-
-
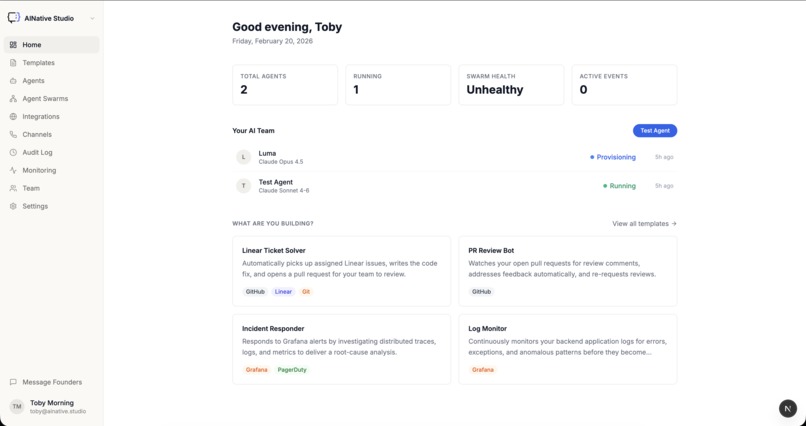
Landing page
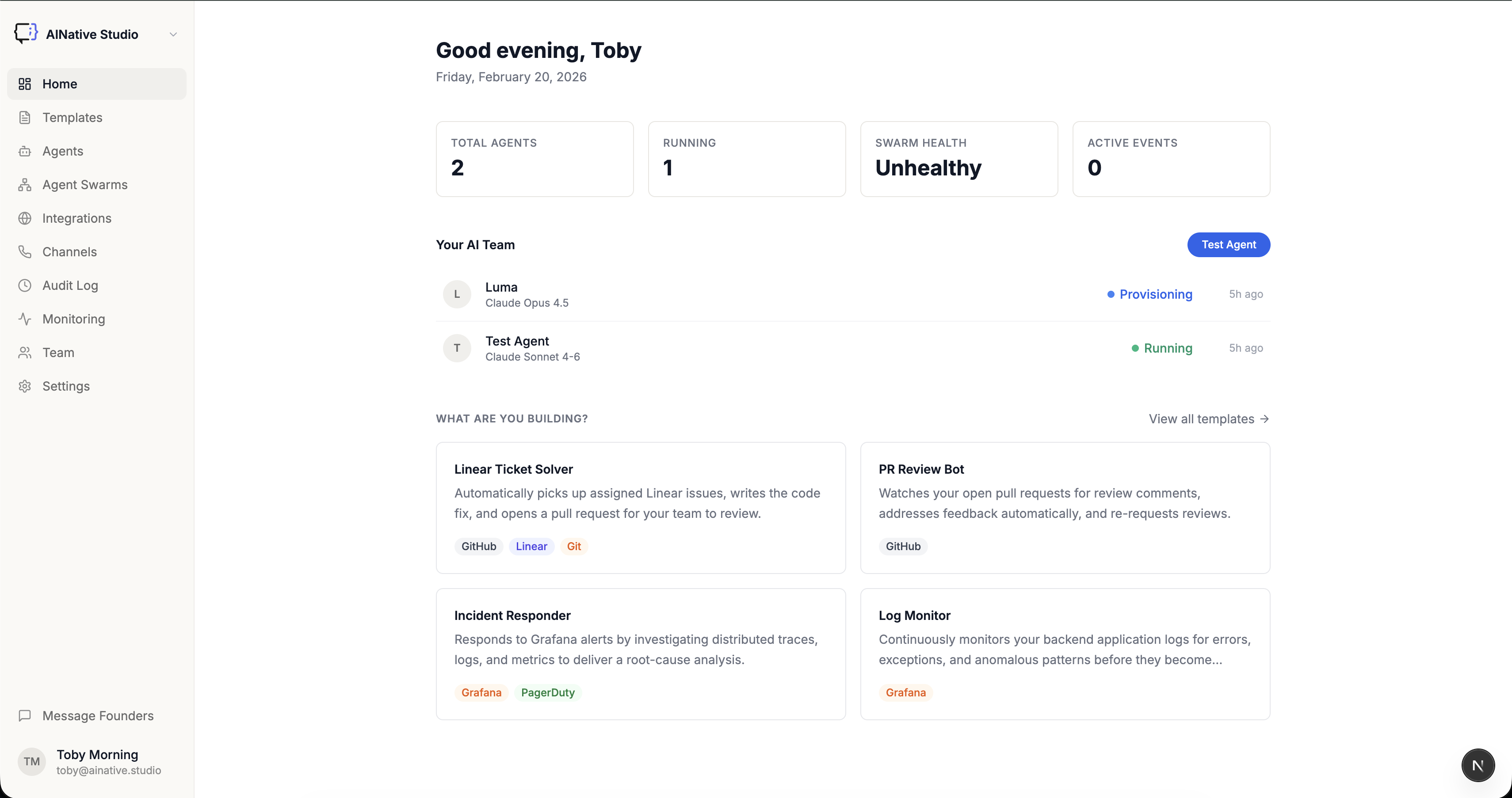
Inspiration
We kept hitting the same wall: building software still requires a human to babysit every step — spinning up services, wiring APIs, handling failures, restarting after crashes. We asked ourselves: what if a swarm of AI agents could take a product requirement doc and autonomously ship it, end to end? Not one agent doing everything, but a coordinated team — each with its own role, capabilities, and accountability — communicating over a secure mesh and recovering gracefully when things go wrong. That vision became AgentClaw.
What it does
AgentClaw turns a PRD into a running application using autonomous AI agent swarms. You describe what you want — via WhatsApp or the management dashboard — and a swarm of specialized agents self-organizes to build it. Agents are provisioned with specific capabilities, assigned tasks through a lease-based system, and communicate over an encrypted P2P network. Every workflow is crash-recoverable: if an agent fails mid-task, the system detects it, revokes the lease, and reassigns the work — no human intervention needed. The dashboard gives you real-time visibility into agent status, task timelines, swarm health, and Prometheus metrics.
How we built it
- Backend (Python/FastAPI): Service layer handling agent lifecycle, task orchestration, lease issuance/validation/expiration, and fault tolerance. PostgreSQL on Railway for persistence.
- Durable Gateway (Node.js/DBOS): WebSocket gateway with DBOS SDK for crash-recoverable workflow execution. Every agent operation survives process crashes and resumes from the last checkpoint.
- P2P Networking: libp2p with a Go bootstrap node for peer discovery via Kademlia DHT. Ed25519 message signing and verification for secure agent-to-agent communication.
- WireGuard VPN: Hub-and-spoke mesh for encrypted agent networking with automated peer provisioning and IP pool management.
- Security Layer: Capability-based authorization tokens (JWT), Ed25519 message signing, peer key store, token rotation with grace periods, and a full security audit logging system.
- Frontend (Next.js 15): Real-time dashboard with React Query polling, agent management, chat interface, and monitoring views. Built with Tailwind CSS, Radix UI, and Framer Motion.
- Monitoring Stack: Prometheus metrics, swarm health aggregation, task execution timeline, and configurable alert thresholds — all exposed through REST endpoints and the dashboard.
Challenges we ran into
- Fault tolerance at every layer. Agents crash, networks partition, databases go offline. We built a full crash-to-recovery pipeline: node crash detection triggers lease revocation, which triggers task requeue with exponential backoff. DBOS partitions switch the system to degraded mode with SQLite result buffering, and a reconciliation state machine flushes results when connectivity returns.
- Three competing task models. As the system evolved, we ended up with three separate ORM model sets for tasks and leases (SQLite-oriented, PostgreSQL-oriented, and lease-specific) with overlapping table names and different schemas. Unifying them without breaking the 690+ existing tests remains ongoing work.
- Exactly-once semantics. Preventing duplicate task execution in a distributed system with unreliable networks required idempotency keys, database unique constraints, and careful IntegrityError handling for race conditions.
- Clock skew in P2P messaging. With agents running on different machines, message timestamp validation needed a tolerance window (5 minutes past, 30 seconds future) to avoid false rejections while still preventing replay attacks.
Accomplishments that we're proud of
- 690+ tests covering unit, integration, networking, P2P protocols, security, and API layers.
- Zero-loss task pipeline: Between DBOS durable workflows, SQLite result buffering, and the reconciliation state machine, no completed work is ever lost — even through cascading failures.
- WhatsApp as a control plane. You can provision, pause, resume, and monitor agent swarms from a WhatsApp conversation. Natural language commands get parsed and routed to the orchestrator.
- Capability-based task matching. The system doesn't just assign tasks randomly — it matches task requirements (GPU, CPU, memory, model) against node capabilities, issues time-bounded leases, and handles late/invalid results gracefully.
- Full observability from day one. Prometheus metrics, swarm health snapshots, task execution timelines, and configurable alert thresholds — not bolted on, but built into the architecture.
What we learned
- Durable execution changes everything. DBOS workflows meant we could stop writing defensive retry logic and focus on business logic. If the process dies, the workflow picks up where it left off.
- Design for degraded mode first. Assuming everything works is a trap. Building partition detection and result buffering early saved us from data loss scenarios we would have discovered painfully in production.
- Leases beat locks in distributed systems. Time-bounded leases with automatic expiration are far more resilient than distributed locks. A crashed node's work gets reclaimed automatically instead of deadlocking the system.
- P2P networking is hard but worth it. libp2p with DHT-based discovery eliminated our dependency on a central message broker. The Ed25519 signing layer gave us message authenticity without a PKI.
- Mock early, integrate late. The frontend's service singleton pattern (100% mock, zero real HTTP calls) let the UI team move independently while the backend API stabilized.
What's next for AgentClaw
- Unify the data model. Consolidate the three competing task/lease model sets into a single PostgreSQL-backed schema.
- Real frontend integration. Replace the mock service layer with actual API calls to the backend, add WebSocket streaming for live agent chat, and implement the missing audit log and settings pages.
- Multi-model agent specialization. Let agents dynamically select models (Claude, GPT, local LLMs) based on task type — code generation gets a different model than testing or documentation.
- Agent-to-agent delegation. Enable agents to break down complex tasks and delegate subtasks to other agents in the swarm, creating recursive work decomposition.
- Production hardening. Move PeerKeyStore to database backing, replace placeholder signature validation with full Ed25519 verification, resolve the Pydantic v1/v2 inconsistencies, and add dark mode to the dashboard.
- Open source the core. Package the orchestration engine and P2P protocol layer as standalone libraries so others can build their own agent swarms.
Built With
- nextjs
- python
- railway
- react
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.