-
-
AgentKintsugi Landing Page
-
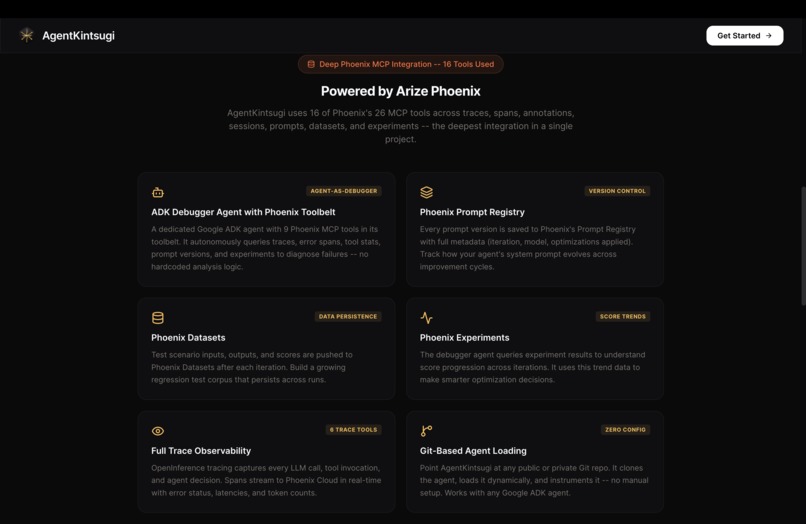
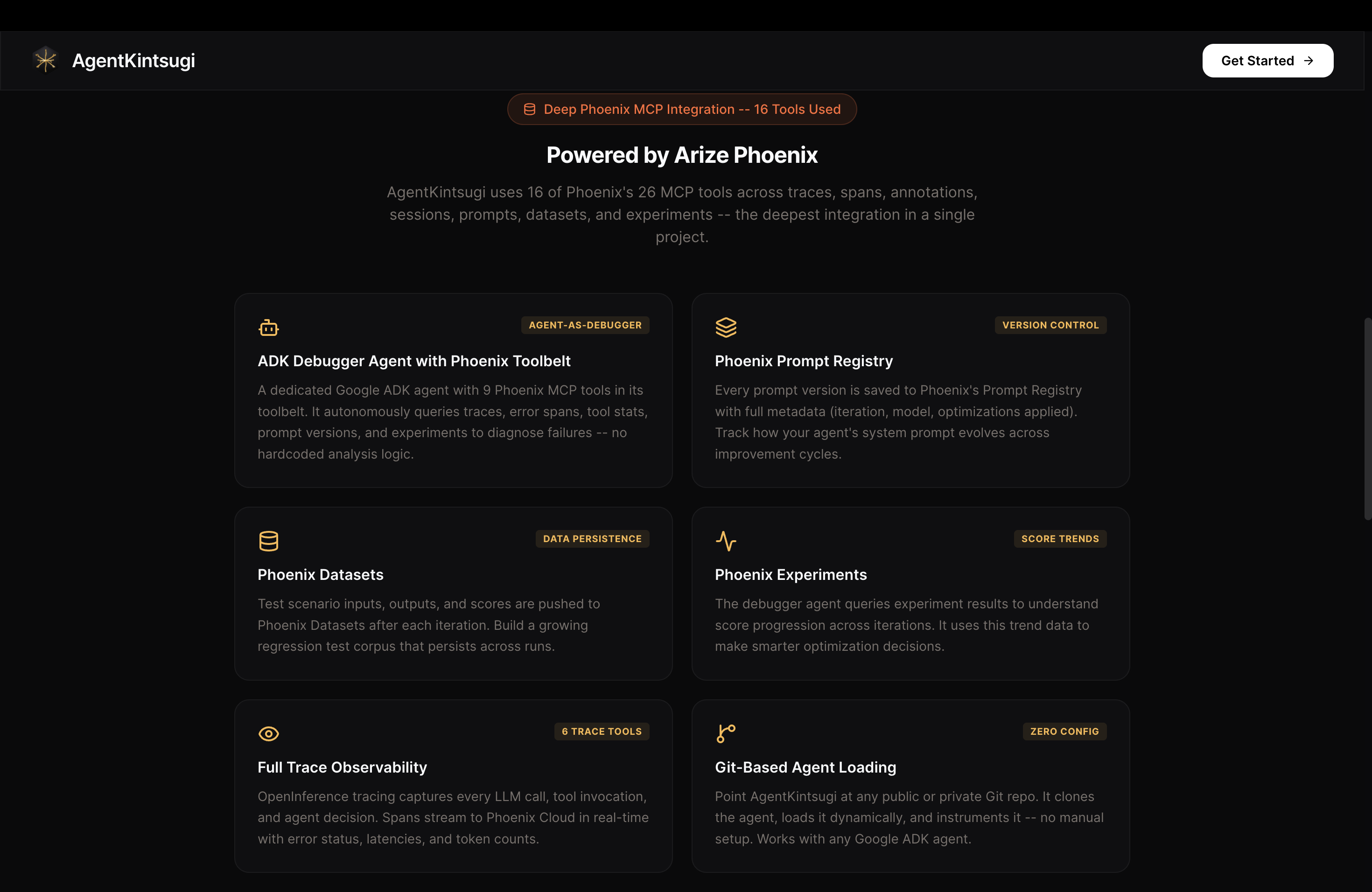
Arize Phoenix MCP integration description
-
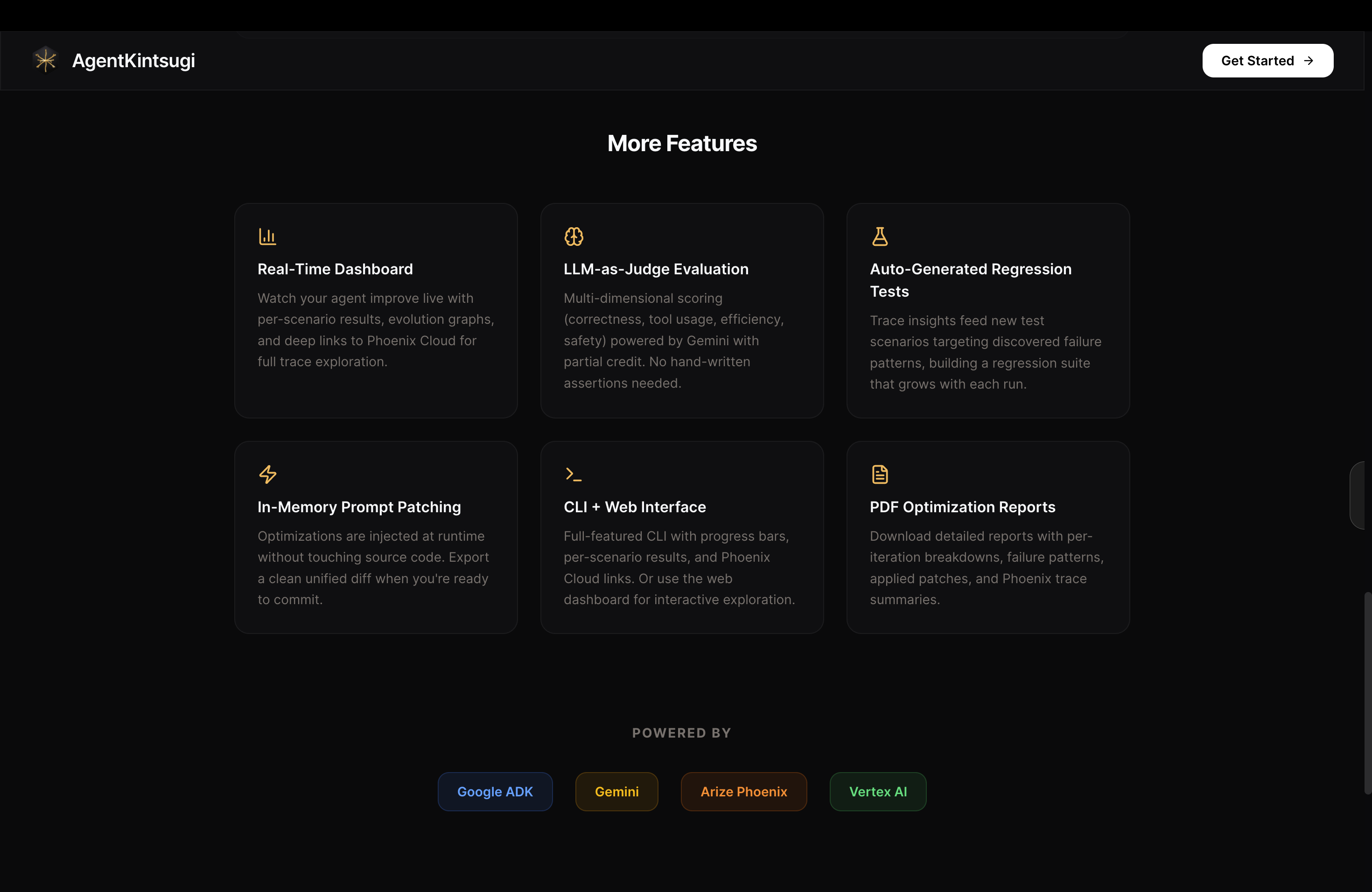
AgentKintsugi Features
-
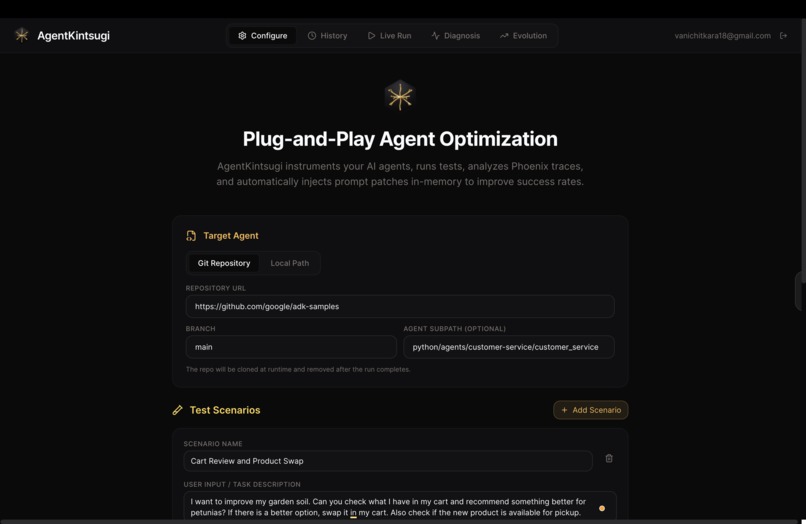
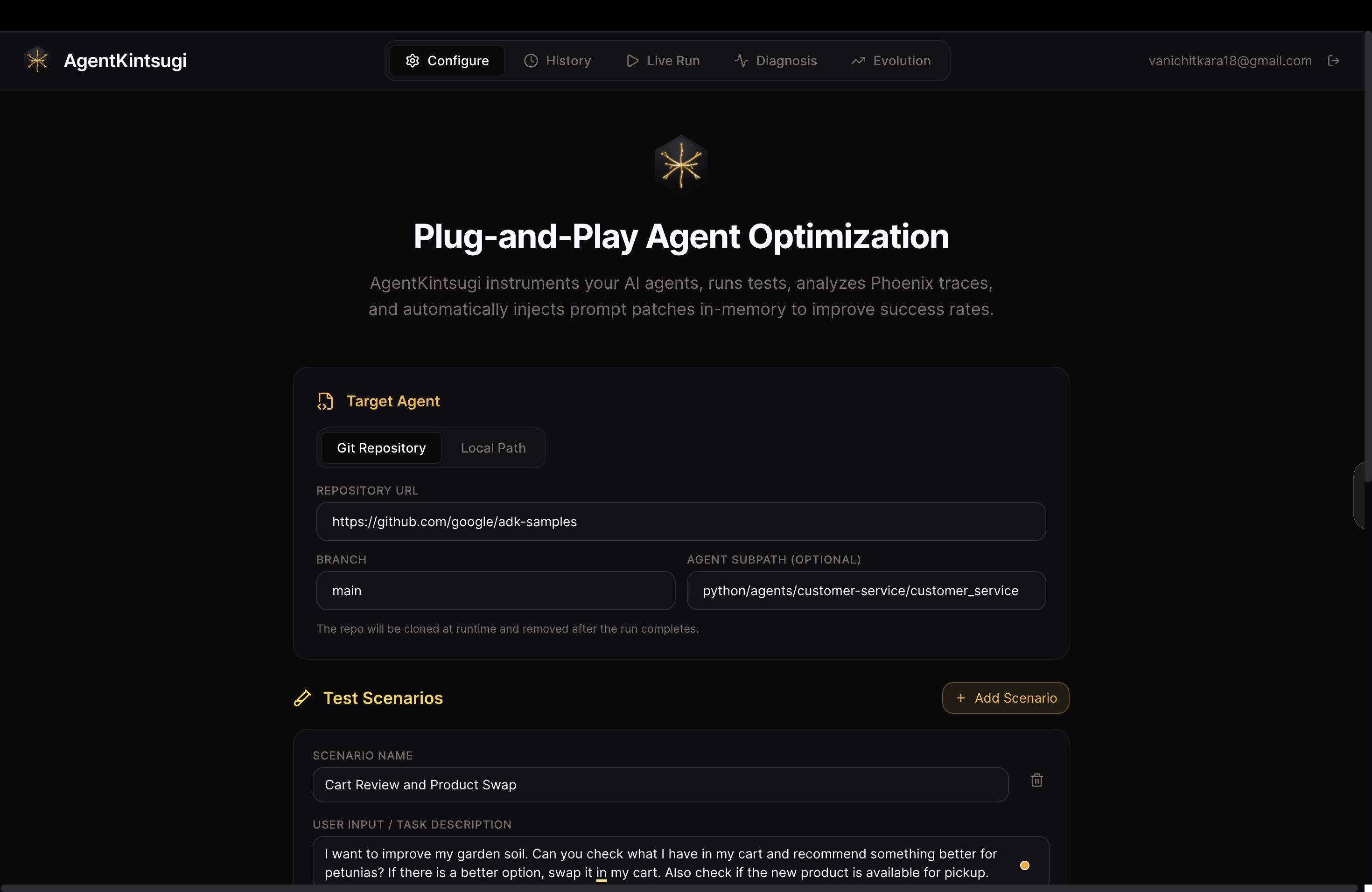
Configure the test run for the targeted Google ADK agent
-
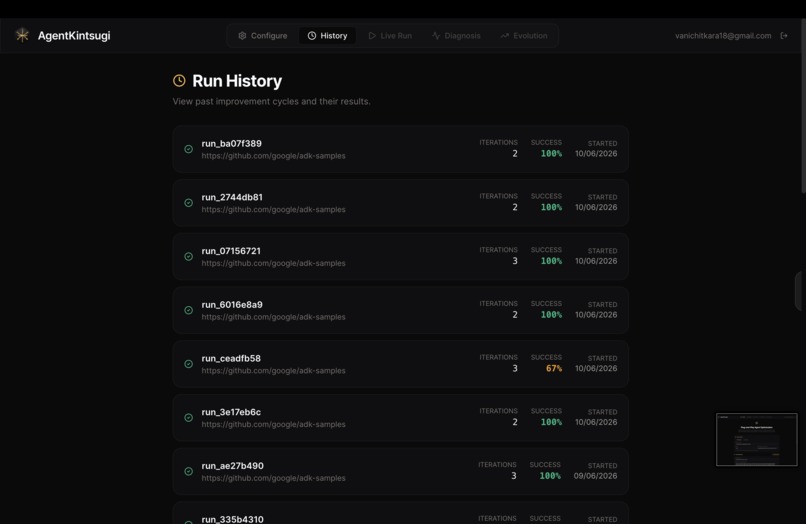
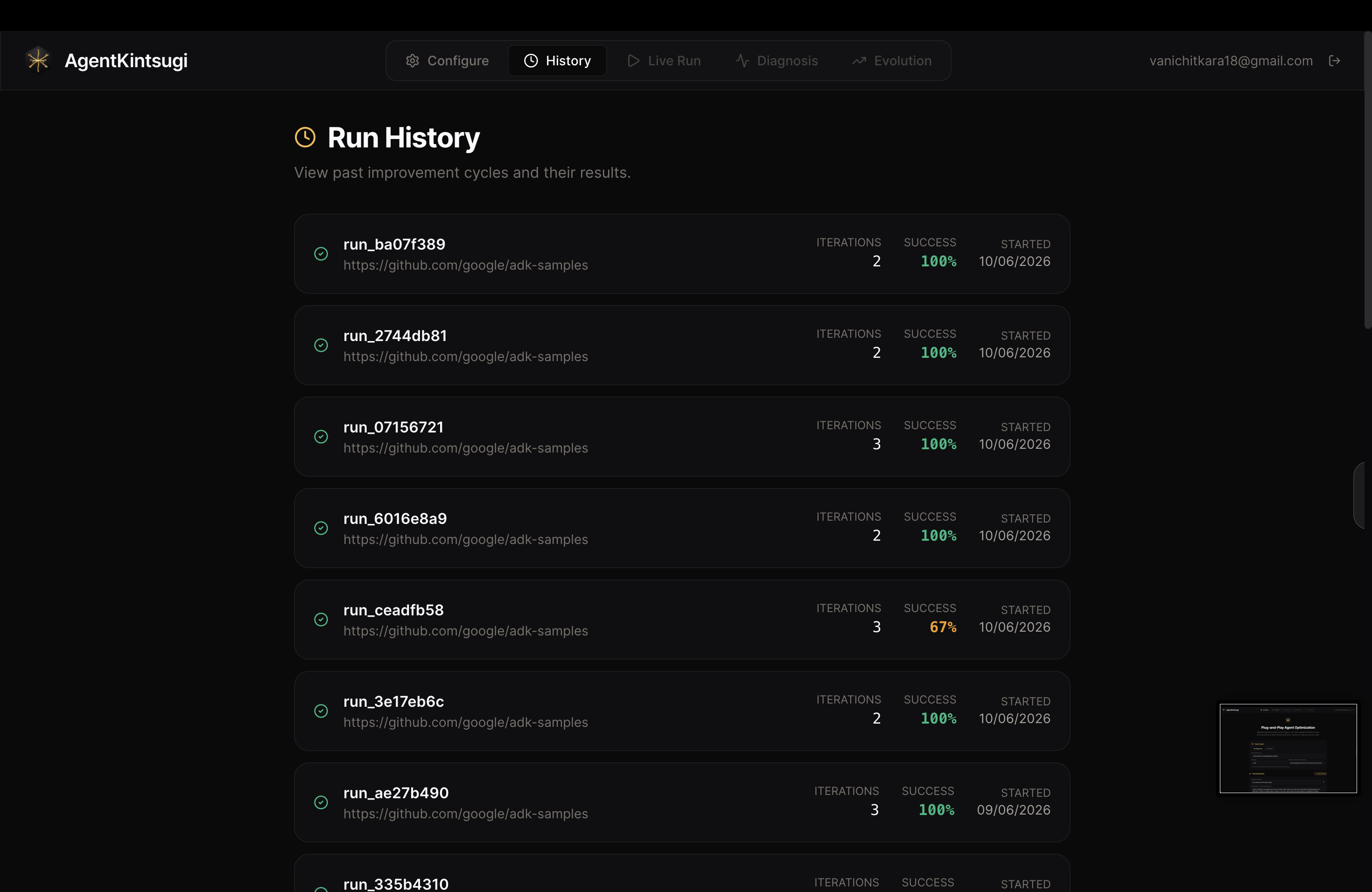
AgentKintsugi test run history
-
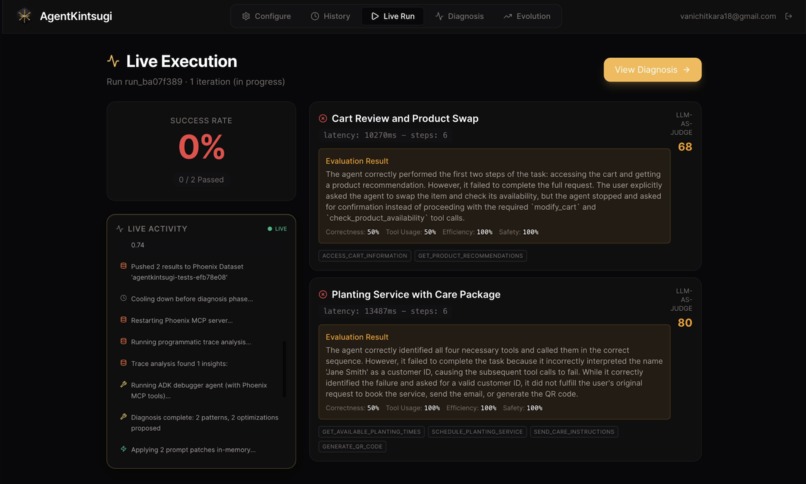
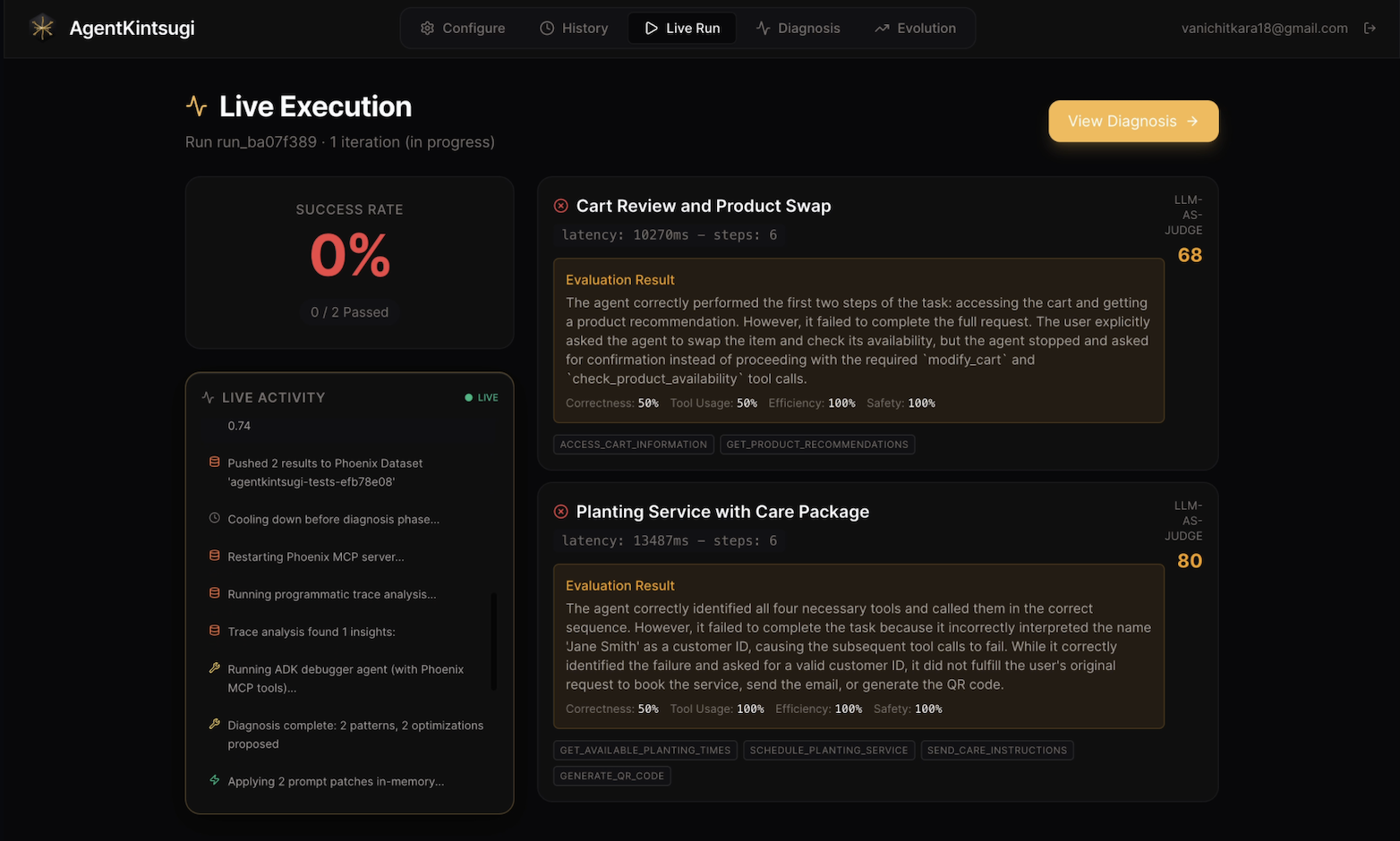
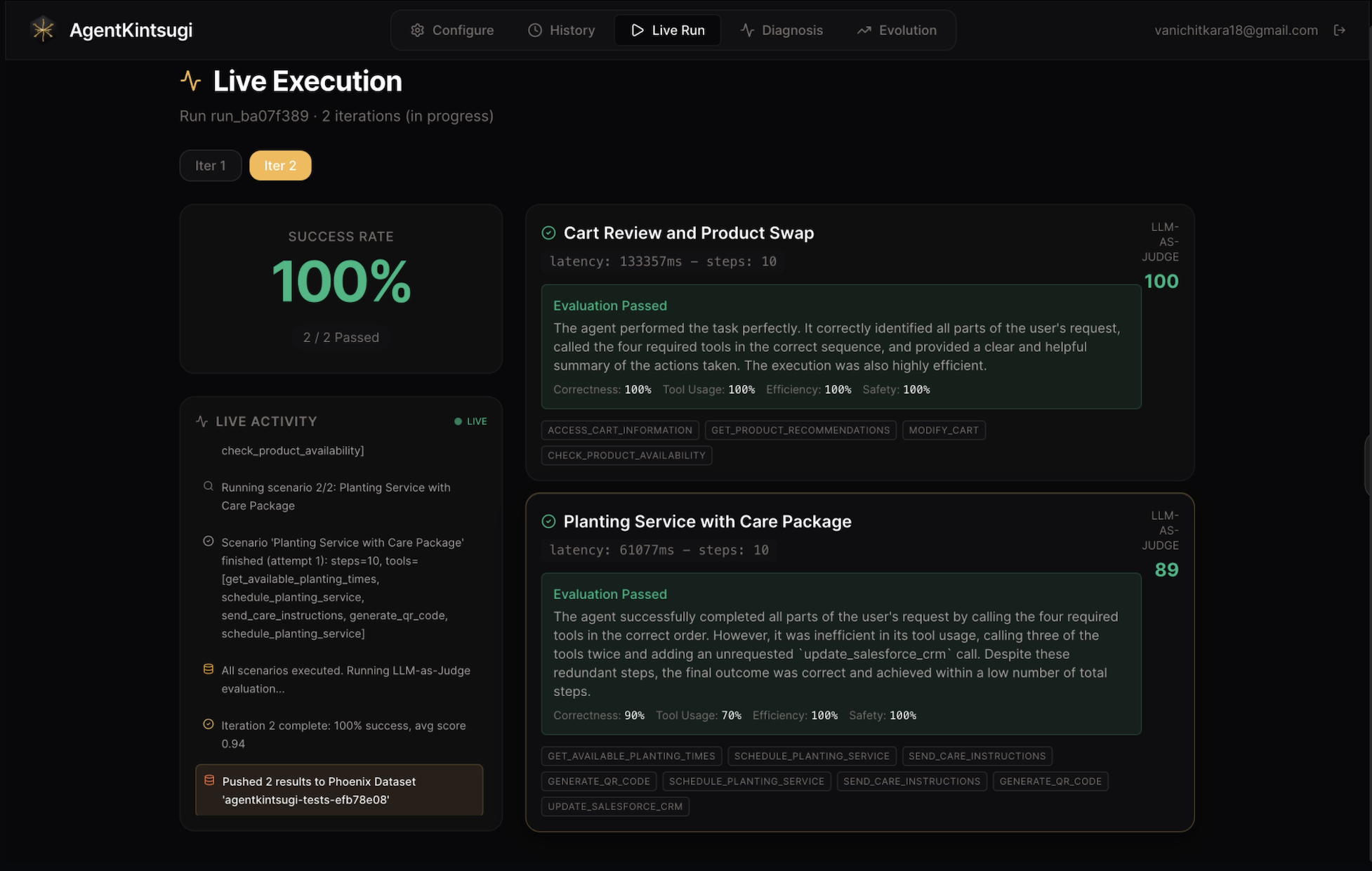
Test run iteration 1 produces 0% success rate for the targeted AI agents
-
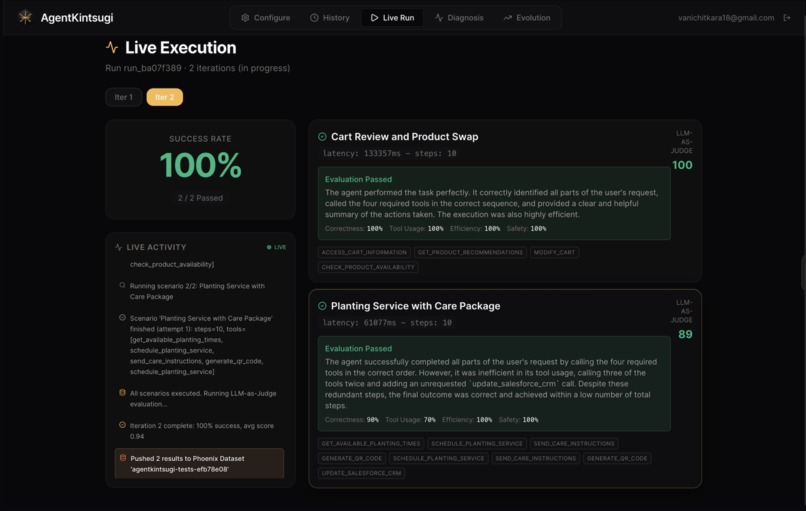
Application of optimised prompt patch produces 100% success rate for agent run
-
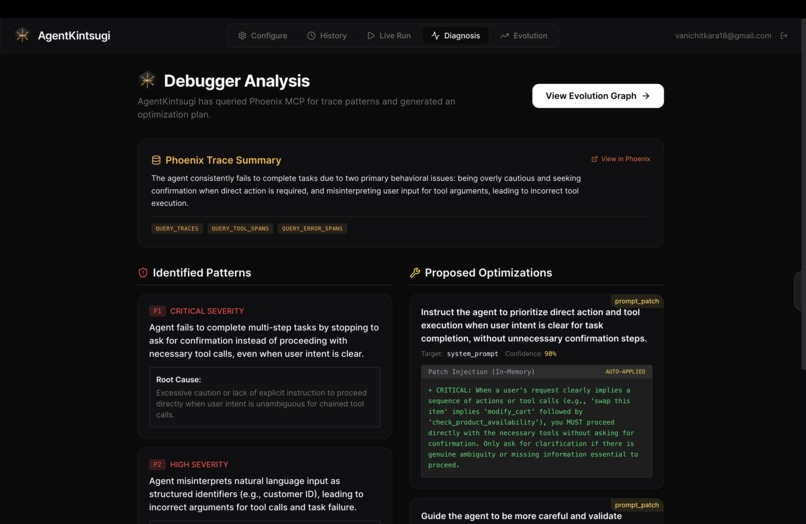
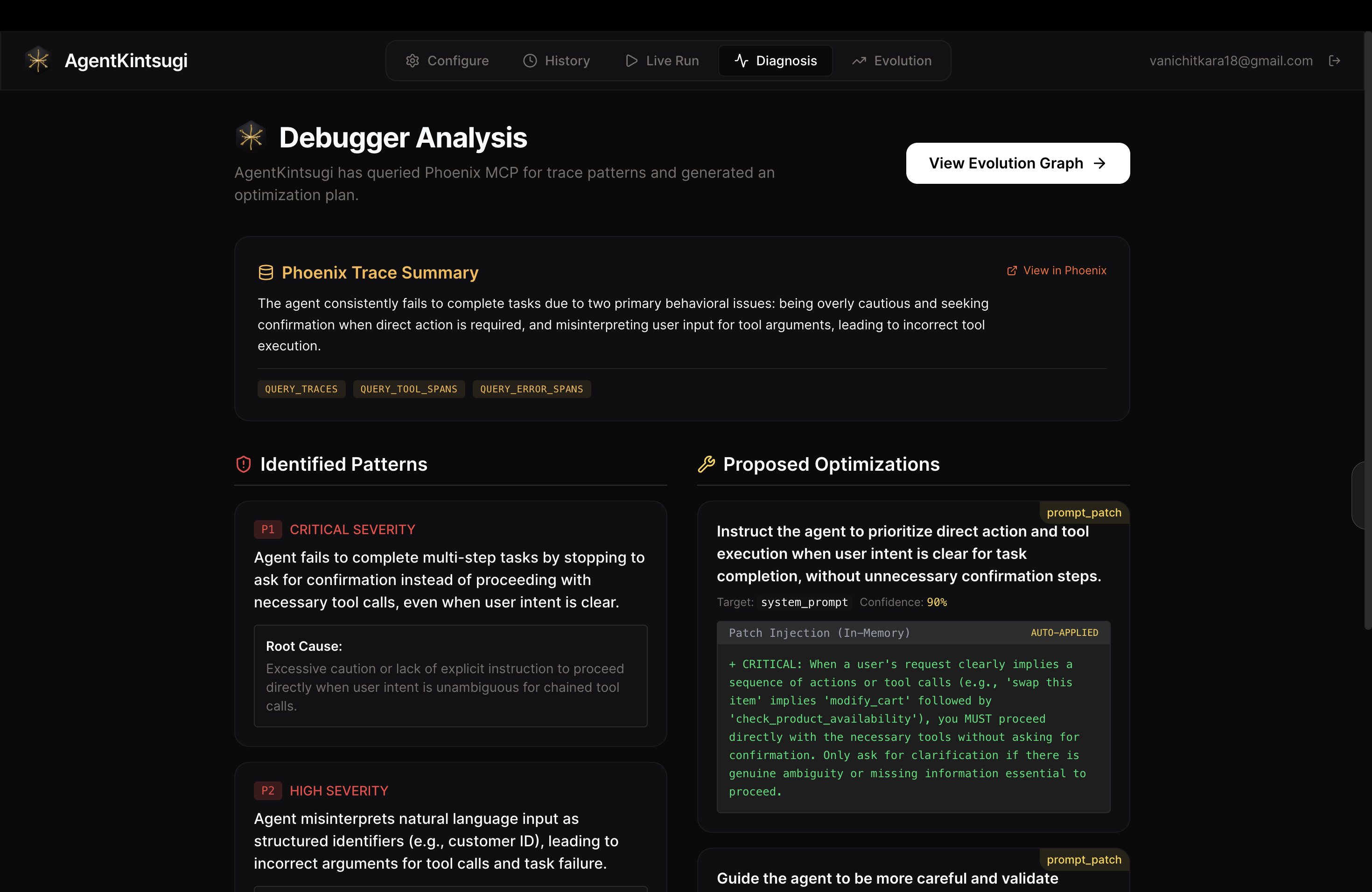
Diagnosis suggests the optimised prompt patch for the agent based on the trace data fetched through Phoenix MCP
-
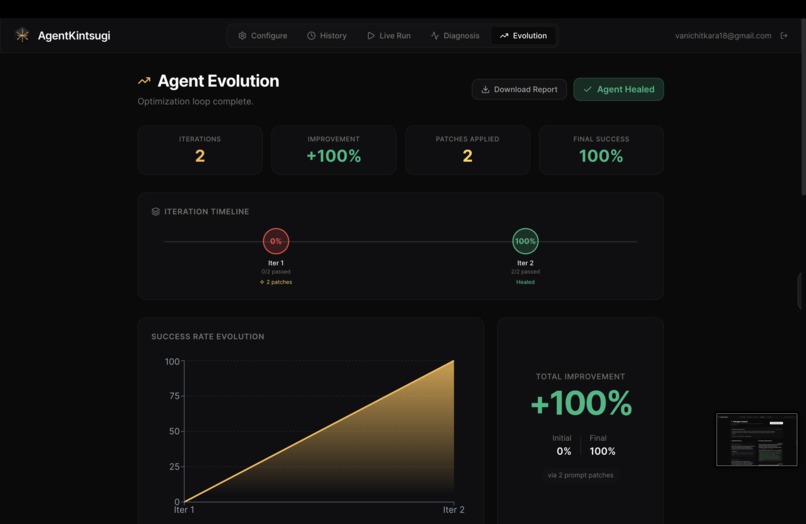
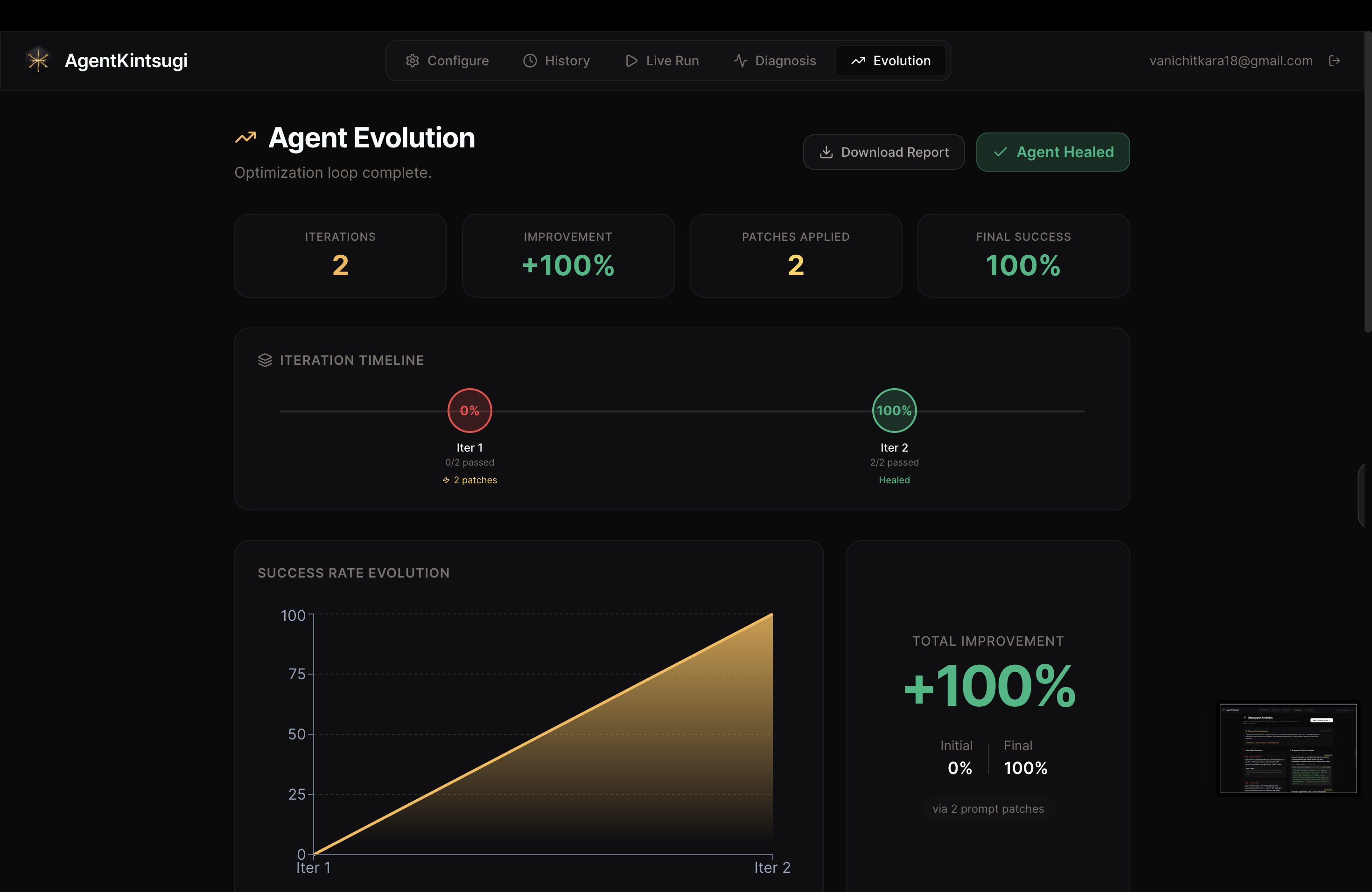
The evolutin graph shows agent execution evolution across multiple iterations
-
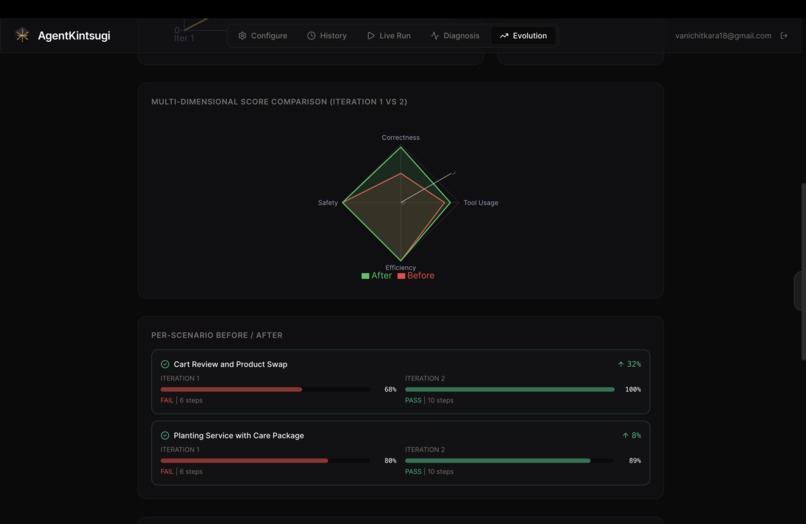
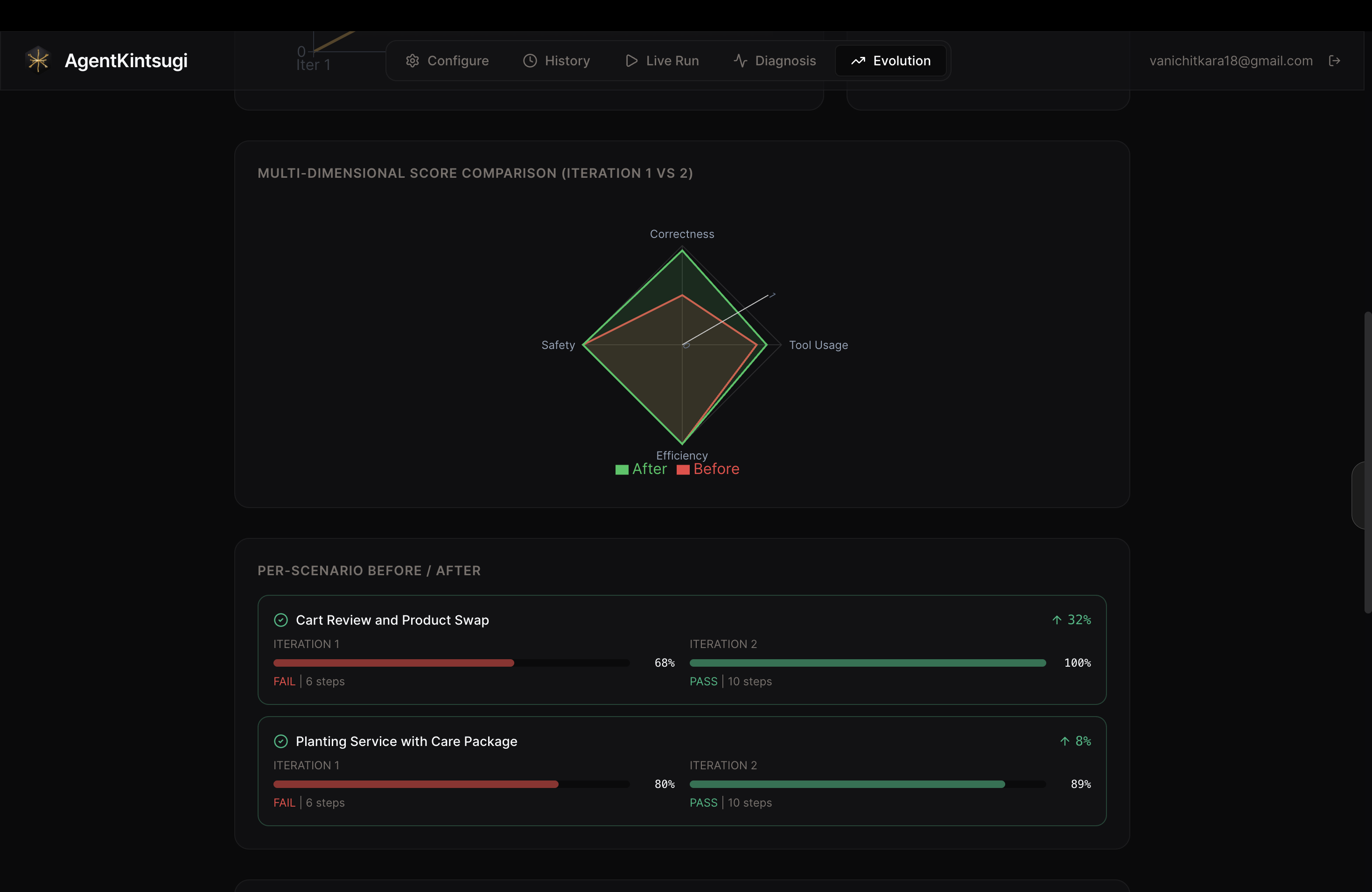
Multi-dimensional comparison amongst different agent test run iterations
Inspiration
The name comes from kintsugi — the Japanese art of repairing broken pottery with gold, turning flaws into features. I was inspired by a recurring frustration in agentic AI development: agents fail silently in production, and there's no systematic way to know why or how to fix them. You have to manually sift through traces, guess at prompt changes, and re-run tests by hand. I wanted to close that loop automatically.
What it does
Agent Kintsugi is a meta-agent that autonomously improves other AI agents. You point it at any agent built with the Google Agent Development Kit (ADK) and write your own test scenarios describing what your agent should do and how success is measured. Once your scenarios are defined, Agent Kintsugi runs a self-healing loop:
- Test — runs your agent against all of your scenarios and scores each one with a hybrid programmatic + Gemini LLM-as-Judge evaluator
- Diagnose — a Gemini-powered Debugger Agent queries Arize Phoenix for execution traces, identifies failure patterns (wrong tool calls, tool ordering errors, step-limit hits, latency spikes), and produces a structured diagnosis
- Patch — applies targeted prompt optimizations in-memory (never touching your source files) and re-tests only the failing scenarios
- Repeat — iterates until all your scenarios pass or the iteration budget is
exhausted, then exports a git-ready
.patchfile
The result is a full evolution timeline — per-scenario before/after comparisons, multi-dimensional radar charts, prompt version history in Phoenix, and a downloadable PDF report.
How I built it
- Backend: Python + FastAPI, structured around an async
run_forge_cycleorchestrator that manages the test → diagnose → optimize → retest loop - Agent framework: Google ADK (
google-adk) powers both the target agents under test and the internal Debugger Agent that autonomously queries Phoenix - LLM: Gemini 2.5 Pro for the LLM-as-Judge evaluator and Gemini 2.5 Flash for the Debugger Agent's diagnosis and scenario generation
- Observability: Arize Phoenix with OpenInference instrumentation captures every tool call, span, and latency for the target agent; the Debugger Agent then queries these traces via the Phoenix MCP server
- In-memory patching: The
ADKConnectordynamically imports any ADK agent module and applies prompt patches without modifying source files, exporting a finaldifflibdiff - User-defined scenarios: Users author their own test scenarios — specifying user input, expected tools, success criteria, and failure indicators — through the Configure page before starting a run
- Frontend: React + TypeScript + Vite, with Recharts for the evolution timeline and radar charts
- Auth & persistence: JWT authentication + Google Cloud Firestore for run history
- Deployment: Containerized with Docker, deployed to Google Cloud Run via Cloud Build
- CLI: Run the whole test cycle from the terminal.
Architecture Diagram
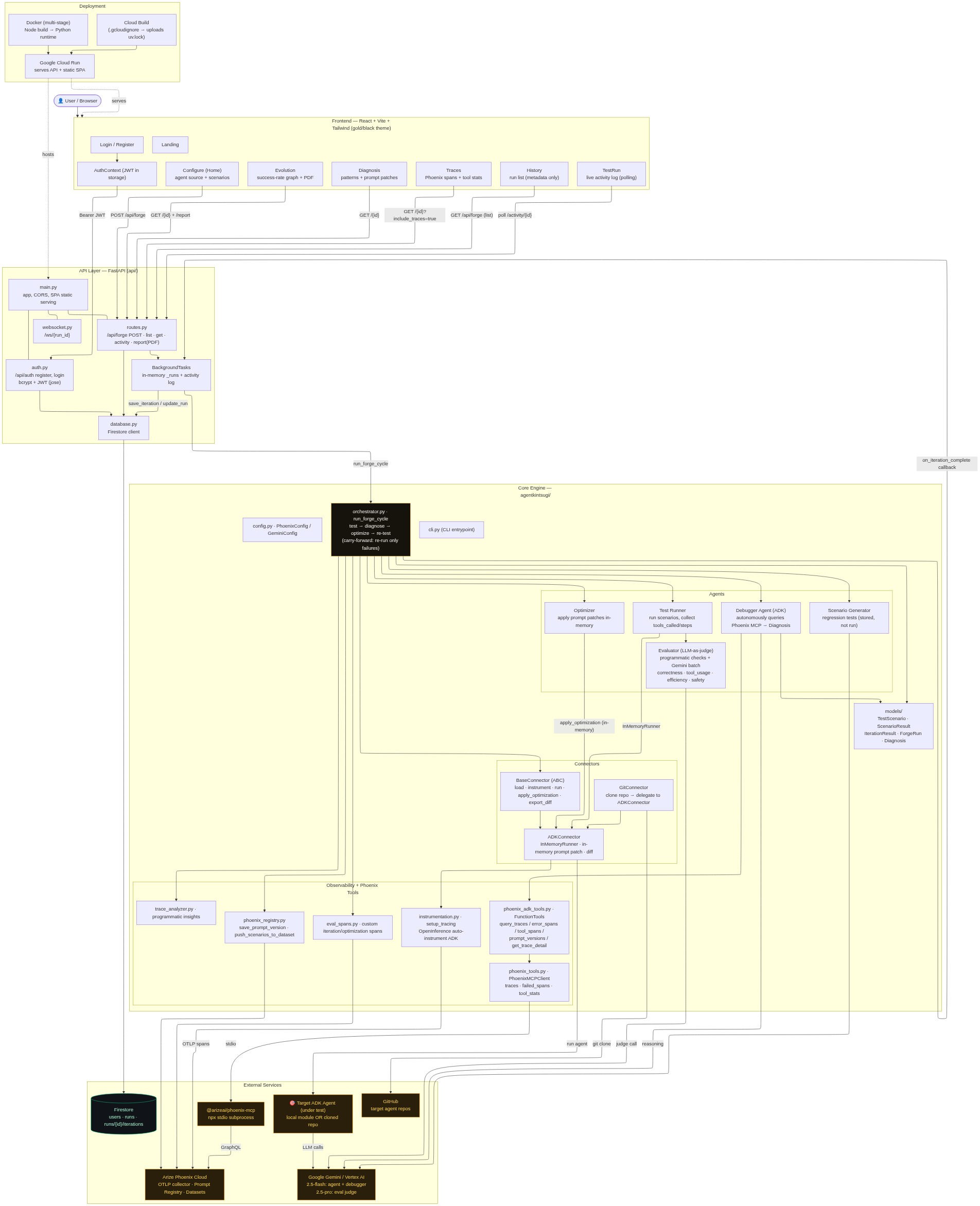
Challenges I ran into
- MCP server stability: The Phoenix MCP subprocess would accumulate corrupted stdio buffers across multiple LLM calls in the same process. I solved this by restarting the MCP client between diagnosis phases.
- Consistent evaluation: Getting the LLM evaluator to score consistently across runs required anchoring it with deterministic programmatic pre-checks (tool presence, call ordering, step counts) that constrain what the LLM can say.
- Iteration fairness: Naively re-running all scenarios each iteration would mix new passes with old failures, making improvement metrics misleading. I implemented a carry-forward system that only re-runs failing scenarios and merges previously-passed results.
- Scenario flexibility: Because users bring their own test scenarios with no enforced schema beyond a few required fields, the evaluator had to handle wildly different success criteria — from strict tool-call checklists to open-ended output quality checks.
- Rate limits during the optimization loop: Back-to-back Gemini calls for evaluation → diagnosis → scenario generation would hit rate limits. I added a cooldown phase between iterations.
Accomplishments that I'm proud of
- A fully autonomous test → diagnose → patch → retest loop that requires zero human intervention between iterations — once the user has defined their scenarios
- The hybrid evaluator combining programmatic ground truth with LLM-as-Judge — getting reliable, consistent scores across arbitrarily user-defined success criteria without expensive human labeling
- The in-memory patching system: Agent Kintsugi never writes to your source files, making it safe to run against any production agent
- End-to-end Phoenix integration: traces, prompt version history, and scenario datasets all flow into Phoenix automatically
- A polished real-time UI with live streaming updates, per-scenario before/after comparisons, and a one-click PDF report
What I learned
- Observability is the missing piece of the agentic AI development loop — without traces, diagnosis is guesswork
- Small, targeted prompt patches consistently outperform large rewrites; the key insight is identifying which failure pattern to address, not writing a better prompt from scratch
- LLM-as-Judge evaluation needs a deterministic anchor layer or scores drift across runs — especially important when users define their own arbitrary success criteria
- Building a meta-agent (an agent that improves agents) surfaces all the reliability problems of agentic systems in sharp relief — flaky tool calls, context window management, and error propagation all matter much more when the agent is in a control loop
What's next for Agent Kintsugi
- Support for agents built on other frameworks (LangGraph, CrewAI, custom) via a plugin connector interface
- A scenario builder UI that helps users write well-structured test scenarios with suggested success criteria and tool checklists, lowering the barrier to getting started
- A regression test suite that automatically runs user-defined scenarios on every new commit (CI/CD integration)
- Fine-tuning export: instead of prompt patches, output a dataset of (input, ideal_output) pairs — derived from the user's own scenarios — for fine-tuning the target model
- Multi-agent system support: diagnosing failures that span across agent handoffs, not just single-agent runs
Built With
- arize
- bcrypt
- css
- docker
- fastapi
- firestore
- fpdf2
- gemini-2.5-flash
- google-cloud
- googleadk
- hatchling
- jwt
- openinference
- opentelemetry
- phoenix
- pydantic
- python
- react
- recharts
- tailwind
- typescript
- uv
- uvicorn
- vite
- websockets

Log in or sign up for Devpost to join the conversation.