Inspiration
The inspiration was twofold: the desire to democratize machine learning for non-experts and the need to overcome the data privacy barrier that stops companies from using AI. While tools like H2O AutoML are powerful, they still require technical expertise. We saw AI agents as the perfect bridge.
The "eureka" moment came with powerful open-source models like gpt-oss-120b. We realized we could build a system that runs entirely locally, allowing companies to finally use their most sensitive data for AI without sending it to external APIs. Our vision was to bring the AI to the data, not the other way around, creating a secure, accessible, and intelligent system.
What it does
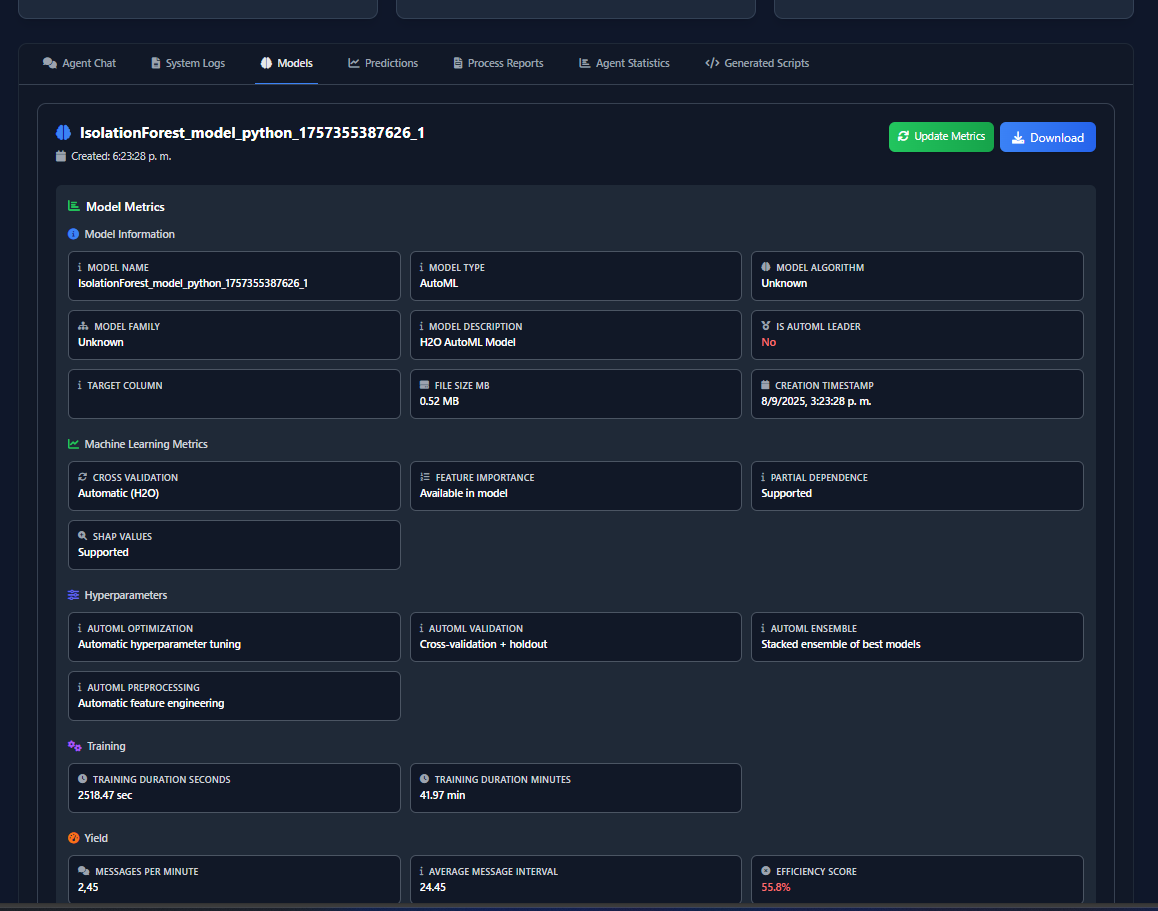
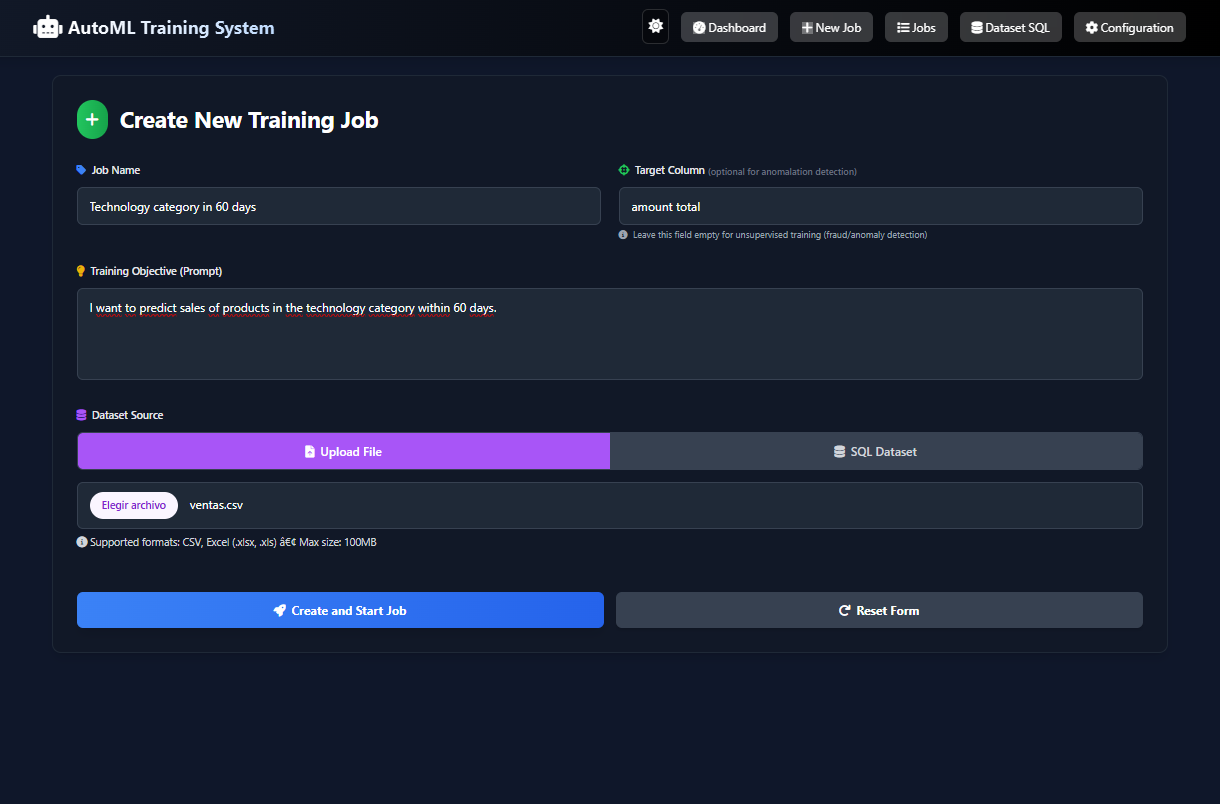
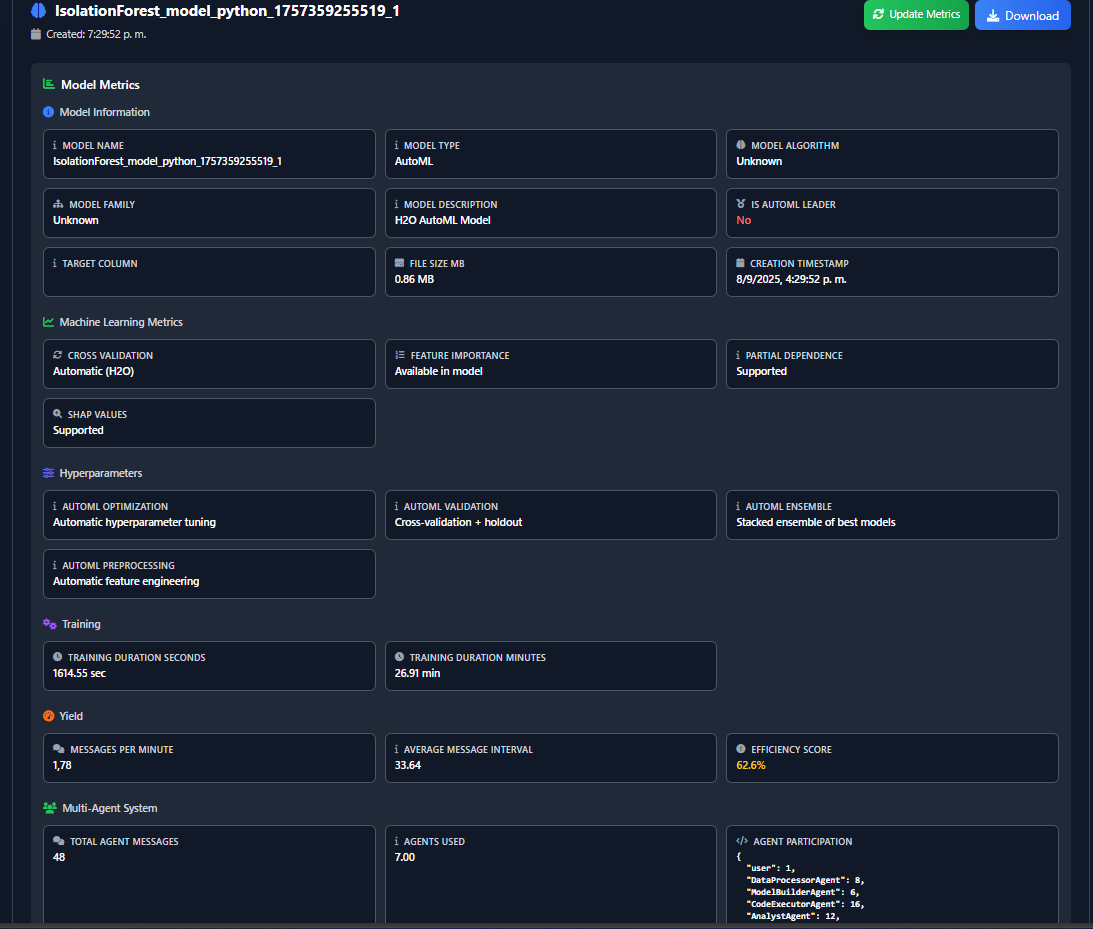
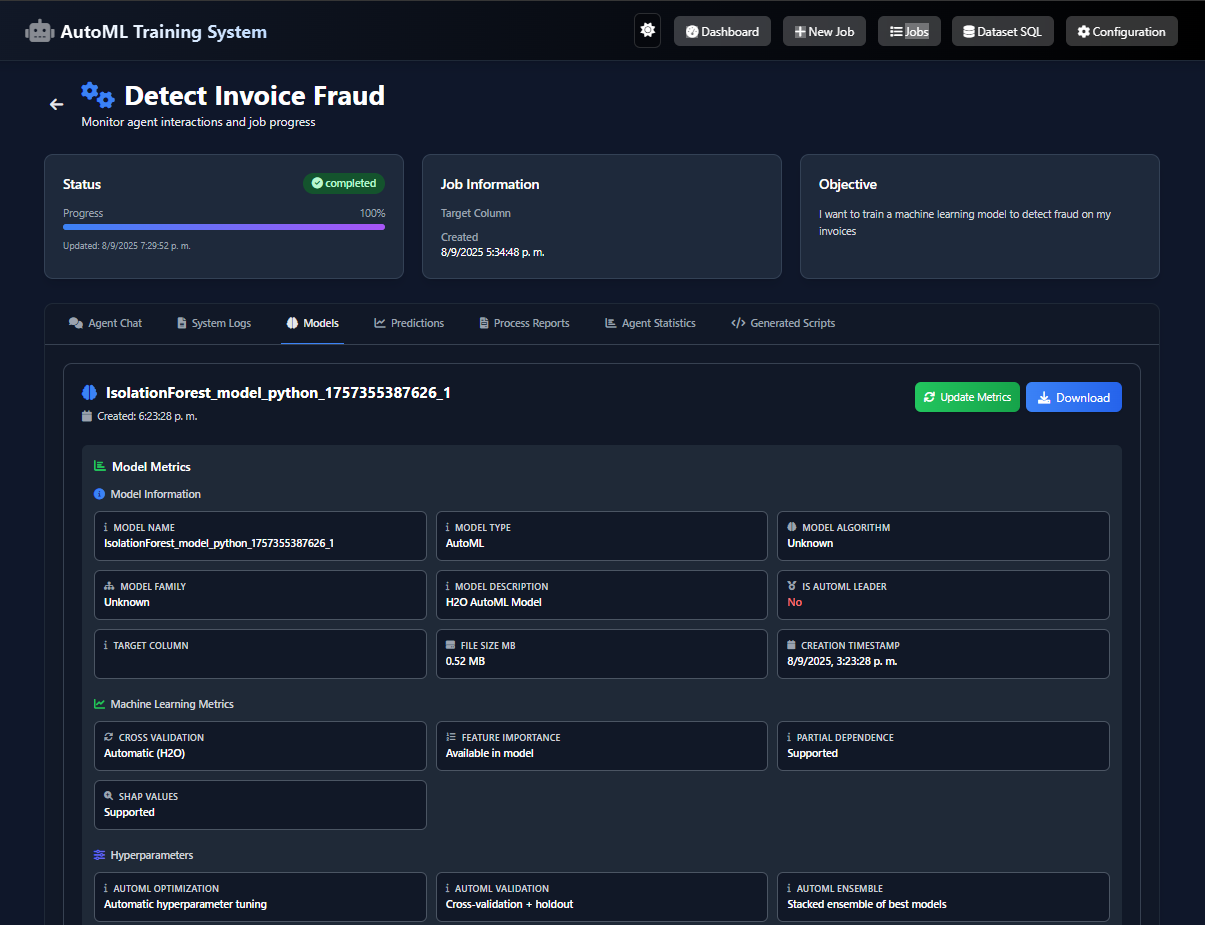
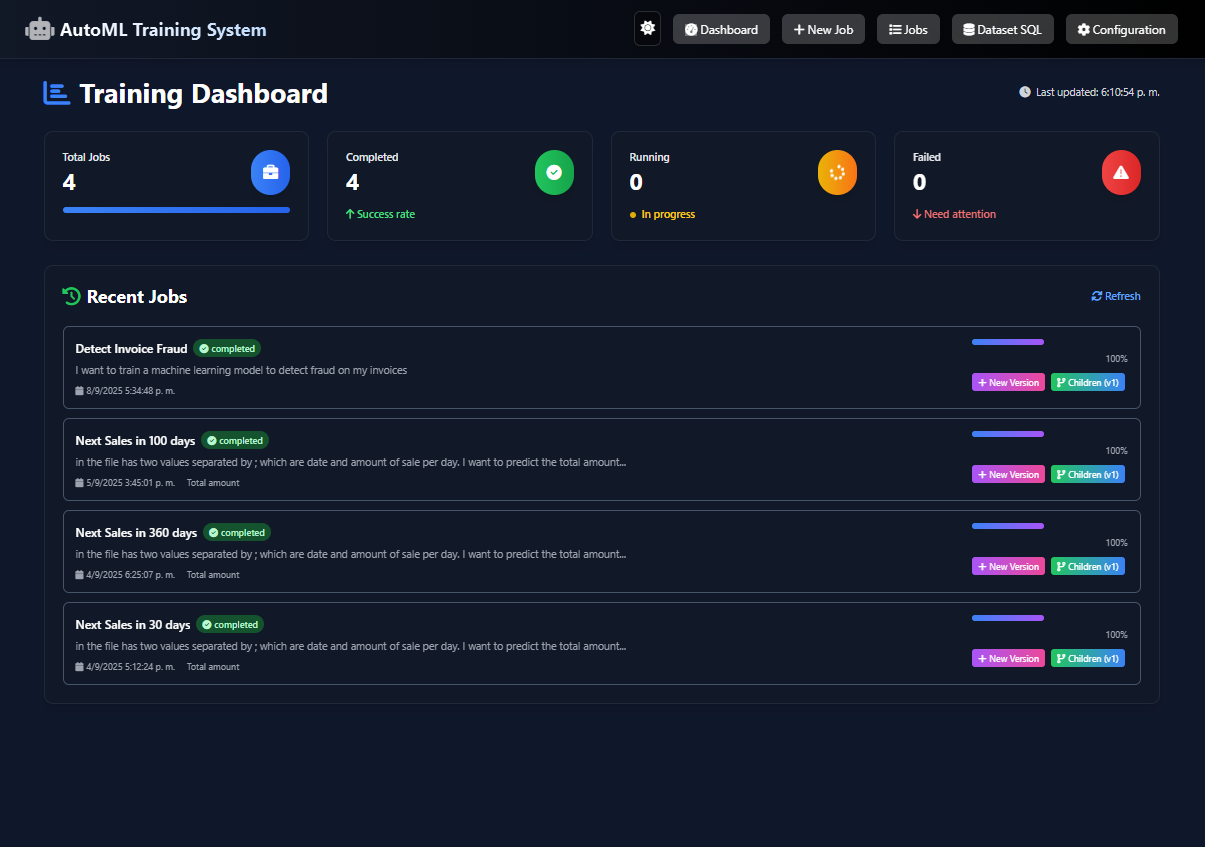
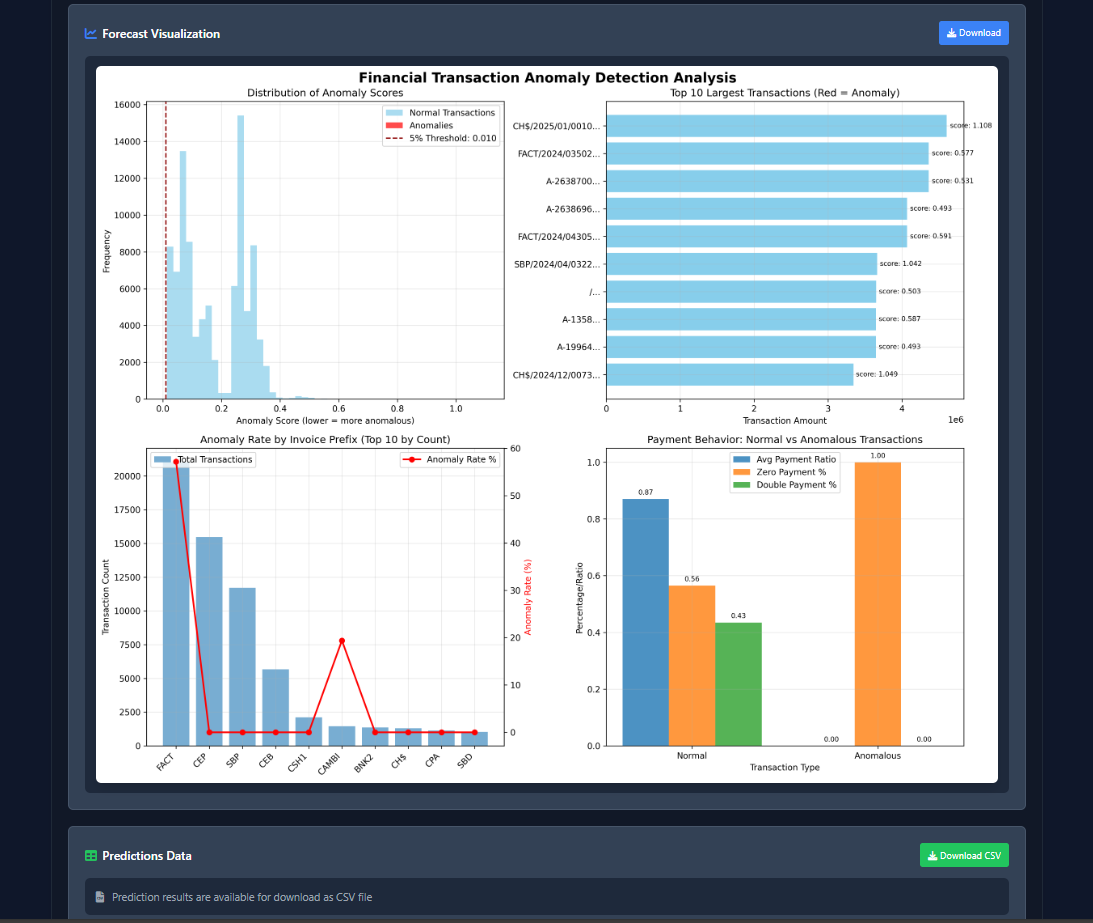
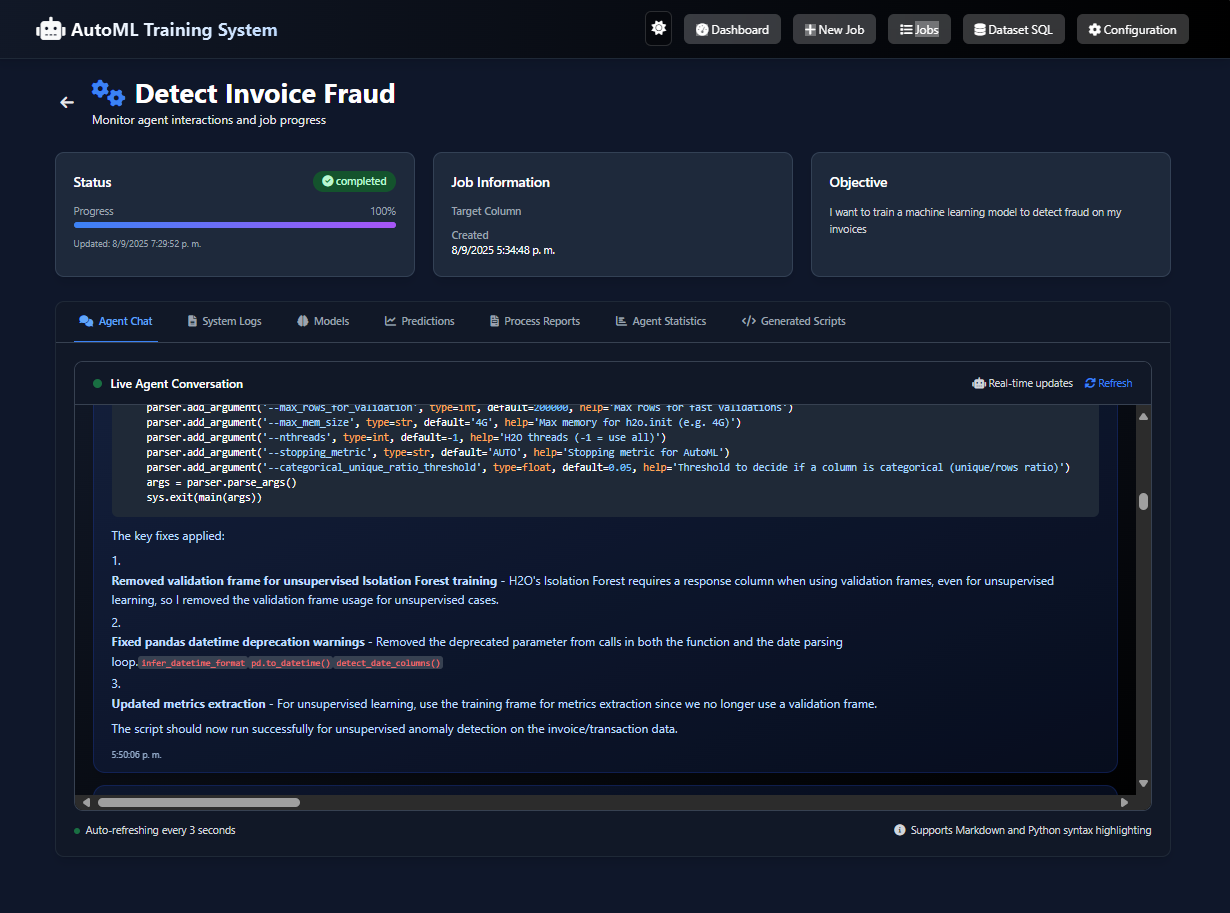
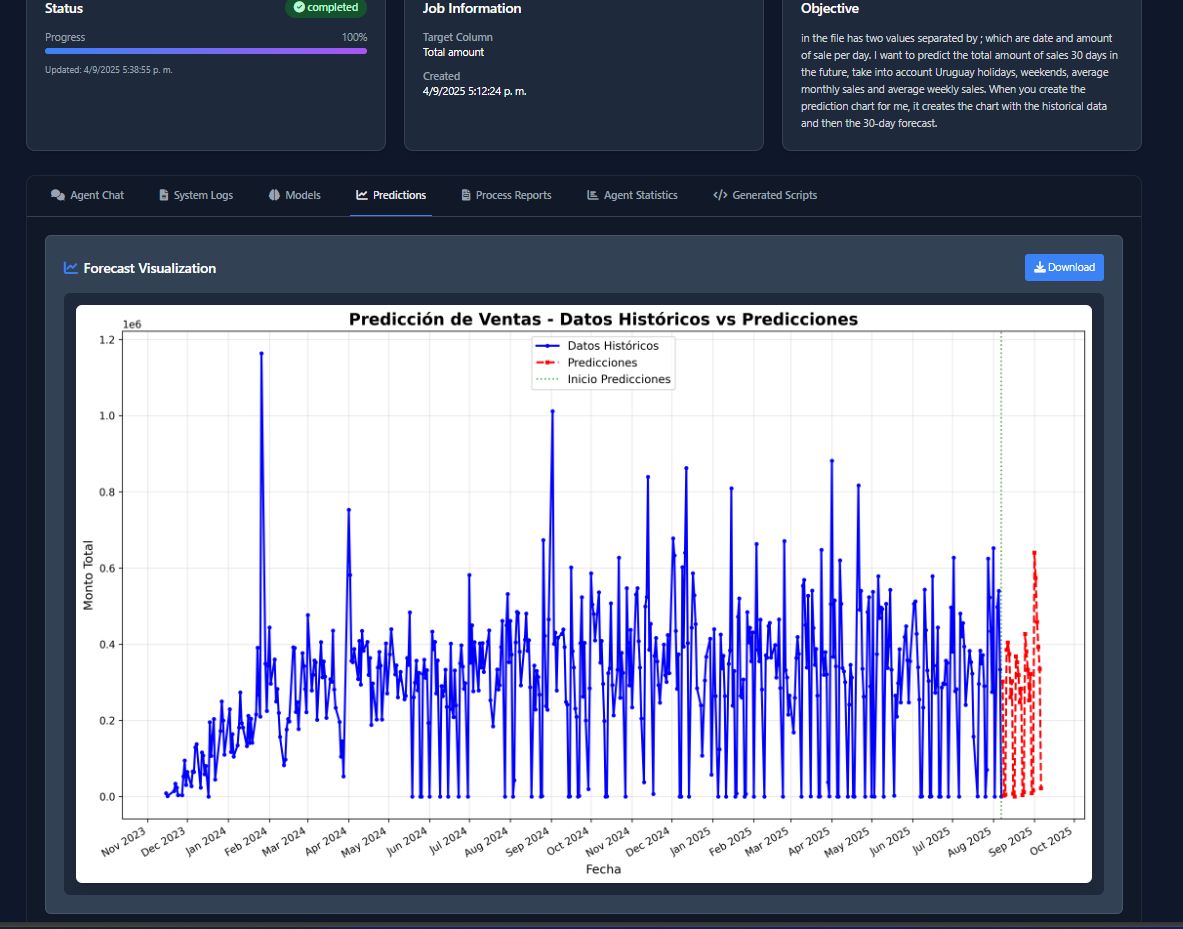
This project is an autonomous, privacy-first ML system powered by seven specialized AI agents. A user uploads a dataset and defines an objective in natural language (e.g., "predict customer churn"). The system then handles the entire workflow: data analysis, code generation, model training (using H2O AutoML), and visualization.
The core value is 100% Data Privacy. The system is powered by a locally-run gpt-oss model (via Ollama), so sensitive data never leaves the user's machine. This unlocks AI for "trapped" data in finance and healthcare. The system outputs trained models, predictions, and charts to a simple web dashboard, versions every run, and includes a beta SQL Agent to query databases using natural language.
How we built it
We built the system on a modular, agent-based architecture:
- Local AI Brain: Agent intelligence is powered by a gpt-oss model running on a local inference server like Ollama.
- Core ML Engine: We use H2O AutoML for its robust, high-performance model generation.
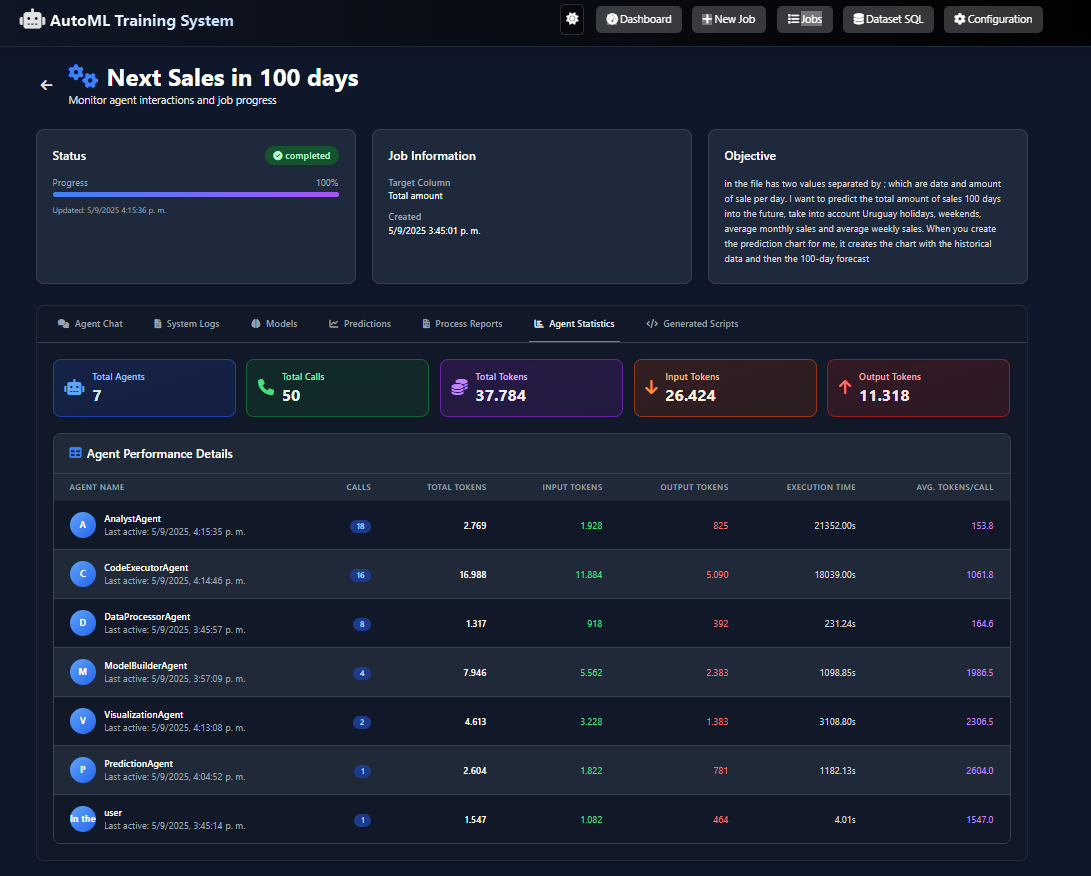
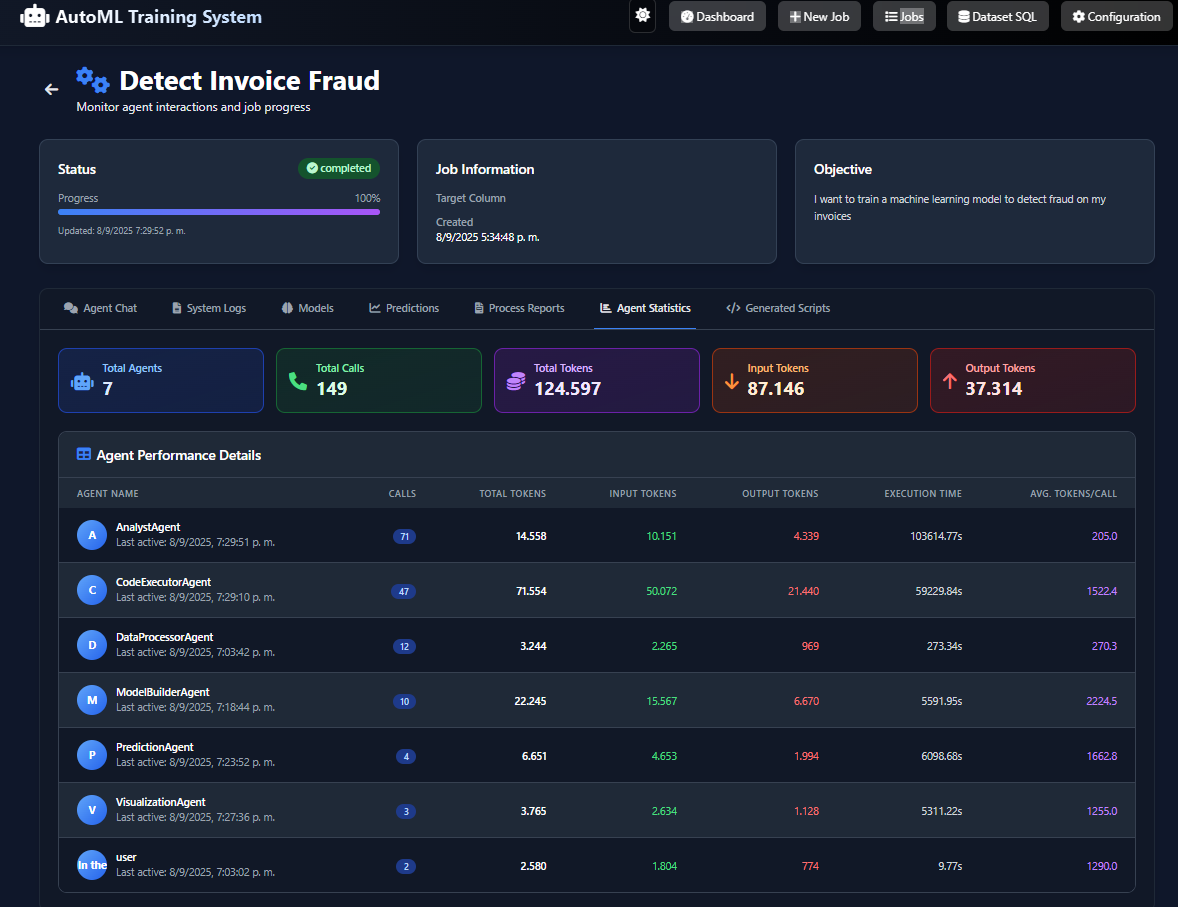
- Agent Framework: We used AutoGen to create a "team of experts", with seven agents (DataProcessor, ModelBuilder, etc.) each having a unique role.
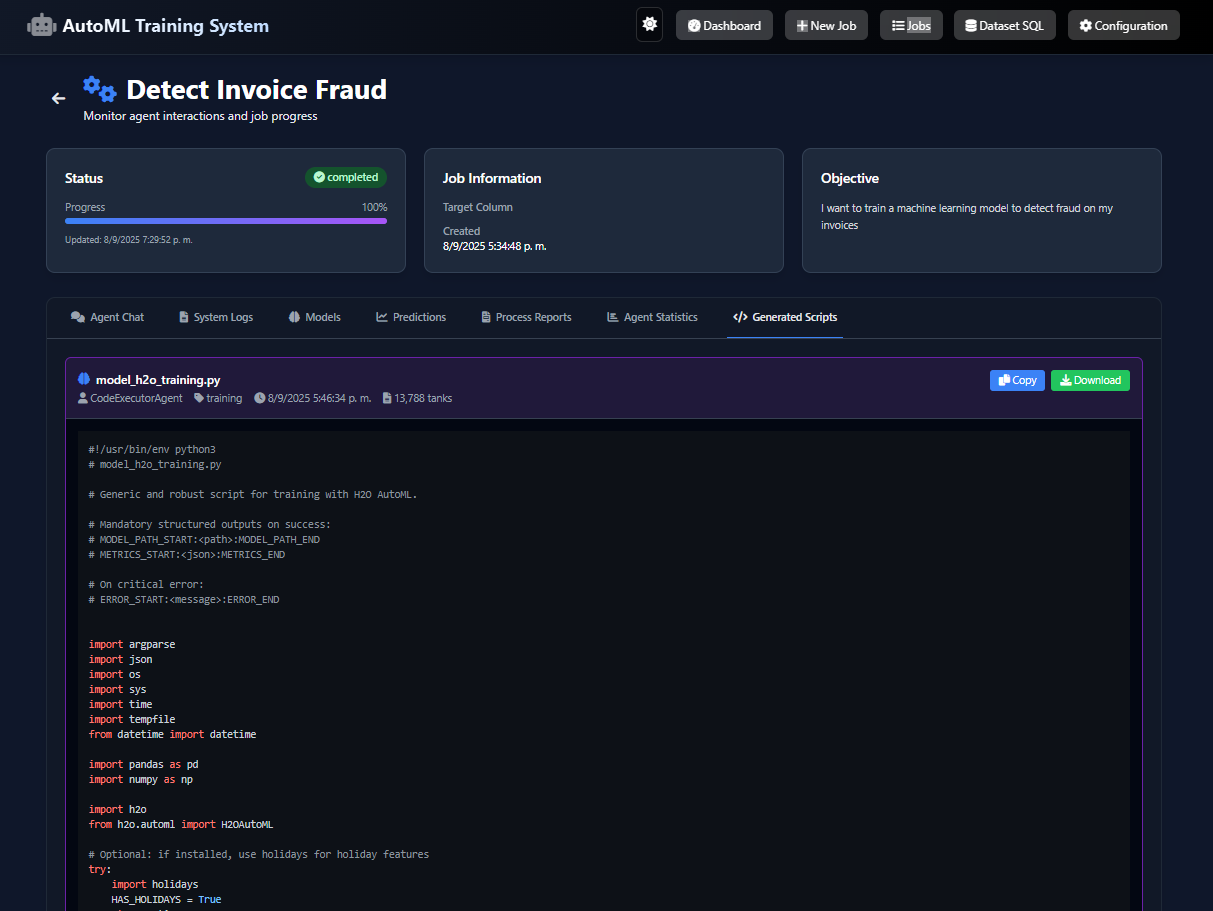
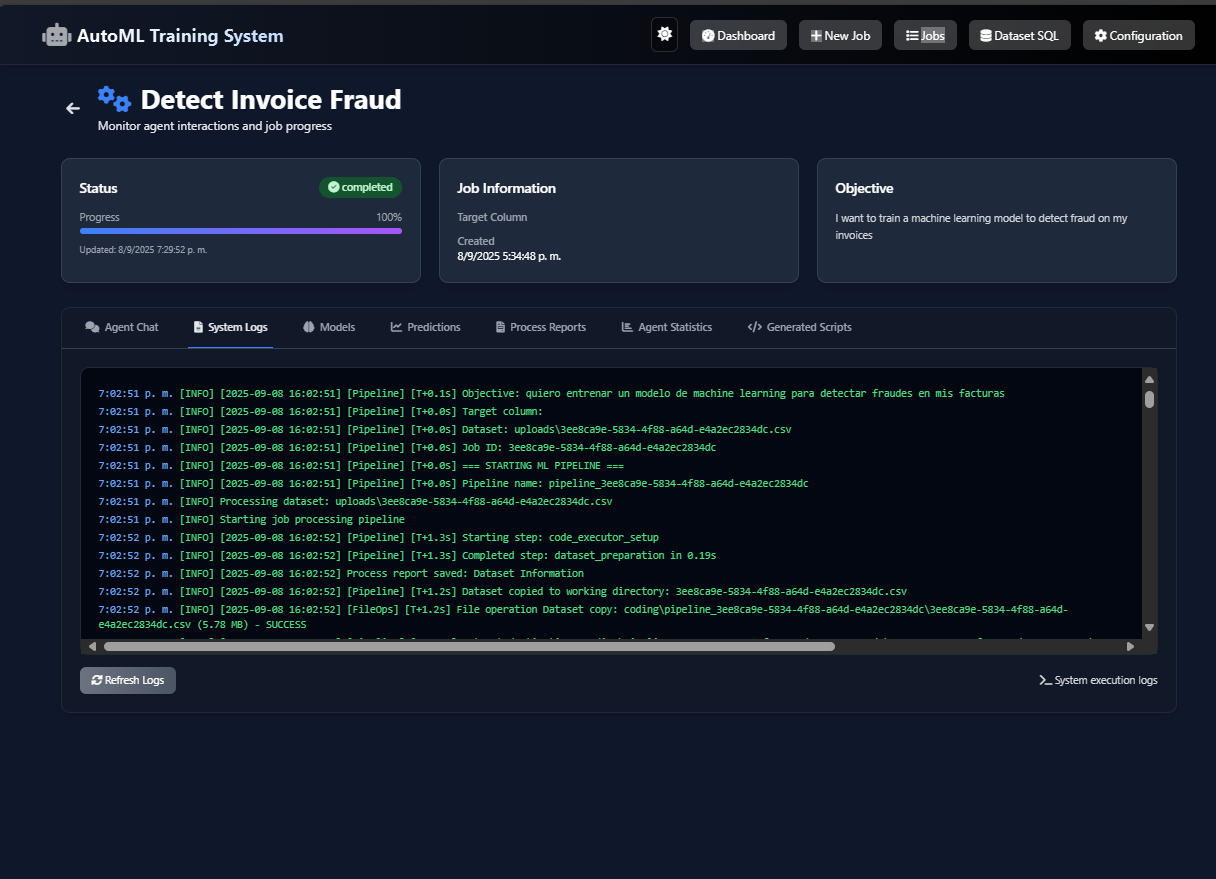
- Secure Execution: All agent-generated code runs in an isolated Docker sandbox to ensure security and manage dependencies.
- Web Interface and API: A FastAPI backend and simple HTML/JS frontend allow users to upload files, monitor training, and view results.
- Orchestration: A central Pipeline Orchestrator manages the workflow, deciding which agent to invoke and passing information between them.
Challenges we ran into
- Agent Coordination: Ensuring seamless communication between agents (e.g., from the DataProcessor's analysis to the ModelBuilder's code) required extensive prompt refinement.
- State Management: Managing state (file paths, models) across stateless Docker executions for different pipeline stages was a major architectural hurdle.
- Handling AI Non-Determinism: LLMs can be unpredictable. We built robust error-handling and retry loops, especially with the AnalystAgent, to make the pipeline reliable.
- Local Model Optimization: Finding the right local model was critical. gpt-oss-120b provided the best balance of reasoning, while smaller models got stuck, and larger models were too resource-intensive for a local environment.
- Dynamic Adjustment: Teaching agents to recognize poor model metrics and automatically decide to adjust parameters or features to improve performance was challenging.
Accomplishments that we're proud of
- Real-World Validation & Empowerment: We successfully tested the system with real sales data from two Uruguayan online stores (wiki.com.uy, decotech.uy). This proved that users with deep business knowledge, but no ML experience, could train powerful models on their own—like giving them a virtual data scientist.
- Harnessing gpt-oss for Superior Reasoning: Using gpt-oss as the core brain was a huge win. It reduced the agents’ code self-correction cycle by 50% compared to other models, showing massive improvements in task execution and workflow understanding.
- Achieving True Data Privacy: We built a powerful AutoML system where sensitive data never leaves the user's machine, solving a major blocker for AI adoption in regulated industries.
- Building a Self-Healing System: The AnalystAgent acts as a quality control specialist. It reviews code and results from other agents and can send tasks back for correction, creating a robust, self-healing workflow.
- The Power of Specialization: We proved that dividing the complex AutoML pipeline into tasks for specialized agents is far more effective than a monolithic approach.
What we learned
- gpt-oss Excels in Reasoning: This project confirmed that gpt-oss is exceptional at reasoning tasks, which significantly sped up development and improved reliability.
- Prompt Engineering is Everything: The quality of the system is directly tied to the quality of the prompts. We learned that refining prompts to clearly define each agent's role, limitations, and output format is the most critical part of development.
- Self-Correction Loops are a Must: A validator agent (like our AnalystAgent) is essential. It creates a robust system that can catch and fix its own mistakes.
- Specialization Unlocks Potential: Breaking a complex problem down for specialized agents is a highly effective design pattern, allowing the LLM to focus its reasoning power on well-defined tasks.
What's next for Multi-Agent Auto Machine Learning - Deep Learning System
- Expanded ML Capabilities: Move beyond tabular data to support time-series forecasting, NLP, and computer vision.
- Enhanced User Interaction: Build a more interactive UI where users can collaborate with agents and tweak parameters during the training process.
- Custom Agent Workflows: Allow users to define their own agent workflows to tailor the pipeline to unique business problems.
- Advanced Feature Engineering: Empower agents with more sophisticated tools for automatic feature engineering to further improve model performance.


Log in or sign up for Devpost to join the conversation.