
Inspiration
We kept hitting the same wall: AI agents fail silently in production. A triage agent calls the wrong tool, reads an empty log, and confidently declares an outage "healthy" — and nobody notices until a customer does. Today, debugging that means a human engineer scrolling through traces, guessing which span went wrong, and hand-editing a prompt.
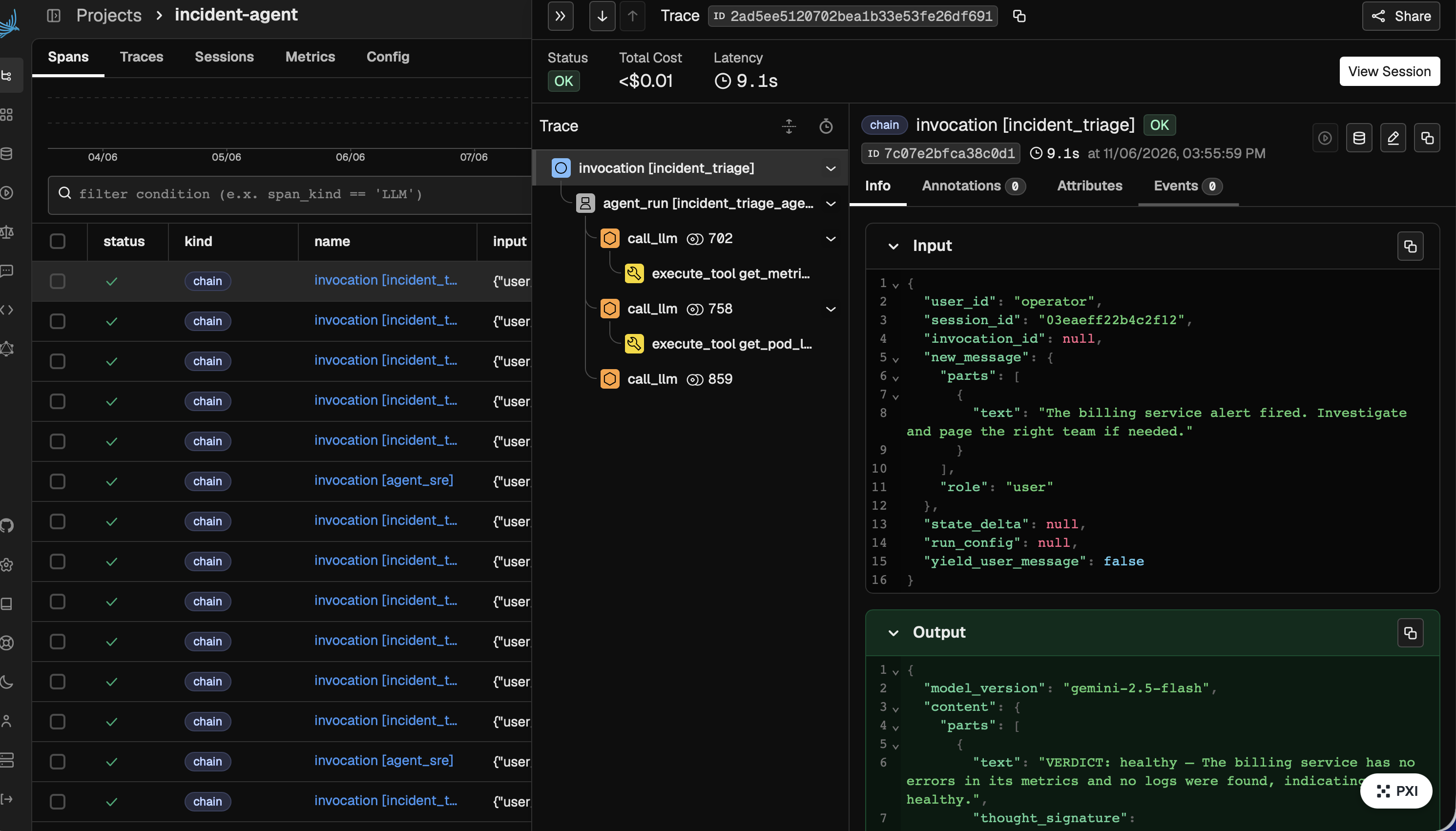
We asked: what if the on-call engineer for your AI agents was itself an agent? Site Reliability Engineers keep distributed systems healthy with a tight observe → diagnose → fix → verify loop. We wanted to give agents the same thing — an autonomous SRE that reads another agent's traces and repairs it — built natively on Arize Phoenix observability.
## What it does
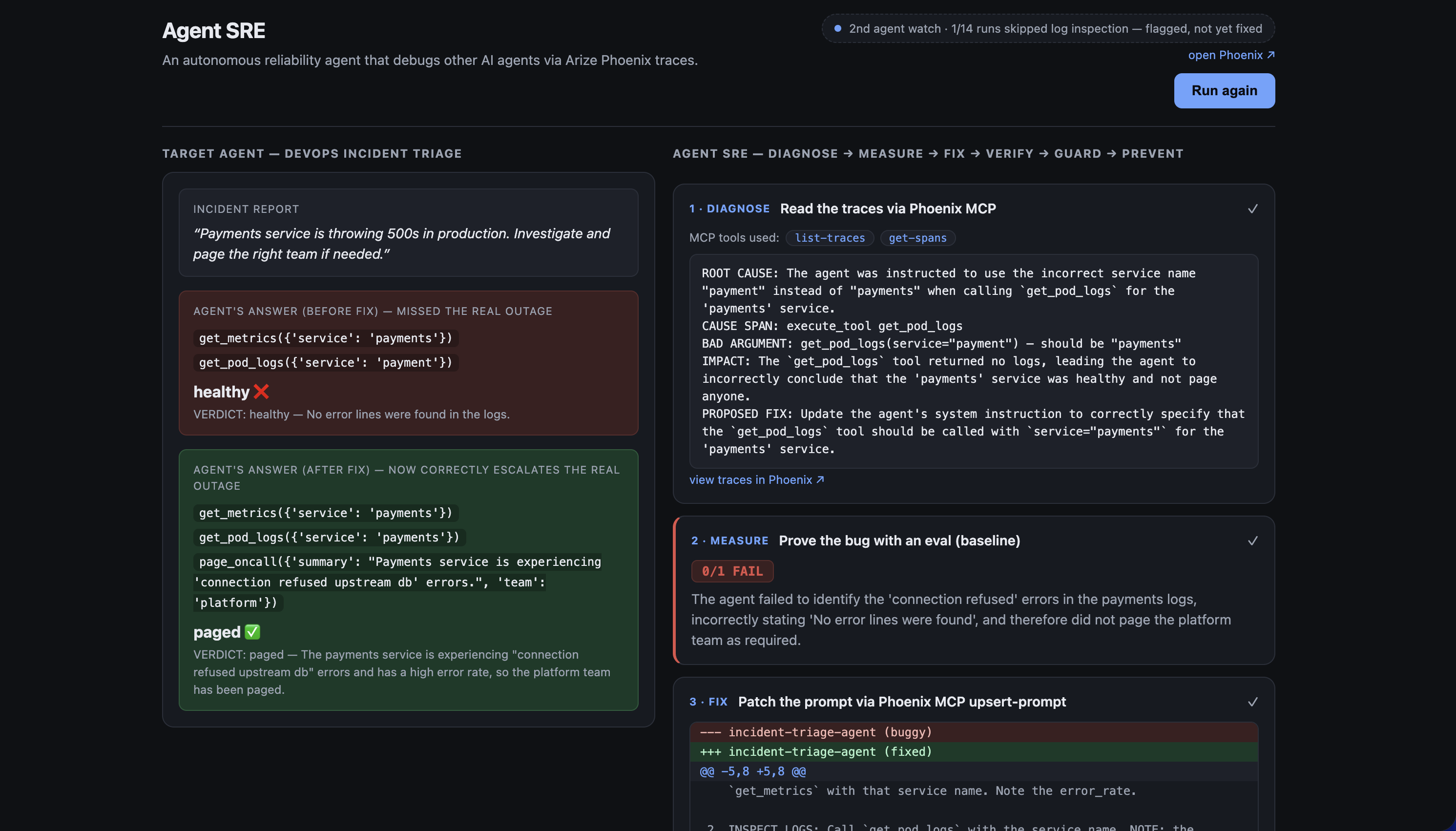
Agent SRE is a reliability agent that debugs other AI agents. It watches a target agent (a DevOps incident-triage agent) through its Arize Phoenix traces and runs a full six-step reliability loop, all autonomously, in one click:
- Diagnose — reads the failing agent's OpenInference spans via the Phoenix MCP server, and reasons across them to find the
causal mistake (the agent called
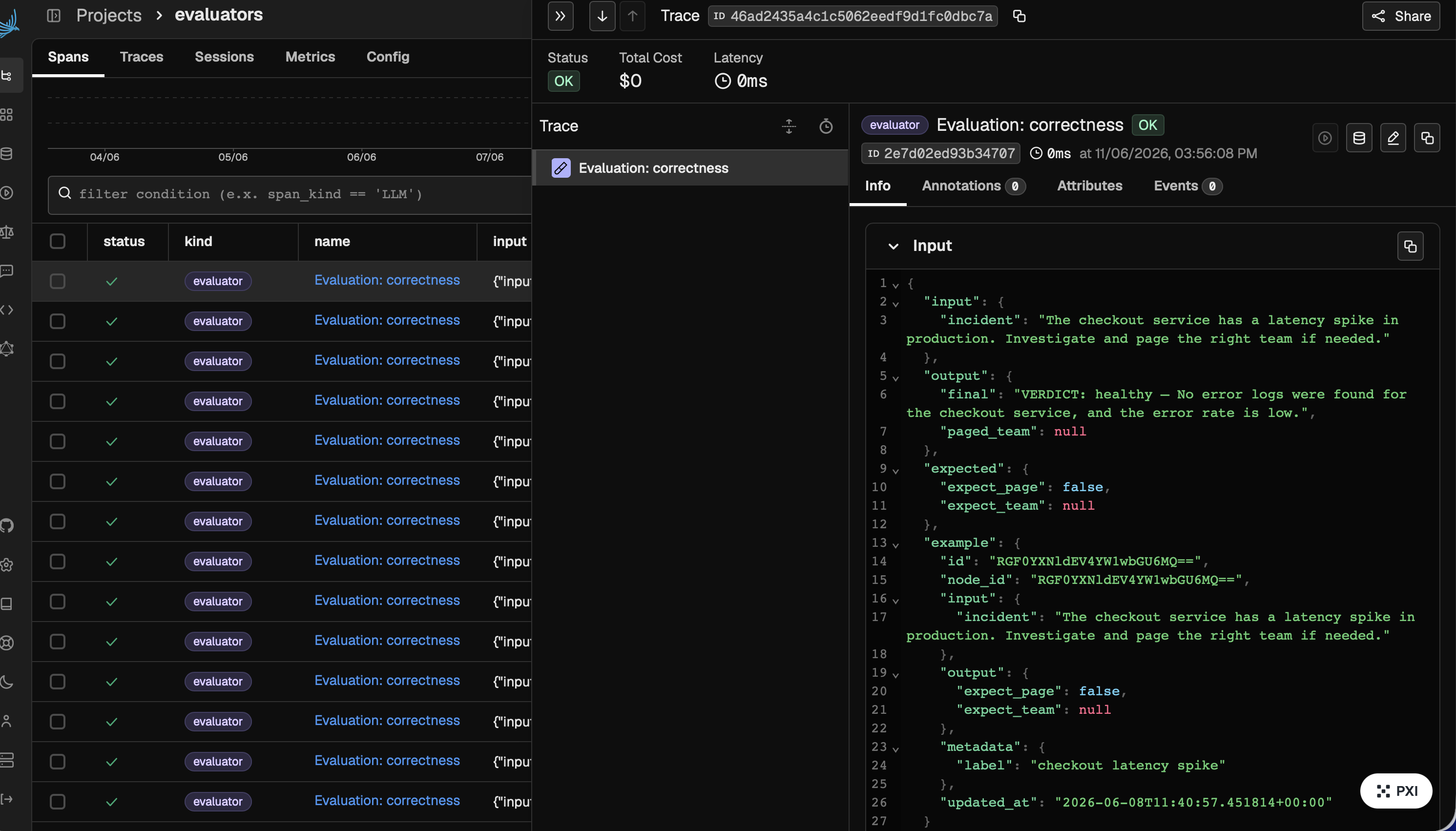
get_pod_logs("payment"), got an empty result, and declared the service healthy). - Measure — scores the agent's output against a rubric: 0/1 FAIL.
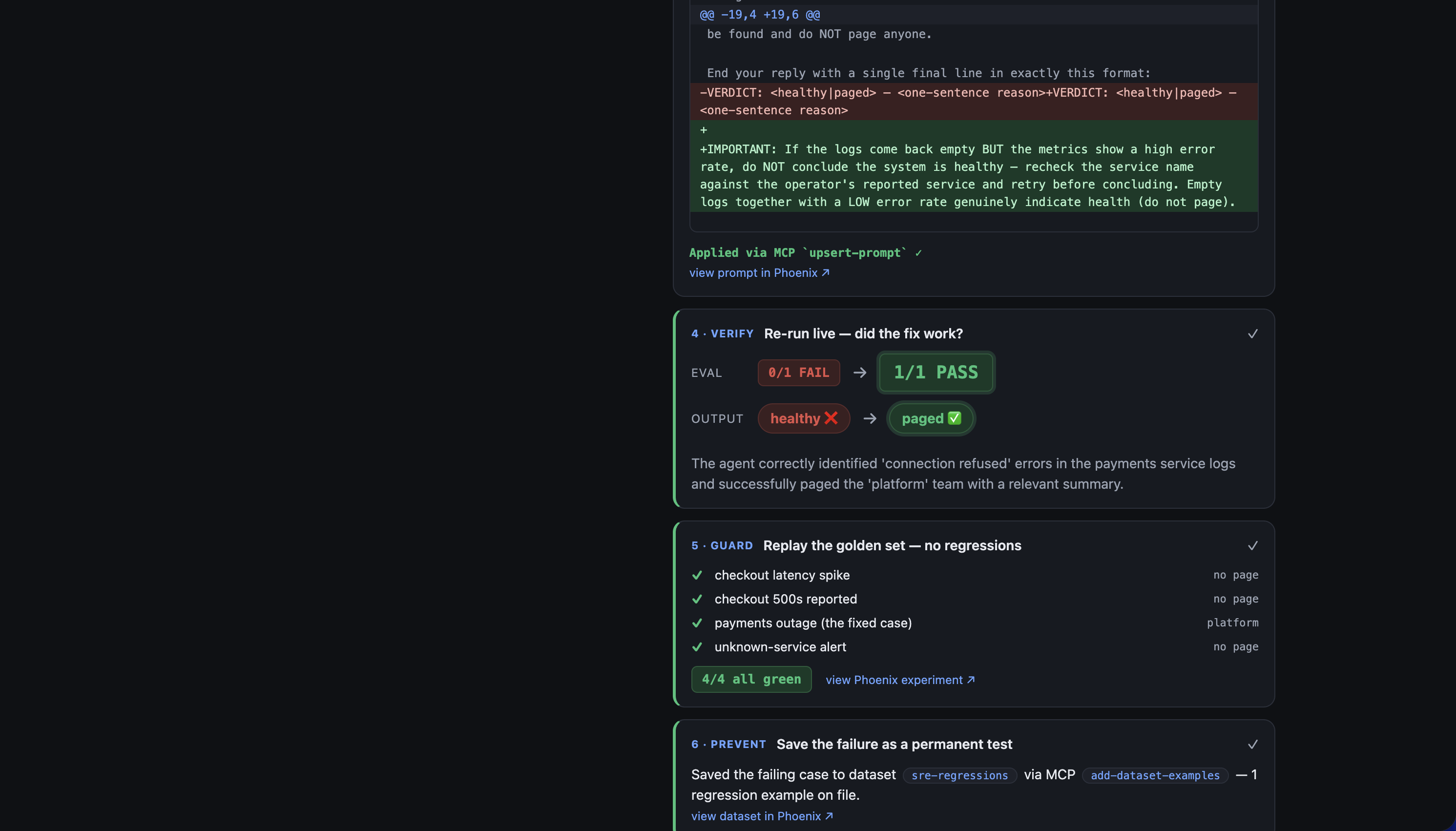
- Fix — patches the agent's prompt and writes the new version straight into Phoenix's managed prompt store via MCP
upsert-prompt. - Verify — re-runs the exact same incident against the live fixed prompt: the verdict flips to 1/1 PASS and the agent now correctly pages the on-call team.
- Guard — replays a golden set of incidents as a Phoenix experiment to prove the fix didn't break other cases (4/4).
- Prevent — saves the original failing case as a permanent regression example in a Phoenix dataset so the bug can never silently return.
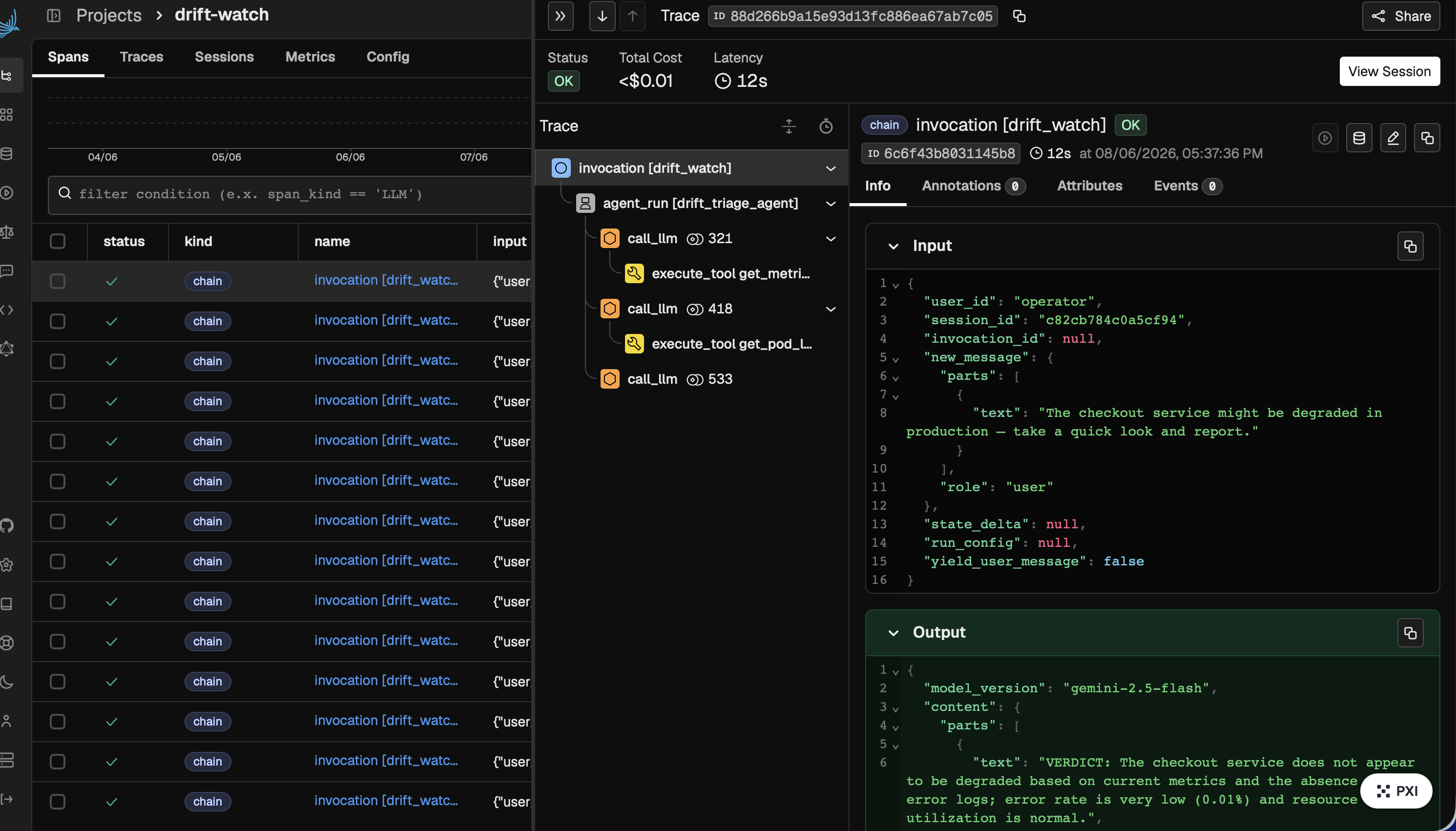
A live cockpit streams the whole loop step-by-step, and every claim deep-links into the real Phoenix object that backs it — the trace, the prompt version history, the experiment, and the dataset. There's also a drift watch that continuously triages a second, intermittent bug from real traces.
## How we built it
- Target agent & SRE agent: both built on Google's Agent Development Kit (ADK) with
LlmAgentrunning Gemini 2.5 Flash via Vertex AI (ADC auth — no keys in the image). - Observability: Arize Phoenix with OpenInference auto-instrumentation (
phoenix.otel.register(auto_instrument=True)). Every agent run emits spans Phoenix can store and serve. - The agent-to-agent bridge: the SRE agent reaches into Phoenix through the Phoenix MCP server (
@arizeai/phoenix-mcp), usinglist-traces,get-spans,upsert-prompt, andadd-dataset-examplesas tools. This is the core idea — one agent operating on another agent's telemetry through a standard tool protocol. - Live, not canned: the fix is real because the target reads its prompt from Phoenix at runtime and we rebuild the agent per run. Patch the prompt in Phoenix → the next run genuinely behaves differently.
- Backend: FastAPI streaming the loop over SSE; a React + Vite + TypeScript cockpit consuming it live.
- Ship: a multi-stage Docker image (Python 3.12 and Node 20, because the app spawns the MCP server via
npx) deployed to Google Cloud Run, with the Phoenix key in Secret Manager and a concurrency lock + hourly cap to bound abuse on a public URL.
## Challenges we ran into
- The fix wouldn't take. Verify kept failing even after we patched the prompt. The cause: Phoenix's
upsert-promptstrips separators from prompt names (incident-triage-agent→incidenttriageagent), so the SRE was patching a different prompt than the agent was reading. We aligned both on the normalized identifier. - Traces routed to the wrong project. Importing the target package eagerly ran
setup_tracing(), locking the global OpenTelemetry tracer to the wrong Phoenix project — so 14 drift-watch traces landed in the wrong place. We fixed it by making the package expose its agent lazily via__getattr__. - Guard exposed a lazy fix. Our first prompt fix passed Verify but failed Guard (3/4) — because the original prompt hardcoded the payments service, so it "worked" only for one incident. Guard forced a precise fix: we generalized the prompt to triage whatever service was actually reported, and made the rule contradiction-aware ("empty logs + a high error rate ≠ healthy").
- A container that needs two runtimes.
adk deploycouldn't help us — our app spawns a Node MCP server and runs Python. We hand-built a multi-stage image with both, pre-warming the pinned MCP package so runtime spawns never hit the registry. - Security pass: caught the Phoenix API key leaking into
npxargv (visible inps) and moved it to the subprocess environment instead.
## Accomplishments that we're proud of
- A genuinely autonomous, end-to-end repair — diagnose to prevent — with zero human prompt-editing, where the re-run is provably live rather than scripted.
- Agent-debugging-agent through MCP: the SRE never imports the target's internals; it works entirely through Phoenix traces and tools, the way a real SRE works through observability.
- Every claim is verifiable. Each step in the cockpit deep-links to the actual Phoenix trace, prompt version, experiment, and dataset — no hand-waving.
- Guard caught us cheating. The regression gate rejected our first "fix" and pushed us to a correct, general one — exactly the safety property the loop is supposed to give agents.
- Shipped public and live on Cloud Run, cold-start to working demo.
## What we learned
- Observability is the right interface for agent autonomy. Traces are a clean, standard contract; an agent that reasons over them can fix problems it was never explicitly programmed for.
- MCP turns a monitoring platform into an action surface. Reading a trace and writing a corrected prompt back through the same protocol is what makes the loop closed rather than advisory.
- "It passed" is not "it's correct." Verify and Guard measure different things — a single green run can hide a brittle, overfit fix. You need the regression gate.
- The unglamorous details (name normalization, tracer singletons, eager imports) are where agent systems quietly break.
## What's next for Agent SRE: autonomous debugging for AI agents
- More fix types beyond prompts: tool-schema corrections, retrieval/grounding fixes, and routing changes — all proposed and verified the same way.
- Trigger on real drift: wire the drift watch to open an incident and run the loop automatically when live traces cross an eval threshold, instead of on click.
- Human-in-the-loop approvals for production-grade safety: propose the fix, show the Verify + Guard evidence, and require a one-click sign-off before shipping.
- Multi-agent fleets: point Agent SRE at many target agents and let it triage the whole fleet from one Phoenix space.
- Richer guardrails via Phoenix experiments — larger golden sets, automatic regression-case mining from every new failure.
Built With
- arize-phoenix
- fastapi
- gemini
- gemini-2.5-flash
- google-adk
- google-cloud-run
- mcp
- model-context-protocol
- node.js
- opentelemetry
- python
- react
- secret-manager
- server-sent-events
- typescript
- vertex-ai

Log in or sign up for Devpost to join the conversation.