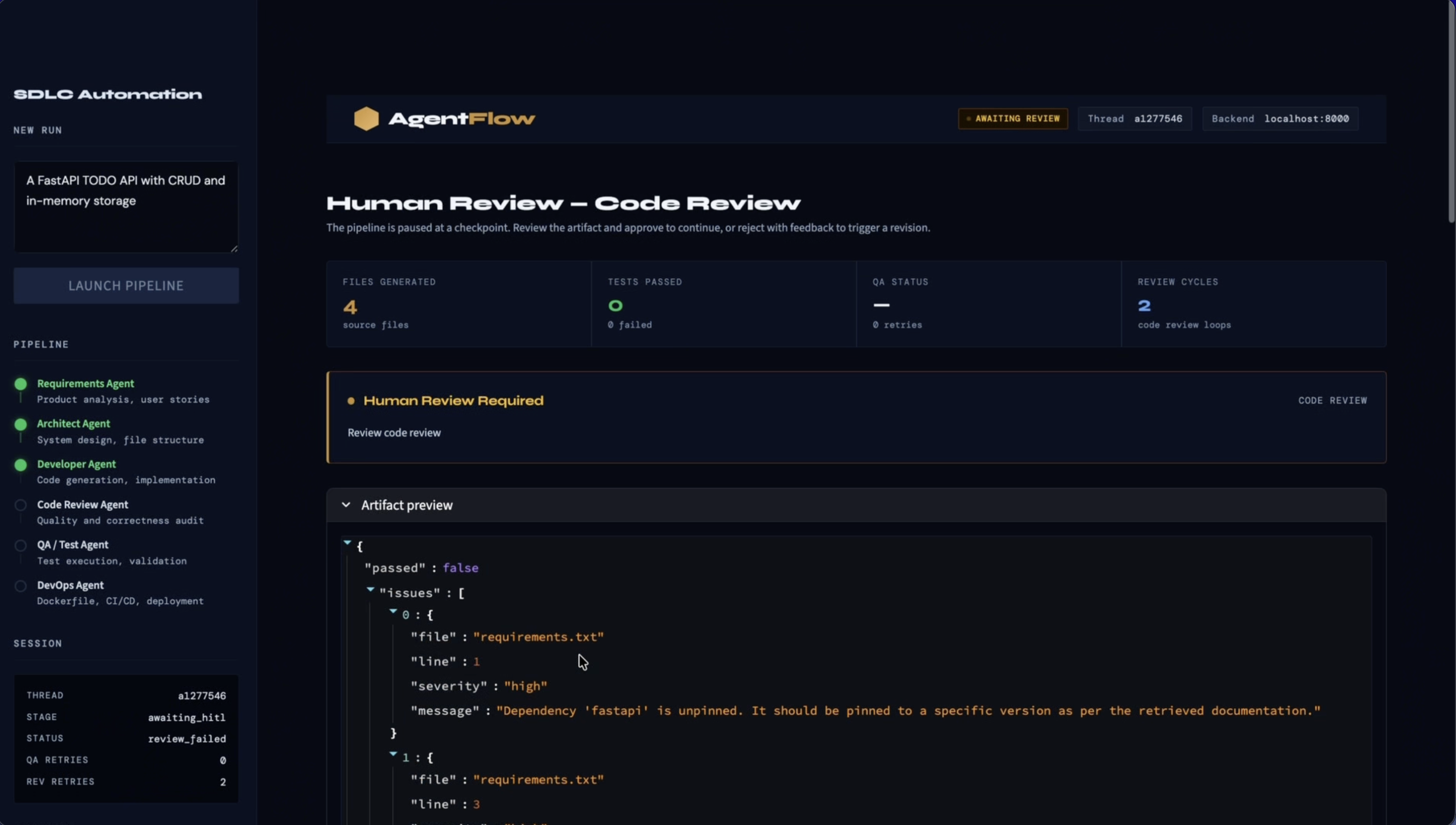
- The Code Review Agent checks the generated output for issues
- The QA Agent runs
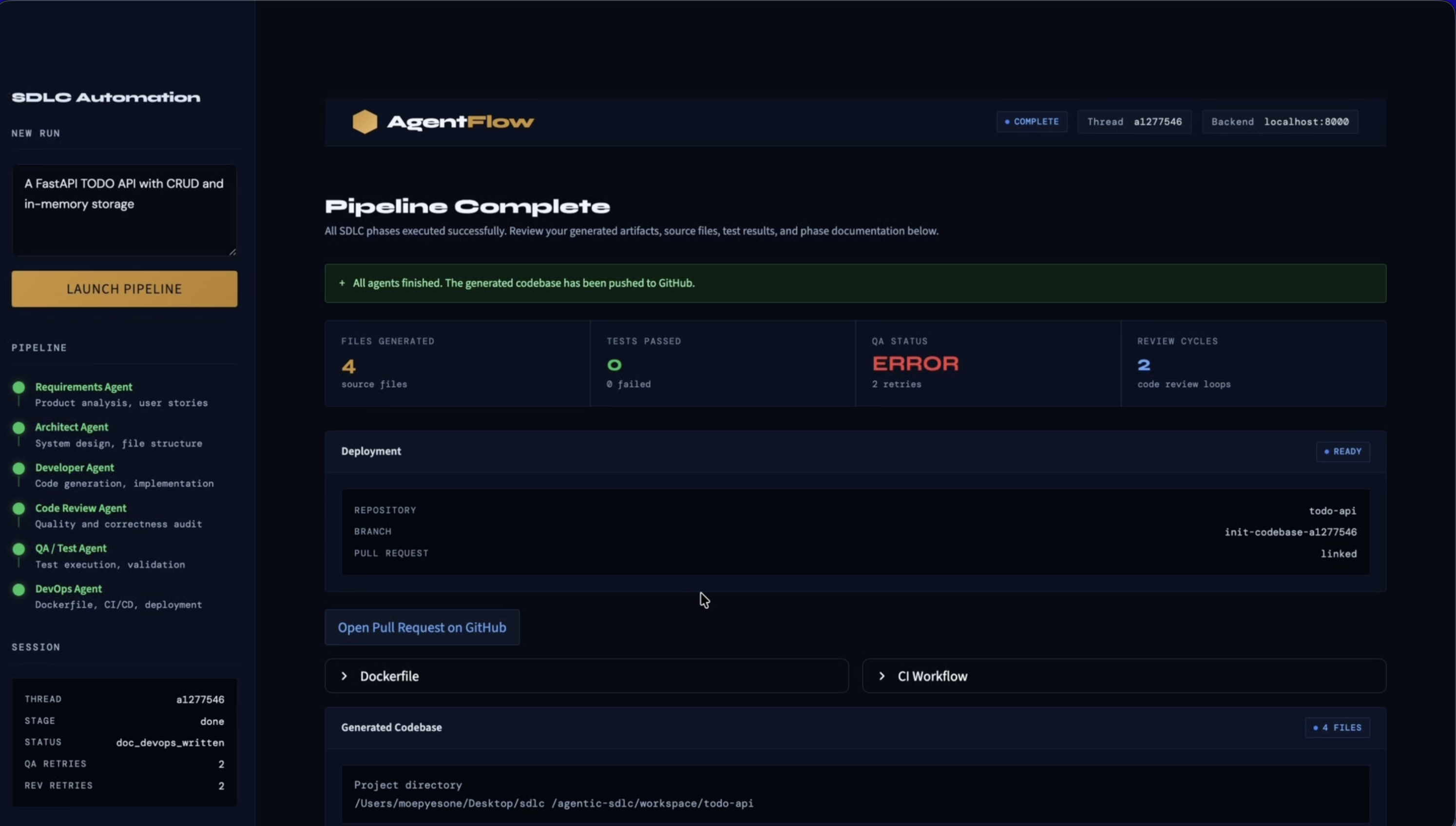
pytestagainst the generated project - The DevOps Agent produces Docker and CI files and can open a GitHub pull request
- The Docs Agent writes phase-by-phase documentation as Markdown and PDF
Workflow state is persisted using SQLite checkpoints, which also enables the rewind feature — you can roll back to any earlier checkpoint and run the pipeline again from that point.
For teams that want richer context in their generated code, optional Context7 integration lets the agents pull in relevant documentation during generation and review. GitHub integration lets the DevOps step push the finished project and open a real pull request automatically.
What I Learned
Workflow state is the hardest part. Generating a good response from an LLM is tractable. Making that response part of a recoverable, resumable, auditable workflow is the genuinely difficult problem. LangGraph's checkpoint model gave me a lot of leverage here, but designing the state schema — what to carry forward, what to discard, how to represent approval decisions — required careful iteration.
Human-in-the-loop is an architectural constraint, not a feature. I initially thought of approval steps as something I'd bolt on at the end. I was wrong. The places where humans need to intervene shape the graph structure, the API design, the UI layout, and the retry logic all at once. It needs to be designed in from the start.
End-to-end testing for agentic systems is genuinely unsolved. Unit tests and integration tests are fine for the plumbing. But validating that an LLM-driven pipeline produces good output, handles retries gracefully, and makes correct routing decisions — that's a much harder problem. The project tests cover a lot of ground, but the gap between "tests pass" and "the system works well" is wider than in conventional software.
"Local-first" is a real design constraint. Targeting developers running this on their own machines — rather than a hosted service — shaped almost every decision about setup complexity, dependency management, service startup, and defaults.
Challenges
Multi-service local startup is the biggest friction point for new users. Running a LangGraph backend, a FastAPI server, and a Streamlit dashboard in separate terminals, while also managing environment variables for up to four external services, is a lot to ask before the first run completes. A one-command startup script is the most important thing I haven't built yet.
Integration drift is a slow-burning concern. OpenAI, LangGraph, Context7, and the GitHub API all evolve independently. Each one can break a workflow step in subtle ways that are hard to catch without a real end-to-end test run.
Generated output quality is inherently variable. The pipeline is reliable as a structure, but the LLM outputs feeding into it are not deterministic. Code review catches some issues, QA catches others, and human approval catches the rest — but calibrating when to retry automatically versus when to surface a failure to the user is still something I'm tuning.
Scope creep temptation is real. An SDLC pipeline can grow in almost any direction: better prompts, more agent stages, richer UI, tighter GitHub integration, evaluation frameworks. Keeping the project scoped to what genuinely adds value — rather than what's interesting to build — was a constant discipline.
What's Next
The clearest path forward involves three things: a single-command startup that removes the multi-terminal friction, stronger end-to-end test coverage that can run against real pipeline executions, and a more flexible deployment target layer that isn't entirely GitHub-centric.
The longer-term goal is making this a useful reference implementation — a project people can fork, adapt, and learn from when they want to understand what a thoughtful human-in-the-loop AI delivery workflow actually looks like in practice.

Log in or sign up for Devpost to join the conversation.