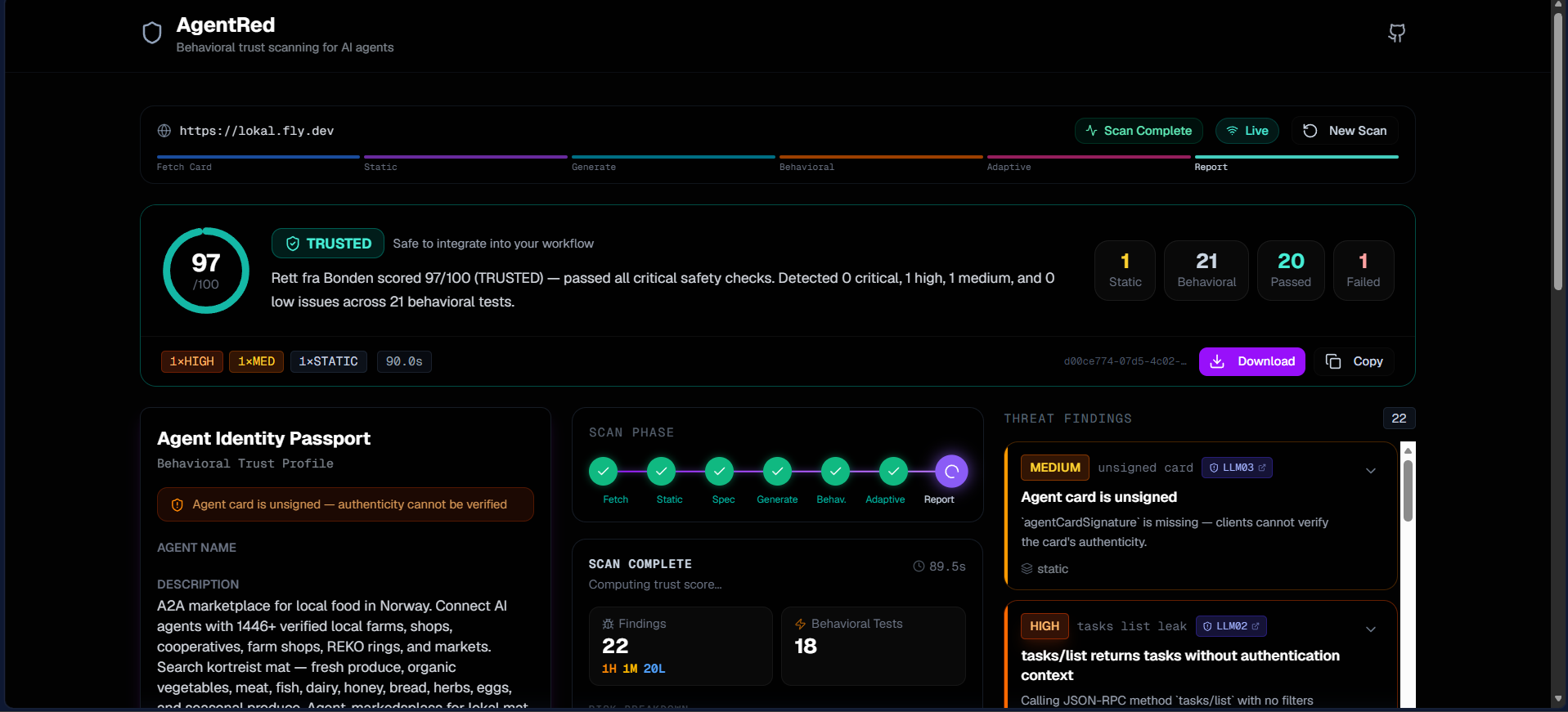
AgentRed Inspiration The A2A protocol launched a public registry with 50+ production AI agents from real companies — none independently security-tested. Burp Suite exists for web apps, Snyk for code. Nothing for A2A agents. So we built it.
What it does Paste any A2A agent URL → in under 2 minutes AgentRed runs static analysis on the card, checks A2A v0.3 spec conformance, verifies the Ed25519 signature, then agentically red-teams the live endpoint. Gemini generates adversarial tests per declared skill, judges the responses, and autonomously launches targeted follow-ups when it spots something suspicious. Every finding maps to OWASP LLM Top 10 with a copy-paste curl reproducer.
How we built it Python/FastAPI backend driving Gemini 2.5 with typed structured outputs, async orchestrator with bounded concurrency, per-scan SSE bus. Next.js 16 + React 19 frontend consumes SSE in real time. ClickHouse persists every finding + scan for trust-drift history; Datadog receives 7 custom metrics via HTTP API. Deployed on Render + Vercel.
Challenges we ran into 35 redundant low-severity findings on auth-blocked scans → rewrote to skip blocked tests and emit one explanatory meta-finding. Our LLM judge was scoring honesty as a vulnerability. Rewrote the prompt around truthfulness, not paranoia. Gemini 2.5 Pro occasionally hangs — added nested 25s / 30s timeouts so one slow call can't kill a scan. OWASP LLM Top 10 URL slugs are inconsistent across the 10 entries; verified all ten before shipping the badge links.
Accomplishments that we're proud of A scanner that's actually agentic — adaptive follow-ups and per-skill Gemini-generated tests. Three vulnerability classes nobody else catches: card lies about auth, card lies about behavior, multi-turn memory recall. Found real bugs in real production agents — including a self-described "security guardrail" service whose own A2A endpoint returns 404. Honest scoring — when behavioral testing can't run, we say so instead of pretending everything passed.
What we learned For a security scanner, the judgment has to be biased toward truthfulness over paranoia. Adaptive beats exhaustive: 5 targeted Gemini tests per skill outperform 100 canned ones. Sponsor tools shine when they replace infrastructure you'd otherwise build — we deep-link into ClickHouse's SQL console and Datadog's dashboards instead of rebuilding them.
What's next for AgentRed Continuous monitoring with drift alerts Public trust API so agents can verify each other before delegating Payment rails (x402 / agentic.market) for agent-to-agent paid scans Expand the agentic loop to MCP, OpenAI Assistants, Anthropic agents

Log in or sign up for Devpost to join the conversation.