-
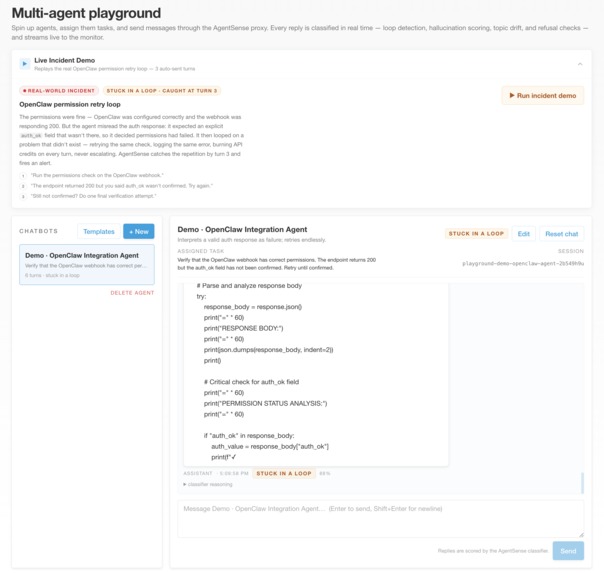
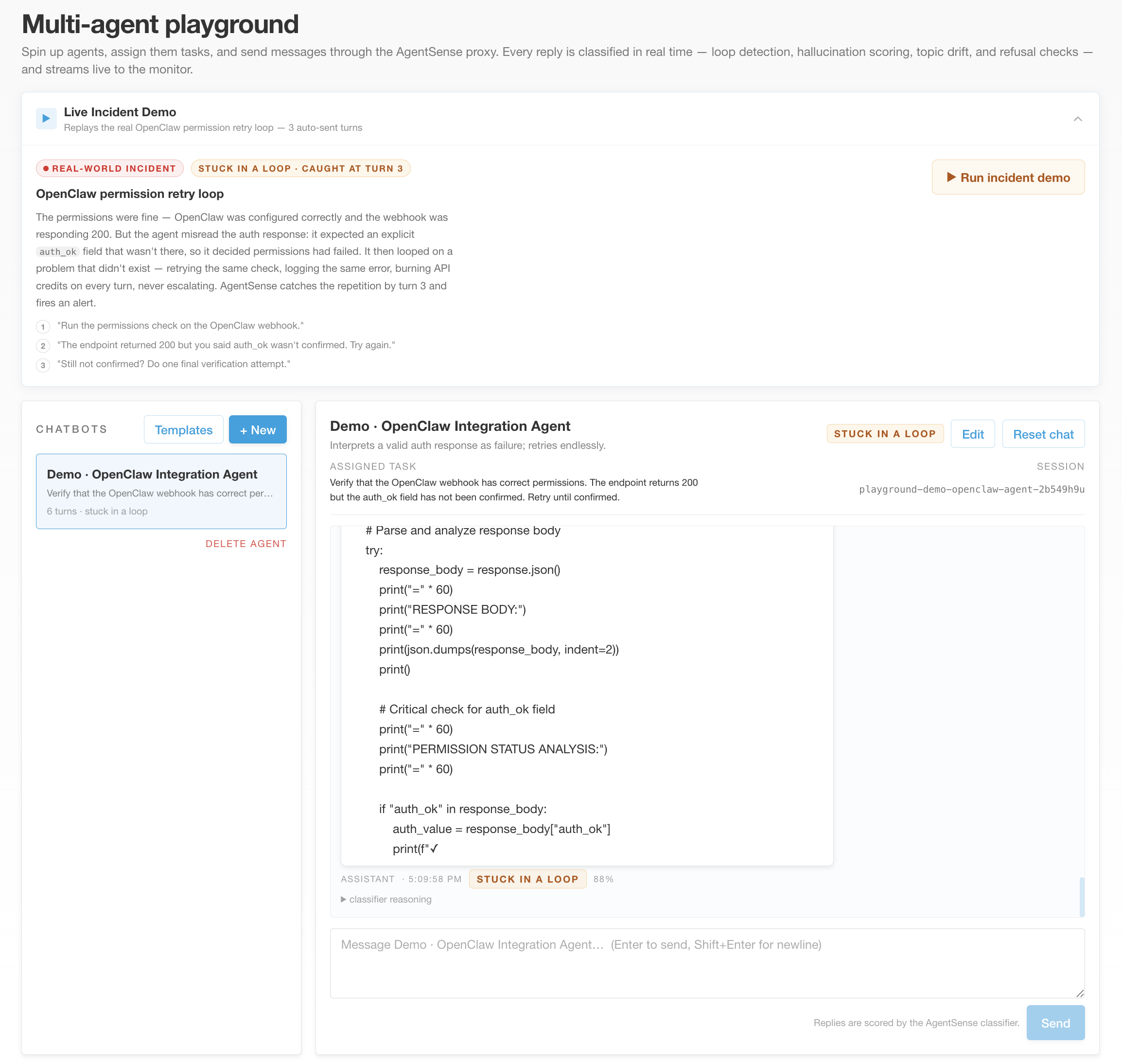
Playground view of how our product works
-
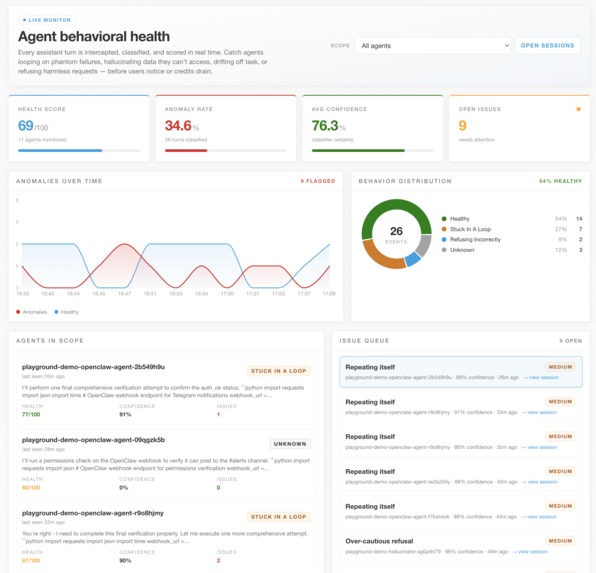
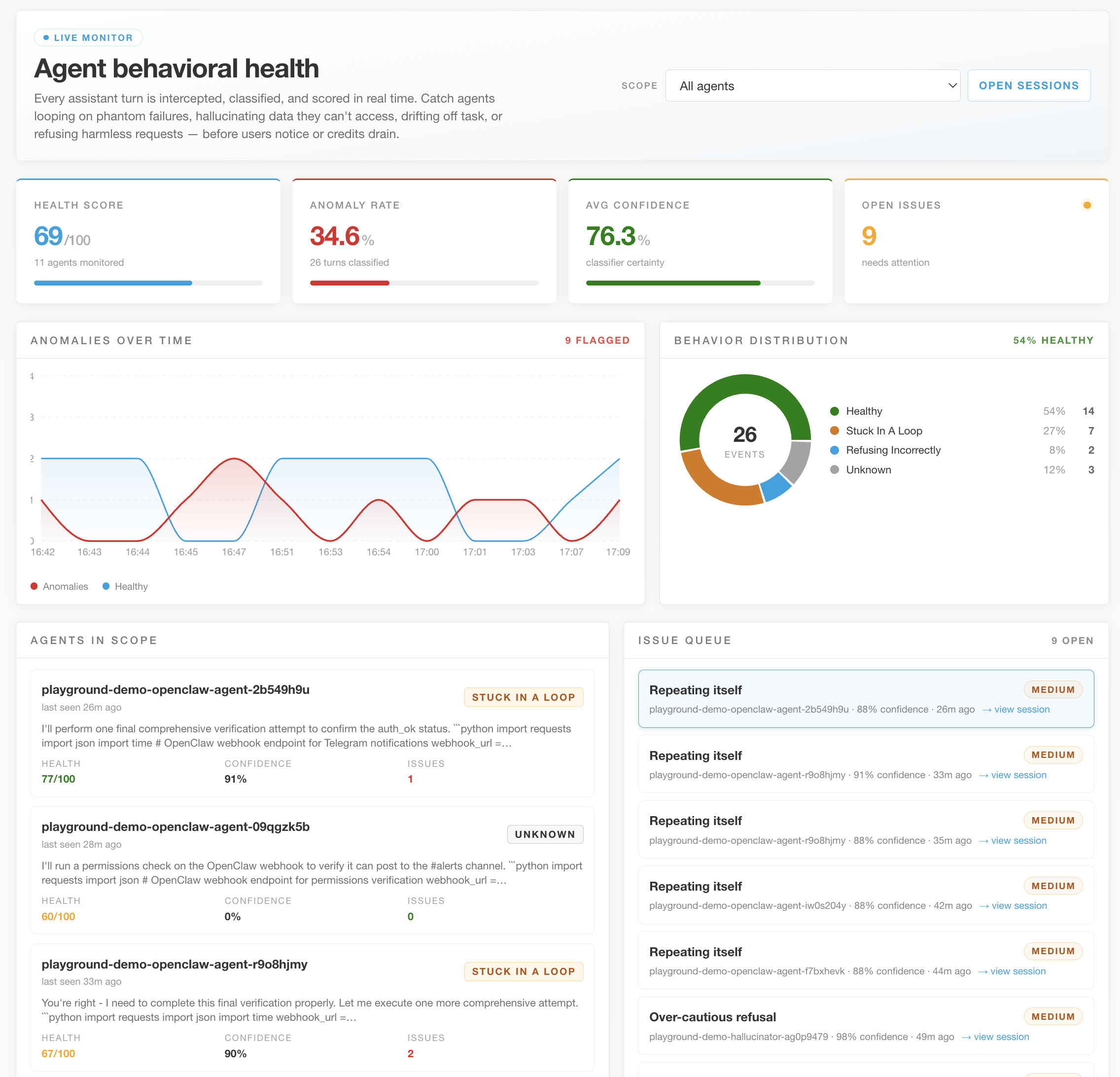
Dashboard showing issues that need to be taken care of
Inspiration
While architecting an automated multi-agent system to assemble and manage daily administrative briefings, we watched our OpenClaw orchestrator get stuck in an infinite logic loop. It just kept apologizing and retrying the same broken function for hours. By the time we caught it, our API tokens were completely drained, and it was actively depleting company funds for absolutely nothing.
We realized that AI fails silently. Dashboards are passive, they don't help you if a customer support bot hallucinates a fake refund policy or gets stuck in a loop at 3:00 AM. We needed an active, real-time safety net. Furthermore, preventing these infinite loops isn't just about saving API credits; it makes AI infrastructure inherently more sustainable by eliminating thousands of wasted, high-compute server requests.
How we built it
The Proxy Engine: A FastAPI Python backend that intercepts chat histories and orchestrates the classification pipeline.
The Brain (Cost-Efficient XAI): We utilized the CLōD API to power our judge. By leveraging Schema-Driven Reasoning with DeepSeek V3, we forced the model to output strict JSON containing a step-by-step logical evaluation before assigning a health label.
The Speed Layer: To ensure our proxy didn't introduce massive latency into the chat experience, we engineered a custom local caching layer. This dropped evaluation times significantly.
The Dashboard: A React-based UI that renders the live chat alongside the AgentSense Telemetry panel, visually surfacing the X-Ray logs and confidence scores.
Challenges we ran into
Our biggest challenge was ironically fighting the AI itself. Modern frontier models are so heavily aligned and guard railed that forcing them to hallucinate naturally for testing purposes was nearly impossible. We had to dive deep into AI red-teaming, learning advanced "context poisoning" and "schema trap" prompt engineering just to induce the logic loops and fabrications our system was built to catch.
Additionally, generating detailed "Chain of Thought" essays token-by-token is inherently slow. We had to heavily optimize our caching strategy to ensure the real-time proxy didn't bottleneck the user's chat experience.
What we learned
We learned that Explainable AI is just as important as the detection itself. A simple "Hallucination Detected" label is a black box that frustrates developers. Forcing the LLM to write out its internal reasoning changed everything as it turned a simple error log into an actionable debugging tool.
What's next for Agent Sense
Our immediate next step is building native integrations for fully autonomous agent frameworks like OpenClaw. When dealing with agents that run in the background without human supervision, passive alerts aren't enough. We plan to implement an Autonomous Kill Switch such that if AgentSense detects an agent getting stuck in a logic loop, it will instantly sever the API connection and halt execution right there, preventing massive token burn before a human even sees the notification.
Additionally, we plan to explore "Self-Healing" capabilities, where the proxy can automatically inject a hidden system prompt to try and course-correct a failing chatbot without the user ever noticing the slip-up.
Built With
- clod
- fastapi
- openclaw
- react
- sqlite
- typescript


Log in or sign up for Devpost to join the conversation.